How Kaggle solved a spam problem in 8 days using AutoML
Will Cukierski
Staff Developer Advocate and Head of Competitions, Kaggle
Kaggle is a data science community of nearly 5 million users. In September of 2019, we found ourselves under a sudden siege of spam traffic that threatened to overwhelm visitors to our site. We had to come up with an effective solution, fast. Using AutoML Natural Language on Google Cloud, Kaggle was able to train, test, and deploy a spam detection model to production in just eight days. In this post, we’ll detail our success story about using machine learning to rapidly solve an urgent business dilemma.
A spam dilemma
Malicious users were suddenly creating large numbers of Kaggle accounts in order to leave spammy search engine optimization (SEO) content in the user bio section. Search engines were indexing these bios, and our existing spam detection heuristics were failing to flag them. In short, we faced a growing and embarrassing predicament.
Our problem was context. Kaggle is a community focused on data science and machine learning. As a result of our topical data-science focus, a user bio that seems harmless in isolation may be the work of a spammer. Here is a real example of one such bio:
I am a personal injury lawyer in Chicago. I help individuals and families in cases involving serious injuries and wrongful death. Many of my cases involve car accidents, nursing home abuse, and medical malpractice.
Such a bio may fit in on a forum of legal professionals, but on the Kaggle site it’s a mark of an SEO spammer. This content also lacks the typical keywords and unsavory topics that one might expect to find in spam. This context meant that stopping the spam required more than a generic model; we needed a solution that could take our Kaggle-specific context into account.
We had the intuition that machine learning could handle this problem, but building natural language models to deal with spam was not anyone at Kaggle’s day job. We feared weeks of late nights slogging towards a good-enough solution—spam models require very high accuracy because of the high cost of miscategorizing a legitimate user. Even with a usable prototype running in R or Python, there was the looming frustration of deploying it in Kaggle’s C# codebase. As we planned out our options, we had an unconventional idea: what about trying AutoML?
Enter AutoML
True to its name, AutoML performs automated machine learning: evaluating huge numbers of neural network architectures to determine the most effective model for a problem. We first witnessed the potential of the AutoML suite of products when a Google team used it to take second place at the 2019 KaggleDays hackathon. On a whim, we decided to pass our bio problem through the AutoML Natural Language Classification API. We could readily generate a labeled training dataset because we had existing examples of bios belonging to known-legitimate users:

After uploading these bios, clicking the “Start Training” button, and waiting a few hours, we received an email that training was complete. Building models is normally a process that involves many failures, but the results were astoundingly impressive for a first attempt, with precision (how “accurate” the model is) and recall (how “thorough” the model is) above 99%.
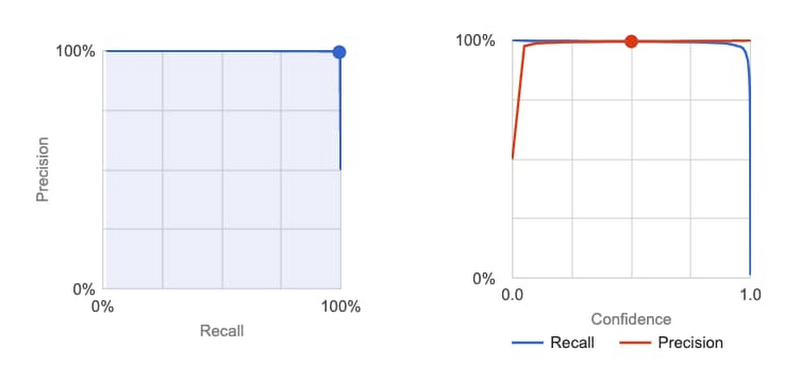
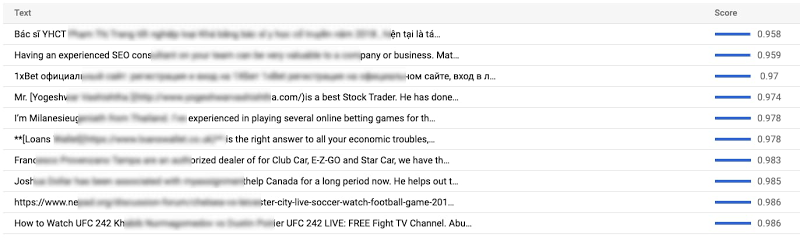
We manually inspected the performance, ran test examples through the model, and determined it would be immediately suitable to deploy in production. It successfully picked up on a wide variety of spammy content types (some identifying information and language is blurred out):
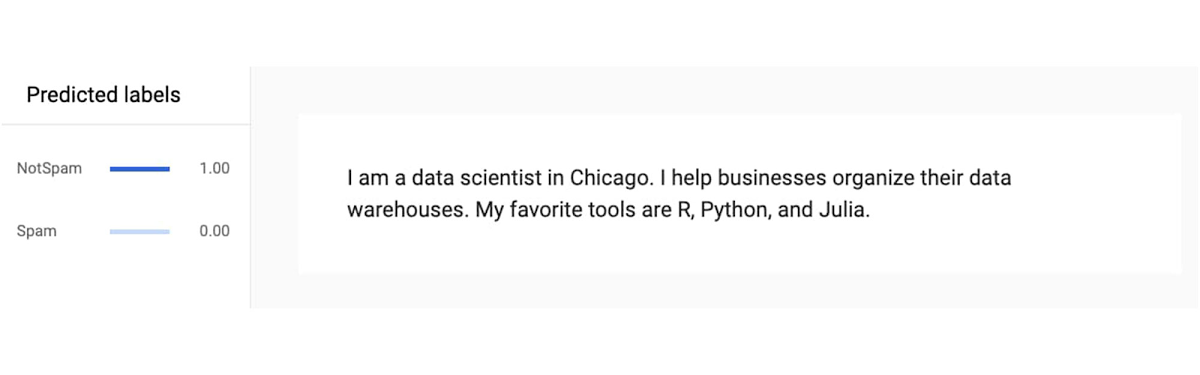
Returning to our previous example on the importance of context, the model gives the personal injury lawyer a 98% confidence of being spam:

Meanwhile, it has full confidence that the data scientist equivalent is allowable:
On top of being accurate, AutoML afforded a major advantage when the time came to deploy the model. When training was finished, the model was already hosted and exposed via an API. Kaggle simply had to write a quick shim to call this API from our application.
It took only eight days from when we started working on this problem to when we deployed a model serving live traffic. It required no advanced skills in deep learning or natural language processing. The model has since made thousands of correct decisions and greatly reduced our spam-related traffic.
While this story was about spam detection, the takeaway isn’t just that you can use AutoML for spam. AutoML has the potential to replicate this success story across the thousands of bespoke image, text, or tabular problems that businesses face. AutoML can step in when off-the-shelf models are insufficient, when you want to test a hunch but don’t have months to dedicate to it, or if you’re simply not a deep learning expert. The combination of high accuracy, rapid iteration, and smooth deployment can make AutoML an attractive approach to developing machine learning solutions for a wide range of business problems and needs.



