AlphaFold のバッチ推論を Vertex AI Pipelines で実行する

Google Cloud Japan Team
※この投稿は米国時間 2022 年 8 月 4 日に、Google Cloud blog に投稿されたものの抄訳です。
本日、病気の治療法の創出から新しい合成生体材料の製造まで、バイオファーマ分野の研究を加速させるため、Vertex AI Pipelines を使用して DeepMind の AlphaFold タンパク質構造予測を大規模に実行する方法を実証する、新しい Vertex AI ソリューションを発表いたします。
タンパク質の構造が解明され、細胞内での役割が把握できれば、サイエンティストは細胞内での役割に応じてタンパク質機能を調節可能な薬を開発できます。Alphabet 傘下の AI 研究機関である DeepMind は、AlphaFold システムを作成し、データ サイエンティストやその他の研究者が、タンパク質の形状を正確に予測することを大規模に支援することによって、この分野の研究を推進してきました。
2020 年、Critical Assessment of Techniques for Protein Structure Prediction(CASP14)のテストで、DeepMind は非常に正確にタンパク質構造を予測する AlphaFold のバージョンを発表し、「タンパク質の折りたたみ問題」は解決したと専門家は宣言しました。翌年、DeepMind は AlphaFold 2.0 システムをオープンソース化し、その後すぐ、Google Cloud は AlphaFold と Vertex AI Workbench を統合して、インタラクティブなテストを容易にするソリューションをリリースしました。これにより、多くのデータ サイエンティストが AlphaFold を活用して効率的に作業できるようになり、その土台があってこそ本日の発表ができます。
先週、DeepMind が欧州バイオインフォマティクス研究所(EMBL-EBI)と協力して、科学的に知られているカタログ化されたほぼすべてのタンパク質の予測構造をリリースすることで、AlphaFold はさらに意義のある前進を遂げました。今回のリリースで、AlphaFold のデータベースは、約 100 万構造から 2 億構造以上に拡張され、これにより、私たちの生物学に対する理解は大幅に向上する可能性があります。継続的な成長を遂げる AlphaFold データベースと Vertex AI の効率性を組み合わせることで、世界中の研究者がどのような発見をするのか楽しみです。
今回の記事では、このソリューションを使用したテストの開始方法を説明し、ハードウェアの最適な選択によるコストの低減、テストの追跡、リネージ、メタデータ管理による再現性、並列化による実行時間の短縮などのメリットについて調査しました。
Vertex AI 上で AlphaFold を実行する背景
タンパク質の構造予測を行うことは、コンピューティング集約的なタスクになります。CPU と ML のアクセラレータ リソースを大量に必要とし、コンピューティングには数時間から数日かかることさえあります。推論ワークフローを大規模に実行するのは簡単なことではありません。推論にかかる経過時間の最適化、ハードウェア リソースの使用率の最適化、テストの管理など困難な課題があります。Google の新しい Vertex AI ソリューションは、このような課題に対処できるように設計されています。
このソリューションがこれらの課題にどのように対処するかについて理解を深めるために、AlphaFold の推論ワークフローを確認してみましょう。
特徴の前処理。入力タンパク質配列(FASTA 形式)を使用して、生物全体の遺伝子配列やタンパク質のテンプレート データベースを、一般的なオープンソース ツールを使って検索します。こうしたツールには、MGnify と UniRef90 を使った JackHMMER、Uniclust30 と BFD を使った HHBlits、および PDB70 を使った HHSearch があります。検索の出力(複数の配列アラインメント(MSA)と構造テンプレートで構成される)と入力配列は、推論モデルへの入力として処理されます。特徴の前処理のステップは、CPU プラットフォームでのみ実行可能です。フルサイズのデータベースを使用している場合、この処理の完了までに数時間かかることがあります。
モデルの推論。AlphaFold 構造予測システムには、単量体構造予測モデル、多量体構造予測モデル、CASP 用に微調整されたモデルなど、一連の事前トレーニング済みモデルが含まれています。推論時に、特定のタイプ(単量体モデルなど)の 5 つのモデルを同じ入力セットで個別に実行します。デフォルトでは、単量体モデルの折りたたみでは 1 モデルにつき 1 つの予測が、多量体の折りたたみでは 1 モデルにつき 5 つの予測が生成されます。推論ワークフローのこのステップは、コンピューティングにかかる負荷が非常に高いため、GPU または TPU のアクセラレーションが必要になります。
(オプション)構造緩和。推論モデルによって返される構造内における構造の違反と衝突を解決するために、構造緩和のステップを実行します。AlphaFold システムでは、OpenMM 分子力学シミュレーション パッケージを使用し、拘束されたエネルギーの極小化を実行します。また、緩和は CPU のみのプラットフォームでも実行できますが、コンピューティングにかかる負荷が非常に高いステップのため、GPU を使用することで処理を高速化できます。
Vertex AI ソリューション
Vertex AI ソリューションを活用した AlphaFold バッチ推論では、以下の最適化に重点を置くことで、AlphaFold 推論を効率的かつ大規模に実行できます。
独立したステップを並列化することによる推論ワークフローの最適化。
各ステップを最適なハードウェア プラットフォームで実行することによるハードウェアの使用率(結果的にコスト)の最適化。このソリューションでは、最適化の一環として、各ステップに必要なコンピューティング リソースを自動的にプロビジョニングおよびデプロビジョニングします。
何百もの並列推論ワークフローの実行と分析プロセスを簡素化する、堅牢で柔軟なテスト追跡のアプローチについての説明。
次の図は、ソリューションのアーキテクチャを示したものです。
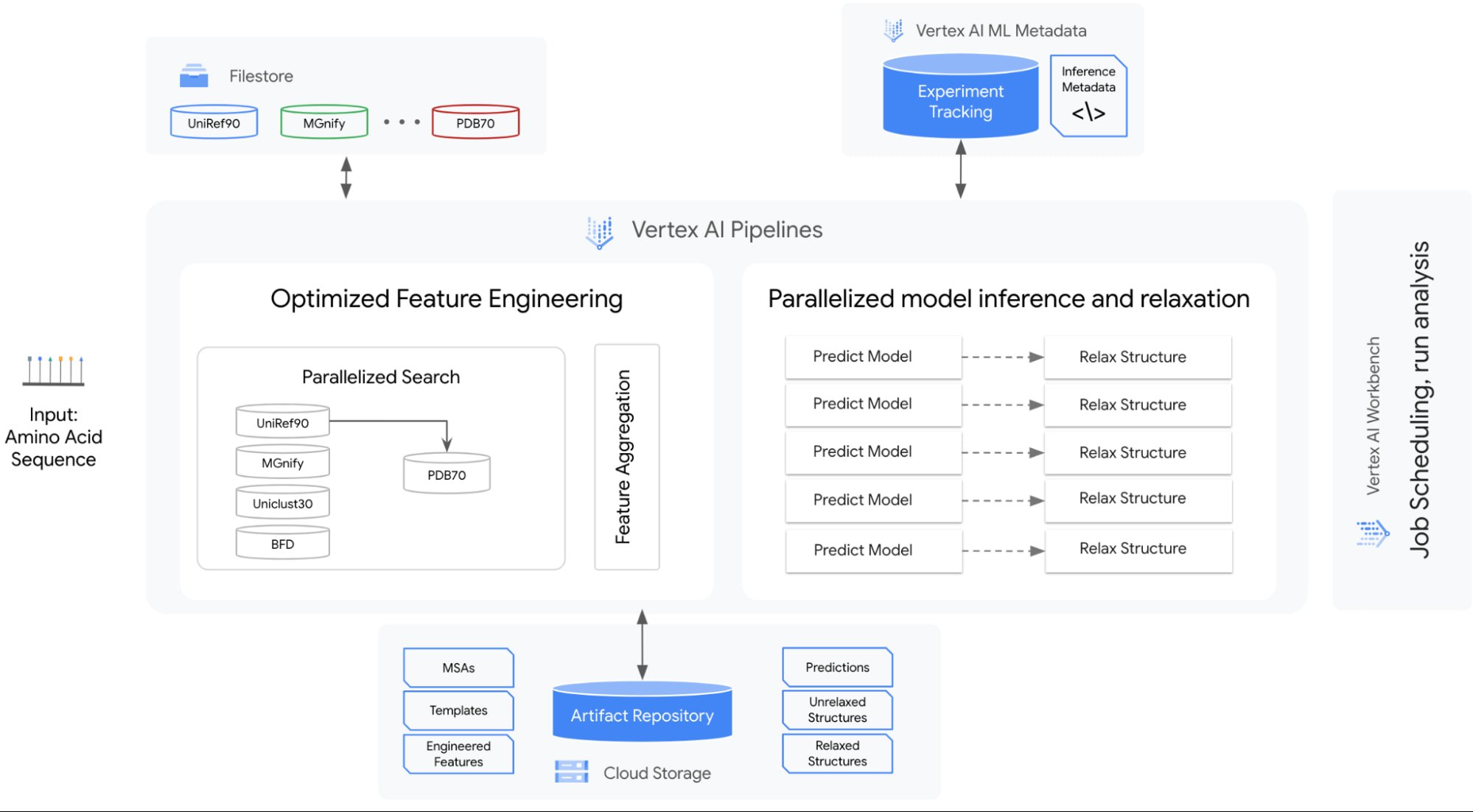
このソリューションには、次のものが含まれます。
遺伝子データベース管理に関する戦略。このソリューションには、高パフォーマンスでフルマネージドのファイル ストレージが含まれています。このソリューションは、Cloud Filestore を使用して、データベースの複数のバージョンを管理し、高スループットと低レイテンシのアクセスを提供します。
ワークフローにおけるステップを並列化しオーケストレートして、効率的に実行するためのオーケストレーター。予測、緩和、および一部の特徴量エンジニアリングを並列化できます。このソリューションでは、Vertex AI Pipelines がワークフローのステップに対するオーケストレーターおよびランタイム実行エンジンとして使用されています。
各ステップに合わせて最適化されたハードウェア プラットフォームの選択。予測と緩和のステップは GPU で、特徴量エンジニアリングは CPU で実行されます。予測と緩和のステップでは、マルチ GPU ノード構成を使用できます。これは特に予測ステップでは重要になります。なぜなら、メモリ使用量が残基数に対してほぼ二次関数的に増加するためです。したがって、大規模なタンパク質構造を予測する場合、1 つの GPU デバイスのメモリを超過する可能性があります。
メタデータとアーティファクトの管理。このソリューションには、テストを大規模に実行し、分析するための管理機能が含まれています。このソリューションでは、Vertex AI Metadata がメタデータとアーティファクトの管理に使用されています。
このソリューションの基本は、AlphaFold 推論ワークフローにおける主なステップ(特徴の前処理、予測、緩和)をカプセル化した、一連の再利用可能な Vertex AI Pipelines コンポーネントです。これらのコンポーネントに加え、特徴量エンジニアリングのステップをツールに分類する補助コンポーネントや、ワークフローの統合やオーケストレーションを支援するヘルパー コンポーネントがあります。
このソリューションには、ユニバーサル パイプラインと単量体パイプラインという 2 つのサンプル パイプラインが含まれています。ユニバーサル パイプラインは、AlphaFold GitHub リポジトリ内の推論スクリプトの設定と機能を反映しています。また、経過時間を追跡し、コンピューティング リソースの利用を最適化します。単量体パイプラインでは、特徴量エンジニアリングの効率化を図ることで、ワークフローをさらに最適化します。また、独自のデータベースをプラグインすることで、パイプラインをカスタマイズできます。
次のステップ
このソリューションに関する詳細と試用については、コンポーネントおよびユニバーサル パイプラインと単量体パイプラインについて記載されている GitHub リポジトリをご確認ください。リポジトリ内のアーティファクトは、カスタマイズできるように設計されています。さらに、このソリューションをアップストリームおよびダウンストリームのワークフローに統合して、詳細な分析を行うことができます。Vertex AI の詳細については、プロダクト ページをご覧ください。
謝辞
以下の方々のご協力に感謝いたします。Shweta Maniar、Sampath Koppole、Mikhail Chrestkha、Jasper Wang、Alex Burdenko、Meera Lakhavani、Joan Kallogjeri、Dong Meng 氏(NVIDIA)、Mike Thomas 氏(NVIDIA)、Jill Milton 氏(NVIDIA)
最後になりましたが、このソリューションの管理を最初から最後まで担当した、ソリューション マネージャーの Donna Schut に感謝の意を示したいと思います。Donna の存在なくしては、実現できなかったでしょう。
- ソリューション アーキテクト Jarek Kazmierczak
- ソリューション アーキテクト Renato Leite



