Google Kubernetes Engine で Gemma を使用するための詳細: 生成 AI オープンモデルのサービングを実現する新たなイノベーション

Google Cloud Japan Team
※この投稿は米国時間 2024 年 4 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
AI のイノベーションにまい進する組織にとって、すばらしい時代が到来しました。先日 Google がリリースした Gemini は Google 最大かつ最高性能の AI モデルです。これに続き、Gemini のモデルの作成に使用されたものと同じ研究と技術に基づいて構築された軽量な最先端のオープンモデル ファミリー、Gemma をリリースしました。Gemma のモデルは、他のオープンモデルと比べて軽量(Gemma 2B と Gemma 7B)でありながら最高水準のパフォーマンスを発揮します。トレーニング済みバージョンと指示用にチューニングされたバージョンがあり、研究開発に活用できます。Google は、Google Cloud のデベロッパーにとってよりオープンで利用しやすい AI を実現する取り組みの次の段階として、Gemma と最新のプラットフォーム機能をリリースしました。本日は、Gemma のサービングとデプロイを GKE Standard と GKE Autopilot で行えるよう Google Kubernetes Engine(GKE)に加えた以下の機能改良についてご紹介します。
-
Hugging Face、Kaggle、Vertex AI Model Garden とのインテグレーション: GKE のお客様は、Hugging Face、Kaggle、または Vertex AI Model Garden から Gemma をデプロイできます。このインテグレーションにより、任意のリポジトリから任意のインフラストラクチャに簡単にモデルをデプロイできるようになりました。
-
Colab Enterprise を使用した GKE ノートブック環境の構築: デベロッパーが IDE タイプのノートブック環境で ML プロジェクトを実行することを希望する場合、Google Colab Enterprise を使用して Gemma のデプロイとサービングを行えます。
-
費用対効果と信頼性が高くレイテンシが低い AI 推論スタック: 今週初めに発表した JetStream は、GKE での Gemma のサービングを可能にする、AI で最適化された非常に効率的な大規模言語モデル(LLM)推論スタックです。JetStream の他にも、費用対効果とパフォーマンスに優れた、AI で最適化された多数の推論スタックを導入しました。これらを使用することで、Cloud GPU または Google の専用 Tensor Processing Unit(TPU)を搭載した ML フレームワーク(PyTorch、JAX)で Gemma のサービングを行えます。本日、別の投稿で Google Cloud で Gemma を使用する場合のパフォーマンスに関する詳細をお知らせしました。この AI で最適化されたインフラストラクチャで、生成 AI ワークロードのトレーニングと処理を行うことができます。
生成 AI アプリケーションを構築する開発者、生成 AI のコンテナ ワークロードを最適化する ML エンジニア、これらのコンテナ ワークロードを運用化するインフラストラクチャ エンジニアなど、あらゆる役割の方々が Gemma を使用して移植とカスタマイズが可能な AI アプリケーションを構築し、GKE でデプロイできます。
各リリースについて詳しく見ていきましょう。
Hugging Face、Vertex AI Model Garden、Kaggle とのインテグレーション
Google は、どこで入手した AI モデルでも、GKE で簡単にデプロイできるようにすることを目指しています。
Hugging Face
今年に入り、Google は Hugging Face との戦略的パートナーシップを締結しました。Hugging Face は、データ サイエンティスト、ML エンジニア、開発者に最新モデルへのアクセスを提供する、人気の高い AI コミュニティのひとつです。Hugging Face がリリースした Gemma モデルカードを使用すると、Gemma を Hugging Face から直接 Google Cloud にデプロイできます。Google Cloud のオプションをクリックするとリダイレクトされる Vertex Model Garden で、Vertex AI または GKE での Gemma のデプロイとサービングを選択できます。
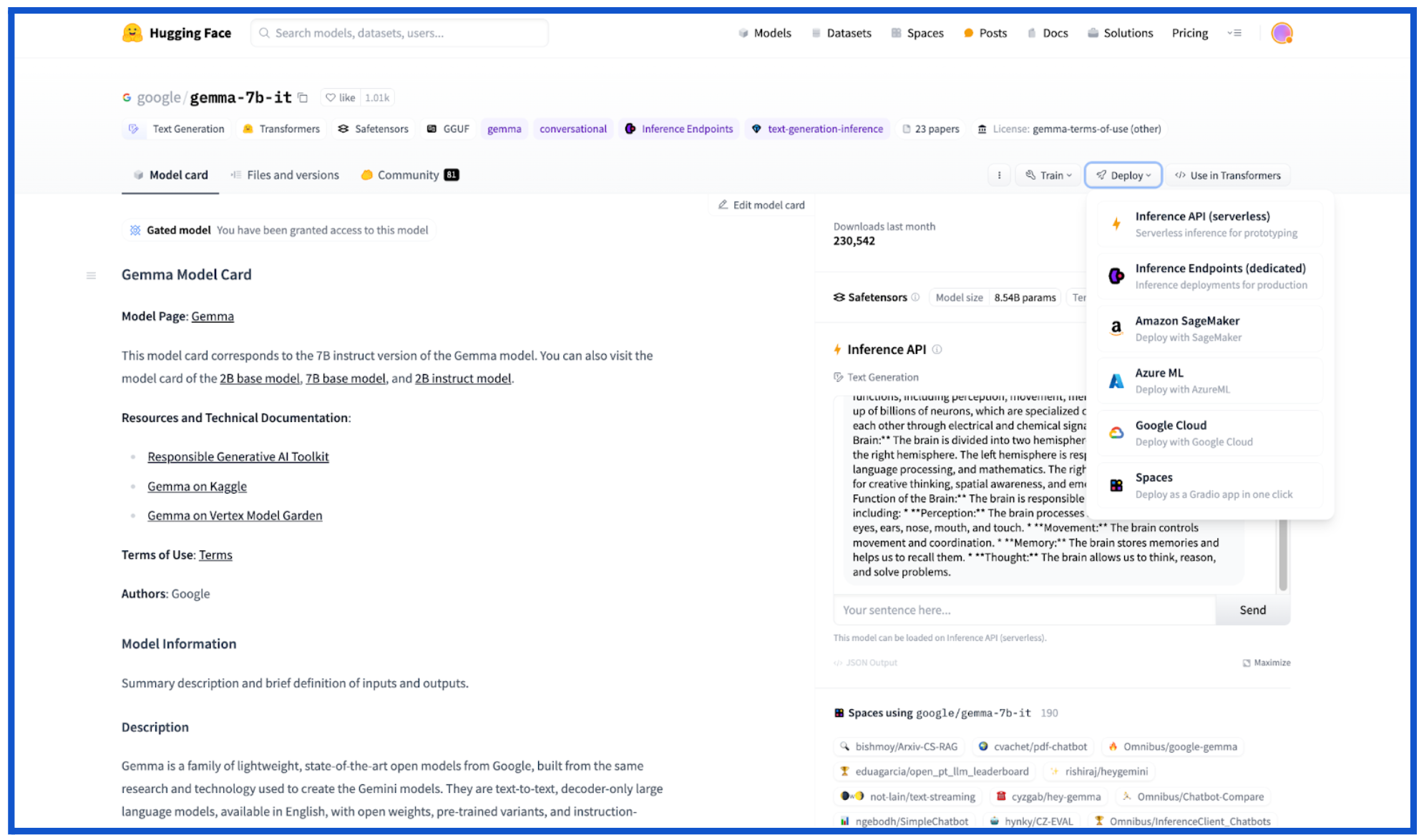
Vertex Model Garden
Vertex AI Model Garden では、Google やサードパーティのエンタープライズ向け基盤モデル API、オープンソース モデル、タスク固有モデルなど、130 を超えるモデルを提供しており、Gemma もそのひとつです。
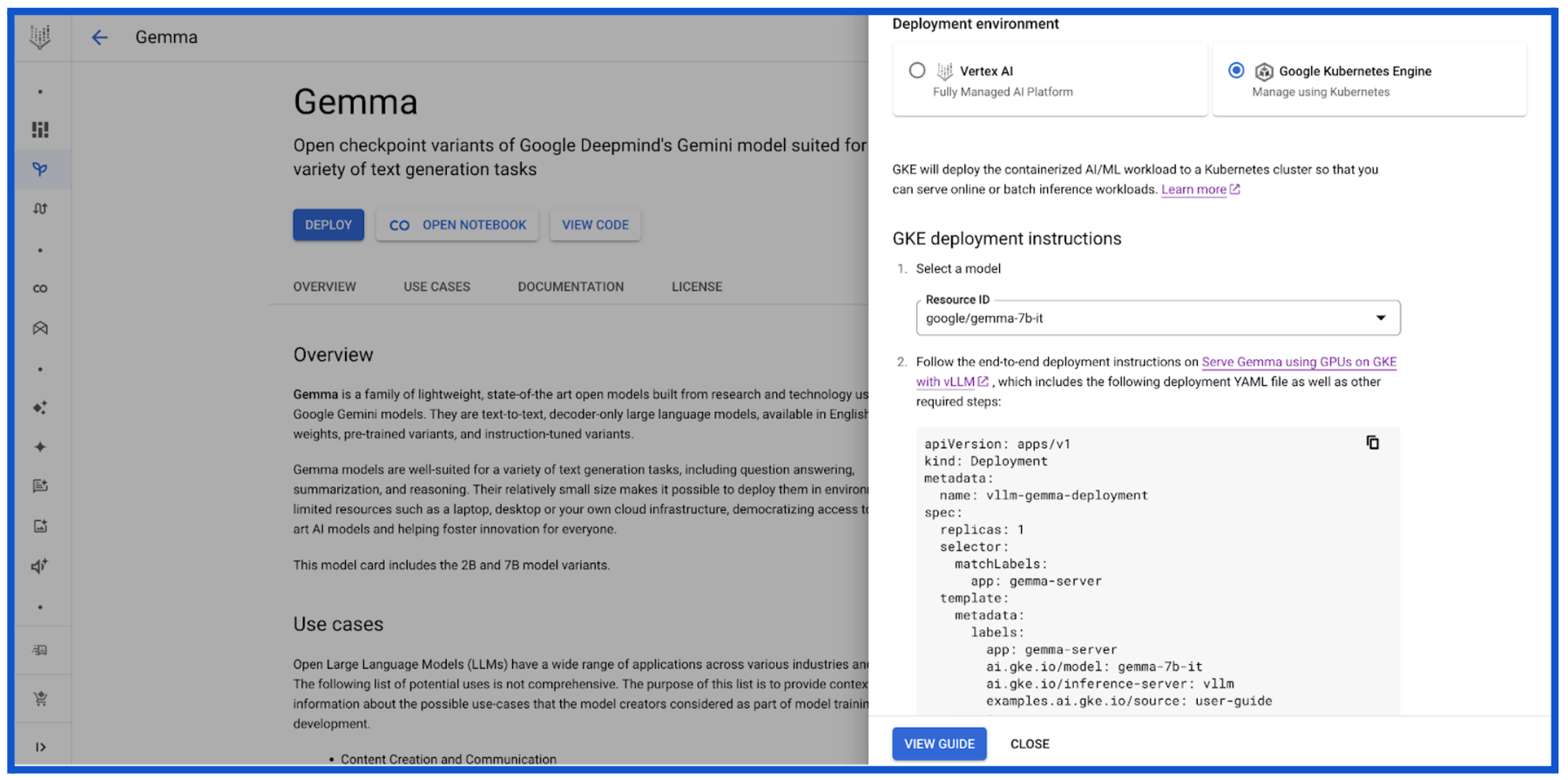
Kaggle
Kaggle を利用する開発者は、すぐにデプロイ可能な数千種類のトレーニング済み ML モデルを一か所で検索して見つけることができます。Kaggle の Gemma モデルカードには多数のモデル バリエーション(PyTorch、FLAX、Transformers など)が示されており、GKE クラスタでの Gemma のダウンロード、デプロイ、サービングをエンドツーエンドのワークフローで実行できます。Kaggle のお客様が「Vertex で開く」こともできます。この場合、Vertex Model Garden に移動し、前述したように、Vertex AI または GKE での Gemma のデプロイを選択するオプションが表示されます。Kaggle の Gemma のモデルページのコミュニティでは Gemma を使用した実際の例が共有されているので、ご覧ください。
Google Colab Enterprise ノートブック
開発者、ML エンジニア、ML 担当者は、Vertex AI Model Garden を介して、Google Colab Enterprise ノートブックを使用して GKE で Gemma のデプロイとサービングを行うこともできます。Colab Enterprise ノートブックではコードセルに指示があらかじめ入力されているため、開発者、ML エンジニア、サイエンティストが好むインターフェースを使用して GKE で柔軟にデプロイを行い、推論を実行できます。
AI で最適化されたインフラストラクチャでの Gemma モデルのサービング
推論を大規模に実行する場合、1 ドルあたりのパフォーマンスとサービングにかかる費用が重要です。Google Cloud TPU と GPU を搭載した、AI で最適化されたインフラストラクチャ スタックを基盤とする GKE なら、幅広い AI ワークロードで費用対効果とパフォーマンスに優れた推論を実行できます。
「GKE によって TPU と GPU がシームレスに統合されることで、ML パイプラインが強化されます。これにより特定のタスクにそれぞれの強みを活用し、レイテンシと推論費用を削減できるようになります。たとえば、TPU 上で大規模なテキスト エンコーダを使用してテキスト プロンプトをバッチで効率的に処理した後に GPU を使用して社内拡散モデルを実行し、テキスト埋め込みを利用して見事な画像を生成しています。」 - Lightricks、コア生成 AI リサーチチーム リーダー Yoav HaCohen 博士
Google は、GKE で Gemma を使用するワークロードにこれらのメリットを拡張できることを喜ばしく思っています。
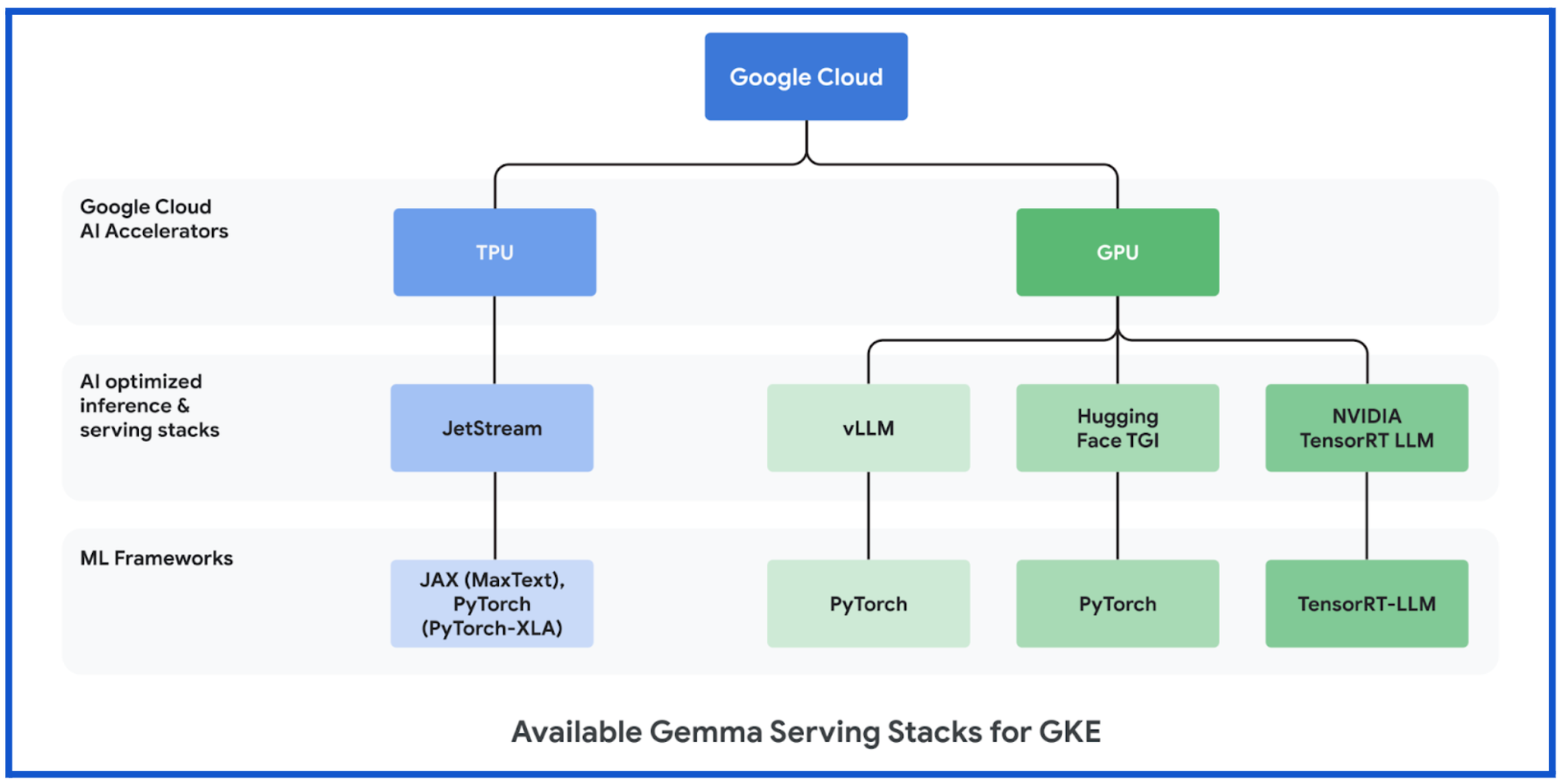
GKE の Gemma で TPU を使用する場合
GKE インフラストラクチャで Google Cloud TPU アクセラレータを使用したい場合、AI で最適化された複数の推論およびサービング フレームワークで Google Cloud TPU の Gemma もサポートしています。よく使用される LLM はすでにサポート済みです。たとえば次のようなものです。
JetStream
Google Cloud TPU での PyTorch または JAX LLM の推論パフォーマンスを最適化するために、JetStream(MaxText)と JetStream(PyTorch-XLA)をリリースしました。JetStream は、LLM の推論に特化した新しい推論エンジンです。JetStream はパフォーマンスと費用対効果の両方を大幅に向上させるソリューションであり、Google Cloud TPU での LLM の推論のスループットとレイテンシの面で強みを発揮します。JetStream はスループットとメモリ使用率の両方を考慮して最適化されており、連続的なバッチ処理、重みのための int8 量子化、アクティベーション、KV キャッシュなどの高度な最適化手法を組み込むことで効率向上を実現しています。JetStream は Google が推奨する TPU 推論スタックです。
GKE の Gemma で Google Cloud TPU を使用する環境で JetStream の推論を初めて実行する場合は、こちらのチュートリアルを参考にしてください。
GKE の Gemma で GPU を使用する場合
GKE インフラストラクチャで Google Cloud GPU アクセラレータを使用したい場合、AI で最適化された複数の推論およびサービング フレームワークで Google Cloud GPU の Gemma もサポートしています。よく使用される LLM はすでにサポート済みです。たとえば次のようなものです。
vLLM
PyTorch の生成 AI ユーザーのサービング スループットを向上させるために使用される vLLM は、高度に最適化されたオープンソースの LLM サービング フレームワークです。vLLM には次のような機能が用意されています。
-
PagedAttention による Transformer の実装の最適化
-
サービング スループットを全体的に向上させる連続的なバッチ処理
-
複数の GPU でのテンソル並列処理と分散サービング
GKE の Gemma で Google Cloud GPU を使用する環境で vLLM を初めて使用する場合は、こちらのチュートリアルを参考にしてください。
Text Generation Inference(TGI)
高パフォーマンスなテキスト生成を可能にする Text Generation Inference(TGI)は、LLM のデプロイとサービングを目的とする Hugging Face の高度に最適化されたオープンソース LLM サービング フレームワークです。TGI には、サービングのスループット全体を改善する継続的なバッチ処理、複数の GPU でのテンソル並列処理や分散サービングなどの機能が用意されています。
GKE の Gemma で Google Cloud GPU を使用する環境で Hugging Face の Text Generation Inference を初めて使用する場合は、こちらのチュートリアルを参考にしてください。
TensorRT-LLM
NVIDIA Tensor Core GPU が搭載された Google Cloud GPU VM で最新の LLM の推論パフォーマンスを最適化する場合、NVIDIA TensorRT-LLM を使用できます。これは、LLM を推論向けにコンパイルし、最適化するための包括的なライブラリです。TensorRT-LLM は、アテンションの分割(PagedAttention)や継続的なインフライト バッチングなどの機能をサポートしています。
GKE と NVIDIA Tensor Core GPU が搭載された Google Cloud GPU VM で NVIDIA Triton および TensorRT LLM バックエンドを初めて使用する場合は、こちらのチュートリアルを参考にしてください。
AI ワークロードのトレーニングとサービングをもっと自由に
Gemma で新しい生成 AI モデルを構築する場合も、これらのモデルのトレーニングとサービングを行うインフラストラクチャを選択する場合も、Google Cloud には開発者のニーズと好みに対応する多様なオプションが用意されています。GKE は、汎用性、費用対効果、パフォーマンスに優れたセルフマネージドのプラットフォームであり、次世代の AI モデル開発の土台として活用できます。
主要な AI モデル リポジトリすべて(Vertex AI Model Garden、Hugging Face、Kaggle、Colab ノートブック)とのインテグレーションを実現し、Google Cloud GPU と Google Cloud TPU の両方をサポートする GKE なら、Gemma のデプロイとサービングを複数の方法で柔軟に行えます。今後、世界中の皆様が Gemma と GKE を活用して達成する成果を楽しみにしています。詳しくは、こちらのランディング ページで GKE での Gemma に関するユーザーガイドをご覧ください。
ー プロダクト マネージャー Vilobh Meshram

