Introducing Cloud AI Platform Pipelines
Anusha Ramesh
Product Manager, TFX
Amy Unruh
Staff Developer Advocate
When you're just prototyping a machine learning (ML) model in a notebook, it can seem fairly straightforward. But when you need to start paying attention to the other pieces required to make a ML workflow sustainable and scalable, things become more complex. A machine learning workflow can involve many steps with dependencies on each other, from data preparation and analysis, to training, to evaluation, to deployment, and more. It’s hard to compose and track these processes in an ad-hoc manner—for example, in a set of notebooks or scripts—and things like auditing and reproducibility become increasingly problematic.
Today, we’re announcing the beta launch of Cloud AI Platform Pipelines. Cloud AI Platform Pipelines provides a way to deploy robust, repeatable machine learning pipelines along with monitoring, auditing, version tracking, and reproducibility, and delivers an enterprise-ready, easy to install, secure execution environment for your ML workflows.
AI Platform Pipelines gives you:
Push-button installation via the Google Cloud Console
Enterprise features for running ML workloads, including pipeline versioning, automatic metadata tracking of artifacts and executions, Cloud Logging, visualization tools, and more
Seamless integration with Google Cloud managed services like BigQuery, Dataflow, AI Platform Training and Serving, Cloud Functions, and many others
Many prebuilt pipeline components (pipeline steps) for ML workflows, with easy construction of your own custom components
AI Platform Pipelines has two major parts—the enterprise-ready infrastructure for deploying and running structured ML workflows that are integrated with GCP services; and the pipeline tools for building, debugging, and sharing pipelines and components.
In this post, we’ll highlight the features and benefits of using AI Platform Pipelines to host your ML workflows, show its tech stack, and then describe some of its new features.
Benefits of using AI Platform Pipelines
Easy installation and management
You access AI Platform Pipelines by visiting the AI Platform panel in the Cloud Console.
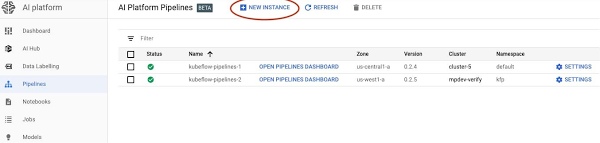
The installation process is lightweight and push-button, and the hosted model simplifies management and use. AI Platform Pipelines runs on a Google Kubernetes Engine (GKE) cluster. A cluster is automatically created for you as part of the installation process, but you can use an existing GKE cluster if you like. The Cloud AI Platform UI lets you view and manage all your clusters. You can also delete the Pipelines installation from a cluster and then reinstall, retaining the persisted state from the previous installation while updating the Pipelines version.
Easy authenticated access
AI Platform Pipelines gives you secure and authenticated access to the Pipelines UI via the Cloud AI Platform UI, with no need to set up port-forwarding. You can also give access to other members of your team.
It is similarly straightforward to programmatically access a Pipelines cluster via its REST API service. This makes it easy to use the Pipelines SDK from Cloud AI Platform notebooks, for example, to perform tasks like defining pipelines or scheduling pipeline run jobs.
The AI Platform Pipelines tech stack
With AI Platform Pipelines, you specify a pipeline using the Kubeflow Pipelines (KFP) SDK, or by customizing the TensorFlow Extended (TFX) Pipeline template with the TFX SDK. The SDK compiles the pipeline and submits it to the Pipelines REST API. The AI Pipelines REST API server stores and schedules the pipeline for execution. AI Pipelines uses the Argo workflow engine to run the pipeline and has additional microservices to record metadata, handle components IO, and schedule pipeline runs. Pipeline steps are executed as individual isolated pods in a GKE cluster, enabling the Kubernetes-native experience for the pipeline components. The components can leverage Google CLoud services such as Dataflow, AI Platform Training and Prediction, BigQuery, and others, for handling scalable computation and data processing. The pipelines can also contain steps that perform sizeable GPU and TPU computation in the cluster, directly leveraging GKE autoscaling and node autoprovisioning.
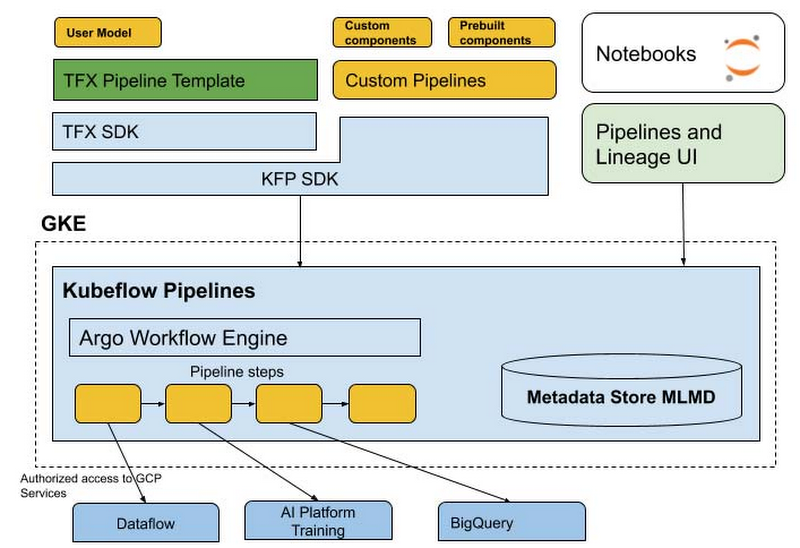
Let’s look at parts of this stack in more detail.
SDKs
Cloud AI Platform pipelines supports two SDKs to author ML pipelines: the Kubeflow Pipelines SDK—part of the Kubeflow OSS project—and the TFX SDK.
Over time, these two SDK experiences will merge. The TFX SDK will support framework-agnostic operations available in the KFP SDK. And we will provide transition paths that make it easy for existing KFP SDK users to upgrade to the merged SDK.
Why have two different SDKs?
The Kubeflow Pipelines SDK is a lower-level SDK that’s ML-framework-neutral, and enables direct Kubernetes resource control and simple sharing of containerized components (pipeline steps).
The TFX SDK is currently in preview mode and is designed for ML workloads. It provides a higher-level abstraction with prescriptive, but customizable components with predefined ML types that represent Google best practices for durable and scalable ML pipelines. It also comes with a collection of customizable TensorFlow-optimized templates developed and used internally at Google, consisting of component archetypes, for production ML.
You can configure the pipeline templates to build, train, and deploy your model with your own data; automatically perform schema inference, data validation, model evaluation, and model analysis; and automatically deploy your trained model to the AI Platform Prediction service.
When choosing the SDK to run your ML pipelines with the AI Platform Pipelines beta, we recommend:
TFX SDK and its templates for E2E ML Pipelines based on TensorFlow, with customizable data pre-processing and training code.
Kubeflow Pipelines SDK for fully custom pipelines, or pipelines that use prebuilt KFP components, which support access to a wide range of GCP services.
The metadata store and MLMD
AI Platform Pipeline runs include automatic metadata tracking, using ML Metadata (MLMD), which is a library for recording and retrieving metadata associated with ML developer and data scientist workflows. It’s part of TensorFlow Extended (TFX), but it’s designed to also be used independently.
The automatic metadata tracking logs the artifacts used in each pipeline step, pipeline parameters, and the linkage across the input/output artifacts, as well as the pipeline steps that created and consumed them.
New Pipelines features
The beta launch of AI Platform Pipelines includes a number of new features, including support for template-based pipeline construction, versioning, and automatic artifact and lineage tracking.
Build your own ML pipeline with TFX templates
To make it easier for developers to get started with ML pipeline code, the TFX SDK provides templates, or scaffolds, with step-by-step guidance on building a production ML pipeline for your own data. With a TFX template, you can incrementally add different components to the pipeline and iterate on them.
TFX templates can be accessed from the AI Platform Pipelines Getting Started page in the Cloud Console. The TFX SDK currently provides a template for classification problem types and is optimized for TensorFlow, with more templates on the way for different use cases and problem types.
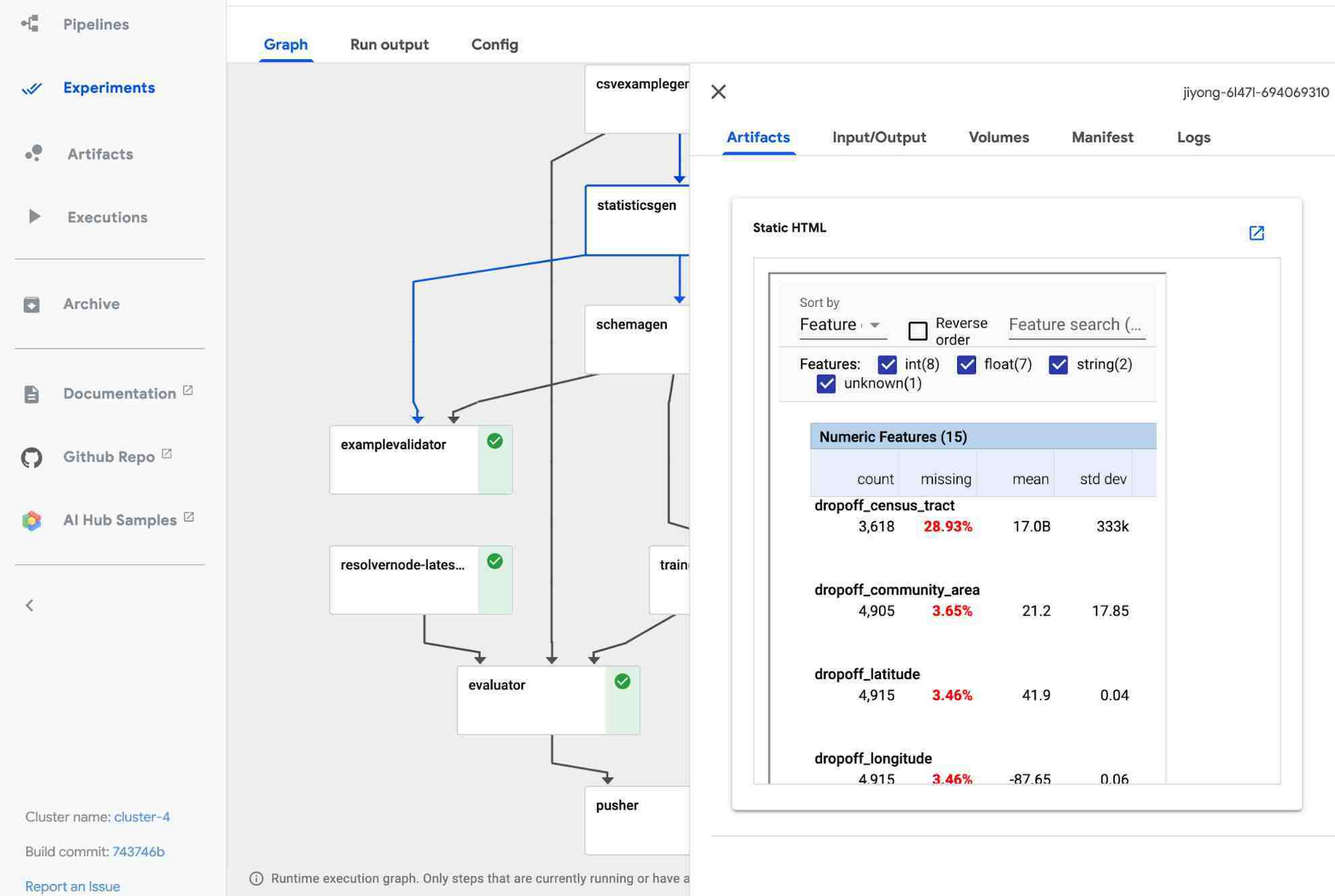
A TFX pipeline typically consists of multiple pre-made components for every step of the ML workflow. For example, you can use ExampleGen for data ingestion, StatisticsGen to generate and visualize statistics of your data, ExampleValidator and SchemaGen to validate data, Transform for data preprocessing, Trainer to train a TensorFlow model, and so on. The AI Platform Pipelines UI lets you visualize the state of various components in the pipeline, dataset statistics, and more, as shown below.
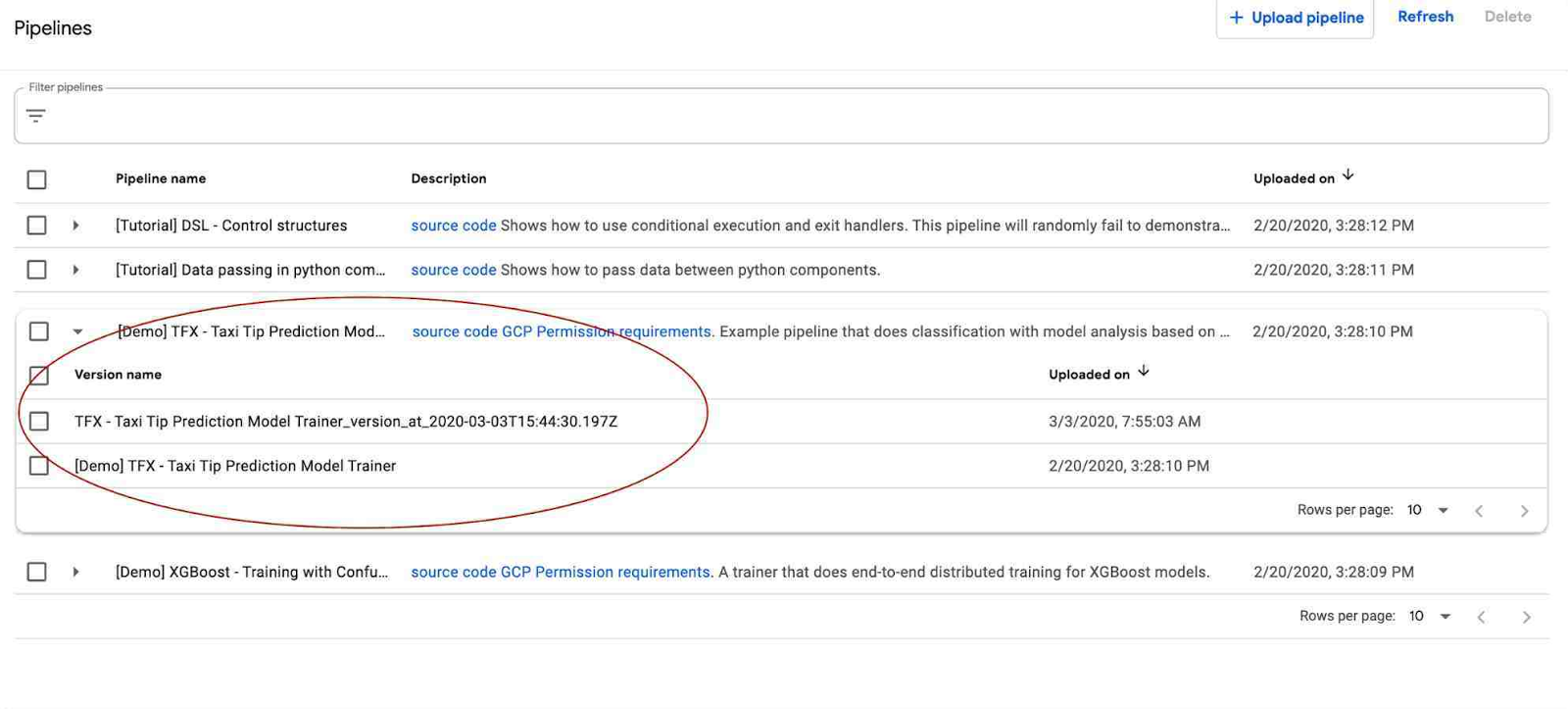
Pipelines versioning
AI Platform Pipelines supports pipeline versioning. It lets you upload multiple versions of the same pipeline and group them in the UI so you manage semantically-related workflows together.
Artifact and lineage tracking
AI Platform Pipelines supports automatic artifact and lineage tracking powered by ML Metadata, and rendered in the UI.
Artifact Tracking: ML workflows typically involve creating and tracking multiple types of artifacts—things like models, data statistics, model evaluation metrics, and many more. With AI Platform Pipelines UI, it’s easy to keep track of artifacts for a ML pipeline.
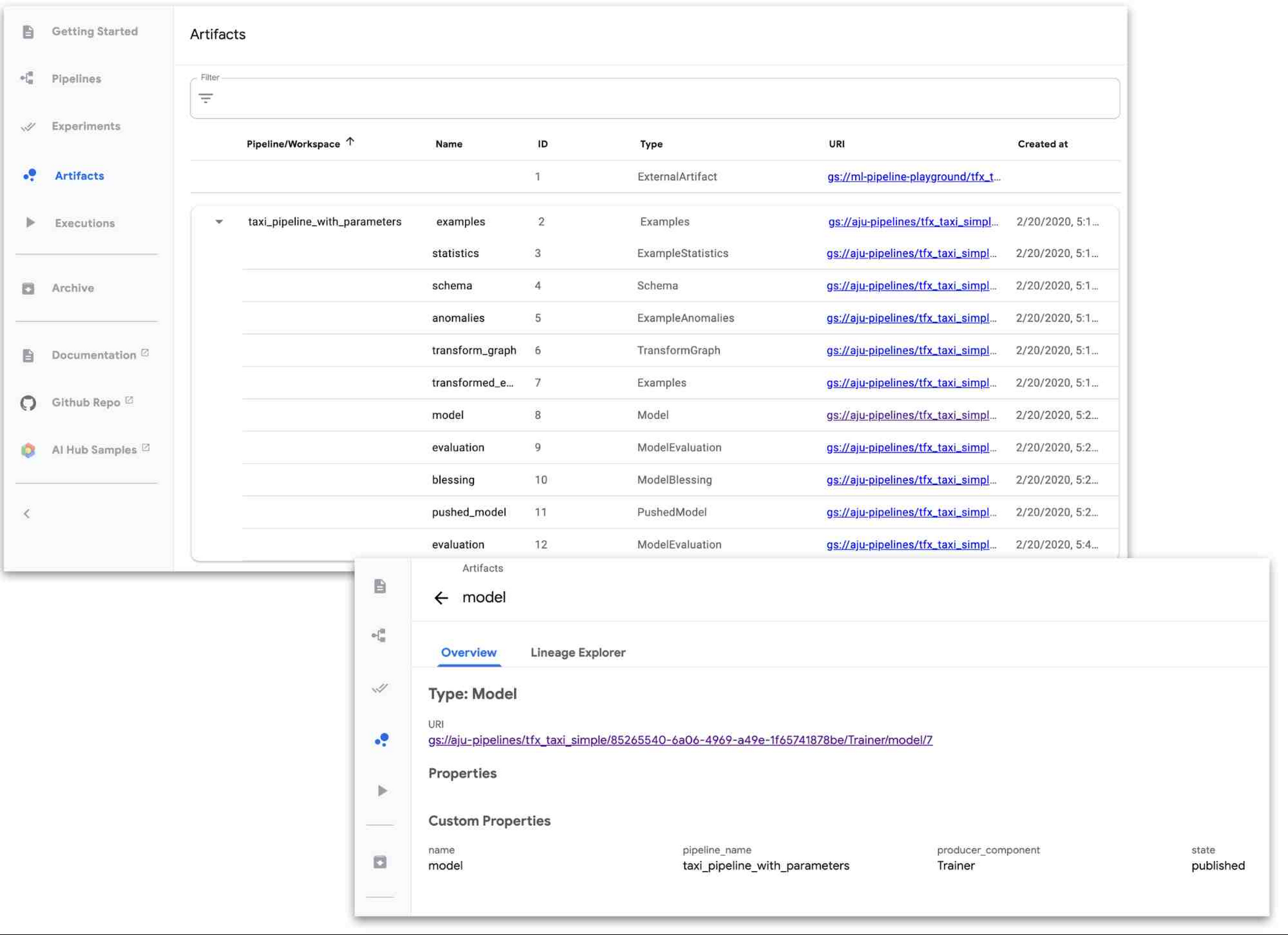
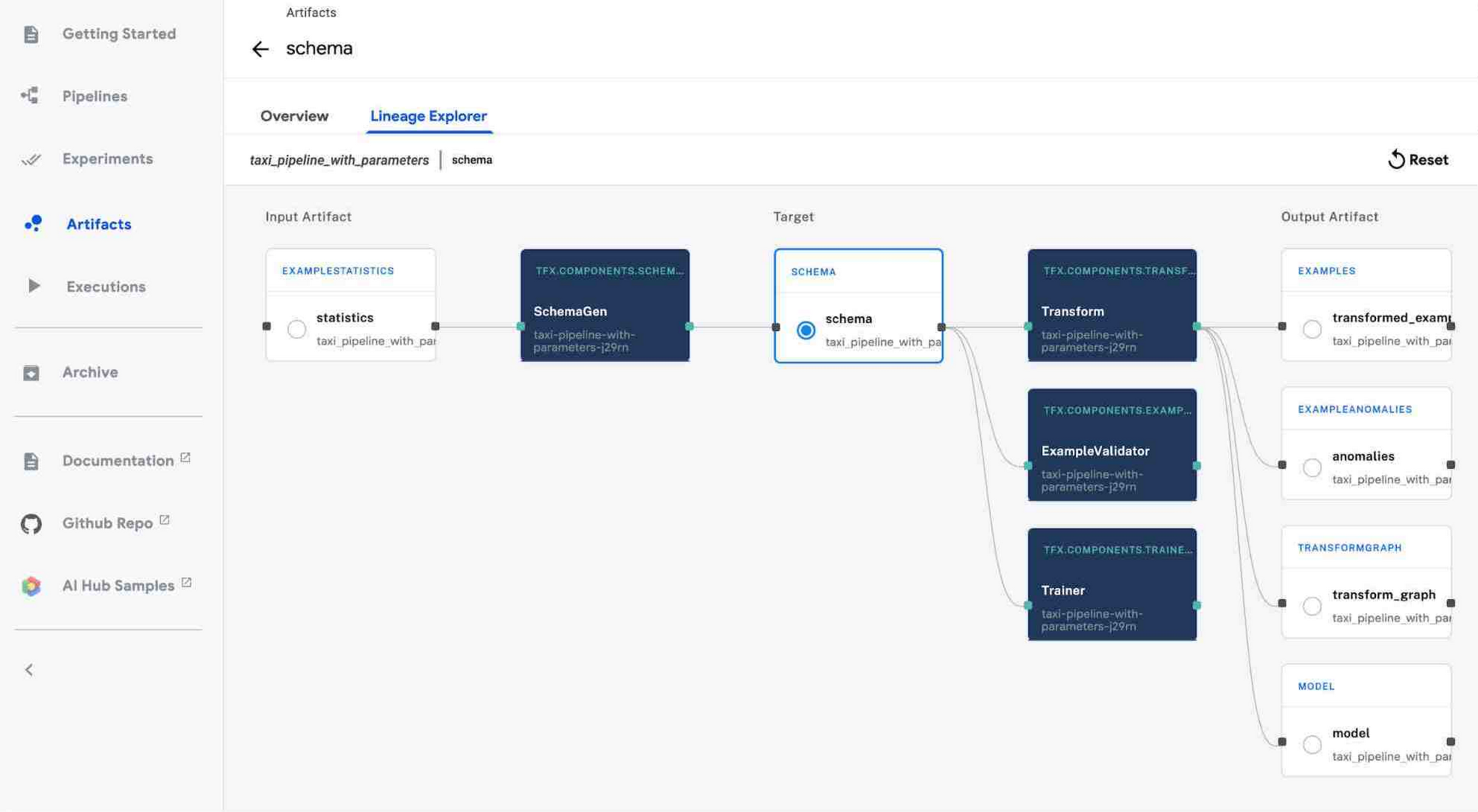
Lineage tracking: Just like you wouldn’t code without version control, you shouldn’t train models without lineage tracking. Lineage Tracking shows the history and versions of your models, data, and more. You can think of it like an ML stack trace. Lineage tracking can answer questions like: What data was this model trained on? What models were trained off of this dataset? What are the statistics of the data that this model trained on?
Other improvements
The recent releases of the Kubeflow Pipelines SDK include many other improvements. A couple worth noting are improved support for building Pipeline components from Python functions, and easy specification of component inputs and outputs, including the ability to easily share large datasets between pipeline steps.
Getting started
To get started, visit the Google Cloud Console, navigate to AI Platform > Pipelines, and click on NEW INSTANCE. You can choose whether you want to use an existing GKE cluster or have a new one created for you as part of the installation process. If you create a new cluster, you can check a box to allow access to any Cloud Platform service from your pipelines. (If you don’t, you can specify finer-grained access with an additional step. Note that demo pipelines and TFX templates require access to Dataflow, AI Platform, and Cloud Storage.)
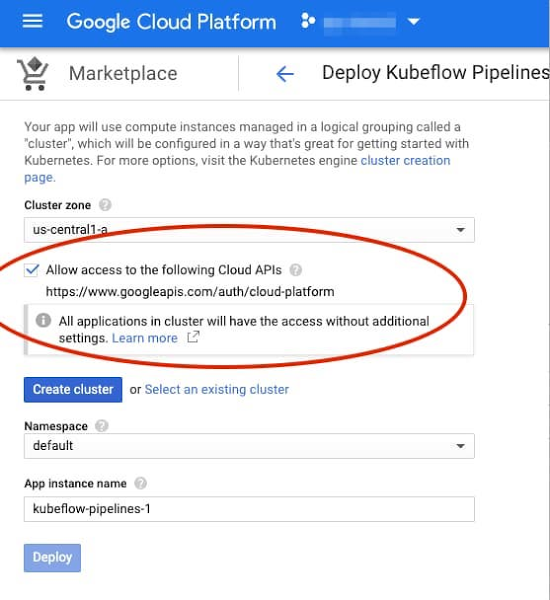
See the instructions for more detail.
If you prefer to deploy Kubeflow Pipelines to a GKE cluster via the command line, those deployments are also accessible under AI Platform > Pipelines in the Cloud Console.
Once your AI Platform Pipelines cluster is up and running, click its OPEN PIPELINES DASHBOARD link. From there, you can explore the Getting Started page, or click on Pipelines in the left navigation bar to run one of the examples. The <add name> pipeline shows an example built using the ML pipeline templates described above. You can also build, upload, and run one of your own pipelines.
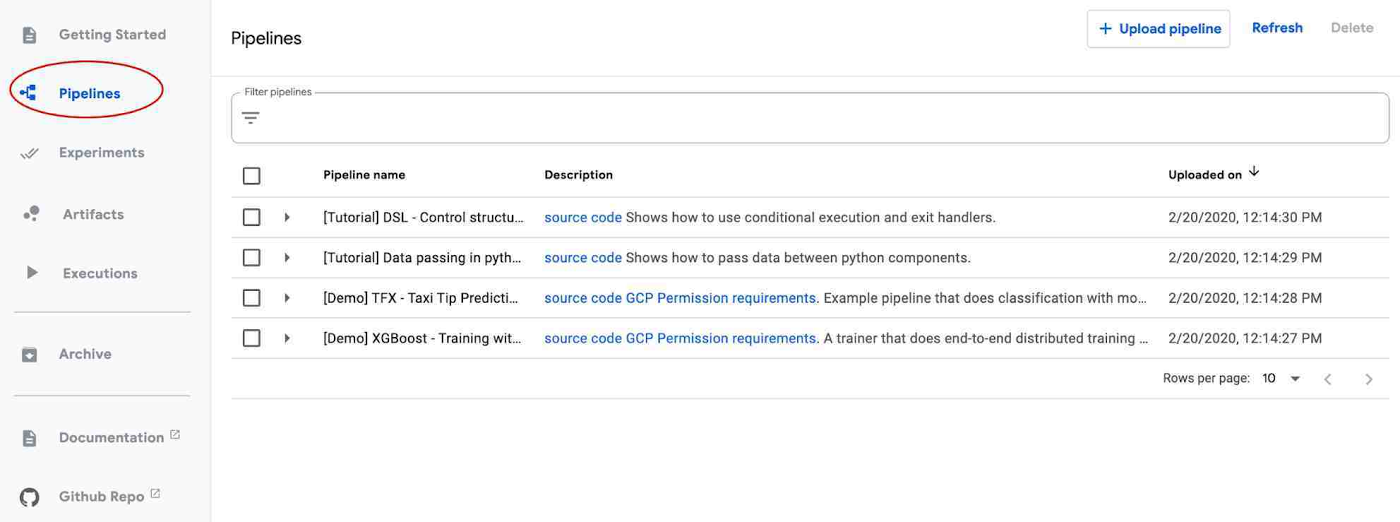
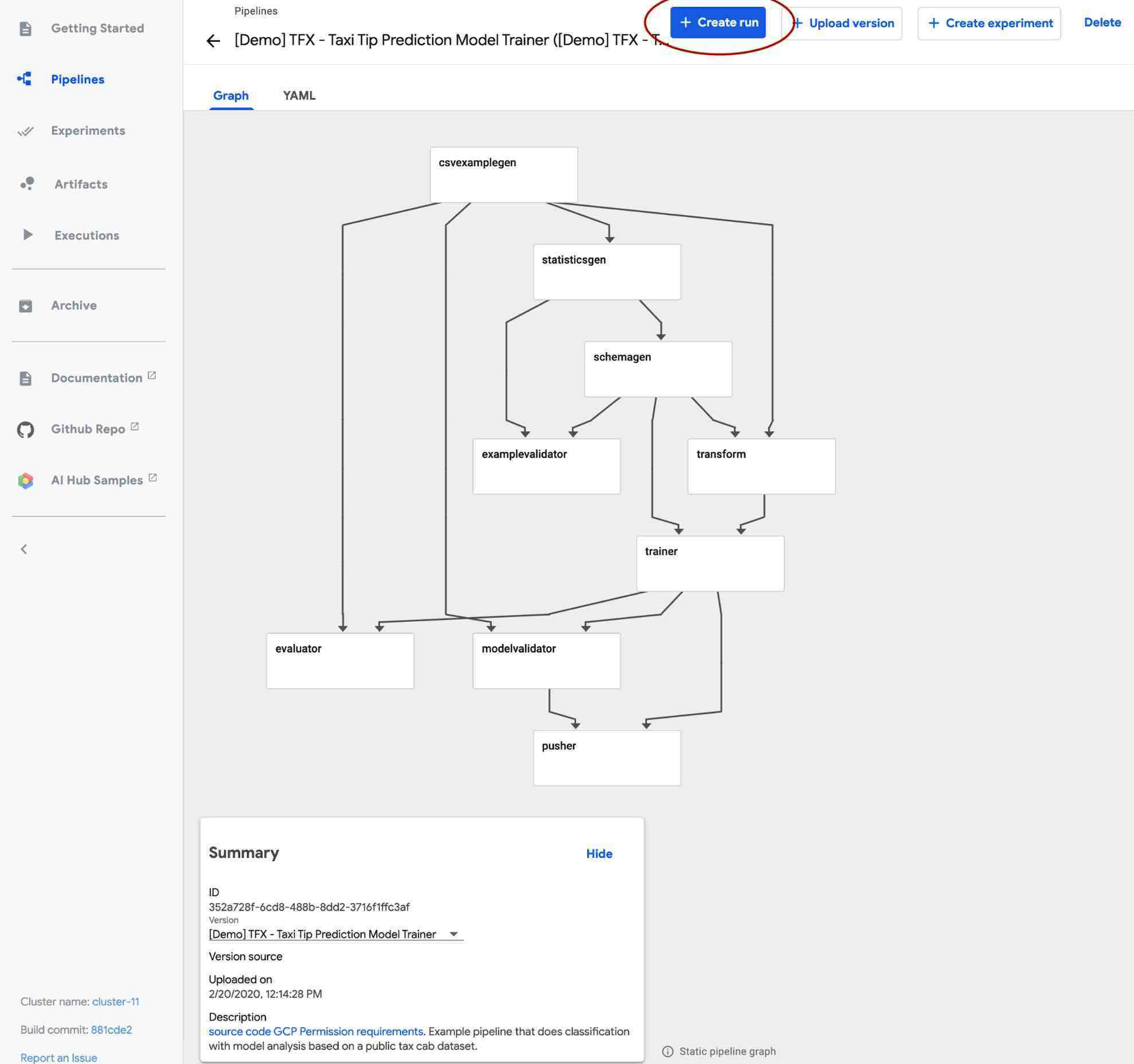
The static graph for a pipeline. (The Templates section above shows an image of a pipeline’s runtime graph, including visualizations it has generated).
Once a pipeline is running—or after it has finished—you can view its runtime graph, logs, output visualizations, artifacts, execution information, and more. See the documentation for more details.
What’s next?
We have some new Pipelines features coming soon, including support for:
Multi-user isolation, so that each person accessing the Pipelines cluster can control who can access their pipelines and other resources
Workload identity, to support transparent access to GCP services
Easy, UI-based setup of off-cluster storage of backend data—including metadata, server data, job history, and metrics—for larger scale deployments and so that it can persist after cluster shutdown
Easy cluster upgrades
More templates for authoring ML workflows
To get started with AI Platform Pipelines, try some of the example pipelines included in the installation, or check out the “Getting Started” landing page of the Pipelines Dashboard. These notebooks also provide more examples of pipelines written using the KFP SDK.




