Cluster Director による AI および HPC クラスタ自動化の一般提供を開始
Ilias Katsardis
Sr. Product Manager, Cluster Director, Google Cloud
Jason Monden
Group Product Manager, AI Infrastructure, Google Cloud
※この投稿は米国時間 2025 年 12 月 18 日に、Google Cloud blog に投稿されたものの抄訳です。
AI トレーニング ワークロードとハイ パフォーマンス コンピューティング(HPC)ワークロードを支えるインフラストラクチャの複雑さは、チームの作業ペースを低下させる可能性があります。Google Cloud において、世界最大規模の AI 研究チームとの共同作業を重ねる中で、あらゆる場面でそのような状況を目にしています。たとえば、複雑な構成ファイルという障壁にぶつかっている研究者、自社開発スクリプトによる GPU の管理に苦労しているプラットフォーム チーム、数週間に及ぶトレーニング実行を阻む予測不能なハードウェア障害に絶えず奮闘している運用管理者などです。物理的なコンピューティングの利用だけでは十分ではありません。最先端の技術を利用するには、ハードウェア障害を克服する信頼性、トポロジを尊重するオーケストレーション、拡大するニーズに適応するライフサイクル管理戦略が必要です。
このたび Google Cloud は、このような要求に応えるべく、Cluster Director の一般提供(GA)を開始し、Cluster Director サポートのプレビュー版(Google Kubernetes Engine(GKE)上の Slurm 向け)をリリースしました。
-
Cluster Director(GA)は、最新のスーパーコンピューティングの厳しい要件を満たせるように設計されたマネージド インフラストラクチャ サービスです。脆弱な DIY ツールの代わりに、トポロジを考慮した堅牢なコントロール プレーンを使用することで、最初のデプロイから 1,000 回目のトレーニング実行に至る Slurm クラスタのライフサイクル全体を処理します。
-
Google Cloud は、Cluster Director をさらに拡張して、GKE 上の Slurm のサポート(プレビュー版)を提供します。これにより、お客様は高パフォーマンス スケジューリングの慣れ親しんだ精度と Kubernetes の自動スケーリングという 2 つの強みを最大限に利用できます。これは、GKE ノードプールを Slurm クラスタの直接的なコンピューティング リソースとして扱い、既存の Slurm ワークフローを変更せずに Kubernetes のパワーでワークロードをスケーリングできるようにすることで実現されます。
Cluster Director の一般提供を開始
Cluster Director は、クラスタ ライフサイクルの各フェーズで高度な機能を提供します。フェーズには、インフラストラクチャの設計とキャパシティを決定する準備作業(0 日目)、クラスタが自動的にデプロイおよび構成されるデプロイ(1 日目)、パフォーマンス、ヘルス、最適化が継続的にトラッキングされるモニタリング(2 日目)があります。
この包括的なアプローチにより、お客様は詳細な構成が可能なインフラストラクチャのメリットを享受しながら、下位レベルのオペレーションを自動化して、コンピューティング リソースが常に最適化され、信頼性と可用性が確保されている状態を維持できます。
では、これらすべてにかかる費用はどれくらいになるでしょうか?最大のメリットはそこにあります。Cluster Director の使用に追加料金はかかりません。料金は、基盤となる Google Cloud リソース(コンピューティング、ストレージ、ネットワーキング)に対してのみ発生します。
Cluster Director によるデプロイの各フェーズのサポート
0 日目: 準備
通常、クラスタの立ち上げには数週間にわたるプランニング、Terraform のラングリング、ネットワークのデバッグが必要です。Cluster Director は、ワークロード要件に合わせて最適化されたインフラストラクチャ トポロジを設計するツールを備えており、「0 日目」の体験を完全に様変わりさせます。
Cluster Director は、0 日目のセットアップを効率化するため、以下を提供します。
-
リファレンス アーキテクチャ: Google の社内ベスト プラクティスを再利用可能なクラスタ テンプレートに体系化し、標準化された検証済みのクラスタを数分でスピンアップできるようにしました。これにより、組織内のすべてのチームが同じセキュリティ基準をデプロイに使用し、デフォルトで正しく構成されるインフラストラクチャ上で、ネットワーク トポロジやストレージのマウントにデプロイできるようになります。
-
ガイド付き構成: よく知られているように、オプションが多すぎると構成の停滞を招くことがあります。Cluster Director のコントロール プレーンは、効率化されたセットアップ フローを通してお客様をガイドします。お客様がリソースを選択すると、システムによって複雑なバックエンド マッピングが処理されます。これにより、デプロイに先立ってストレージ階層、ネットワーク ファブリック、コンピューティング シェイプの互換性が確保され、最適化されます。
-
広範なハードウェア サポート: Cluster Director は、大規模 AI システム向けのフルサポートを提供します。これには、NVIDIA GB200 および GB300 GPU を搭載した Google Cloud の A4X および A4X Max VM や、費用対効果の高いログインノードとデバッグ パーティションに適した N2 VM などの多目的 CPU が含まれます。
-
柔軟な使用オプション: Cluster Director は、重要なトレーニング実行時のキャパシティを確保する予約機能、動的スケーリング用の Dynamic Workload Scheduler Flex-start、低コストの随時実行に適した Spot VM をサポートしており、お客様が希望する調達戦略に合わせて柔軟に調整できます。
「Google Cloud の Cluster Director は、大規模な AI と HPC の環境を管理できるように最適化されており、NVIDIA の高速コンピューティング プラットフォームのパワーとパフォーマンスを補完する役割を果たします。私たちは互いに協力して、次世代のコンピューティングの課題に対処できる簡素化された強力でスケーラブルなソリューションをお客様に提供します。」- NVIDIA、高速コンピューティング プロダクト担当ディレクター、Dave Salvator 氏
1 日目: デプロイ
ハードウェアのデプロイとパフォーマンスの最大化はまったく別物です。1 日目は実行フェーズであり、お客様の構成が完全に動作するクラスタに変換されます。素晴らしいことに、Cluster Director は VM をプロビジョニングするだけでなく、ソフトウェアとハードウェアのコンポーネントが健全な状態にあり、適切にネットワーク化され、最初のワークロードを受け入れる準備ができているかどうかを検証します。
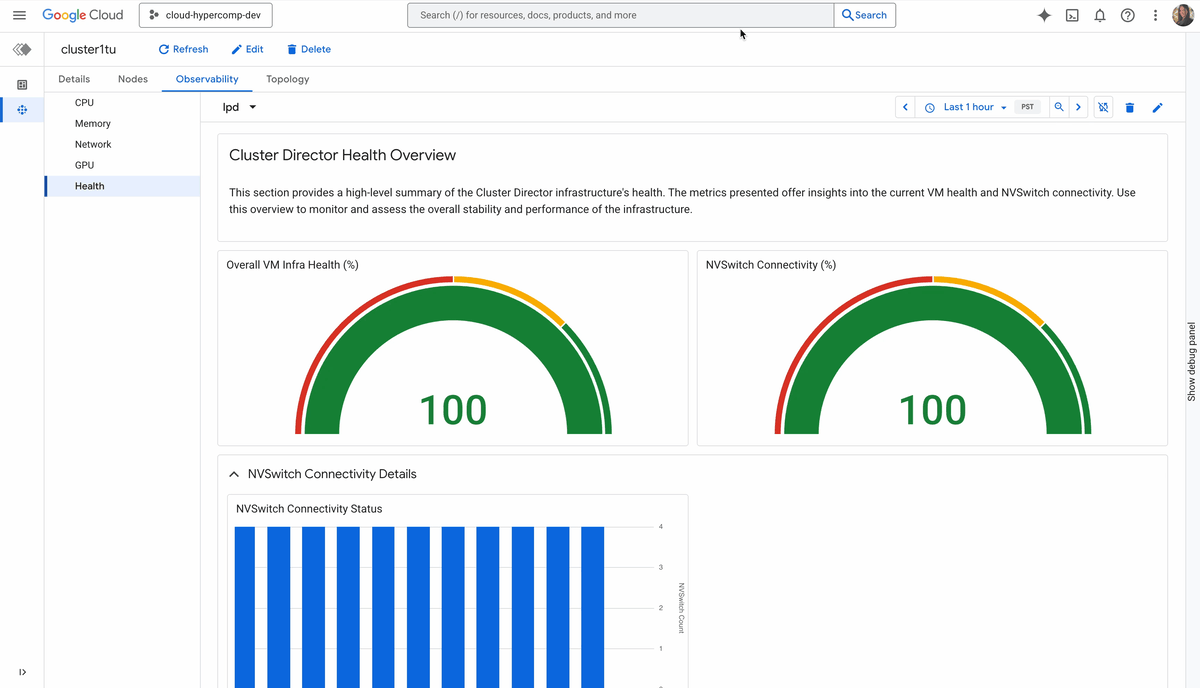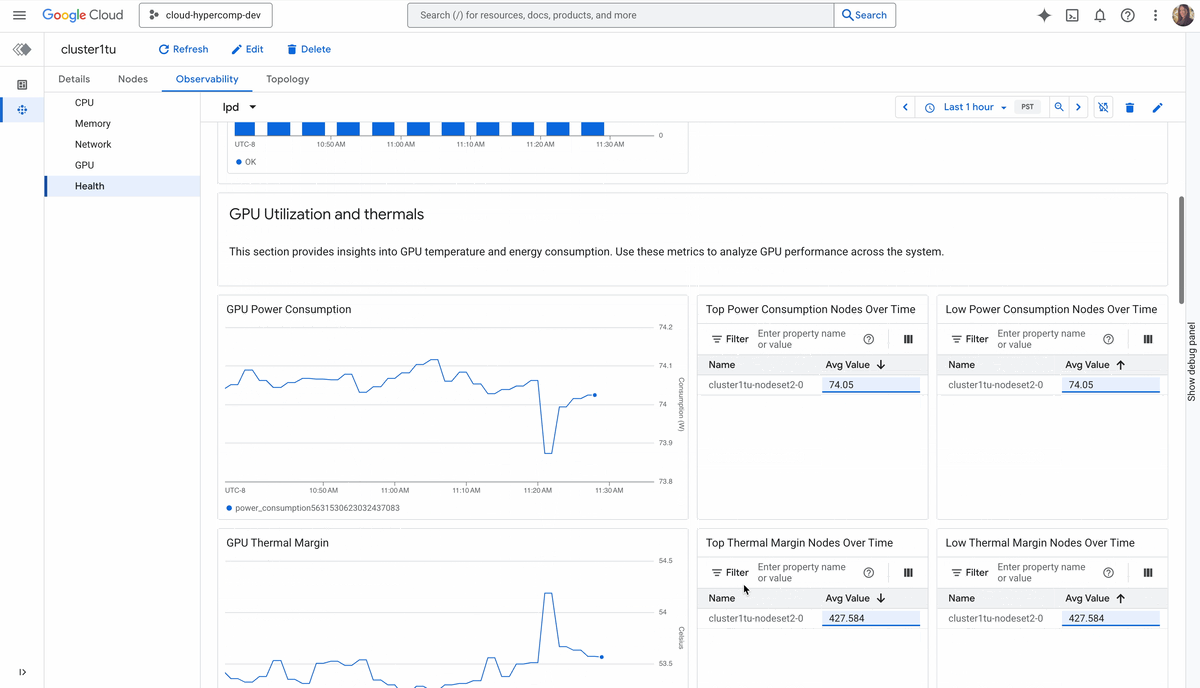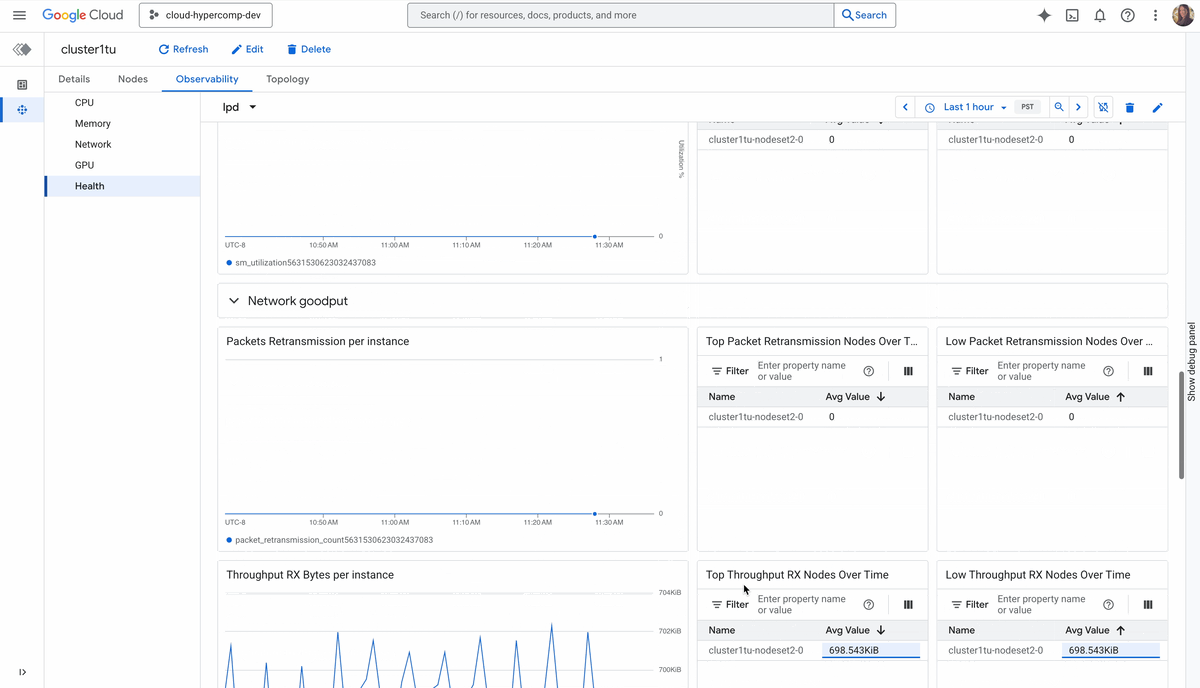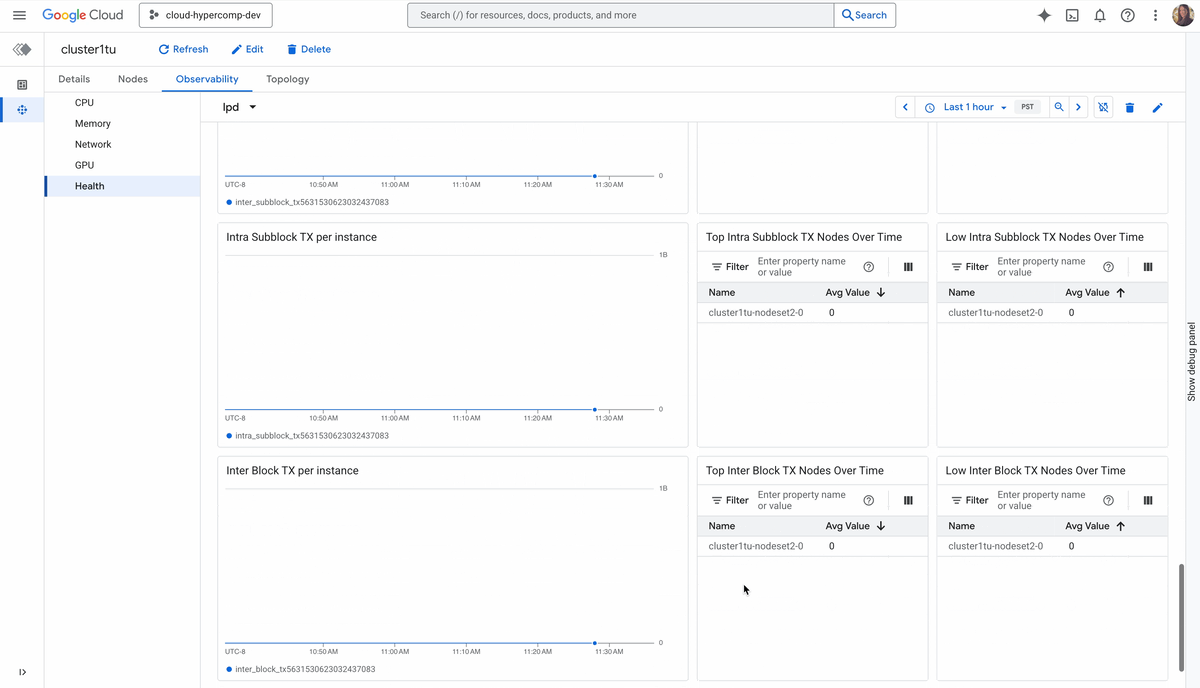
Cluster Director は、高パフォーマンスのデプロイを保証するために、以下を自動化します。
-
健全性の証明: Cluster Director は、ジョブが GPU に到達する前に、DCGMI 診断や NCCL パフォーマンス検証などの厳格なヘルスチェック スイートを実行し、ネットワーク、ストレージ、アクセラレータの完全性を検証します。
-
アクセラレータへの継続的なデータ供給: ストレージ スループットは、しばしばトレーニング効率を低下させる隠れた要因となります。そのため、Cluster Director はパフォーマンス階層の選択が可能な Google Cloud Managed Lustre を完全にサポートしています。高スループットの並列ストレージをコンピューティング ノードに直接接続できるため、GPU がデータ不足になることはありません。
-
相互接続のパフォーマンスの最大化: スケーリングを最大化するため、Cluster Director はトポロジを考慮したスケジューリングとコンパクト プレースメント ポリシーを実装します。システムは、Google のノンブロッキング ファブリックで高密度の予約を利用することによって、分散ワークロードを可能な限り最短の物理パスに配置し、テール レイテンシを最小限に抑え、最初から集団通信(NCCL)の速度を最大化します。
2 日目: モニタリング
現実の AI / HPC インフラストラクチャでは、ハードウェアの障害や要件の変更が発生します。柔軟性を欠くクラスタは非効率的です。継続的な「2 日目」の運用フェーズに移行したら、クラスタの健全性を維持し、利用率とパフォーマンスを最大化する必要があります。Cluster Director は、長期的な運用の複雑さに対応できるコントロール プレーンを備えています。このたび導入したのは、2 日目の運用の煩雑な現実に対処できる新しいアクティブ クラスタ管理機能です。
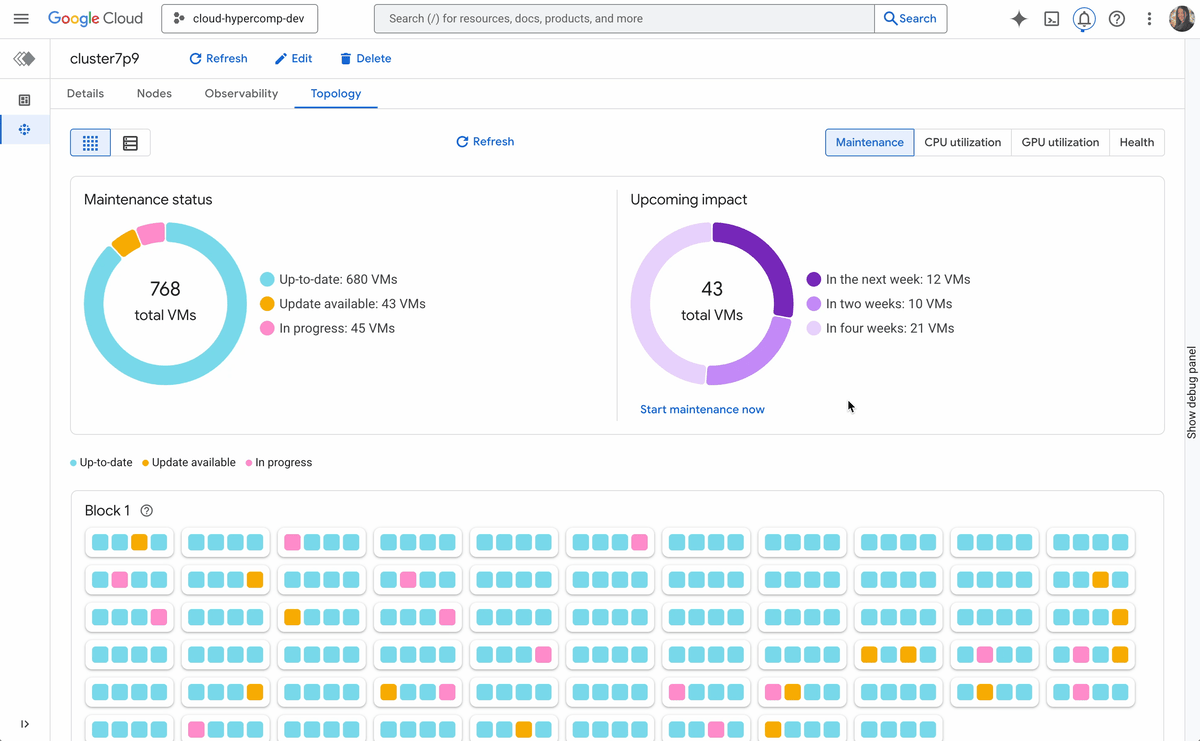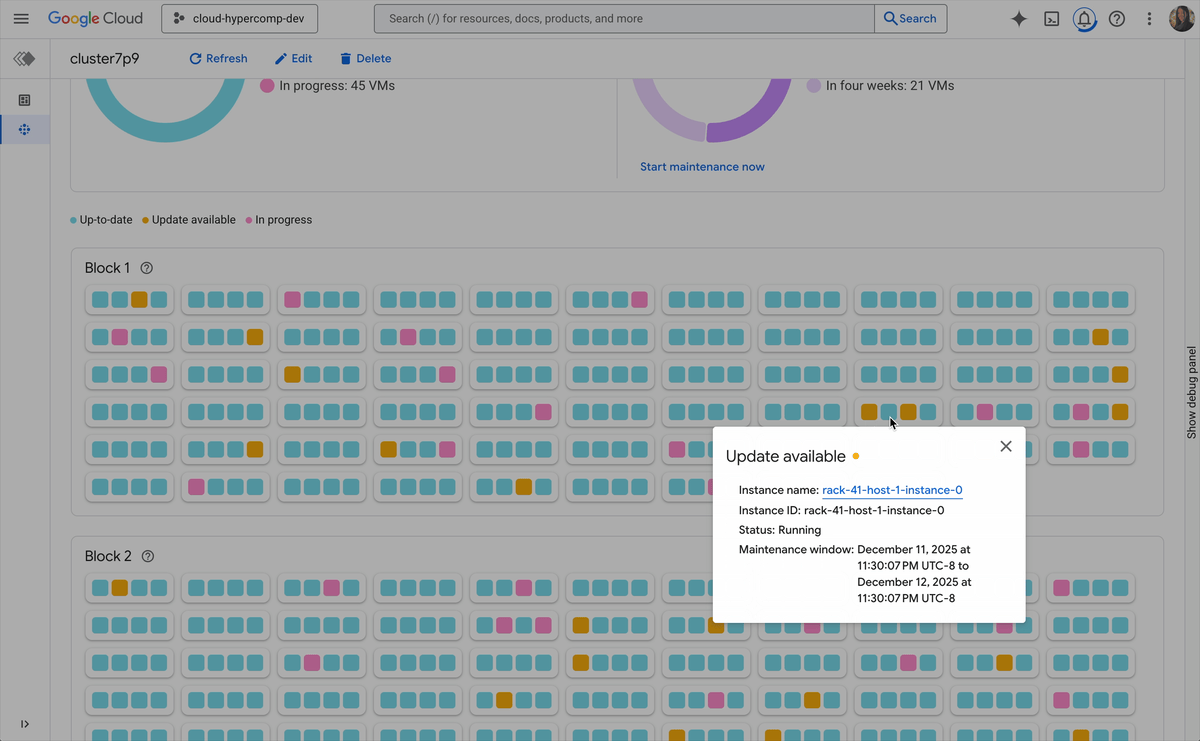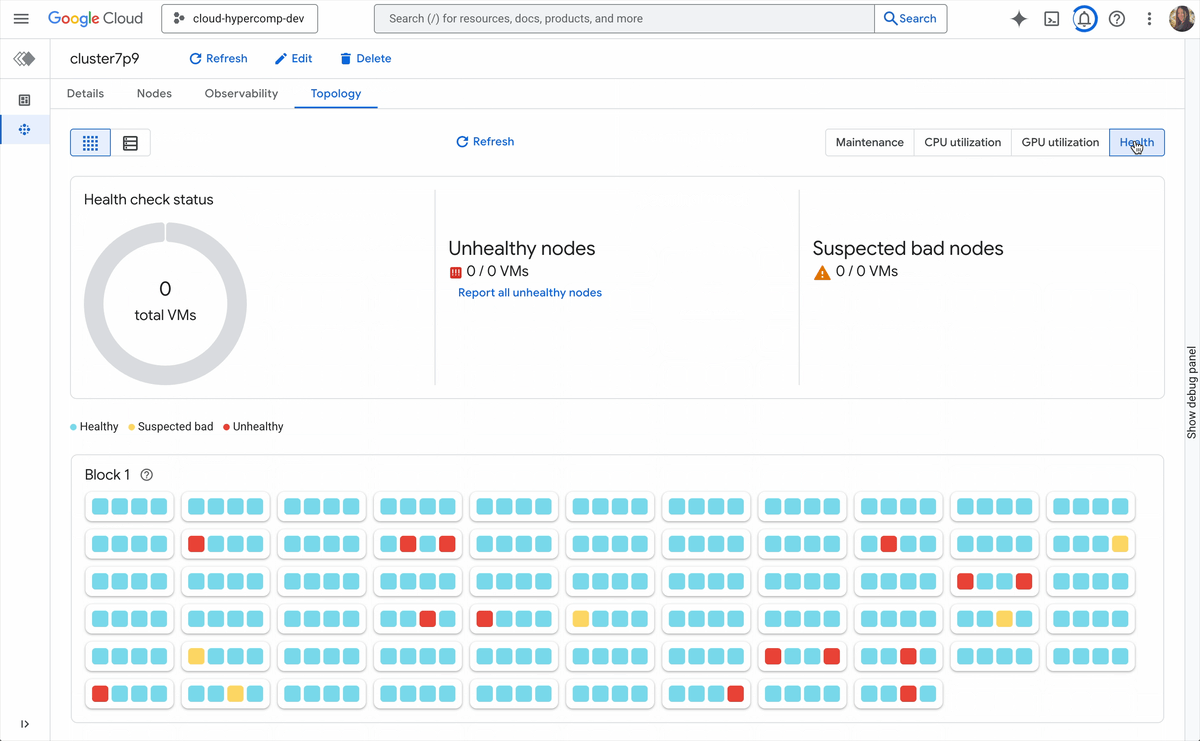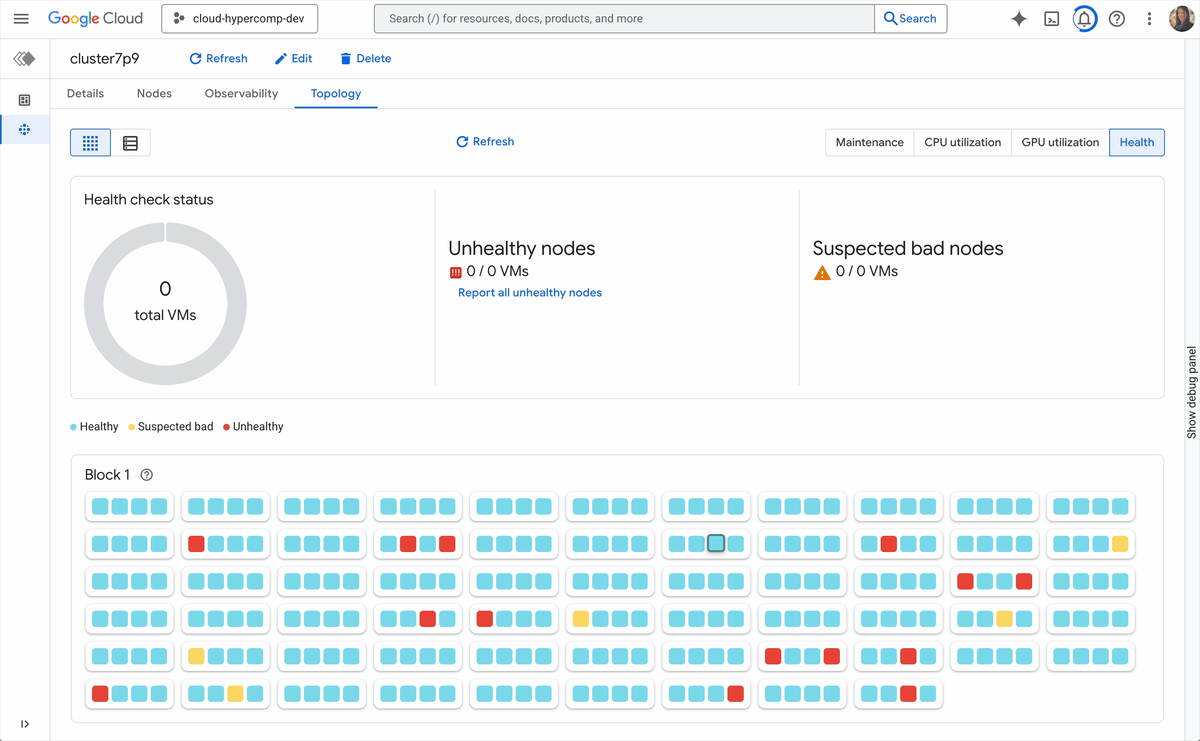
新しいアクティブ クラスタ管理機能には、以下が含まれます。
-
トポロジレベルの可視性: 目に見えないものはオーケストレートできません。Cluster Director のオブザーバビリティ グラフとトポロジ グリッドを使用すると、フリート全体を可視化し、サーマル スロットリングや相互接続に関する問題を特定して、物理的な近接性に基づいてジョブの配置を最適化できます。
-
ワンクリック修復: ノードが劣化したときに、SSH で接続してデバッグする必要がなくなります。Cluster Director を使用すると、ワンクリックで Google Cloud コンソールから直接、障害が発生したノードを交換できます。システムによってドレイン、破棄、交換が処理され、数分でクラスタが最大キャパシティに戻されます。
-
適応型インフラストラクチャ: 研究のニーズに変更があったときは、クラスタも変更する必要があります。今後は、アクティブなクラスタを変更できます。つまり、クラスタを破棄したり進行中の作業を中断したりすることなく、ストレージ ファイル システムの追加や削除などのアクティビティを即座に行えます。
GKE 上の Slurm 向け Cluster Director サポートのプレビュー版をリリース
イノベーションはオープンな環境で発展します。Kubernetes を構築した Google と、Slurm の開発をバックアップした SchedMD は、世界最先端のコンピューティングを支えるオープンソース テクノロジーを長きにわたって支持してきました。この数年間、NVIDIA と SchedMD は緊密に連携して GPU スケジューリングの最適化に取り組んでいます。その結果、最新の AI に不可欠な基本機能である汎用リソース(GRES)フレームワークやマルチインスタンス GPU(MIG)などのサポートが提供されるようになりました。NVIDIA は SchedMD の買収を通じて、Slurm をベンダーに依存しない標準として発展させる取り組みを強化しました。これは、世界最速のスーパーコンピュータを支えるソフトウェアがオープンかつ高パフォーマンスであり続け、未来の高速コンピューティングに向けて完璧に調整されることを保証するものです。
Google は、この高速コンピューティングの土台に立って、SchedMD との連携を深めつつ、いかにしてクラウドネイティブ オーケストレーションと高パフォーマンス スケジューリングのギャップを埋めるかという業界の根本的な課題を解決しようとしています。このたび、SchedMD の Slinky サービスを利用した、GKE 上の Slurm 向け Cluster Director サポートのプレビュー版のリリースをお知らせできるのは、Google Cloud にとって大きな喜びです。
このイニシアチブは、インフラストラクチャの世界の 2 つの標準を統合するものです。GKE 上でネイティブ Slurm クラスタを直接実行することで、両方のコミュニティの強みを増幅できます。
-
研究者の皆様は、sbatch や squeue など、数十年にわたって HPC を定義してきた妥協のない Slurm のインターフェースとバッチ機能を利用できます。
-
プラットフォーム チームの皆様は、自動スケーリング、自己回復、ビンパッキングの機能を備えた GKE がもたらす運用のベロシティを利用できます。
GKE 上の Slurm は、Google と SchedMD の長きにわたるパートナーシップによって強化されており、次世代の AI および HPC ワークロード向けのオープンで強力な統合基盤の構築に役立ちます。今すぐプレビュー版へのアクセスをリクエストしましょう。
今すぐ Cluster Director をお試しください
Cluster Director を使用して AI および HPC クラスタの自動化を開始する準備はできましたか?
-
エンドツーエンドの機能について詳しくは、ドキュメントをご覧ください。
-
コンソールで Cluster Director を有効化してください。
-Google Cloud、Cluster Director 担当シニア プロダクト マネージャー、Ilias Katsardis
-Google Cloud、AI インフラストラクチャ担当グループ プロダクト マネージャー、Jason Monden
