Explaining model predictions on structured data
Amy Unruh
Staff Developer Advocate
Sara Robinson
Software Engineer
Machine learning technology continues to improve at a rapid pace, with increasingly accurate models being used to solve more complex problems. However, with this increased accuracy comes greater complexity. This complexity makes debugging models more challenging. To help with this, last November Google Cloud introduced Explainable AI, a tool designed to help data scientists improve their models and provide insights to make them more accessible to end users.
We think that understanding how models work is crucial to both effective and responsible use of AI. With that in mind, over the next few months, we’ll share a series of blog posts that covers how to use AI Explanations with different data modalities, like tabular, image, and text data.
In today’s post, we’ll take a detailed look at how you can use Explainable AI with tabular data, both with AutoML Tables and on Cloud AI Platform.
What is Explainable AI?
Explainable AI is a set of techniques that provides insights into your model’s predictions. For model builders, this means Explainable AI can help you debug your model while also letting you provide more transparency to model stakeholders so they can better understand why they received a particular prediction from your model.
AI Explanations works by returning feature attribution values for each test example you send to your model. These attribution values tell you how much a particular feature affected the prediction relative to the prediction for a model’s baseline example. A typical baseline is the average value of all the features in the training dataset, and the attributions tell how much a certain feature affected a prediction relative to the average individual.
AI Explanations offers two approximation methods: Integrated Gradients and Sampled Shapley. Both options are available in AI Platform, while AutoML Tables uses Sampled Shapley. Integrated Gradients, as the name suggests, uses the gradients—which show how a prediction is changing at each point—in its approximation. It requires a differentiable model implemented in TensorFlow, and is the natural choice for those models, for example neural networks. Sampled Shapley provides an approximation through sampling to the discrete Shapley value. While it doesn’t scale as well in the number of features, Sampled Shapely does work on non-differentiable models, like tree ensembles. Both methods allow for an assessment of how much each feature of a model led to a model prediction by comparing those against a baseline. You can learn more about them in our whitepaper.
About our dataset and scenario
The Cloud Public Datasets Program makes available public datasets that are useful for experimenting with machine learning. For our examples, we’ll use data that is essentially a join of two public datasets stored in BigQuery: London Bike rentals and NOAA weather data, with some additional processing to clean up outliers and derive additional GIS and day-of-week fields.
Using this dataset, we’ll build a regression model to predict the duration of a bike rental based on information about the start and end stations, the day of the week, the weather on that day, and other data. If we were running a bike rental company, we could use these predictions—and their explanations—to help us anticipate demand and even plan how to stock each location.
While we’re using bike and weather data here, you can use AI Explanations for a wide variety of tabular models, taking on tasks as varied as asset valuations, fraud detection, credit risk analysis, customer retention prediction, analyzing item layouts in stores, and many more.
AI Explanations for AutoML Tables
AutoML Tables lets you automatically build, analyze, and deploy state-of-the-art machine learning models using your own structured data. Once your custom model is trained, you can view its evaluation metrics, inspect its structure, deploy the model in the cloud, or export it so that you can serve it anywhere a container runs.
Of course, AutoML Tables can also explain your custom model’s prediction results. This is what we’ll look at in our example below. To do this, we’ll use the “bikes and weather” dataset that we described above, which we’ll ingest directly from a BigQuery table. This post walks through the data ingestion—which is made easy by AutoML—and training process using that dataset in the Cloud Console UI.
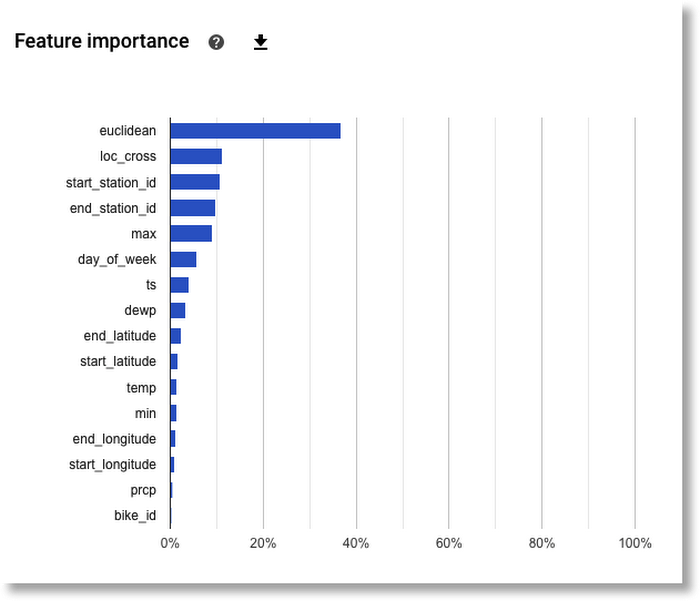
Global feature importance
AutoML Tables automatically computes global feature importance for the trained model. This shows, across the evaluation set, the average absolute attribution each feature receives. Higher values mean the feature generally has greater influence on the model’s predictions.
This information is extremely useful for debugging and improving your model. If a feature’s contribution is negligible—if it has a low value—you can simplify the model by excluding it from future training. Based on the diagram below, for our example, we might try training a model without including bike_id.
Explanations for local feature importance
You can now also measure local feature importance: a score showing how much (and in which direction) each feature influenced the prediction for a single example.
It’s easy to explore local feature importance through Cloud Console’s Tables UI. After you deploy your model, go to the TEST & USE tab of the Tables panel, select ONLINE PREDICTION, enter the field values for the prediction, and then check the Generate feature importance box at the bottom of the page. The result will now be the prediction, the Baseline prediction value, and the feature importance values.
Let’s look at a few examples. For these examples, in lieu of real-time data, we’re using instances from the test dataset that the model did not see while training. AutoML tables allows you to export the test dataset to BigQuery after training, including the target column, which makes it easy to explore.
One thing our bike rental business might want to investigate is why different trips between the same two stations are sometimes accurately predicted to have quite different durations. Let’s see if the prediction explanations give us any hints. The actual duration value (that we want our model to predict) is annotated in red in the screenshots below.
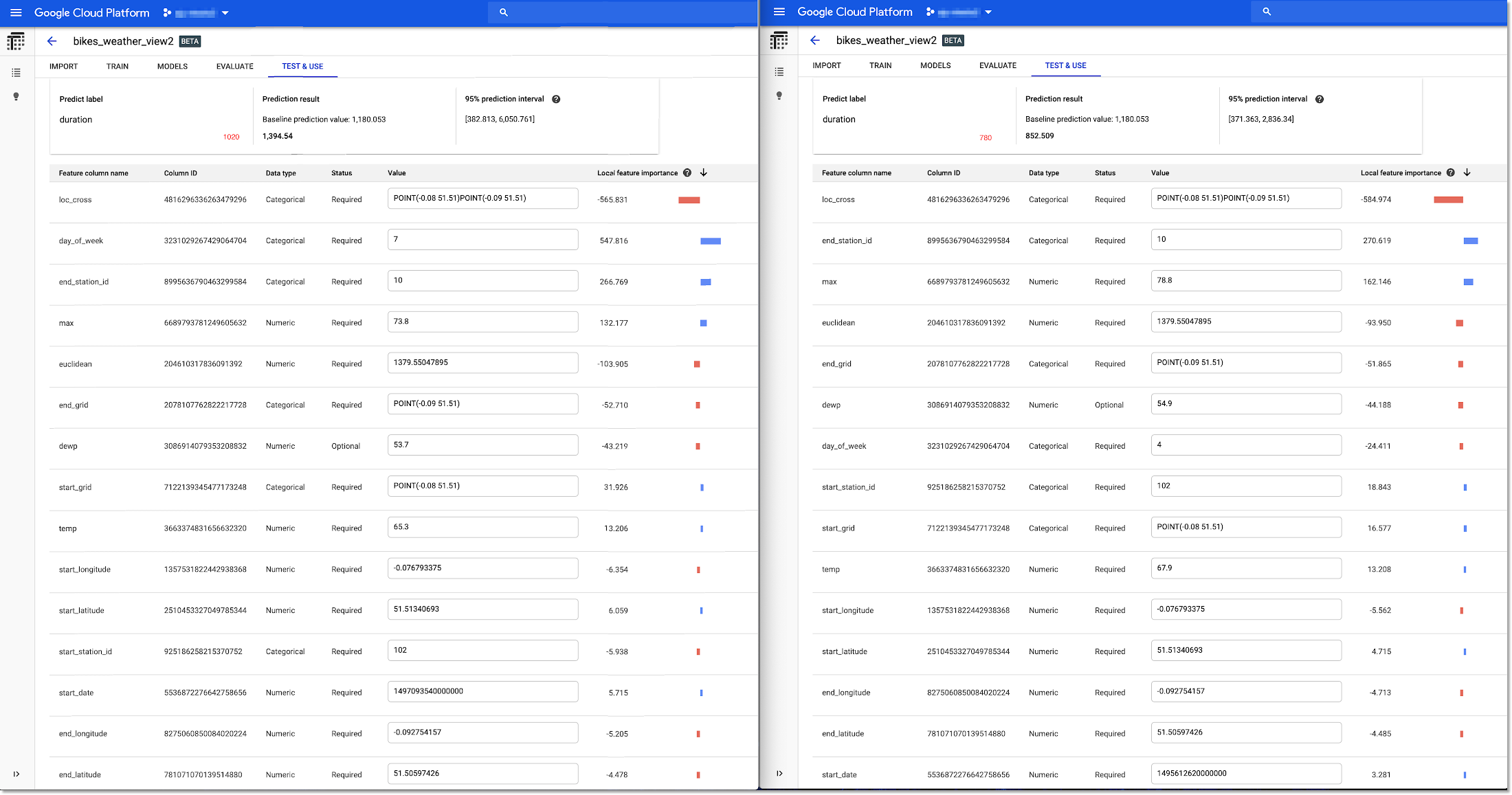
Both of these trips are to and from the same locations, but the one on the left was correctly predicted to take longer. It looks like the day of week (7 is a weekend; 4 is a weekday) was an important contributor. When we explore the test dataset in BigQuery, confirm that the average duration of weekend rides is indeed higher than for weekdays.
Let’s look at two more trips with the same qualities: to and from the same locations, yet the duration of one is accurately predicted to be longer.
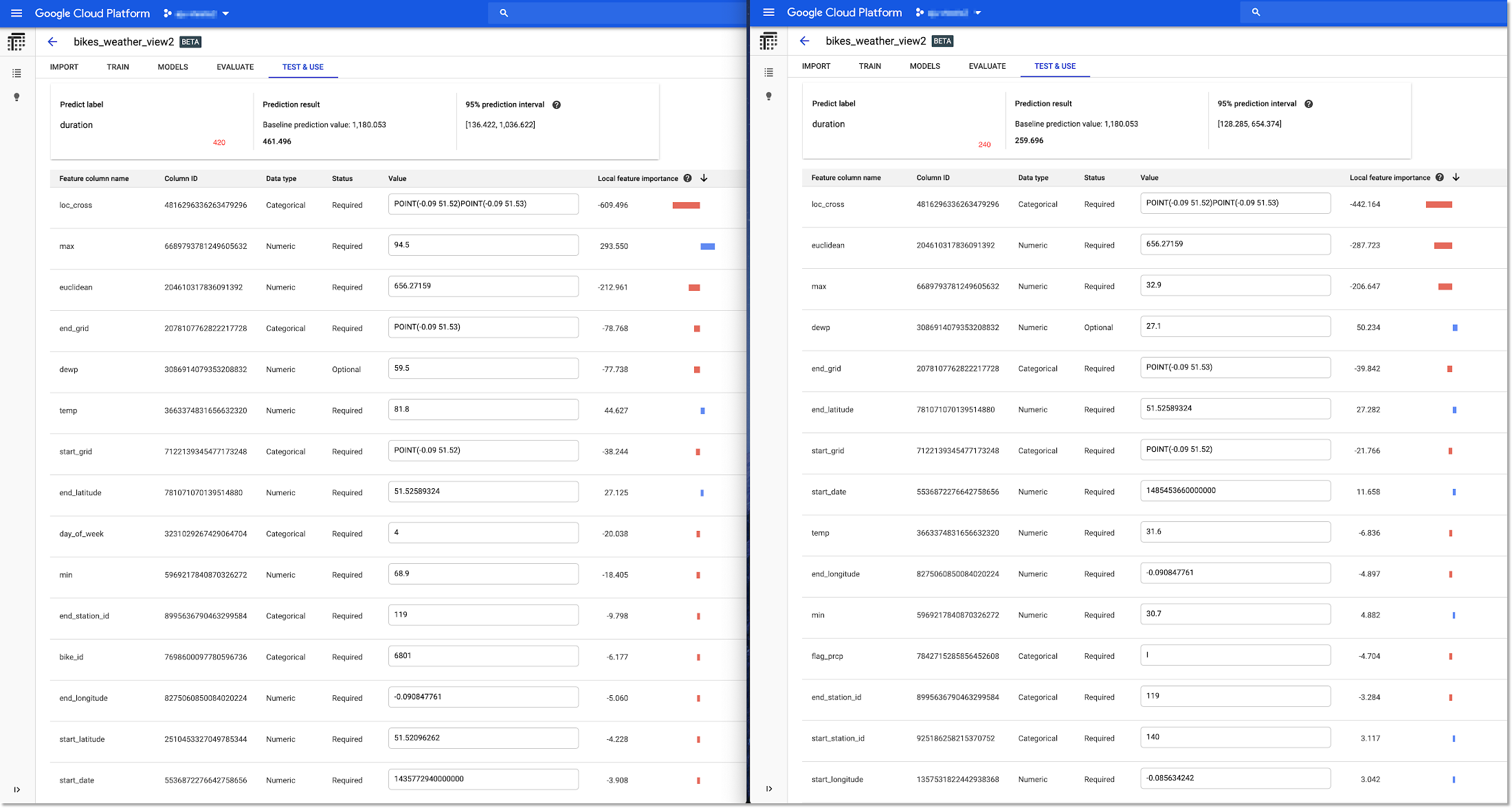
In this case, it looks like the weather, specifically max temperature, might have been an important factor. When we look at the average ride durations in the BigQuery test dataset for temps at the high and low end of the scale, our theory is supported.
So these prediction explanations suggest that on the weekends, and in hot weather, bike trips will tend to take longer than they do otherwise. This is data our bike rental company can use to tweak bike stocking, or other processes, to improve business.
What about inaccurate predictions? Knowing why a prediction was wrong can also be extremely valuable, so let’s look at one more example: where the predicted trip duration is much longer than the actual trip duration, as shown below.
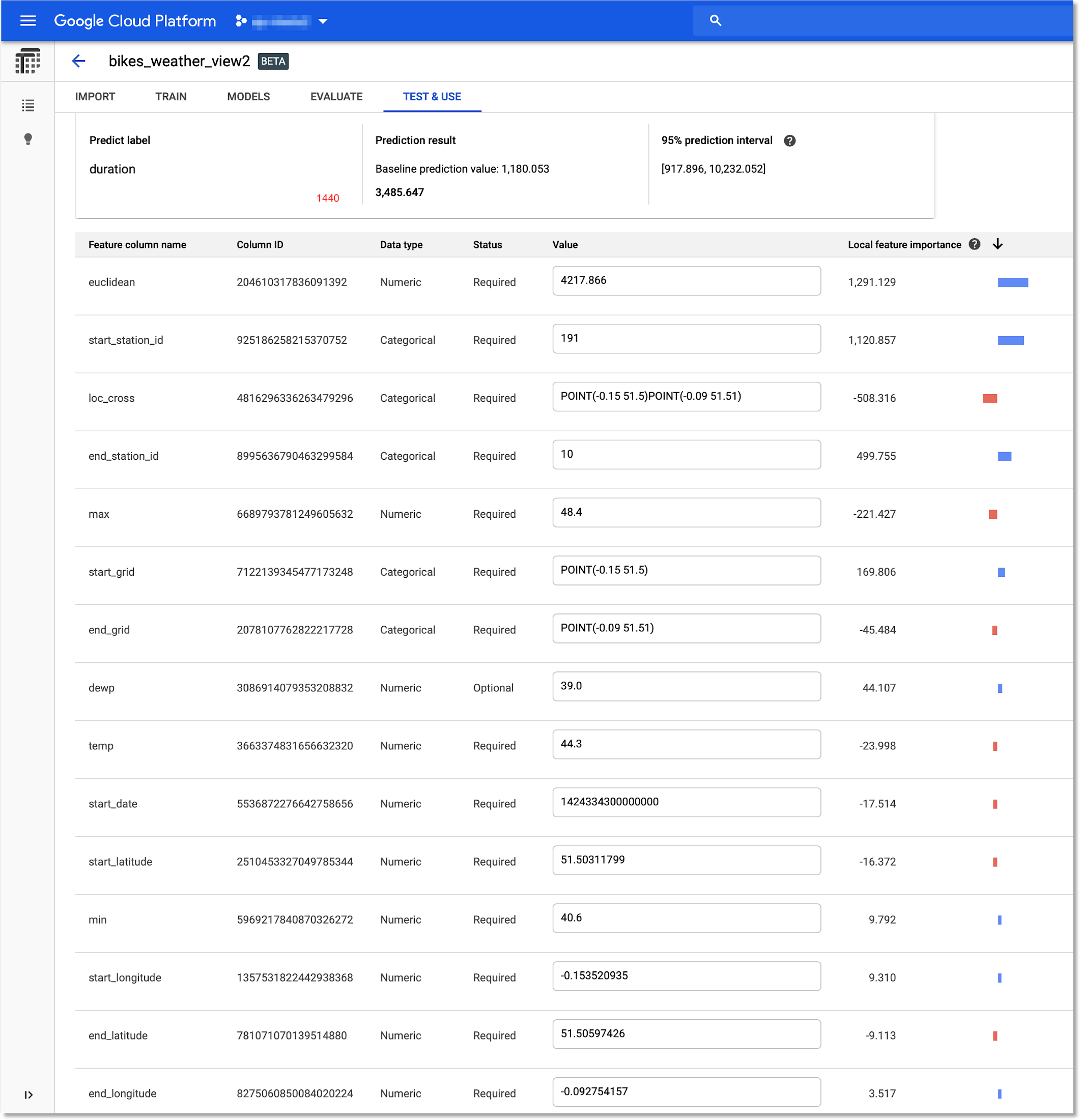
Again, we can load an example with an incorrect prediction into Cloud Console. This time, the local feature importance values suggest that the starting station might have played a larger-than-usual role in the overly high prediction. Perhaps the trips from this station have more variability than the norm.
After querying the test dataset on BigQuery, we can detect that this station is in the top three for standard deviation in prediction accuracy. This high variability of prediction results suggests that there might be some issues with the station or its rental setup, that the rental company might want to look into.
Using the AutoML Tables client libraries to get local explanations
You can also use the AutoML Tables client libraries to programmatically interact with the Tables API. That is, from a script or notebook, you can create a dataset, train your model, get evaluation results, deploy the model for serving, and then request local explanations for prediction results given the input data.
For example, with the following “bikes and weather” model input instance:
… you can request a prediction with local feature importance annotations like this:
The response will return not only the prediction itself and the 95% prediction interval—the bounds that the true value of the prediction is likely to fall between with 95% probability—but also the local feature importance values for each input field. The prediction response should look something like this.
This notebook walks through the steps in more detail, and shows how to parse and plot the prediction results.
Explanations for AI Platform
You can also get explanations for custom TensorFlow models deployed to AI Platform. Let’s show how using a model trained on a similar dataset to the one above. All of the code for deploying an AI Explanations model to AI Platform can be found in this notebook.
Preparing a model for deployment
When we deploy AI Explanations models to AI Platform, we need to choose a baseline input for our model. When you choose a baseline for tabular models, think of it as helping you identify outliers in your dataset. For this example we’ve set the baseline to the median across all of our input values, computed using Pandas.
Since we’re using a custom TensorFlow model with AI Platform, we also need to tell the explanations service which tensors we want to explain from our TensorFlow model’s graph. We provide both the baseline and this list of tensors to AI Explanations in an explanation_metadata.json file, uploaded to the same GCS bucket as our SavedModel.
Getting attribution values from AI Platform
Once our model is deployed with explanations, we can get predictions and attribution values with the AI Platform Prediction API or gcloud. Here’s what an API request to our model would look like:
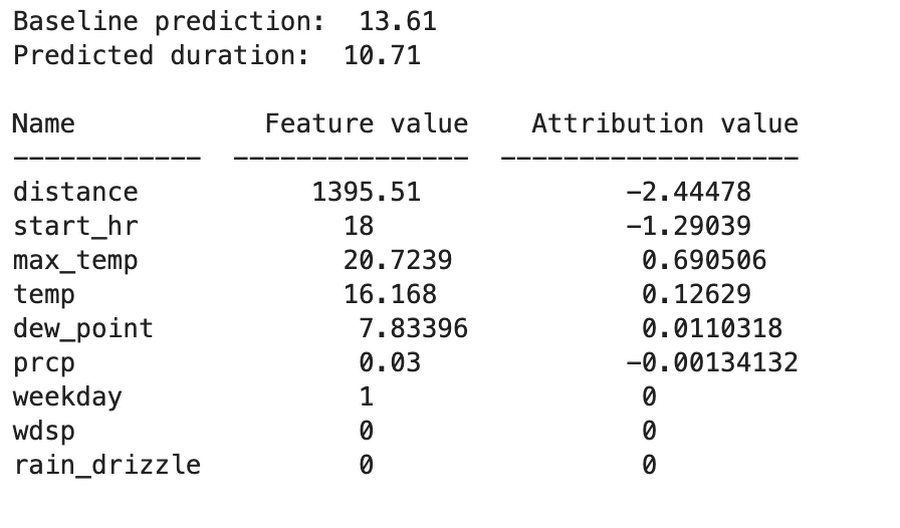
For the example below, our model returns the following attribution values, which are all relative to our model’s baseline value. Here we can see that distance was the most important feature, since it pushed our model’s prediction down from the baseline by 2.4 minutes. It also shows that the start time of the trip (18:00, or 6:00 pm) caused the model to shorten its predicted trip duration by 1.2 minutes:
Next, we’ll use the What-If Tool to see how our model is performing across a larger dataset of test examples and to visualize the attribution values.
Visualizing tabular attributions with the What-If Tool
The What-If Tool is an open-source visualization tool for inspecting any machine learning model, and the latest release includes features intended specifically for AI Explanations models deployed on AI Platform. You can find the code for connecting the What-If Tool to your AI Platform model in this demo notebook.
Here’s what you’ll see when you initialize the What-If Tool with a subset of our test dataset and model and click on a data point:
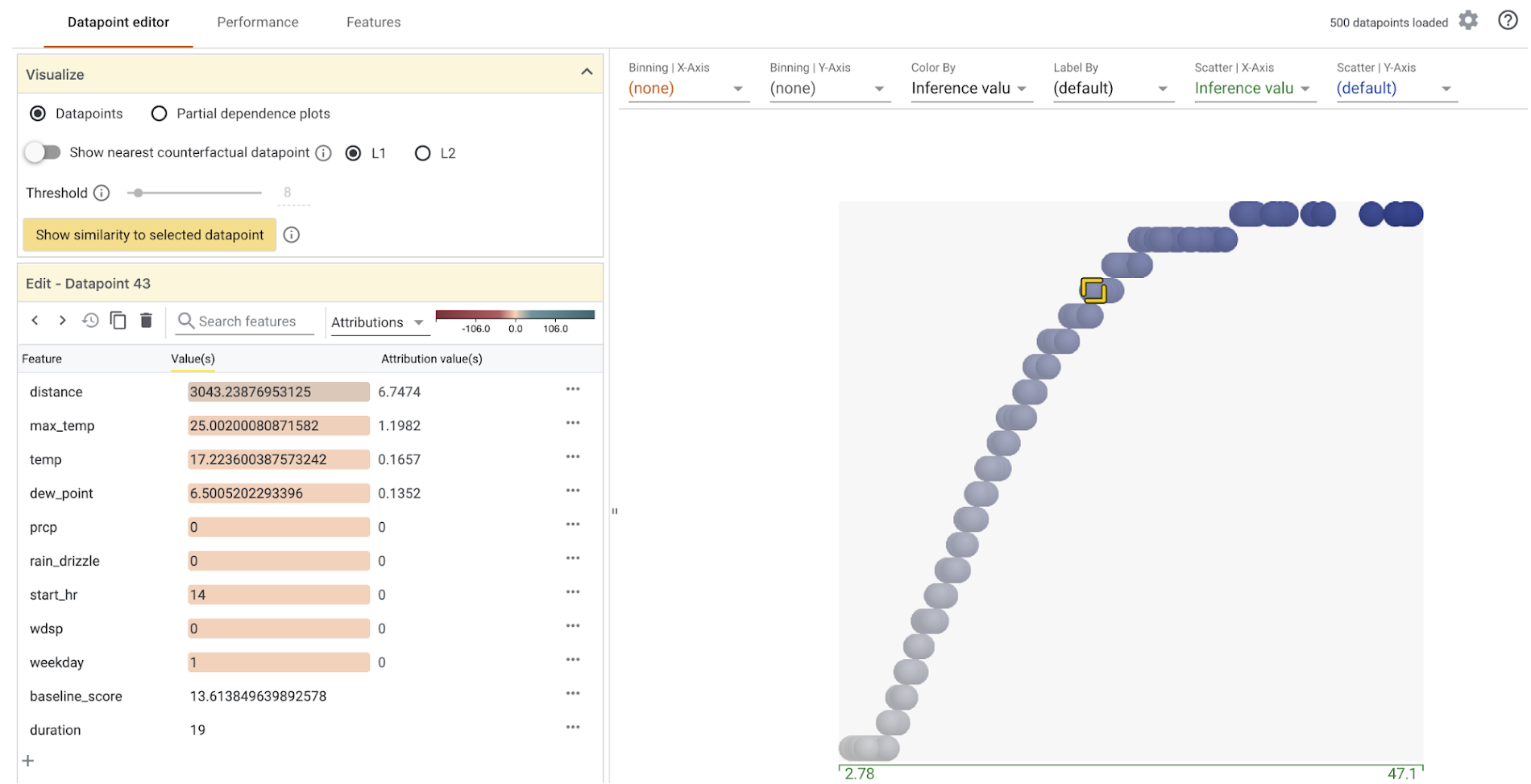
On the right, we see the distribution of all 500 test data points we’ve passed the What-If Tool. The Y-axis indicates the model’s predicted trip duration for these values. When we click on an individual data point, we can see all of the feature values for that data point along with each feature’s attribution value. This part of the tool also lets you change feature values and re-run the prediction to see how the updated feature value affected the model’s prediction:
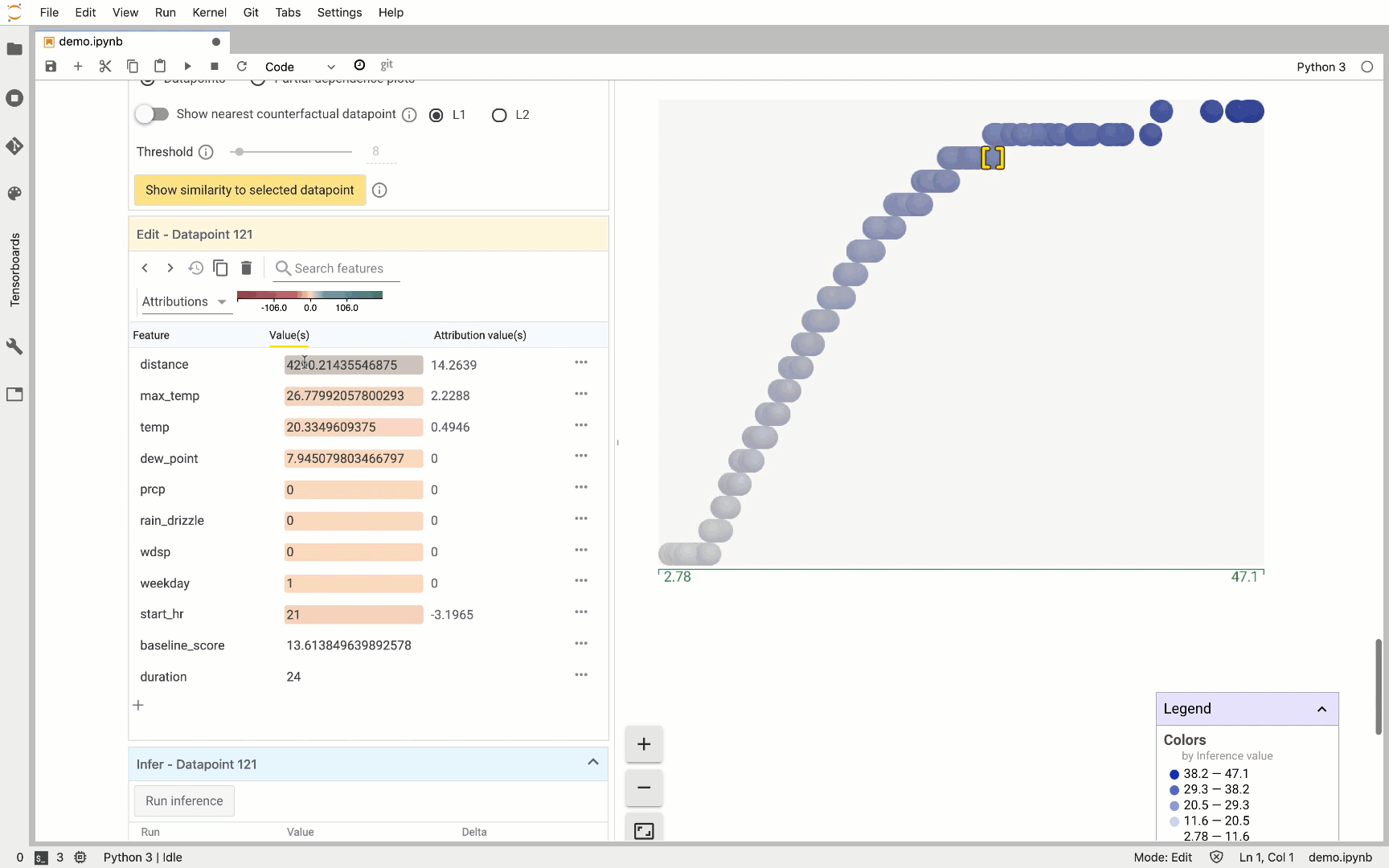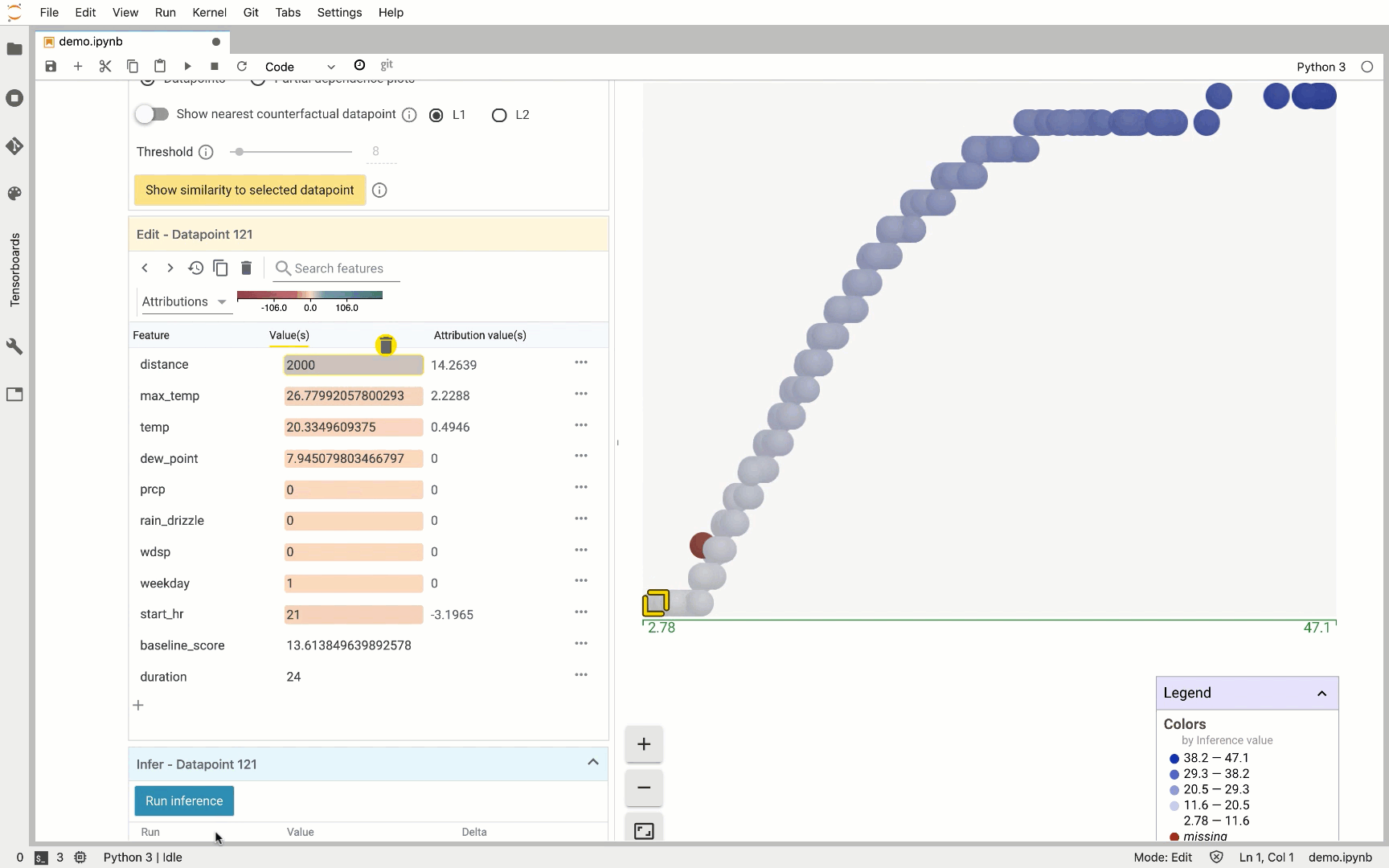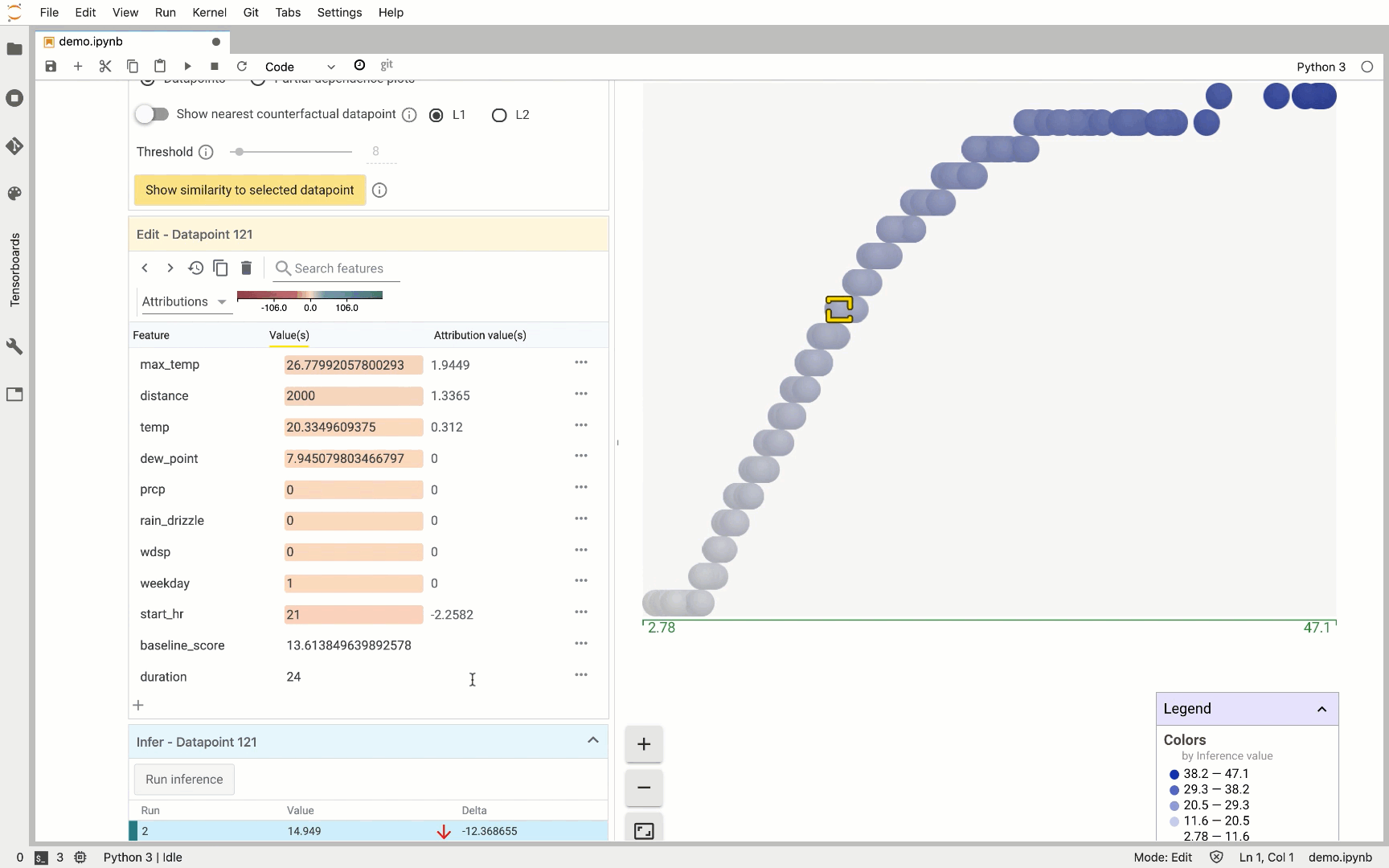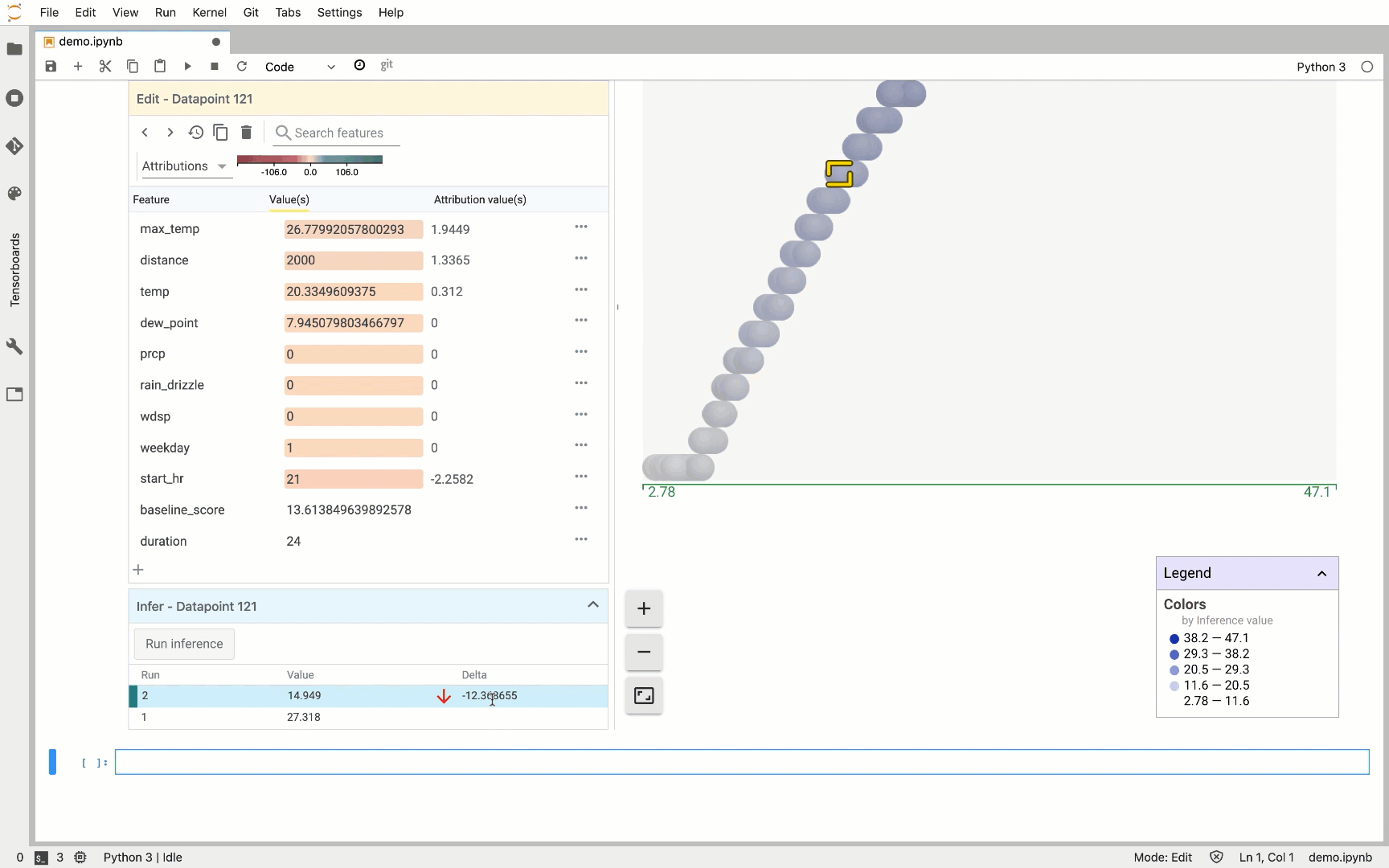
One of our favorite What-If Tool features is the ability to create custom charts and scatter plots, and the attributions data returned from AI Platform makes this especially useful. For example, here we created a custom plot where the X-axis measures the attribution value for trip distance and the Y-axis measures the attribution value for max temperature:
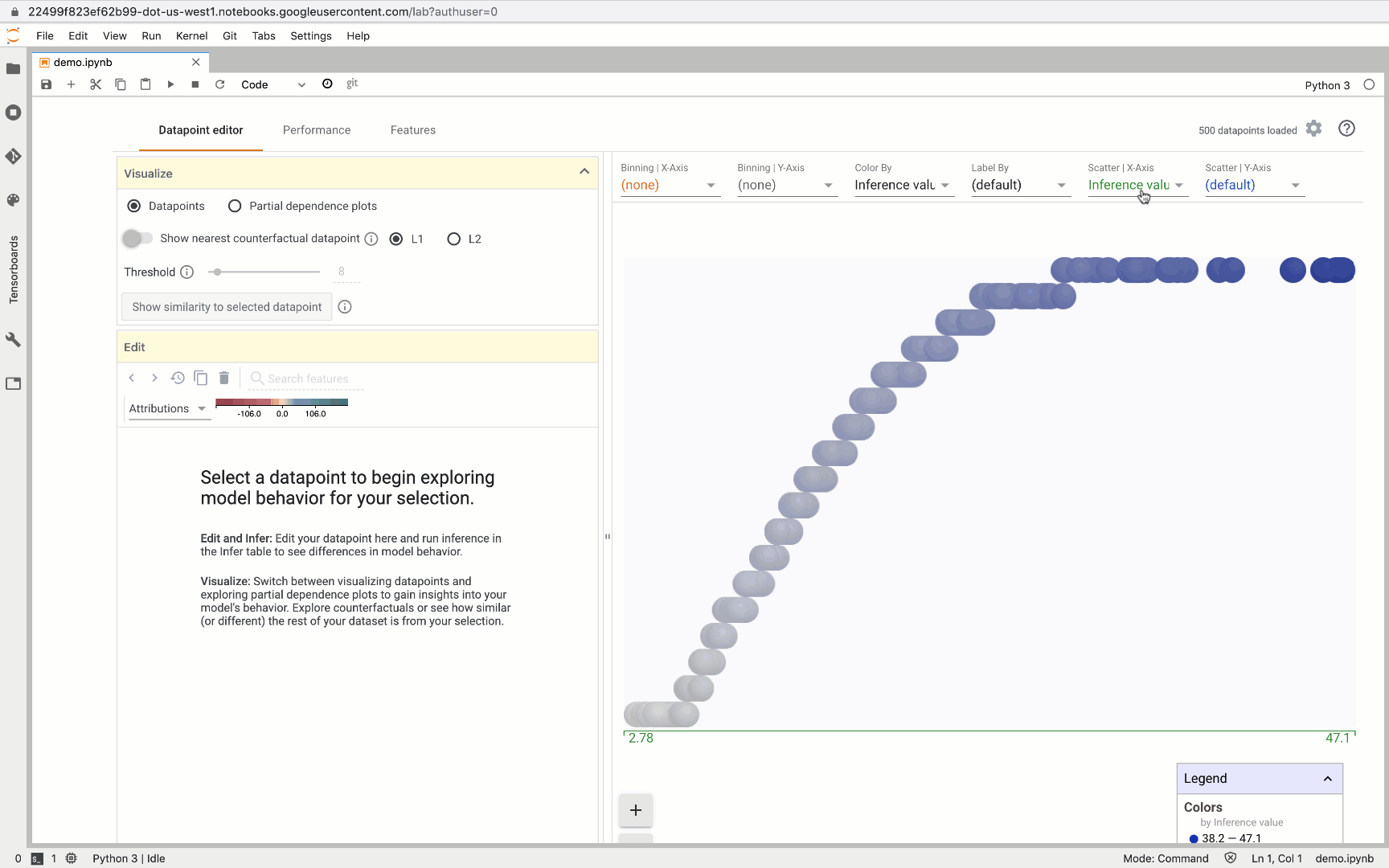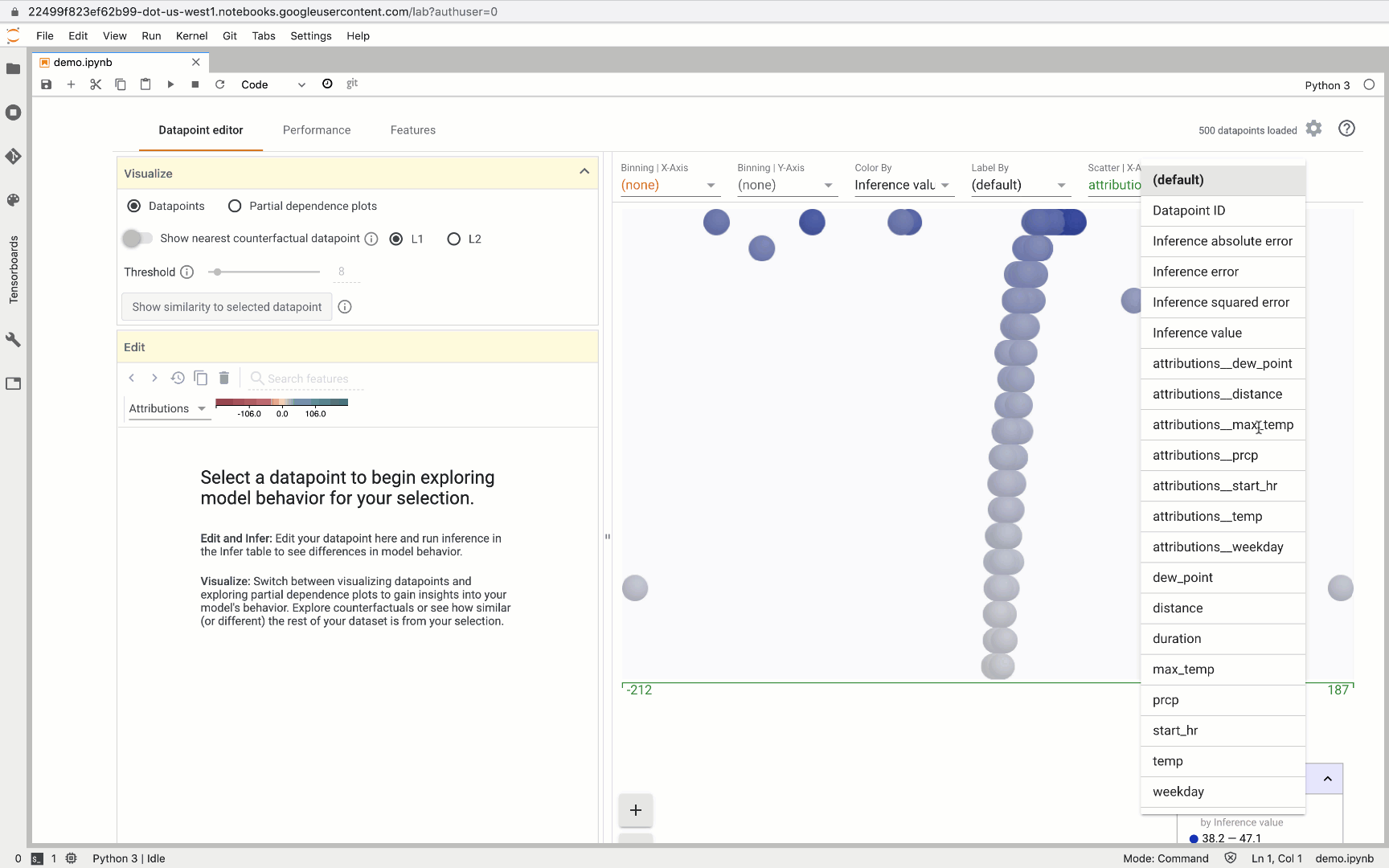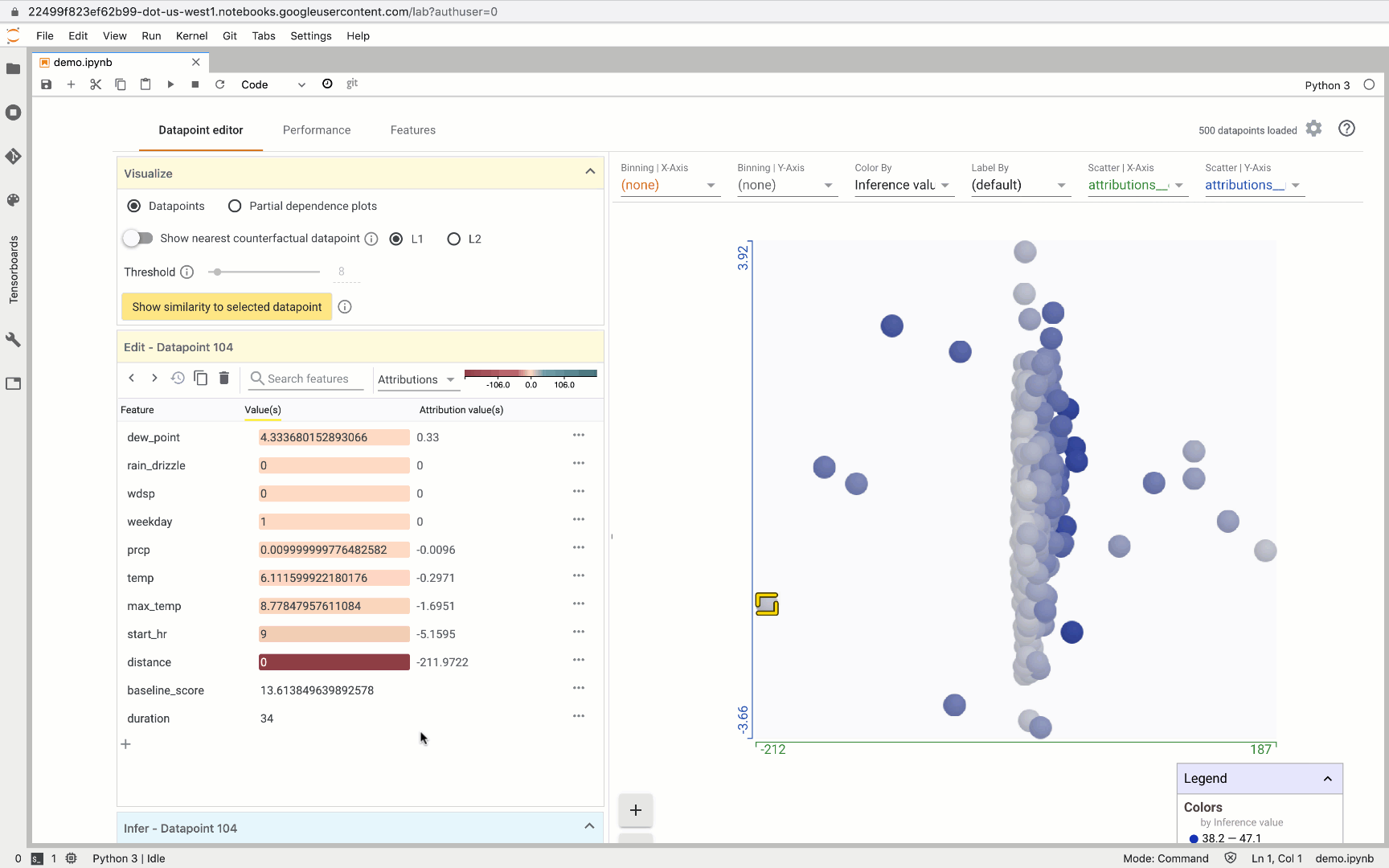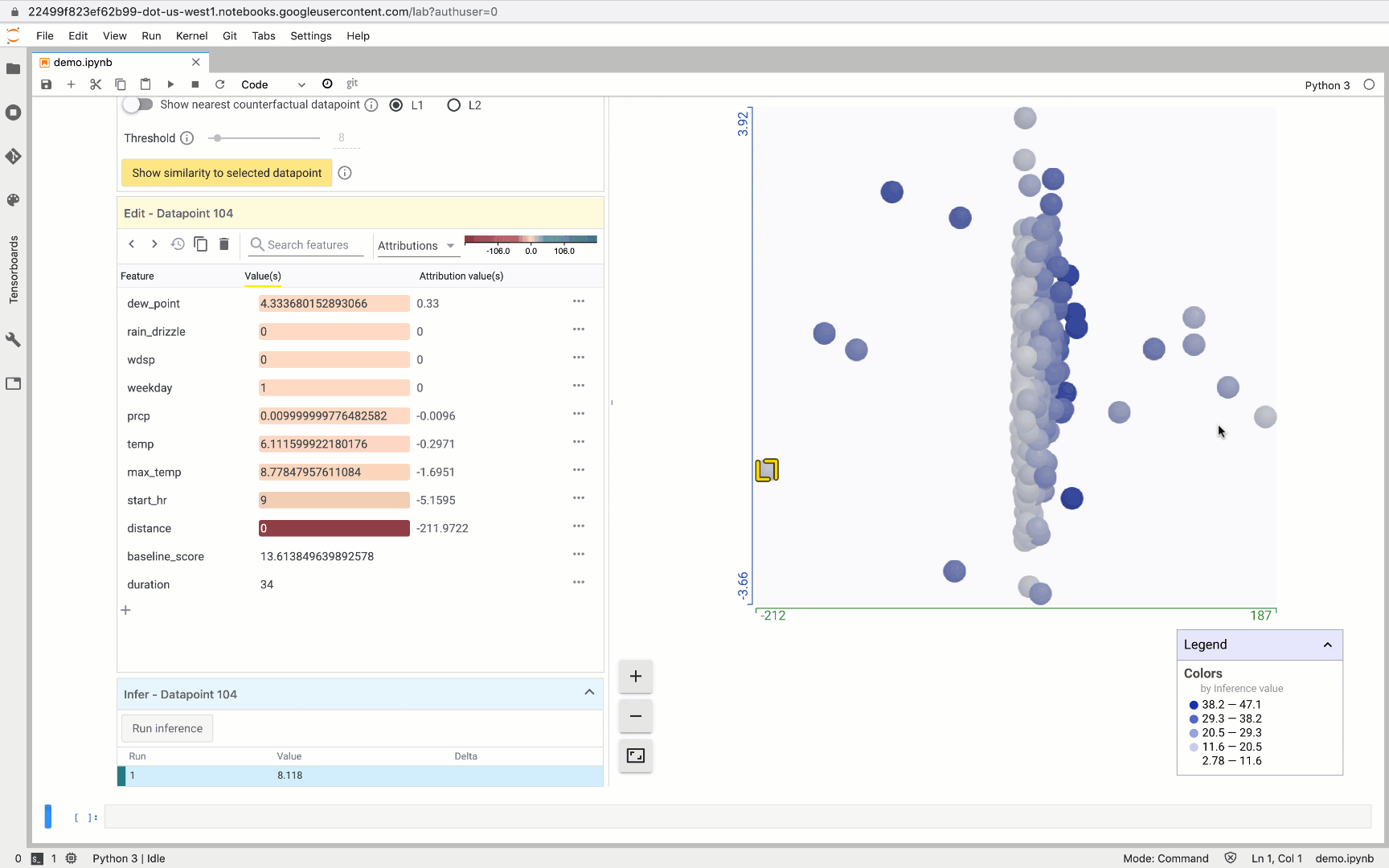
This can help us identify outliers. In this case, we show an example where the predicted trip duration was way off since the distance traveled was 0 but the bike was in use for 34 minutes.
There are many possible exploration ideas with the What-If Tool and AI Platform attribution values, like analyzing our model from a fairness perspective, ensuring our dataset is balanced, and more.
Next steps
Ready to dive into the code? These resources will help you get started with AI Explanations on AutoML Tables and AI Platform:
The AutoML Tables documentation and more detail on the local feature importance calculations
A sample notebook for building and deploying a tabular model to AI Platform
A blog post that also walks through using AutoML Tables from a notebook
A notebook that shows how to use the AutoML Tables Python client library to get prediction explanations
A video series on the What-If Tool
The keynote announcement of AI Explanations
If you’d like to use the same datasets we did, here is the London bikeshare data in BigQuery. We joined this with part of the NOAA weather dataset, which was recently updated to include even more data.
We’d love to hear what you thought of this post. You can find us on Twitter at @amygdala and @SRobTweets. If you have specific questions about using Explainable AI in your models, you can reach us here. And stay tuned for the next post in this series, which will cover explainability on image models.



