Gemini の教師ありファインチューニング: ベスト プラクティス ガイド
Erwin Huizenga
AI engineering and evangelism manager
Bethany Wang
Staff Software Engineer and Manager, Google Cloud
※この投稿は米国時間 2025 年 1 月 8 日に、Google Cloud blog に投稿されたものの抄訳です。
Gemini などの基盤モデルは人間の働き方を大きく進化させましたが、特定のビジネスタスクでは、ガイダンスがなければ優れた結果を出すことができない場合もあります。たとえば、回答が長すぎる場合や、要約が的外れである場合などです。こうしたケースで威力を発揮するのが、教師ありファインチューニング(SFT)です。適切に機能すれば、特殊なタスク、分野、さらには文体のニュアンスに合わせて、驚くべき精度で Gemini をカスタマイズできます。
以前のブログでは、SFT を使用すべき状況について取り上げ、モデルの出力を最適化するためのその他の手法との比較を示しました。今回のブログでは、デベロッパーが SFT プロセスを効率化するための次のような方法について掘り下げます。
-
最適なモデル バージョンの選択
-
質の高いデータセットの作成
- 問題を診断して修正するためのツールを含む、モデル評価のベスト プラクティス
1. ベースラインを定めてモデルを選択する
ファインチューニングの前に基盤モデルを代表的なデータセットで評価し、改善点を定量化します。これにより、初期の機能を把握し、目指すべき改善領域を特定できます。主な分析対象は次の 3 つです。
-
初期のパフォーマンス: トレーニングなしのモデル(ゼロショット)のパフォーマンスと、可能であればいくつかのサンプルを提示したモデル(少数ショット)のパフォーマンスを評価します。
-
指標: 完全一致、BLEU、ROUGE など、特定のタスクに合致した評価指標を選択します。
-
データ: 対象のモデルに入力される実際のデータを代表するような、多様性のある評価データセットを使用します。
モデルが適切に機能しない場合は特に、これらのベースラインの結果を分析することが、効果的なファインチューニング戦略の定義に欠かせません。Gemini をファインチューニングする場合、次のいずれかのモデルを選択できます。
-
Gemini 1.5 Pro: 一般的なパフォーマンスに最適な Google のモデル。
-
Gemini 1.5 Flash: 費用対効果と低レイテンシを重視して設計された Google のモデル。
最適なモデルを選択するには、主に次の 2 つの点について検討する必要があります。
-
モデルとユースケースを一致させる: SFT を使い始める前に、まず必要な機能を最も簡単に実現できるモデルを選びます。アプリケーションに高い精度と複雑な推論が必要な場合は、まず Gemini Pro を選ぶとよいでしょう。これが問題なく機能したら、費用についての検討を開始します。たとえば、レイテンシを改善し、推論の費用を削減するために、Flash で SFT を試してもよいでしょう。
-
モデルをデータで効率的に改善する: ほとんどの場合、Gemini Pro などの大規模モデルをファインチューニングする前に、Gemini Flash などの小規模で比較的費用の安いモデルでチューニング データをテストした方がよいでしょう。これにより、モデルのパフォーマンスがデータによって実際に改善していることを確認できます。パフォーマンスが不十分な場合は、いつでも大規模モデルに切り替えられます。チューニング データで小規模なモデルの精度を効果的に高めることができた場合、データの質が高いことを意味し、このデータによって大規模モデルも効果的にチューニングできる可能性が高いと考えられます。
データの検討
SFT とは、単にラベル付きデータをモデルに放り込むものではありません。適切な選択が欠かせない、細やかなプロセスです。特定のタスク向けに基盤モデルを調整する場合、ラベル付きデータセットでそのモデルをファインチューニングします。このデータセットには、入力(収益レポートなど)と目的とする出力(要約など)が含まれています。
ML が成功するかどうかはデータ次第です。教師ありファインチューニングの成功は、チューニング データの質に大きく依存しています。以降では、参考にしていただきたい重要なガイドラインをご紹介します。
質か量か
トレーニング データの質と量のバランスを取ることが重要です。Vertex AI では Low-Rank Adaptation(LoRA)によって効率的にファインチューニングを行い、元のモデルの重み付けを固定し、トレーニング可能な行列を挿入して、少数のトレーニング可能パラメータでモデルの動作を効果的に調整します。その結果、ファインチューニングが高速になり、リソースが減少し、大規模なデータセットへの依存度が低下します。
次のような質の高いサンプルを重視してください。
-
関連性が高い: 特定のファインチューニング タスクと緊密に関係している。
-
多様性がある: 考え得る幅広い入力とシナリオに対応している。
-
精度が高い: 正確なラベルと出力を備えている。
データを増やすとモデルが改善する可能性がありますが、必要なトレーニング エポックが少なくなり、ある時点から効果が上がらなくなることが珍しくありません。同じクラスタで何度もチューニングしても意味がありません。多くの場合、小規模な調整済みの代表的なデータセットの方が、大規模でノイズの多いデータセットよりも高いパフォーマンスを発揮します。小規模なデータセットには過学習のリスクがあるため、エポックの数を調整するとよいでしょう。まずは 100 個程度のサンプルから始めて、チューニングの効果を確認しましょう。それからスケールアップして、その他のコーナーケースやカテゴリに対応していきます。
データの前処理
大規模言語モデル(LLM)の教師ありファインチューニング用データの準備では、前処理が重要なステップです。こちらの調査で、重要な前処理ステップの一つが重複除去であることが判明しています。重複除去では、重複したデータポイントを特定して削除します。トレーニング データに重複したサンプルがあると、いくつかの問題が発生するおそれがあります。たとえば、一般化を妨げる記憶化や、モデルが類似クラスタから重複して学習することによる非効率的なトレーニングなどです。トレーニング セットと検証 / テストセットの間でサンプルを重複させたり、ほぼ重複させたりするとデータ リーケージが発生し、パフォーマンスが人為的に上昇します。
重複除去には、完全一致、ファジー一致、クラスタリングなどの手法を利用します。ExactSubstr 重複除去などのツールを利用することで、大規模なデータセットを効率的に処理できます。さらに、データの多様性とモデルの堅牢性を向上させるデータの拡張を検討することもできます。
前処理は、ファインチューニングされたモデルのパフォーマンスの評価にも役立ちます。たとえば、大文字と小文字を区別したり、不要な空白文字を削除したり、句読点を処理したりできます。
2. データセットに指示を追加する
ファインチューニング データセットに指示を含めることで、パフォーマンスが向上します。モデルが特定の指示に基づいて出力を条件付けするよう学習するため、目的のタスクを実行する能力が高まり、類似した未知の指示に対して一般化できるようになります。その結果、推論時の長い複雑なプロンプトの必要性が低減します。主な手法はシステム指示とテキスト プロンプトの 2 つで、両方ともオプションですが、パフォーマンスの改善につながります。
システム指示はグローバル ディレクティブを指定し、回答のスタイル全体を形作ります。たとえば、「JSON 形式で回答して」と指示すると出力が構造化され、「あなたはバイオインフォマティクスの専門家です」と指示すると回答の分野が設定されます。
インスタンス レベルの指示では、サンプル固有のガイダンスがモデルの入力内に埋め込まれます。たとえば、「次の研究論文の要約を、手法と主な結果に焦点を当てて作成して」と指示すると、モデルは特定の情報を抽出します。
Gemini のプロンプト戦略などのリソースを参考にして、さまざまな指示スタイルをテストすることが重要です。テストする場合は、データセットに指示を追加する前に Gemini モデルにプロンプトを指定します。少数ショットのサンプルをデータセットに追加しても、さらなるメリットは得られません。重要な点は、ファインチューニング データセットで使用するプロンプトと指示を、本番環境で使用する予定のものに類似させることです。最適なパフォーマンスを達成するうえで、この調整が欠かせません。
トレーニング サービング スキュー
ファインチューニングの効果に影響を与える重要な要因は、チューニング データと本番環境データの連係です。形式、コンテキスト、サンプルの分布などの面で相違があると、モデルのパフォーマンスが大幅に低下することがあります。たとえば、チューニング データがフォーマルな言語のサンプルで構成されており、本番環境データにインフォーマルなソーシャル メディアのテキストが含まれている場合、モデルで感情分析を適切に処理できない可能性があります。これを回避するには、トレーニング データと本番環境データを慎重に分析します。データの拡張やドメイン適応などの技術によって、さらにギャップを埋め、本番環境におけるモデルの一般化機能を向上させることができます。
複雑なサンプルの重視
ファインチューニングを実行する際に、すべてのデータをモデルに放り込み、後は最善の結果を祈りたいという誘惑にかられるかもしれません。しかし、ベースモデルで適切に処理できないようなサンプルを重視した方が、より戦略的です。
この場合、モデルがどの領域をうまく処理できないかを特定します。こうした難しいサンプルを含むデータセットを作成すれば、少ないデータでより大きな改善を達成できます。この対象を絞り込んだアプローチにより、パフォーマンスが向上するだけでなく、ファインチューニング プロセスの効率化も実現できます。ベンチマーク プロセスでは、多様なデータセットでモデルのパフォーマンスを分析します。モデルが特定のタスク、形式、推論能力を適切に処理できていないサンプルを特定してください。続けて、それらのサンプルをトレーニング データセットに追加します。さらに別のサンプルも見つけて評価データセットに追加すると、リーケージを回避できます。
検証データセットの重要性
ファインチューニング プロセスでは、常に適切に構造化された検証データセットを使用するようにしてください。この分離したラベル付きデータセットは、トレーニング中にモデルのパフォーマンスを評価するための独立したベンチマークの役割を果たします。これにより過学習を特定し、トレーニングを停止するエポックを選択でき、モデルが未知のデータに対して適切に一般化できるようになります。検証データセットは、推論中に使用される実際のデータを代表するものである必要があります。
データ形式
教師ありファインチューニングでは、モデルは入出力ペアのラベル付きデータセットから学習します。Gemini で SFT を使用するには、特定の JSONL ファイル形式のデータが必要です。データセットに指示を追加すると、ファインチューニング プロセスでモデルを導くことができます。systemInstruction とその他の指示を contents フィールドに追加し、それぞれに会話フローと内容を表す role と parts を含めることができます。この処理は、JSON ファイルの各行(サンプル)で行います。たとえば、systemInstruction で LLM のペルソナを指定し、contents にユーザーのクエリと望ましいモデルの回答を含めることができます。正しい形式で適切に構造化されたデータセットは、ファインチューニング時の効果的な知識の引き継ぎとパフォーマンス改善に不可欠です。次に示すのは、データセットに必要な形式の例(データポイント)です。
3. ハイパーパラメータとパフォーマンス
ファインチューニングを開始する際に重要なのが、適切なハイパーパラメータを選択することです。ハイパーパラメータとは、大規模言語モデルのトレーニング プロセスを管理する外部の構成設定であり、特定のタスクにおけるモデルの最終的なパフォーマンスを決定する要素です。Gemini をファインチューニングする場合、以降のガイダンスに従ってハイパーパラメータ(エポック、学習率の乗数、アダプタサイズ)を設定してください。
Gemini 1.5 Pro
-
テキストのファインチューニング: データセットのサイズが 1,000 サンプル未満で、平均的なコンテキストの長さが 500 未満の場合、エポックを 20、学習率の乗数を 10、アダプタサイズを 4 に設定することをおすすめします。データセットのサイズが 1,000 サンプル以上または平均的なコンテキストの長さが 500 以上の場合は、エポックを 10、学習率の乗数をデフォルトまたは 5、アダプタサイズを 4 に設定するとよいでしょう。
-
画像のファインチューニング: データセットのサイズが 1,000 サンプル程度の場合は、まずエポックを 15、学習率の乗数を 5、アダプタサイズを 4 に設定します。1,000 サンプル未満の場合はエポックの数を増やし、1,000 サンプルを超える場合はエポックの数を減らします。
-
音声のファインチューニング: エポックを 20、学習率を 1、アダプタサイズを 4 に設定することをおすすめします。
Gemini 1.5 Flash
-
テキストのファインチューニング: データセットのサイズが 1,000 サンプル未満で、平均的なコンテキストの長さが 500 未満の場合、エポックをデフォルト、学習率の乗数を 10、アダプタサイズを 4 に設定することをおすすめします。データセットのサイズが 1,000 サンプル以上または平均的なコンテキストの長さが 500 以上の場合は、エポックをデフォルト、学習率の乗数をデフォルト、アダプタサイズを 8 に設定するとよいでしょう。
-
画像のファインチューニング: データセットのサイズが 1,000 サンプル未満で、平均的なコンテキストの長さが 500 未満の場合、エポックを 15 以上(サンプル数が少ない場合は増やします)、学習率の乗数を 5、アダプタサイズを 16 に設定することをおすすめします。データセットのサイズが 1,000 サンプル以上または平均的なコンテキストの長さが 500 以上の場合は、エポックを 15 以下(サンプル数が多い場合は減らします)、学習率の乗数をデフォルト、アダプタサイズを 4 に設定するとよいでしょう。
-
音声のファインチューニング: エポックを 20、学習率を 1、アダプタサイズを 4 に設定することをおすすめします。
自動音声認識(ASR)などの音声のユースケースでは、最適な結果を得るために、エポックをさらに増やす必要がある場合があります。まずは前述のように設定し、ご自身の評価基準に応じてエポックの数を増やしてください。
最初の実行を終えたら、ハイパーパラメータを調整し、主要なトレーニング指標と評価指標を注意深くモニタリングして、イテレーションします。ファインチューニングでモニタリングすべき主な指標は次の 2 つです。
-
損失の合計: 予測値と実際の値の差異を測定します。トレーニングの損失が減少している場合、モデルが学習していることを意味します。検証の損失を観測することも重要です。トレーニングの損失よりも検証の損失の方が大幅に多い場合、過学習が考えられます。
-
正しい次のステップを予測した割合: 次のステップを順番に予測するモデルの精度を測定します。この指標は、逐次予測におけるモデルの精度の向上を反映し、時間の経過に応じて増加していくはずです。
トレーニング データセットと検証データセットの両方についてこれらの指標をモニタリングし、その他の関連指標も考慮しながら、タスクに応じた最適なパフォーマンスを発揮できるようにしてください。ファインチューニング ジョブをモニタリングする場合、Google Cloud コンソールまたは TensorBoard を使用します。これらの指標の「理想的」なシナリオは、次のようなものです。
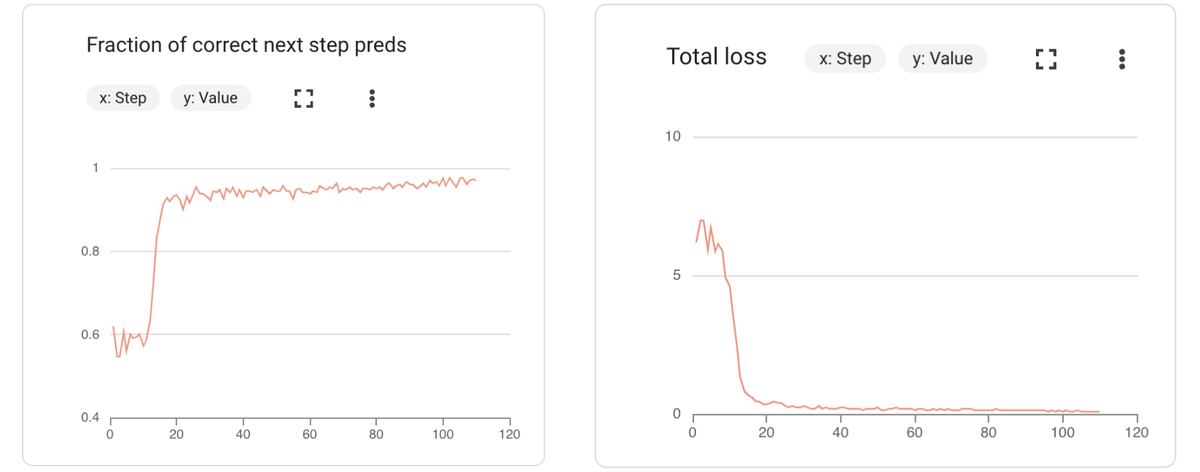
これらは単にスタート地点であることを忘れないでください。特定のファインチューニング タスクに最適なハイパーパラメータを見つける鍵は「テスト」です。ファインチューニングのテストのパフォーマンスに応じて、以降で説明するおすすめのステップのいずれかを取り入れてもよいでしょう。
パフォーマンスが最適ではない
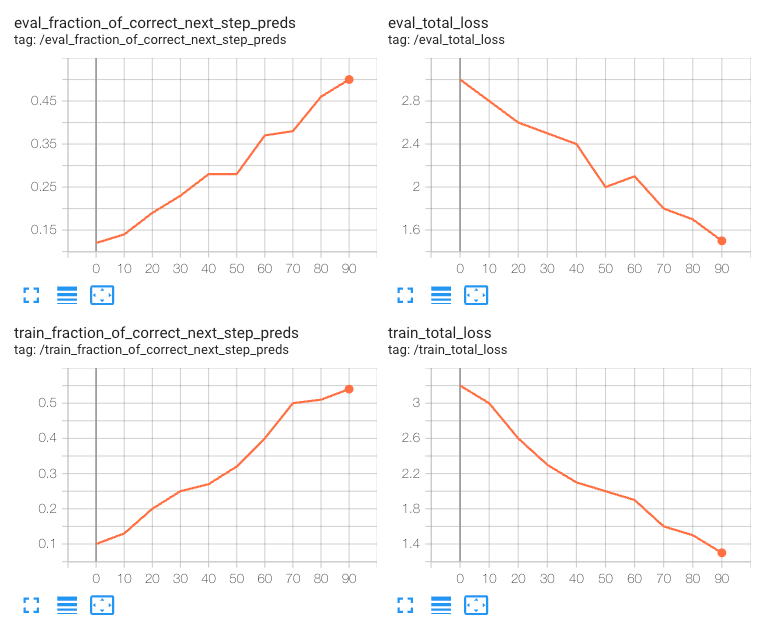
特定する方法: トレーニングの損失と検証の損失はトレーニングが進むにつれて減少しているが、検証の損失が収束または最小値に到達していない。
考えられる原因: トレーニング データセットが小さすぎる、または十分な多様性を備えていないため、対象のモデルが対応する実際のシナリオを表現できていない可能性がある。
緩和する方法: エポックの数または学習率の乗数を増やし、トレーニングを高速化する。これで解消しない場合は、より多くのデータを収集する。
過学習
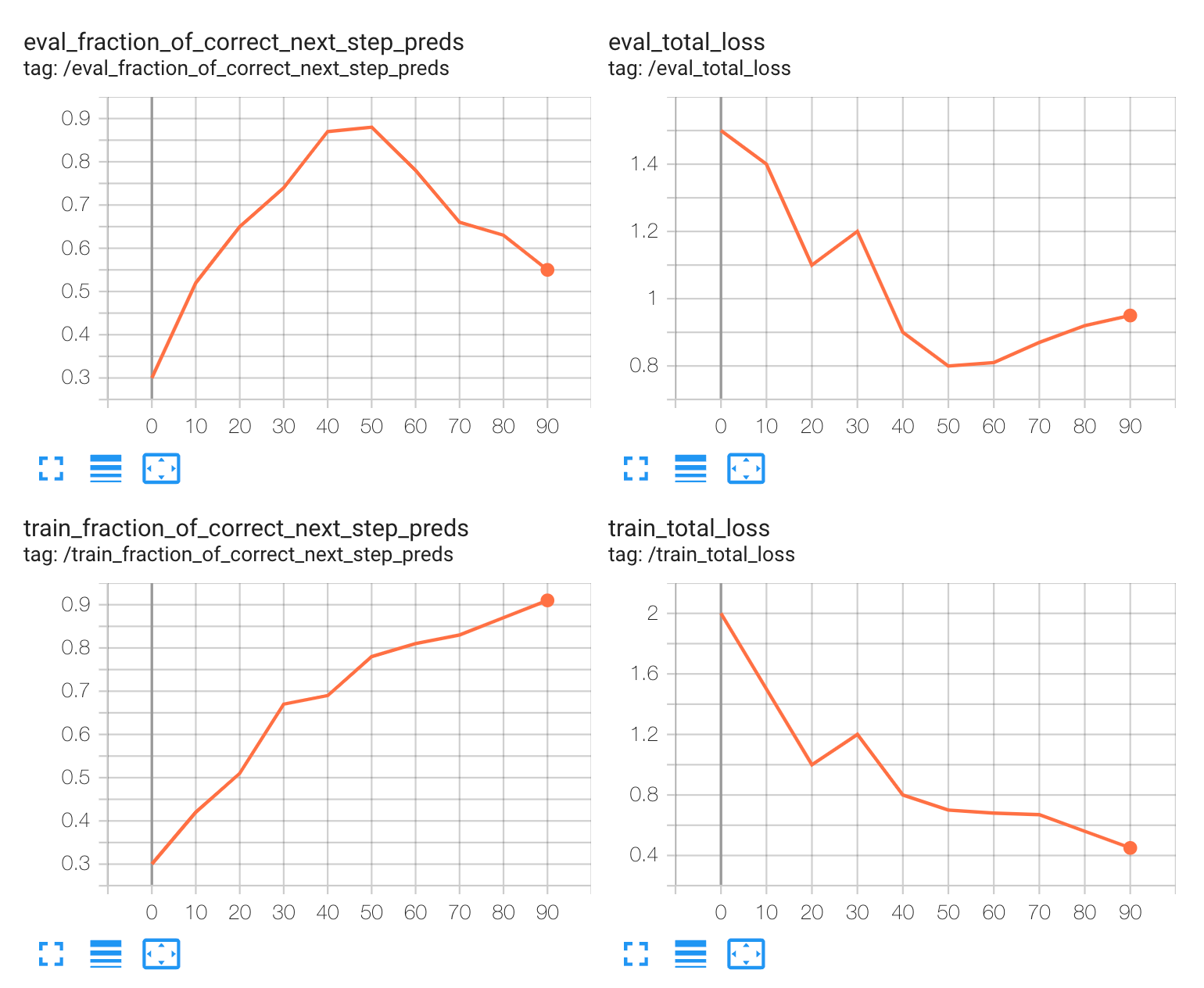
特定する方法: トレーニング中はトレーニングの損失が一貫して減少しているが、検証の損失は最初だけ減少し、その後増加し始めている。この相違は、モデルがトレーニング データを学習しすぎて、新しいデータに対して一般化できていないことを意味する。
原因: モデルのキャパシティが、トレーニング データのサイズと複雑さに比して多すぎる(例: レイヤまたはパラメータが多すぎる)。
緩和する方法: 検証の損失が最小値に到達するまでエポックの数を減らす。または、トレーニング データの有効サイズと多様性を増やす。
データに問題がある可能性がある
特定する方法: トレーニング データの初期の損失が非常に大きい(10 を超える)場合、モデルの予測がラベルからかけ離れていることを意味する。
原因: トレーニング データセットに問題がある可能性がある。典型的な例は、入力の長さがコンテキストの長さの最大値を超え、切り捨てられるというもの。
緩和する方法: トレーニング データセットが前のセクションのベスト プラクティスに確実に従っていることを再確認する。
モデルを評価する
ファインチューニングされた言語モデルのパフォーマンスの評価は、そのパフォーマンスの把握、チェックポイントの選択、ハイパーパラメータの最適化に不可欠です。生成モデルの出力は自由で創造的なものが多いため、こうしたモデルの評価は困難になる可能性があります。パフォーマンスを包括的に把握するには、さまざまな評価アプローチを組み合わせるとよいでしょう。主に、場合によっては人間の評価で調整される、自動指標とモデルベースの評価を取り混ぜて利用します。
自動指標: この指標は、モデルの出力とグラウンド トゥルースを比較して定量的な測定値を算出します。事実性などの細やかな側面を取り込むことはできないかもしれないですが、次の性質によって価値の高いものとなっています。
-
高速: 自動指標の計算は安価で高速。
-
客観性: 一貫性と客観性のある測定値を算出するため、信頼性の高い進捗トラッキングとモデル比較が可能。
-
解釈可能性: 精度、F1 スコア、BLEU などの指標は幅広く認識されており、結果を即座に解釈可能。
タスクに応じた適切な自動指標を選択することが重要です。たとえば、次のような自動指標です。
-
BLEU スコア(翻訳と要約): 生成されたテキストと参照テキストの間の n グラム適合率を、精度に焦点を当てて測定。
-
ROUGE(要約): 再現率を重視して n グラム適合率を評価。
モデルベースの指標: この手法では、言語モデルを判定ツール(自動評価ツール)として利用し、生成された出力の質を定義済みの基準に基づいて評価します。これは、タスク評価ルーブリックにより近いものです。たとえば、モデルベースの評価を使用して、回答の事実の正確性や論理的整合性を評価できます。
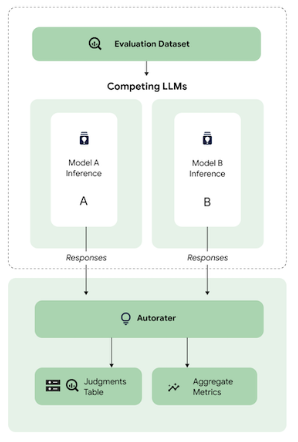
人間による評価: 人間による判断が基本であることに変わりはありませんが、費用が高くスケーラビリティに制限があるため、ファインチューニングで継続的に人間が評価を行うことはあまり現実的ではありません。代わりに、人間の評価を使用してモデルベースのエバリュエータ(自動評価ツール)を調整するという戦略を採用できます。この場合、小規模でも質の高い、人間による評価のデータセットを収集し、その判断を模倣するように自動評価ツールをトレーニングします。その後は、チューニング プロセスでは自動評価ツールを利用し、最後の検証ラウンドでは人間が評価を行って、選択したチェックポイントが目的の品質基準を満たすようにします。
次のステップ
ご関心をお持ちの場合は、生成 AI リポジトリにアクセスし、教師ありファインチューニングの使用方法などのノートブックをご覧ください。Vertex AI で SFT の変革の可能性を体感し、AI アプリケーションをカスタマイズして最高のパフォーマンスを実現してください。
Gemini モデルのファインチューニングが目的の方は、Vertex AI ドキュメントでカスタマイズ可能なモデルをご確認ください。
生成 AI とファインチューニングについて詳しくは、5 日間の生成 AI 集中コースをご覧ください。
今回協力してくれた Google Cloud の May Hu、Yanhan Hou、Xi Xiong、Sahar Harati、Emily Xue、Mikhail Chrestkha に感謝します。
-Google Cloud、ML 担当エンジニア Erwin Huizenga
-Google Cloud、スタッフ ソフトウェア エンジニア兼マネージャー Bethany Wang



