AutoML Tables: AI Platform Pipelines でのエンドツーエンドのワークフロー
Google Cloud Japan Team
※この投稿は米国時間 2020 年 7 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
AutoML Tables では、ユーザーの構造化データを使用して、最先端の機械学習モデルの構築、分析、デプロイを自動的に行えます。アセット評価、不正行為の検出、信用リスク分析、顧客維持率の予測、店舗での商品レイアウトの分析、コメント欄のスパム問題の解決、音声コンテンツの迅速な分類、レンタル需要の予測といった、幅広い機械学習タスクに活用できます。
AutoML Tables をさらに実用的かつユーザー フレンドリーなものにするため、以下のようなさまざまな新機能をリリースしました。
- 改良された Python クライアント ライブラリ
- オンライン予測の説明の取得
- モデルをエクスポートして任意のコンテナで提供
- モデル検索の進捗状況と最終的なモデルのハイパーパラメータを Cloud Logging に表示
この投稿では、こうした新機能を紹介するために、Cloud AI Platform Pipelines の例を使用して、AutoML Tables ワークフローのエンドツーエンド管理を示します。Cloud AI Platform Pipelines は、堅牢で再現可能な機械学習パイプラインをデプロイする手段を提供するだけでなく、モニタリング、監査、バージョン トラッキング、再現性も実現します。また、ML ワークフローのために、エンタープライズ向けのインストールしやすい安全な実行環境を提供します。
サンプル パイプラインについて
サンプル パイプラインはデータセットを作成し、データを BigQuery ビューからデータセットにインポートして、そのデータでカスタムモデルのトレーニングを行います。次に、トレーニング済みモデルの評価と指標の情報を取得します。また、モデルの品質に関する指定された基準に従い、その情報を使用して、オンライン予測を行うためにモデルをデプロイするかどうかを自動的に判定します。モデルのデプロイが完了すると、予測リクエストを作成し、予測の説明と予測結果を取得できます。
また、この例では、Cloud AI Platform Pipelines のインストールからエクスポートしたトレーニング済みモデルをスケーラブルに提供して、予測リクエストを行う方法を示します。
このワークフローのすべての部分を Cloud Console の Tables UI から管理できます。また、ノートブックやスクリプトを使ったプログラムによる管理も可能です。しかし、この処理をワークフローとして指定すると、ワークフローの信頼性と再現性が向上することに加え、Pipelines を使用して簡単に結果をモニタリングして繰り返し実行をスケジュールできるといったメリットがあります。
たとえば、データセットが定期的に(1 日に 1 回など)更新される場合、ワークフローをスケジュールして毎日実行し、そのたびに更新されたデータセットでトレーニングを行うモデルを構築できます(もう少し手間をかければ、Google Cloud Storage のバケットに新しいデータが追加されたときなどに、イベントベースでパイプライン実行をトリガーするように設定できます)。
サンプル データセットとシナリオについて
Cloud 一般公開データセット プログラムでは、機械学習での試験運用に有用な一般公開データセットを提供しています。ここでは、前回の投稿 Explaining model predictions on structured data(構造化データでのモデル予測の説明)と一貫性を保つために、BigQuery に保存されている 2 つの一般公開データセットを結合したデータであるロンドンの自転車レンタルとNOAA 気象データをサンプルとして使用します。また、外れ値をクリーンアップして、追加の GIS と曜日フィールドを導出するための処理も行います。このデータセットを使用して、出発と返却のレンタル ステーション、曜日、その日の天気などに関する情報に基づいて、自転車レンタルの期間を予測する回帰モデルを構築します。自転車レンタル会社の経営者は、こうした予測とその説明を活用して需要を予想し、さらに各ステーションの在庫を計画できます。
ここでは自転車と天気に関するデータを使用しますが、前述のように AutoML Tables もさまざまなタスクに利用できます。
Cloud AI Platform Pipelines を使用した Tables ワークフローのオーケストレーション
現在ベータ版の Cloud AI Platform Pipelines は、堅牢で再現可能な機械学習パイプラインをデプロイする手段を提供するだけでなく、モニタリング、監査、バージョン トラッキング、再現性も実現します。また、ML ワークフローのために、エンタープライズ向けのインストールしやすい安全な実行環境を提供します。AI Platform Pipelines は、Google Kubernetes Engine(GKE)クラスタにインストールされた Kubeflow Pipelines(KFP)に基づいています。また、KFP および TFX SDK を介して指定されたパイプラインを実行できます。Pipelines の技術スタックの詳細については、このブログ投稿をご覧ください。
AI Platform Pipelines のインストールは、数回のクリックで作成できます。インストールが完了すると、Cloud Console の AI Platform パネルから AI Platform Pipelines にアクセスできます(インストールの詳細については、ドキュメントとサンプルの README をご覧ください)。
Tables のエンドツーエンド パイプラインをアップロードして実行する
Pipelines のインストール実行中に、サンプル AutoML Tables パイプラインをアップロードできます。
パイプライン ダッシュボードの左側にあるナビゲーション バーで [パイプライン] をクリックしてから、[パイプラインのアップロード] をクリックします。フォームで、[URL によるインポート] を選択したままにして、次の URL を貼り付けます:https://storage.googleapis.com/aju-dev-demos-codelabs/KF/compiled_pipelines/tables_pipeline_caip.py.tar.gz
リンクはこのパイプラインのコンパイル済みのバージョンを指し、Kubeflow Pipelines SDK を使用して指定されています。アップロードされたパイプラインは、次のようになります。
次に、[+実行の作成] ボタンをクリックしてパイプラインを実行します。パイプラインの入力パラメータ構成の詳細については、サンプルの README で確認できます。
代わりに、繰り返し実行のセットをスケジュールすることもできます。このサンプル パイプラインの場合と同様に、データが BigQuery に存在し、時間的アスペクトがあれば、これを反映するビューを定義できます(たとえば、過去 N 日または N 時間にわたるデータをウィンドウから返すなど)。これで AutoML パイプラインは、そのビューからのデータ取り込みを指定し、パイプラインが実行されるたびに更新されたデータ ウィンドウを取得して、その更新されたウィンドウに基づいて新しいモデルを構築できます。
パイプラインが実行するステップ
サンプル パイプラインはデータセットを作成し、データを BigQuery ビューからデータセットにインポートして、そのデータでカスタムモデルのトレーニングを行います。次に、トレーニング済みモデルの評価と指標の情報を取得します。また、モデルの品質に関する指定された基準に従い、その情報を使用して、オンライン予測を行うためにモデルをデプロイするかどうかを自動的に判定します。
このセクションでは、パイプラインの各ステップの詳細と、それらを実装する方法を確認します。カスタムモデルのグラフを TensorBoard で調べ、後半のセクションで説明するように、コンテナで提供するためにエクスポートすることも可能です。
Tables データセットの作成とそのスキーマの調整
このパイプラインは新しい Tables データセットを作成し、前述の「自転車と天気」のデータセット用に BigQuery テーブルからデータを取り込みます。こうしたアクションは、パイプラインの最初の 2 つのステップ automl-create-dataset-for-tables および automl-import-data-for-tables で実行されます。
この例では解説しませんが、AutoML Tables は BigQuery ビューだけでなく、テーブルからの取り込みもサポートしています。これは、簡単に特徴量エンジニアリングを行う方法になり得ます。BigQuery の豊富な関数と演算子を活用して、取り込む前のデータをクリーンアップおよび変換できます。
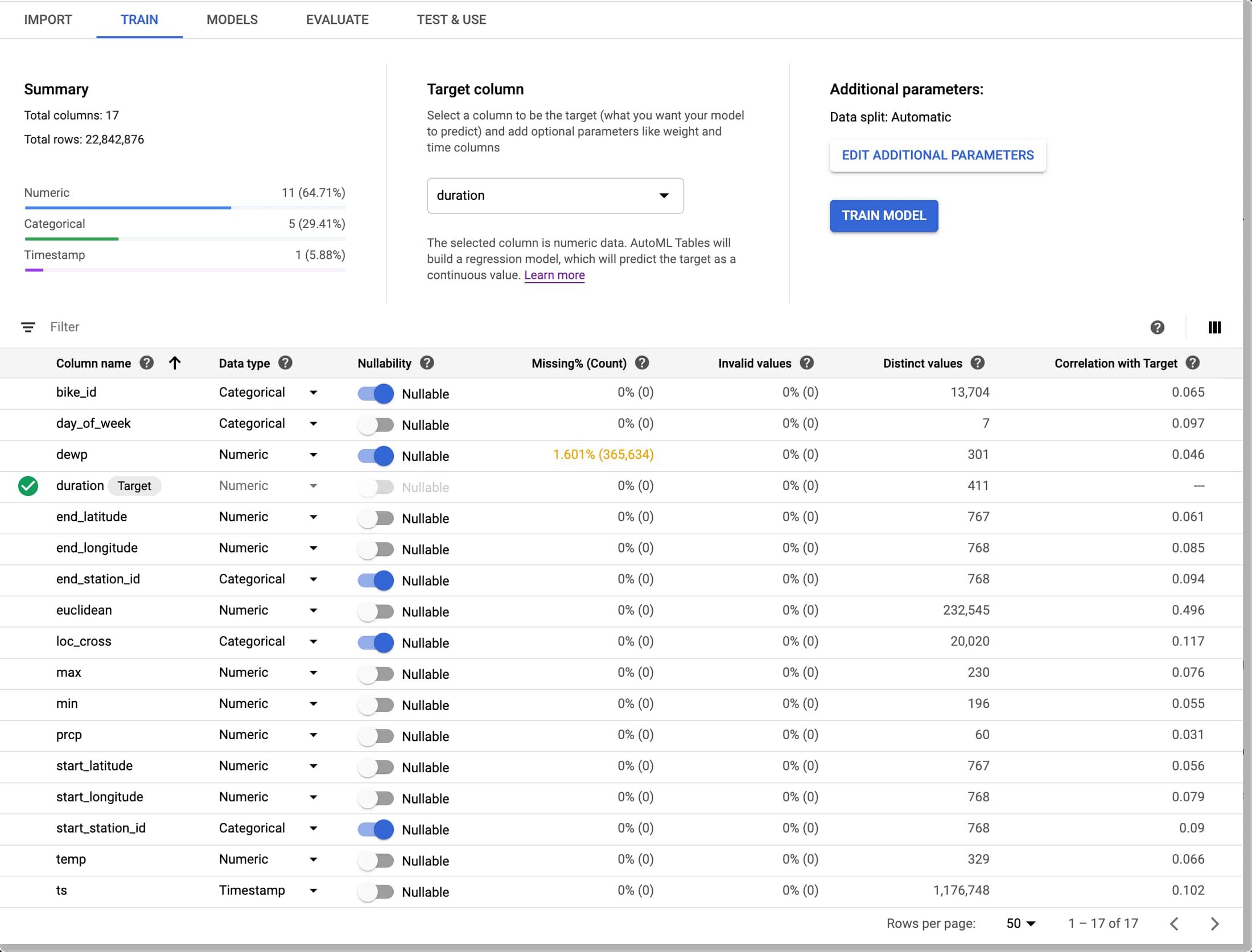
データの取り込みが完了すると、AutoML Tables は各フィールド(列)のデータ型を推測します。推測された型が、自分が求めているものではない場合もあります。たとえば、「自転車と天気」データセットでは、複数の ID フィールド(レンタル ステーション ID など)がデフォルトでは数値となっていますが、モデルのトレーニングを行う際に、これらのフィールドをカテゴリとして扱いたいと考えています。さらに、loc_cross 文字列をテキストではなくカテゴリとして扱いたいと考えています。
こうした調整は、目的のスキーマ変更を指定するパイプライン パラメータを定義することでプログラムにより行います。
続いて、スキーマ調整ごとに、automl-set-dataset-schema パイプライン ステップで update_column_spec を呼び出します。モデルのトレーニングを開始する前に、モデルに予測させるターゲット列を指定する必要があります。ここでは、モデルにレンタル期間を予測するようトレーニングを行います。これは数値のため、回帰モデルをトレーニングします。
Tables UI で、プログラムによる調整の結果は次のようになります。
データセットでのカスタムモデルのトレーニング
データセットが定義され、スキーマが正しく設定されると、パイプラインはモデルのトレーニングを行います。これは automl-create-model-for-tables パイプライン ステップで行われます。パイプライン パラメータを使用して、トレーニングの予算、最適化の目標(デフォルトを使用していない場合)、モデル入力に含める列や除外する列を指定できます。
データセットの特性によっては、デフォルト以外の最適化目標を指定することもできます。このテーブルは、使用可能な最適化目標と、どのような場合に使用するかを示しています。たとえば、不均衡なデータセットを使用して分類モデルのトレーニングを行っていた場合、AUC PR(MAXIMIZE_AU_PRC)を使用するよう指定すると、あまり一般的でないクラスの予測結果を最適化できます。
Cloud Logging を介したモデル検索情報の表示
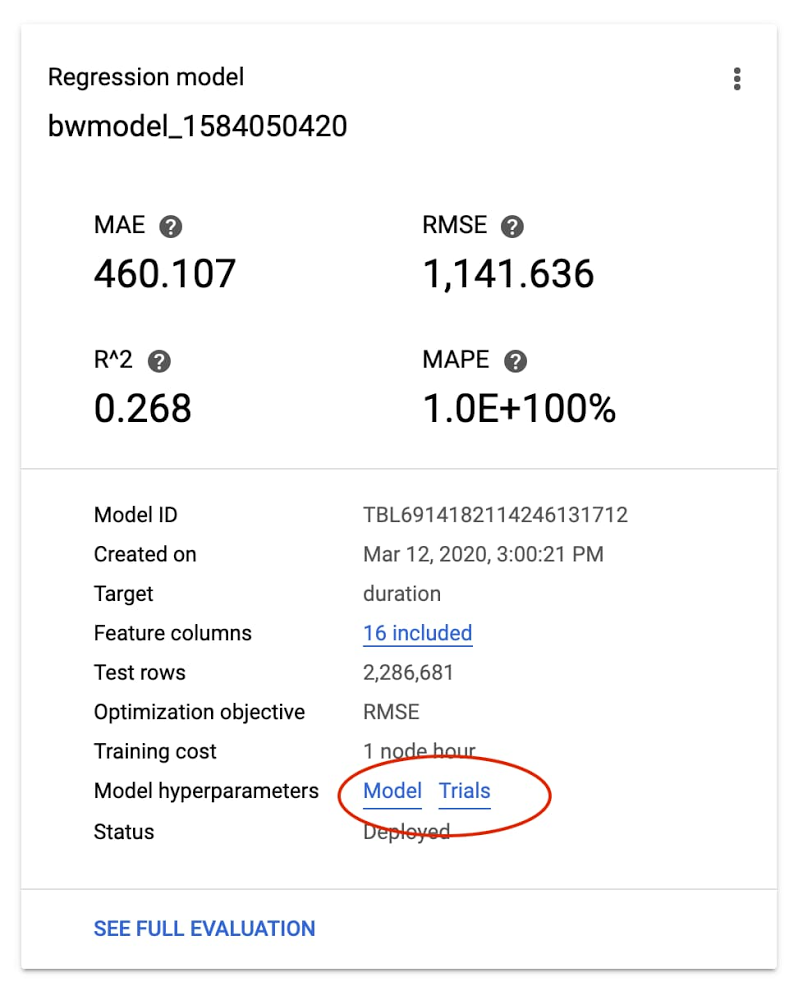
AutoML Tables モデルの詳細は、Cloud Logging を介して表示できます。Logging を使用すると、最終モデルのハイパーパラメータのほか、モデルのトレーニングと調整で使用されるハイパーパラメータとオブジェクト値を確認できます。
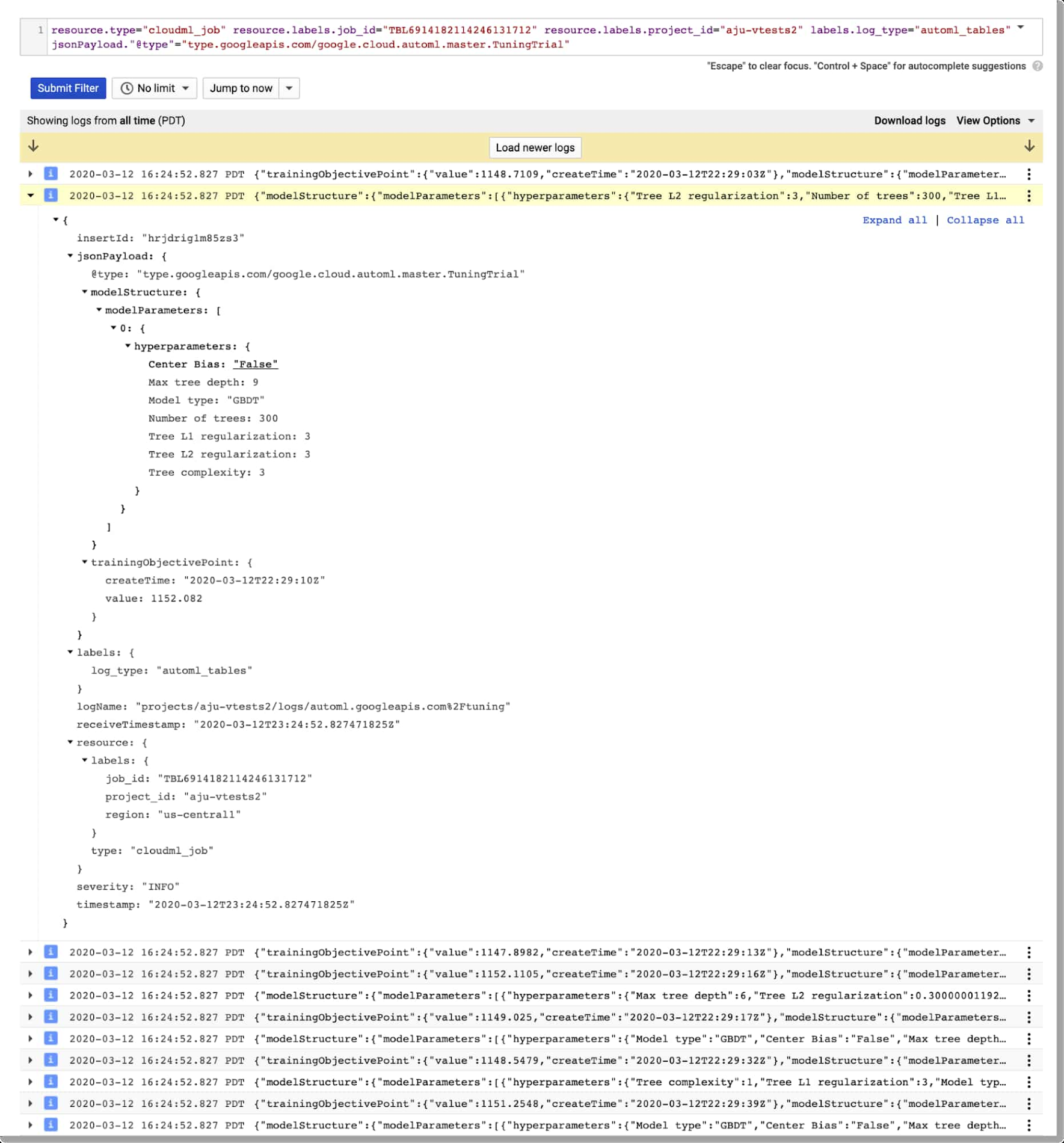
こうしたログに簡単にアクセスするには、Cloud Console の AutoML Tables ページに移動します。左側のナビゲーション ペインで [モデル] タブを選択し、目的のモデルをクリックしてから、[モデル] リンクをクリックして最終的なハイパーパラメータ ログを表示します。調整トライアルのハイパーパラメータを表示するには、[トライアル] をクリックします。
たとえば、カスタムモデルが「自転車と天気」データセットでトレーニングを行ったトライアル ログと、ログ内で展開されたエントリは、次のようになります。
カスタムモデル評価
カスタムモデルがトレーニングを完了すると、パイプラインは次のステップであるモデル評価に移行します。評価指標には API を介してアクセスできます。この情報は、モデルをデプロイするかどうかを決めるために使用します。
このアクションは、2 つのステップに分解されます。評価情報の取得プロセスは、さまざまな状況で使用できる汎用コンポーネント(パイプライン ステップ)にすることもできます。次に、情報を分析する特殊用途のステップを使って、トレーニング済みのモデルをデプロイするかどうかを決定します。
パイプライン ステップの最初にある automl-eval-tables-model ステップでは、評価とグローバル特徴量の重要度の情報を取得します。
AutoML Tables は、トレーニングされたモデルのグローバル特徴量の重要度を自動計算します。これは、評価セット全体における、各機能が受け取る平均的なアトリビューションの絶対値を示しています。値が高いほど、特徴がモデルの予測に与える影響が大きいことを示します。
この情報はモデルのデバッグや改善に役立ちます。特徴の影響がごくわずかである(つまり、値が低い)場合、今後のトレーニングからその特徴を除外することでモデルを簡素化できます。
パイプラインのステップでは、グローバル特徴量の重要度データはパイプライン実行の出力の一部として示されます。
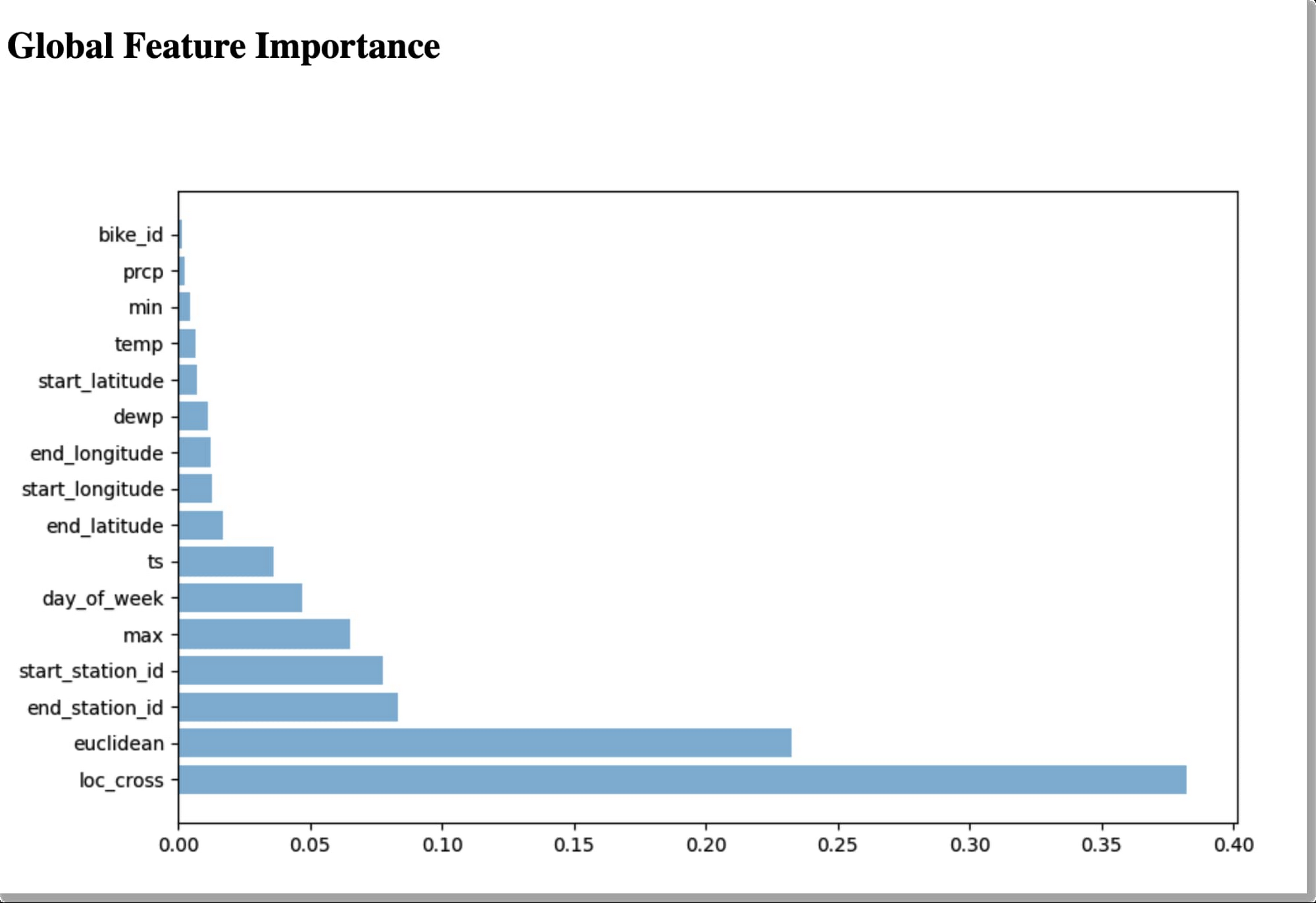
たとえば、上の画像に基づいて、bike_id を含めずにモデルのトレーニングを行うこともできます。
次のパイプライン ステップ automl-eval-metrics では、前のステップの評価出力を入力として取得して解析し、抽出した指標を、モデルをデプロイするかどうかを決定するためのパイプライン パラメータとともに使用します。パイプライン入力パラメータのいずれかを使用して、指標のしきい値を指定できます。この例では、回帰モデルのトレーニングを行い、mean_absolute_error(MAE)値をパイプライン入力パラメータのしきい値として指定します。
パイプライン ステップは、モデルの評価情報と、特定のしきい値の制約を比較します。この場合は、MAE が < 450 であれば、モデルはデプロイされません。パイプライン ステップはこの決定を出力して、パイプライン実行の出力の一部として使用している評価情報を表示します。
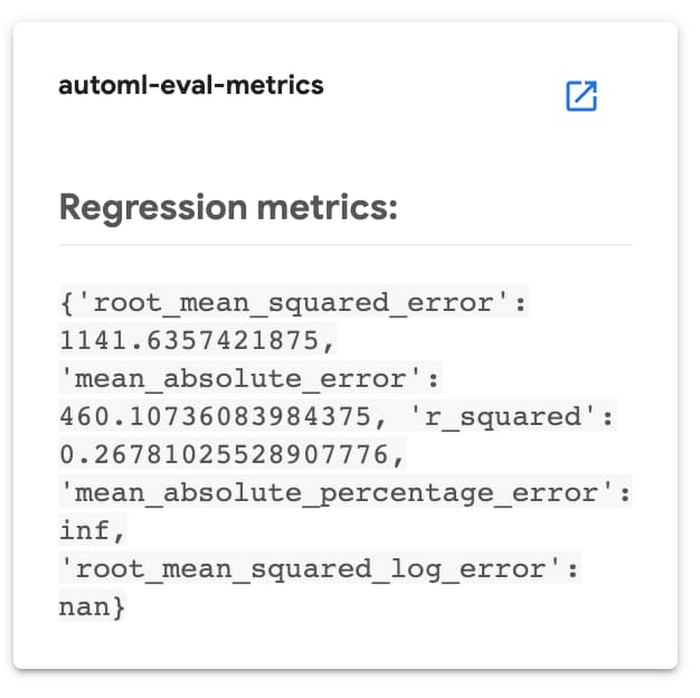
Kubeflow パイプライン ステップにより示される、モデルの評価に関する情報。
(条件付き)モデルのデプロイ
カスタム Tables モデルはいずれもデプロイして、オンライン予測リクエストのためにアクセス可能にできます。
パイプライン コードは、条件テストを使用して、モデルをデプロイするステップを実行するかどうかを決定します。これは、前述の評価ステップの出力に基づいて行われます。
モデルが特定の基準を満たす場合にのみ、デプロイのステップ(automl-deploy-tables-model)が実行され、モデルはパイプライン実行の一部として自動的にデプロイされます。
モデルは、UI を使用するか、プログラムによって、後でデプロイすることもできます。
まとめ: フル パイプラインの実行
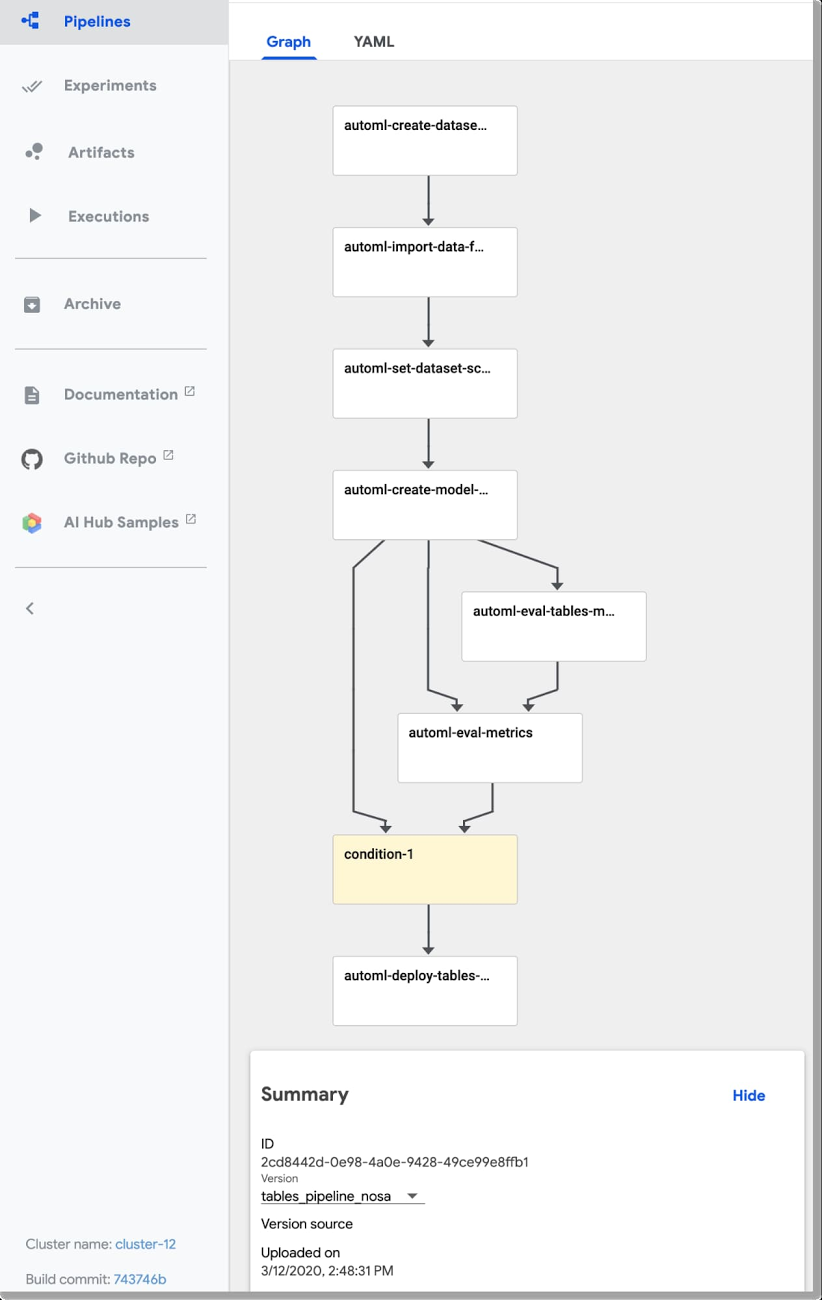
以下の図は、パイプライン実行の結果を示しています。この場合は、モデルの評価基準に基づいて条件付きステップが実行され、トレーニング済みのモデルがデプロイされました。
UI を使用して、各ステップの出力とログ、実行アーティファクトと系統情報などを確認できます。詳細については、この投稿をご覧ください。
モデルの予測に関する説明を取得する
モデルがデプロイされると、そのモデルの予測に加えて、ローカル特徴量の重要度の説明をリクエストできます。これにより、各特徴が 1 つのサンプルの予測に対してどの程度(および、どのような方向性で)影響を与えたかがわかります。こうした値がどのように計算されるかについての詳細は、このブログ投稿をご覧ください。
Python クライアント ライブラリを使用して予測とその説明をリクエストする方法についてのノートブックのサンプルは次のとおりです。
予測レスポンスはこのような構造となります(上記のノートブックは、matplotlib を使用してローカル特徴量の重要度の結果を可視化する方法を示しています)。
ローカル特徴量の重要度は、Cloud Console の AutoML Tables UI を使用して簡単に確認できます。モデルをデプロイしてから、[テーブル] パネルの [テストと使用] タブに移動し、[オンライン予測] を選択します。次に、予測のフィールド値を入力してから、ページの下部にある [特徴量の重要度を生成] ボックスをオンにします。結果に特徴量の重要度の値と予測が表示されます。このブログ投稿では、こうした説明を使用してデータの潜在的な問題を発見したり、問題の領域に関する理解を深めたりする方法について、いくつかの例をご紹介します。
Cloud Console の AutoML Tables UI
この例では、Kubeflow パイプラインと Python クライアント ライブラリを使用して Tables ワークフローを自動化する方法に焦点を当ててきました。
パイプラインのステップはすべて Cloud Console の AutoML Tables UI でも実行可能です。これには、多くの有用な可視化や、このサンプル パイプラインで実装されていないその他の機能(たとえば、より詳細な分析のためにモデルのテストセットと予測結果を BigQuery にエクスポートする機能)などが含まれます。
トレーニング済みモデルをエクスポートして GKE クラスタ上で提供する
Tables には、Docker コンテナ経由で提供できるようにパッケージ化された完全カスタムモデルをエクスポートする機能もあります。これにより、コンテナを実行できる場所であればどこでもモデルを提供できます。たとえば、このブログ投稿では、Cloud Run を使用してエクスポート済みモデルを提供する手順を説明しています。
同様に、AI Platform Pipelines のインストール用に作成されたクラスタなど、任意の GKE クラスタからも、エクスポートしたモデルを提供できます。上記のブログ投稿の手順に沿って、コンテナを作成してください。次に、Kubernetes のデプロイとサービスを作成してモデルを提供できます。これは、このテンプレートをインスタンス化することで行います。
サービスがデプロイされたら、予測リクエストを送信できます。サンプルの README で、さらに詳しい手順を説明しています。
カスタムモデルのグラフを確認する
カスタムモデルのグラフは、TensorBoard を使用して確認することもできます。このブログ投稿で、その方法について詳しく説明しています。
まとめと次のステップ
この投稿では、AutoML Tables の最近機能を紹介しました。これには、改良された Python SDK、オンライン予測の説明のサポート、モデルをエクスポートして任意のコンテナから提供する機能、Cloud Logging でモデル検索の進捗状況と最終的なモデルのハイパーパラメータを追跡する機能が含まれます。
また、Cloud AI Platform Pipelines を使用してエンドツーエンドの Tables のワークフローをオーケストレーションする方法についても説明しました。具体的には、データセットの作成、構造化データの取り込み、データでのカスタムモデルのトレーニング、さらにはモデルで評価データと指標を取得することで得られた情報に基づきデプロイするかどうかを決定する方法について説明しました。サンプルコードは、Cloud AI Platform Pipelines のインストールから、エクスポートしたトレーニング済みモデルをスケーラブルに提供する手順も示しています。
最近公開された BigQuery ML ベータ版の機能もぜひお試しください。これは、BigQuery 内から AutoML Tables モデルをトレーニングする機能です。
パイプライン コードの詳細
パイプライン コードの詳細なチュートリアルについては、サンプルの README をご覧ください。新しい Python クライアント ライブラリ なら、ワークフローの各ステージをサポートする Pipelines のコンポーネントを簡単に構築できます。
- スタッフ デベロッパー アドボケイト Amy Unruh



