Google Cloud and Seagate: Transforming hard-disk drive maintenance with predictive ML
Nitin Aggarwal
Head of AI Services, Google Cloud
Rostam Dinyari
AI Engineer
Data centers may be in the midst of a flash revolution, but managing hard disk drives (HDDs) is still paramount. According to IDC, stored data will increase 17.8% by 2024 with HDD as the main storage technology.
At Google Cloud, we know first-hand how critical it is to manage HDDs in operations and preemptively identify potential failures. We are responsible for running some of the largest data centers in the world—any misses in identifying these failures at the right time can potentially cause serious outages across our many products and services. In the past, when a disk was flagged for a problem, the main option was to repair the problem on site using software. But this procedure was expensive and time-consuming. It required draining the data from the drive, isolating the drive, running diagnostics, and then re-introducing it to traffic.
That’s why we teamed up with Seagate, our HDD original equipment manufacturer (OEM) partner for Google’s data centers, to find a way to predict frequent HDD problems. Together, we developed a machine learning (ML) system, built on top of Google Cloud, to forecast the probability of a recurring failing disk—a disk that fails or has experienced three or more problems in 30 days.
Let’s take a peek.
Managing disks by the millions is hard work
There are millions of disks deployed in operation that generate terabytes (TBs) of raw telemetry data. This includes billions of rows of hourly SMART(Self-Monitoring, Analysis and Reporting Technology) data and host metadata, such as repair logs, Online Vendor Diagnostics (OVD) or Field Accessible Reliability Metrics (FARM) logs, and manufacturing data about each disk drive.
That’s hundreds of parameters and factors that must be tracked and monitored across every single HDD. When you consider the number of drives in an enterprise data center today, it’s practically impossible to monitor all these devices based on human power alone.
To help solve this issue, we created a machine learning system to predict HDD health in our data centers.
Reducing risk and costs with a predictive maintenance system
Our Google Cloud AI Services team (Professional Services), along with Accenture, helped Seagate build a proof of concept based on the two most common drive types.
The ML system was built on the following Google Cloud products and services:
Terraform helped us configure our infrastructure and manage resources on Google Cloud.
Google internal technologies enabled us to migrate data files to Google Cloud.
BigQuery and Dataflow allowed us to build highly scalable data pipelines to ingest, load, transform, and store TB of data, including raw HDD health data, features (used for training and prediction), labels, prediction results, and metadata.
We built, trained, and deployed our time-series forecasting ML model using:
AI Platform Notebooks for experimentation
AutoML Tables for ML model experimentation and development
Custom Transformer-based Tensorflow model trained on Cloud AI Platform.
UI views in Data Studio and BigQuery made it easy to share results for executives, managers, and analysts.
Composer, Cloud Functions, and our Cloud operations suite provided end-to-end automation and monitoring.
In the past, when we flagged a disk problem, the main fix was to repair the disk on site using software. But this procedure was expensive and time-consuming. It required draining the data from the drive, isolating the drive, running diagnostics, and then re-introducing it to traffic.
"End-to-end automated MLOps using Google Cloud products from data ingestion to model training, validation and deployment added significant value to the project." according to Vamsi Paladugu, Director of Data and Analytics at Seagate.
Vamsi also added, "Automated implementation of infrastructure as code using Terraform and DevOps processes, aligning with Seagate security policies and flawless execution of the design and setup of the infrastructure is commendable."
Now, when an HDD is flagged for repair, the model takes any data about that disk before repair (i.e. SMART data and OVD logs) and uses it to predict the probability of recurring failures.
Data is critical—build a strong data pipeline
Making device data useful through infrastructure and advanced analytics tools is a critical component of any predictive maintenance strategy.
Every disk has to continuously measure hundreds of different performance and health characteristics that can be used to monitor and predict its future health. To be successful, we needed to build a data pipeline that was both scalable and reliable for both batch and streaming data processes for a variety of different data sources, including:
SMART system indicators from storage devices to detect and anticipate imminent hardware failures.
Host data, such as notifications about failures, collected from a host system made up of multiple drives.
HDD logs (OVD and FARM data) and disk repair logs.
Manufacturing data for each drive, such as model type and batch number.
Important note: We do not share user data at any time during this process.
With so much raw data, we needed to extract the right features to ensure the accuracy and performance of our ML models. AutoML Tables made this process easy with automatic feature engineering. All we had to do was use our data pipeline to convert the raw data into AutoML input format.
BigQuery made it easy to execute simple transformations, such as pivoting rows to columns, joining normalized tables, and defining labels, for petabytes of data in just a few seconds. From there, the data was imported directly into AutoML Tables for training and serving our ML models.
Choosing the right approach — two models put to the test
Once we had our pipeline, it was time to build our model. We pursued two approaches to build our time-series forecasting model: an AutoML Tables classifier and a custom deep Transformer-based model.
The AutoML model extracted different aggregates of time-series features, such as the minimum, maximum, and average read error rates. These were then concatenated with features that were not time-series, such as drive model type. We used a time-based split to create our training, validation, and testing subsets. AutoML Tables makes it easy to import the data, generate statistics, train different models, tune hyperparameter configurations, and deliver model performance metrics. It also offers an API to easily perform and batch online predictions.
For comparison, we created a custom Transformer-based model from scratch using Tensorflow. The Transformer model didn’t require feature engineering or creating feature aggregates. Instead, raw time series data was fed directly into the model and positional encoding was used to track the relative order. Features that were not time-series were fed into a deep neural network (DNN). Outputs from both the model and the DNN were then concatenated and a sigmoid layer was used to predict the label.
So, which model worked better?
The AutoML model generated better results, outperforming the custom transformer model or statistical model system. After we deployed the model, we stored our forecasts in our database and compared the predictions with actual drive repair logs after 30 days. Our AutoML model achieved a precision of 98% with a recall of 35% compared to precision of 70-80% and recall of 20-25% from custom ML model). We were also able to explain the mode by identifying the top reasons behind the recurring failures and enabling ground teams to take proactive actions to reduce failures in operations before they happened.
Our top takeaway: MLOps is the key to successful production
The final ingredient to ensure you can deploy robust, repeatable machine learning pipelines is MLOps. Google Cloud offers multiple options to help you implement MLOps, using automation to support an end-to-end lifecycle that can add significant value to your projects.
For this project, we used Terraform to define and provision our infrastructure and GitLab for source control versioning and CI/CD pipeline implementation.
Our repository contains two branches for development and production, which corresponds to an environment in Google Cloud. Here is our high-level system design of the model pipeline for training and serving:
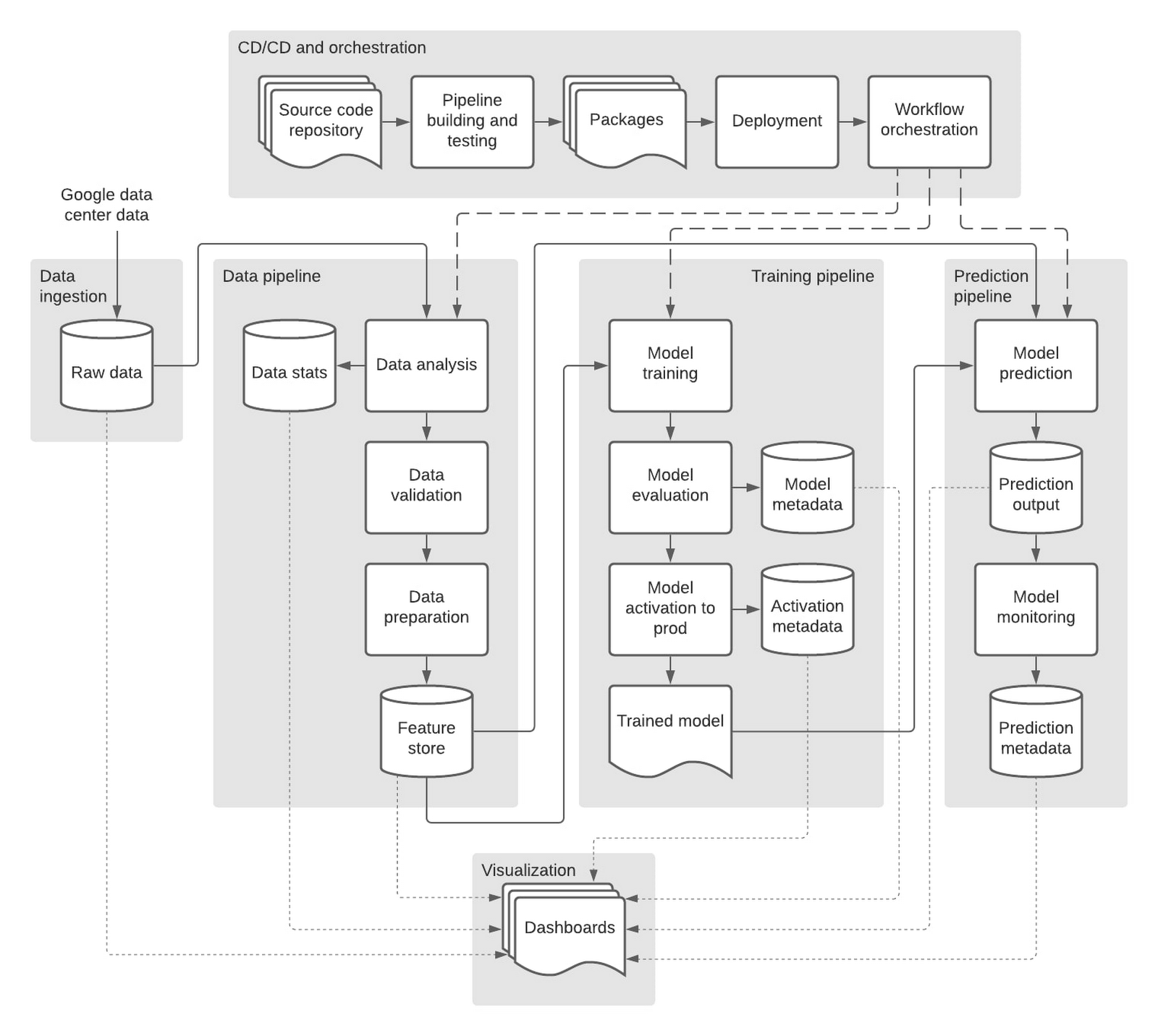
We used Cloud Composer, our fully managed workflow orchestration service, to orchestrate all the data, training, and serving pipelines we mentioned above. After an ML engineer has evaluated the performance-trained model, they can trigger an activation pipeline that promotes the model to production by simply appending an entry in a metadata table.
"Google's MLOps environment allowed us to create a seamless soup-to-nuts experience, from data ingestion all the way to easy to monitor executive dashboards." said Elias Glavinas, Seagate’s Director of Quality Data Analytics, Tools & Automation.
Elias also noted, "AutoML Tables, specifically, proved to be a substantial time and resource saver on the data science side, offering auto feature engineering and hyperparameter tuning, with model prediction results that matched or exceeded our data scientists' manual efforts. Add to that the capability for easy and automated model retraining and deployment, and this turned out to be a very successful project.”
What’s coming next
The business case for using an ML-based system to predict HDD failure is only getting stronger. When engineers have a larger window to identify failing disks, not only can they reduce costs but they can also prevent problems before they impact end users. We already have plans to expand the system to support all Seagate drives—and we can’t wait to see how this will benefit our OEMs and our customers!
Acknowledgements
We’d like to give thanks to Anuradha Bajpai, Kingsley Madikaegbu, and Prathap Parvathareddy for implementing the GCP infrastructure and building critical data ingestion segments. We’d like to give special thanks to Chris Donaghue, Karl Smayling, Kaushal Upadhyaya, Michael McElarney, Priya Bajaj, Radha Ramachandran, Rahul Parashar, Sheldon Logan, Timothy Ma and Tony Oliveri for their support and guidance throughout the project. We are grateful to Seagate team (Ed Yasutake, Alan Tsang, John Sosa-Trustham, Kathryn Plath and Michael Renella) and our partner team from Accenture (Aaron Little, Divya Monisha, Karol Stuart, Olufemi Adebiyi, Patrizio Guagliardo, Sneha Soni, Suresh Vadali, Venkatesh Rao and Vivian Li) who partnered with us in delivering this successful project.




