Google Cloud と Seagate: 予測 ML でハードディスク ドライブのメンテナンスを変革
Google Cloud Japan Team
※この投稿は米国時間 2021 年 5 月 8 日に、Google Cloud blog に投稿されたものの抄訳です。
データセンターは今、フラッシュ革命の真っ只中にあるといえるでしょう。それでも、ハードディスク ドライブ(HDD)の管理は依然として最重要事項です。IDC によれば、保存データは 2024 年までに 17.8% 増加するとされており、HDD はメインのストレージ技術として今後も活用されます。
Google Cloud は、運用中の HDD を管理し、潜在的な障害を事前に特定することの重要性を身をもって理解しています。Google は、世界最大規模のデータセンターを運用する責任を担っています。このような障害を適切なタイミングで特定できなかったとしたら、多くの Google プロダクトやサービスで深刻な停止が発生してしまいかねません。これまでは、問題を示すフラグがディスクに立てられた場合の主な対応策といえば、ソフトウェアを使用して現場でその問題を修復することでした。しかし、この作業には費用と時間がかかります。ドライブからデータを抜き出してドライブを分離し、診断を実行してから、トラフィックに再度戻す必要がありました。
そこで、Google のデータセンターの HDD の相手先ブランド製品製造企業(OEM)パートナーである Seagate と協力して、頻繁に発生する HDD の問題の予測手法を模索しました。そして両者は、障害が繰り返し発生するディスク(障害が発生するディスク、または 30 日間で 3 回以上の問題が発生するディスク)の確率を予測できる、Google Cloud 上に構築される機械学習(ML)システムを開発しました。
それでは見てみましょう。
数百万単位のディスクの管理は大変な作業
運用環境にデプロイされるディスクの数は数百万単位であり、そこから生成される生のテレメトリー データはテラバイト(TB)単位です。これには、毎時間生成される数十億行単位の SMART(Self-Monitoring, Analysis and Reporting Technology)データと、修復ログ、Online Vendor Diagnostics(OVD)や Field Accessible Reliability Metrics(FARM)のログ、各ディスク ドライブに関する製造データなどのホスト メタデータが含まれます。
すべての HDD で追跡およびモニタリングする必要のあるパラメータと因子は数百に及びます。今日のエンタープライズ データセンターにあるドライブの数を考えると、人力だけでこれらすべてのデバイスをモニタリングすることは事実上不可能です。
この問題を解決するために、Google のデータセンターの HDD の状態を予測する機械学習システムを構築しました。
予測メンテナンス システムによるリスクと費用の削減
Google Cloud AI サービスチーム(プロフェッショナル サービス)は Accenture と協力し、Seagate による最も一般的な 2 つのドライブタイプに基づいた概念実証の構築をサポートしました。
この ML システムは、次の Google Cloud プロダクトとサービスをベースとして構築されました。
Terraform。Google Cloud でのインフラストラクチャの構成、リソースの管理に使用しました。
Google の内部テクノロジー。これにより、データファイルの Google Cloud への移行を実現できました。
BigQuery とDataflow。HDD の状態を示す元データ、特徴(トレーニングと予測に使用)、ラベル、予測結果、メタデータなど、TB 単位のデータの取り込み、読み込み、変換、保存に使用できる高度にスケーラブルなデータ パイプラインを構築できました。
時系列予測 ML モデルの構築、トレーニング、デプロイには以下のプロダクトを使用しました。
AutoML Tables。ML モデルのテストおよび開発用
Cloud AI Platform でトレーニングされた Custom Transformer ベースの Tensorflow モデル
データポータルと BigQuery の UI ビュー。これにより、経営幹部、マネージャー、アナリストと結果を簡単に共有できました。
Composer、Cloud Functions、Google Cloud オペレーション スイート。エンドツーエンドの自動化とモニタリングに使用しました。
これまでは、ディスクの問題にフラグが立てられた場合の主な修正方法といえば、ソフトウェアを使用して現場でそのディスクを修復することでした。しかし、この作業には費用と時間がかかります。ドライブからデータを抜き出してドライブを分離し、診断を実行してから、トラフィックに再度戻す必要がありました。
「データの取り込みからモデルのトレーニング、検証、デプロイまで、Google Cloud プロダクトを使用したエンドツーエンドの自動 MLOps は、このプロジェクトに大きな価値をもたらしました」と、Seagate のデータおよび分析担当ディレクター、Vamsi Paladugu 氏は語ります。
Paladugu 氏は以下のように付け加えます。「Terraform と DevOps プロセスを使用したコードとしてのインフラストラクチャの自動実装、Seagate のセキュリティ ポリシーとの調整、インフラストラクチャの設計とセットアップの完璧な実行は称賛に値します。」
今では、HDD に修復のフラグが立てられると、修復前にモデルによってディスクに関するデータ(SMART データや OVD のログなど)が取得されます。モデルはこれを活用して、繰り返し発生する障害の確率を予測します。
データが鍵 - 強力なデータ パイプラインの構築
デバイスデータをインフラストラクチャや高度な分析ツールで活用できるようにすることは、あらゆる予測メンテナンス戦略において重要となります。
すべてのディスクは、将来の状態をモニタリングおよび予測するために、パフォーマンスと健全性に関する数百単位の特徴を継続的に測定する必要があります。これを実現するためには、次のようなさまざまなデータソースのバッチ データプロセスとストリーミング データプロセスの両方でスケーラブルで信頼性の高いデータ パイプラインを構築する必要がありました。
緊急性の高いハードウェア障害を検出して予測する、ストレージ デバイスの SMART システム インジケータ。
ホストデータ。複数のドライブで構成されるホストシステムから収集される、障害に関する通知など。
HDD ログ(OVD および FARM データ)とディスク修復ログ。
各ドライブの製造データ。モデルタイプやバッチ番号など。
重要な注意事項: このプロセス中に Google がユーザーデータを共有することはありません。
元データの量は膨大です。そのため、ML モデルの精度とパフォーマンスを確保できる適切な特徴を抽出する必要がありました。このプロセスは、AutoML Tables の自動特徴量エンジニアリングで簡素化できました。自分たちで行ったのは、データ パイプラインを使用して元データを AutoML 入力形式に変換することだけでした。
行から列へのピボット、正規化されたテーブルの結合、ラベルの定義といった単純な変換は、データがペタバイト規模であっても BigQuery を使用してわずか数秒で簡単に実行できました。その後、このデータは AutoML Tables に直接インポートされ、ML モデルのトレーニングと提供に使用されました。
適切なアプローチの選択 - 2 種類のモデルのテスト
パイプラインが完成したので、次はモデルを構築します。時系列予測モデルを構築するための 2 種類の手法をテストしました。1 つは AutoML Tables 分類器、もう 1 つはカスタムの Transformer ベースのディープモデルです。
AutoML モデルには、読み取りエラー率の最小、最大、平均など、時系列特徴のさまざまな集計を抽出させました。抽出後、これらの特徴は、時系列ではない特徴(ドライブのモデルタイプなど)と連結されました。トレーニング、検証、テストのサブセットは、時間ベースのスプリットを使用して作成しました。AutoML Tables では、データのインポート、統計の生成、さまざまなモデルのトレーニング、ハイパーパラメータ構成の調整、モデルのパフォーマンス指標の提供を簡単に行えます。また、オンライン予測を簡単に実行して一括処理できる API も用意されています。
比較のため、カスタムの Transformer ベースのモデルを Tensorflow を使用してゼロから作成しました。この Transformer モデルでは、特徴量エンジニアリングや特徴の集計の作成は必要ありませんでした。代わりに、未加工の時系列データがモデルに直接供給され、位置エンコードを使用して相対的な順序が保持されました。時系列ではない特徴は、ディープ ニューラル ネットワーク(DNN)に供給されました。その後、モデルと DNN の両方からの出力が連結され、シグモイド層がラベルの予測に使用されました。
どちらのモデルが優れていたか
AutoML モデルは、カスタムの Transformer モデルや統計モデルシステムよりも優れた成果を示しました。モデルをデプロイした後、予測をデータベースに保存し、30 日後、この予測を実際のドライブ修復ログと比較しました。AutoML モデルの場合の精度は 98% で、リコールは 35% でしたが、カスタム ML モデルの場合の精度は 70~80% で、リコールは 20~25% でした。また、繰り返し発生する障害の背後にある主要な原因を特定し、現場チームによる予防措置を講じてオペレーション中の障害発生を事前に削減することで、この方法を説明できました。
最重要ポイント: MLOps は本番環境の成功を握る鍵
堅牢で繰り返し利用可能な機械学習パイプラインをデプロイするために最後に必要なものは、MLOps です。Google Cloud は、MLOps の実装に役立つ複数のオプションを提供しており、自動化を使用して、プロジェクトに大きな価値をもたらすエンドツーエンドのライフサイクルをサポートしています。
このプロジェクトでは、Terraform を使用してインフラストラクチャを定義およびプロビジョニングし、GitLab を使用してソース管理、バージョニング、CI / CD パイプラインの実装を行いました。
Google のリポジトリには開発と本番用の 2 つのブランチが含まれており、これは Google Cloud の環境と対応しています。以下は、トレーニングと提供のためのモデル パイプラインのシステム設計の概要です。
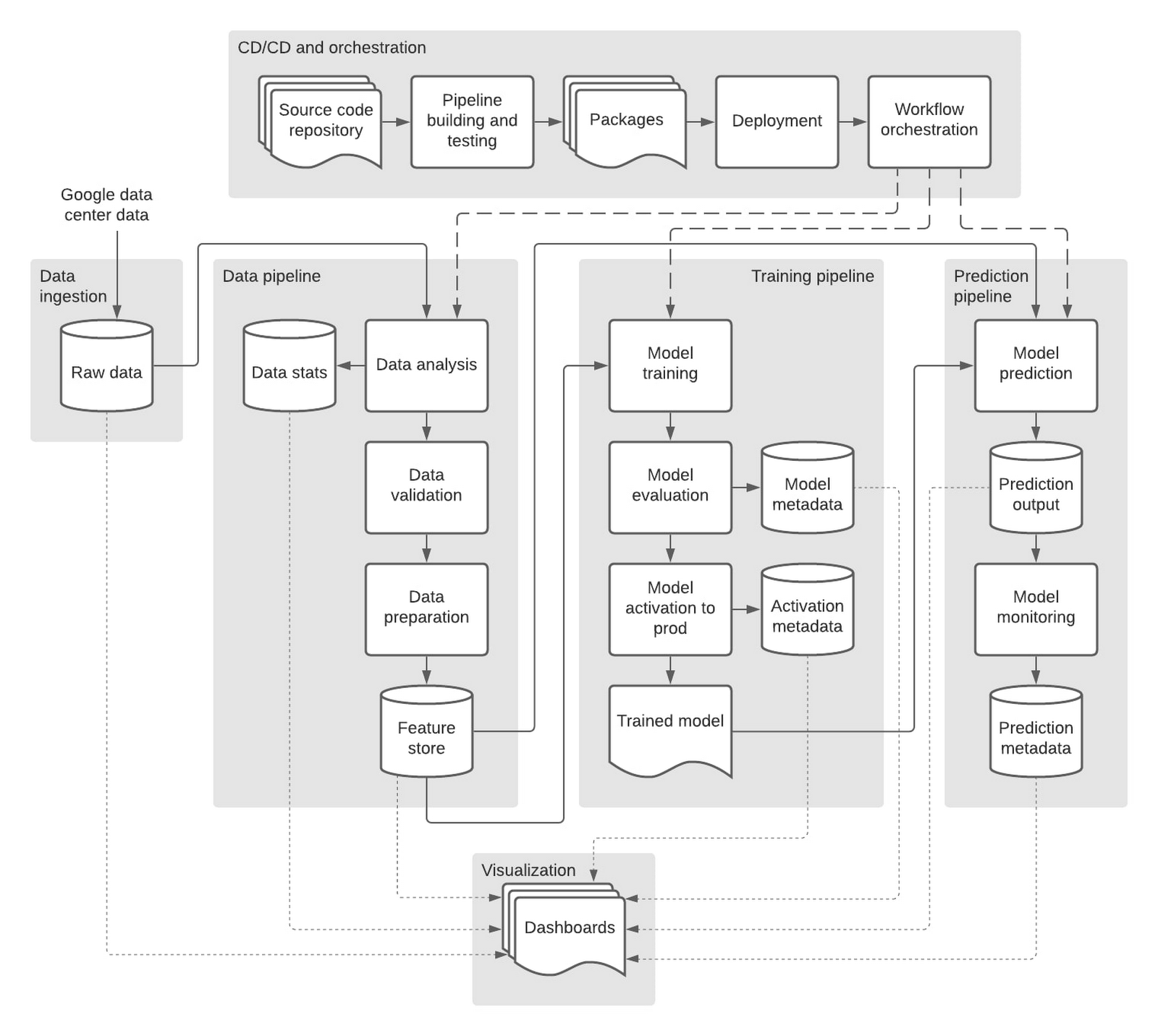
Google のフルマネージド ワークフロー オーケストレーション サービス、Cloud Composer を使用して、上述したすべてのデータ、トレーニング、モデル提供パイプラインをオーケストレーションしました。ML エンジニアは、パフォーマンス トレーニング済みモデルを評価した後、メタデータ テーブルにエントリを追加するだけで、モデルを本番環境に移行させるアクティベーション パイプラインをトリガーできます。
「Google の MLOps 環境で、データ取り込みからモニタリングが容易なエグゼクティブ ダッシュボードまで、終始シームレスで完璧なエクスペリエンスを構築できました」と、Seagate の品質データ分析、ツール、自動化担当ディレクターの Elias Glavinas 氏は語ります。
また、Glavinas 氏は次のようにも述べています。「また特に、AutoML Tables によってデータ サイエンスの分野で時間とリソースを大幅に節約できることがわかりました。このプロダクトでは自動特徴量エンジニアリングやハイパーパラメータ調整が可能であり、そのモデルの予測結果は、弊社のデータ サイエンティストの手動による予測結果と同等かそれ以上でした。モデルの再トレーニングとデプロイも簡単に自動で行えます。このプロジェクトは非常に満足のいくものとなりました。」
今後の予定
ビジネスの観点から見れば、ML ベースのシステムを使用して HDD の障害を予測する必要性は高まる一方です。エンジニアが障害のあるディスクを特定するための手段が増えれば、費用を削減できるだけでなく、エンドユーザーに悪影響が及ぶ前に問題を防止することもできるようになります。Google は、Seagate のすべてのドライブをサポートするようにシステムを拡張する予定です。これが OEM やお客様にどのように役立つか、楽しみにしています。
謝辞
GCP インフラストラクチャを実装し、重要なデータ取り込みセグメントを構築してくれた Anuradha Bajpai、Kingsley Madikaegbu、Prathap Parvathareddy に感謝します。また、プロジェクト全体にわたってサポートと指導をしてくれた Chris Donaghue、Karl Smayling、Kaushal Upadhyaya、Michael McElarney、Priya Bajaj、Radha Ramachandran、Rahul Parashar、Sheldon Logan、Timothy Ma、Tony Oliveri に、特に大きな感謝を捧げます。そして、このプロジェクトの成功に協力していただいた、Seagate チーム(Ed Yasutake 氏、Alan Tsang 氏、John Sosa-Trustham 氏、Kathryn Plath 氏、Michael Renella 氏)と Accenture のパートナー チーム(Aaron Little 氏、Divya Monisha 氏、Karol Stuart 氏、Olufemi Adebiyi 氏、Patrizio Guagliardo 氏、Sneha Soni 氏、Suresh Vadali 氏、Venkatesh Rao 氏、Vivian Li 氏)にも、この場を借りてお礼を申し上げます。
-テクニカル プログラム マネージャー Nitin Aggarwal
-AI エンジニア Rostam Dinyari



