Halaman ini menjelaskan cara menggunakan AutoML Tables untuk melatih model kustom berdasarkan set data Anda. Anda harus sudah membuat set data dan mengimpor data ke dalamnya.
Pengantar
Anda membuat model kustom dengan melatihnya menggunakan set data yang telah disiapkan. AutoML Tables menggunakan item dari set data untuk melatih model, mengujinya, dan mengevaluasi performanya. Anda dapat meninjau hasilnya, menyesuaikan set data pelatihan sesuai kebutuhan, dan melatih model baru menggunakan set data yang ditingkatkan.
Sebagai bagian dari persiapan untuk melatih model, Anda memperbarui informasi skema set data. Pembaruan skema ini memengaruhi semua model mendatang yang menggunakan set data tersebut. Model yang sudah memulai pelatihan tidak akan terpengaruh.
Proses pelatihan model dapat memakan waktu beberapa jam untuk diselesaikan. Anda dapat memeriksa progres pelatihan di Konsol Google Cloud, atau dengan menggunakan Cloud AutoML API.
Karena AutoML Tables membuat model baru setiap kali Anda memulai pelatihan, project Anda mungkin menyertakan banyak model. Anda bisa mendapatkan daftar model di project dan dapat menghapus model yang tidak lagi diperlukan.
Model harus dilatih ulang setiap enam bulan agar dapat terus menyajikan prediksi.
Melatih model
Konsol
Jika perlu, buka halaman Datasets dan klik set data yang ingin Anda gunakan.
Tindakan ini akan membuka set data di tab Train.

Pilih kolom target untuk model Anda.
Ini adalah nilai yang dilatih untuk diprediksi oleh model. Jenis datanya menentukan apakah model yang dihasilkan adalah model regresi (Numerik) atau klasifikasi (Kategoris). Pelajari lebih lanjut.
Jika kolom target Anda memiliki jenis data Kategorikal, kolom target harus memiliki setidaknya dua dan tidak lebih dari 500 nilai yang berbeda.
Tinjau Jenis data, Nullability, dan statistik data untuk setiap kolom dalam set data Anda.
Anda dapat mengklik masing-masing kolom untuk mendapatkan detail lebih lanjut tentang kolom tersebut. Pelajari peninjauan skema lebih lanjut.
Jika Anda ingin mengontrol pemisahan data, klik Edit parameter tambahan, lalu tentukan kolom pemisahan data atau kolom Waktu. Pelajari lebih lanjut.
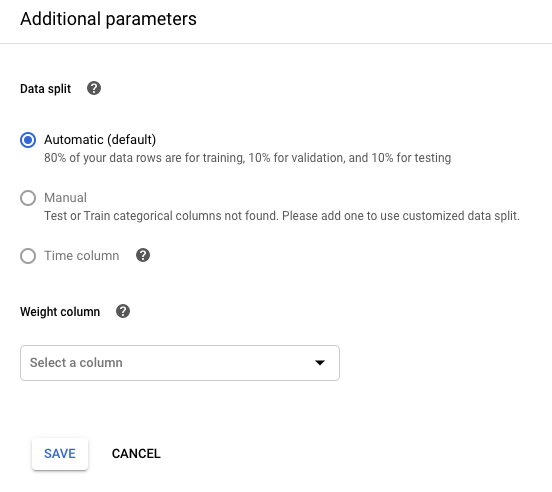
Jika Anda ingin membobotkan contoh pelatihan berdasarkan nilai kolom, klik Edit parameter tambahan dan tentukan kolom yang sesuai. Pelajari lebih lanjut.
Tinjau statistik dan detail ringkasan untuk memastikan kualitas data Anda sesuai harapan, dan Anda telah mengidentifikasi kolom yang perlu dikecualikan saat membuat model.
Untuk informasi selengkapnya, lihat Menganalisis data pelatihan.
Setelah puas dengan skema set data Anda, klik Train model di bagian atas layar.
Saat Anda membuat perubahan pada skema, AutoML Tables akan memperbarui statistik ringkasan, yang dapat memerlukan waktu beberapa saat untuk diselesaikan. Anda tidak perlu menunggu hingga proses ini selesai sebelum memulai pelatihan model.
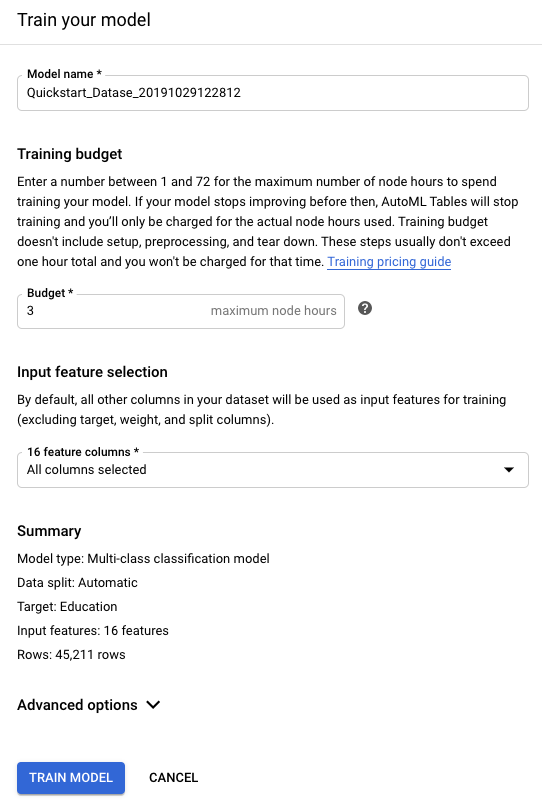
Untuk Anggaran pelatihan, masukkan jumlah jam pelatihan maksimum untuk model ini.
Anggaran pelatihan berkisar antara 1 dan 72 jam. Ini adalah jumlah maksimum waktu pelatihan yang akan ditagihkan kepada Anda.
Waktu pelatihan yang disarankan berkaitan dengan ukuran data pelatihan Anda. Tabel di bawah ini menunjukkan rentang waktu pelatihan yang disarankan berdasarkan jumlah baris; sejumlah besar kolom juga akan meningkatkan waktu pelatihan.
Baris Waktu pelatihan yang disarankan Kurang dari 100.000 1-3 jam 100.000 - 1.000.000 1-6 jam 1.000.000 - 10.000.000 1-12 jam Lebih dari 10.000.000 3 - 24 jam Pembuatan model mencakup tugas lain selain pelatihan, sehingga total waktu yang diperlukan untuk membuat model Anda lebih lama daripada waktu pelatihan. Misalnya, jika Anda menetapkan 2 jam pelatihan, masih diperlukan waktu 3 jam atau lebih sebelum model siap di-deploy. Anda hanya dikenai biaya untuk waktu pelatihan yang sebenarnya.
Pelajari harga pelatihan lebih lanjut.
Jika AutoML Tables mendeteksi bahwa model tidak lagi meningkat sebelum anggaran pelatihan habis, model akan menghentikan pelatihan. Jika Anda ingin menggunakan seluruh waktu pelatihan yang dianggarkan, buka Opsi lanjutan dan nonaktifkan Penghentian awal.
Di bagian Pemilihan fitur input, kecualikan semua kolom yang Anda targetkan untuk pengecualian dalam langkah analisis skema.
Jika Anda tidak ingin menggunakan tujuan pengoptimalan default, buka Advanced options lalu pilih metrik yang ingin dioptimalkan oleh Tabel AutoML saat melatih model Anda. Pelajari lebih lanjut.
Bergantung pada jenis data kolom target Anda, mungkin hanya ada satu pilihan untuk Tujuan pengoptimalan.
Klik Train model untuk memulai pelatihan model.
Melatih model dapat memerlukan waktu beberapa jam hingga selesai, bergantung pada ukuran set data dan anggaran pelatihan. Anda dapat menutup jendela browser tanpa memengaruhi proses pelatihan.
Setelah model berhasil dilatih, tab Model akan menampilkan metrik tingkat tinggi untuk model tersebut, seperti presisi dan perolehan.
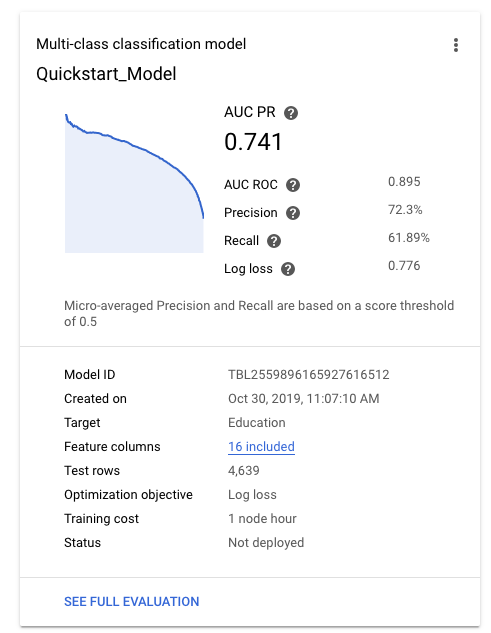
Untuk bantuan dalam mengevaluasi kualitas model, lihat Mengevaluasi model.
REST
Contoh berikut menunjukkan cara meninjau dan memperbarui skema data sebelum melatih model Anda.
Jika resource Anda berada di region Uni Eropa, gunakan eu untuk {location}
dan gunakan endpoint eu-automl.googleapis.com. Jika tidak, gunakan us-central1.
Pelajari lebih lanjut.
Setelah impor selesai, cantumkan spesifikasi tabel untuk mendapatkan ID tabel.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
-
endpoint:
automl.googleapis.comuntuk lokasi global, daneu-automl.googleapis.comuntuk region Uni Eropa. - project-id: Project ID Google Cloud Anda.
- location: lokasi untuk resource:
us-central1untuk Global ataueuuntuk Uni Eropa. -
dataset-id: ID set data. Misalnya,
TBL6543.
Metode HTTP dan URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id/tableSpecs/
Untuk mengirim permintaan, perluas salah satu opsi berikut:
ID tabel ditampilkan dalam huruf tebal di kolom
name.-
endpoint:
Cantumkan spesifikasi kolom Anda.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
-
endpoint:
automl.googleapis.comuntuk lokasi global, daneu-automl.googleapis.comuntuk region Uni Eropa. - project-id: Project ID Google Cloud Anda.
- location: lokasi untuk resource:
us-central1untuk Global ataueuuntuk Uni Eropa. -
dataset-id: ID set data. Misalnya,
TBL6543. - table-id: ID tabel.
Metode HTTP dan URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id/tableSpecs/table-id/columnSpecs/
Untuk mengirim permintaan, perluas salah satu opsi berikut:
-
endpoint:
Secara opsional, konfigurasikan kolom target Anda.
Ini adalah nilai yang dilatih untuk diprediksi oleh model. Jenis datanya menentukan apakah model yang dihasilkan adalah model regresi (Numerik) atau klasifikasi (Kategoris). Pelajari lebih lanjut.
Jika kolom target Anda memiliki jenis data Kategorikal, kolom target harus memiliki setidaknya dua dan tidak lebih dari 500 nilai yang berbeda.
Anda juga dapat menentukan kolom target saat melatih model. Jika Anda berencana melakukannya, pertahankan ID tabel dan ID kolom target yang diinginkan untuk digunakan nanti.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
-
endpoint:
automl.googleapis.comuntuk lokasi global, daneu-automl.googleapis.comuntuk region Uni Eropa. - project-id: Project ID Google Cloud Anda.
- location: lokasi untuk resource:
us-central1untuk Global ataueuuntuk Uni Eropa. - dataset-id: ID set data Anda.
- target-column-id: ID kolom target Anda.
Metode HTTP dan URL:
PATCH https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id
Meminta isi JSON:
{ "tablesDatasetMetadata": { "targetColumnSpecId": "target-column-id" } }Untuk mengirim permintaan Anda, perluas salah satu opsi berikut:
-
endpoint:
Jika ingin, perbarui kolom
mlUseColumnSpecIduntuk menentukan pembagian data, dan kolomweightColumnSpecIduntuk menggunakan kolom bobot.Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
-
endpoint:
automl.googleapis.comuntuk lokasi global, daneu-automl.googleapis.comuntuk region Uni Eropa. - project-id: Project ID Google Cloud Anda.
- location: lokasi untuk resource:
us-central1untuk Global ataueuuntuk Uni Eropa. - dataset-id: ID set data Anda.
- split-column-id: ID kolom target Anda.
- weight-column-id: ID kolom target Anda.
Metode HTTP dan URL:
PATCH https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id
Meminta isi JSON:
{ "tablesDatasetMetadata": { "mlUseColumnSpecId": "split-column-id", "weightColumnSpecId": "weight-column-id" } }Untuk mengirim permintaan Anda, perluas salah satu opsi berikut:
-
endpoint:
Tinjau statistik kolom untuk memastikan nilai
dataTypesudah benar, dan kolom memiliki nilai yang benar untuknullable.Jika kolom ditandai sebagai non-nullable, artinya kolom tersebut tidak memiliki nilai null untuk set data pelatihan. Pastikan ini juga akan berlaku untuk data prediksi Anda; jika kolom ditandai sebagai non-nullable, dan nilai tidak diberikan untuknya pada waktu prediksi, error prediksi akan ditampilkan untuk baris tersebut.
Tinjau kualitas data Anda.
Latih model.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
-
endpoint:
automl.googleapis.comuntuk lokasi global, daneu-automl.googleapis.comuntuk region Uni Eropa. - project-id: Project ID Google Cloud Anda.
- location: lokasi untuk resource:
us-central1untuk Global ataueuuntuk Uni Eropa. - dataset-id: ID set data.
- table-id: ID tabel, yang digunakan untuk menetapkan kolom target.
- target-column-id: ID kolom target.
- model-display-name: nama tampilan untuk model baru.
-
optimization-objective dengan metrik yang akan dioptimalkan (opsional).
-
train-budget-milli-node-hours dengan jumlah jam kerja milidetik untuk pelatihan. Misalnya, 1.000 = 1 jam.
Waktu pelatihan yang disarankan berkaitan dengan ukuran data pelatihan Anda. Tabel di bawah ini menunjukkan rentang waktu pelatihan yang disarankan berdasarkan jumlah baris; sejumlah besar kolom juga akan meningkatkan waktu pelatihan.
Baris Waktu pelatihan yang disarankan Kurang dari 100.000 1-3 jam 100.000 - 1.000.000 1-6 jam 1.000.000 - 10.000.000 1-12 jam Lebih dari 10.000.000 3 - 24 jam Pembuatan model mencakup tugas lain selain pelatihan, sehingga total waktu yang diperlukan untuk membuat model Anda lebih lama daripada waktu pelatihan. Misalnya, jika Anda menetapkan 2 jam pelatihan, masih diperlukan waktu 3 jam atau lebih sebelum model siap di-deploy. Anda hanya dikenai biaya untuk waktu pelatihan yang sebenarnya.
Pelajari harga pelatihan lebih lanjut.
Jika AutoML Tables mendeteksi bahwa model tidak lagi meningkat sebelum anggaran pelatihan habis, model akan menghentikan pelatihan. Jika Anda ingin menggunakan seluruh waktu pelatihan yang dianggarkan, tetapkan properti
disableEarlyStoppingpada objektablesModelMetadataketrue.
Metode HTTP dan URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/
Meminta isi JSON:
{ "datasetId": "dataset-id", "displayName": "model-display-name", "tablesModelMetadata": { "trainBudgetMilliNodeHours": "train-budget-milli-node-hours", "optimizationObjective": "optimization-objective", "targetColumnSpec": { "name": "projects/project-id/locations/location/datasets/dataset-id/tableSpecs/table-id/columnSpecs/target-column-id" } }, }Untuk mengirim permintaan Anda, perluas salah satu opsi berikut:
Anda akan melihat respons JSON seperti berikut:
{ "name": "projects/292381/locations/us-central1/operations/TBL64984", "metadata": { "@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata", "createTime": "2019-12-30T22:12:03.014058Z", "updateTime": "2019-12-30T22:12:03.014058Z", "cancellable": true, "createModelDetails": { "modelDisplayName": "new_model1" }, "worksOn": [ "projects/292381/locations/us-central1/datasets/TBL3718" ], "state": "RUNNING" } }Melatih model adalah operasi yang berjalan lama. Anda dapat memeriksa status operasi atau menunggu operasi ditampilkan. Pelajari lebih lanjut.
-
endpoint:
Java
Jika resource Anda berada di region Uni Eropa, Anda harus menetapkan endpoint secara eksplisit. Pelajari lebih lanjut.
Node.js
Jika resource Anda berada di region Uni Eropa, Anda harus menetapkan endpoint secara eksplisit. Pelajari lebih lanjut.
Python
Library klien untuk AutoML Tables menyertakan metode Python tambahan yang menyederhanakan penggunaan AutoML Tables API. Metode ini merujuk pada set data dan model berdasarkan nama, bukan ID. Nama set data dan model Anda harus unik. Untuk mengetahui informasi selengkapnya, lihat Referensi klien.
Jika resource Anda berada di region Uni Eropa, Anda harus menetapkan endpoint secara eksplisit. Pelajari lebih lanjut.
Ulasan skema
Tabel AutoML menyimpulkan jenis data dan apakah suatu kolom bersifat nullable untuk setiap kolom berdasarkan jenis data asli (jika diimpor dari BigQuery) dan nilai dalam kolom tersebut. Anda harus memeriksa setiap kolom dan memastikannya sudah benar.
Gunakan daftar berikut untuk meninjau skema Anda:
Kolom yang berisi teks bentuk bebas harus berupa Text.
Kolom teks dipisahkan menjadi token berdasarkan UnicodeScriptTokenizer, dengan masing-masing token digunakan untuk pelatihan model. UnicodeScriptTokenizer membuat token teks dengan spasi kosong, sekaligus juga memisahkan tanda baca dari teks dan bahasa yang berbeda satu sama lain.
Jika nilai kolom adalah salah satu dari kumpulan nilai terbatas, nilai tersebut mungkin harus Kategori, terlepas dari jenis data yang digunakan di kolom.
Misalnya, Anda mungkin memiliki kode untuk warna: 1 = merah, 2 = kuning, dst. Anda harus memastikan bahwa kolom tersebut ditetapkan sebagai Kategori.
Pengecualian untuk panduan ini adalah jika kolom berisi string multi-kata. Dalam hal ini, Anda harus menetapkannya sebagai kolom Teks, meskipun memiliki kardinalitas rendah. AutoML Tables membuat token kolom Teks, dan mungkin dapat memperoleh sinyal prediksi dari setiap token atau urutannya.
Jika kolom ditandai sebagai non-nullable, artinya kolom tersebut tidak memiliki nilai null untuk set data pelatihan. Pastikan ini juga akan berlaku untuk data prediksi Anda; jika kolom ditandai sebagai non-nullable, dan nilai tidak diberikan untuknya pada waktu prediksi, error prediksi akan ditampilkan untuk baris tersebut.
Menganalisis data pelatihan Anda
Jika persentase nilai yang hilang di kolom tinggi, pastikan hal ini diperkirakan, bukan karena masalah pengumpulan data.
Pastikan jumlah nilai yang tidak valid relatif rendah atau nol.
Setiap baris yang berisi satu atau beberapa nilai yang tidak valid akan otomatis dikecualikan agar tidak digunakan untuk pelatihan model.
Jika Nilai berbeda untuk kolom Kategoris mendekati jumlah baris (misalnya, lebih dari 90%), kolom tersebut tidak akan memberikan banyak sinyal pelatihan. Model harus dikecualikan dari pelatihan. Kolom ID harus selalu dikecualikan.
Jika nilai Correlation with Target di kolom tinggi, pastikan hal tersebut sesuai perkiraan, dan bukan merupakan indikasi kebocoran target.
Jika kolom akan tersedia saat Anda meminta prediksi, berarti kolom tersebut mungkin merupakan fitur yang memiliki penjelasan yang sangat kuat dan dapat disertakan. Namun, terkadang fitur dengan korelasi tinggi sebenarnya berasal dari target atau dikumpulkan setelah fakta. Fitur ini harus dikecualikan dari pelatihan, karena tidak tersedia pada waktu prediksi, sehingga model tidak dapat digunakan dalam produksi.
Korelasi dihitung untuk kolom kategori, numerik, dan stempel waktu menggunakan Cramér's V. Untuk kolom numerik, korelasi dihitung menggunakan jumlah bucket yang dihasilkan dari kuantil.
Tentang tujuan pengoptimalan model
Tujuan pengoptimalan memengaruhi cara model dilatih, dan juga performa model dalam produksi. Tabel di bawah ini memberikan beberapa detail tentang jenis masalah yang paling cocok untuk setiap tujuan:
| Tujuan pengoptimalan | Jenis masalah | Nilai API | Gunakan tujuan ini jika Anda ingin... |
|---|---|---|---|
| AUC ROC | Classification | MAXIMIZE_AU_ROC |
Membedakan antar-class. Memberikan nilai default untuk klasifikasi biner. |
| Kerugian log | Classification | MINIMIZE_LOG_LOSS |
Membuat probabilitas prediksi seakurat mungkin. Hanya mendukung tujuan untuk klasifikasi multi-class. |
| AUC PR | Classification | MAXIMIZE_AU_PRC |
Mengoptimalkan hasil untuk prediksi bagi class yang kurang umum. |
| Presisi pada Perolehan | Classification | MAXIMIZE_PRECISION_AT_RECALL |
Mengoptimalkan presisi pada nilai perolehan tertentu. |
| Perolehan pada Presisi | Classification | MAXIMIZE_RECALL_AT_PRECISION |
Mengoptimalkan perolehan pada nilai presisi tertentu. |
| RMSE | Regresi | MINIMIZE_RMSE |
Menangkap nilai yang lebih ekstrem secara akurat. |
| MAE | Regresi | MINIMIZE_MAE |
Lihat nilai ekstrem sebagai outlier dengan dampak lebih kecil pada model. |
| RMSLE | Regresi | MINIMIZE_RMSLE |
Menindak error pada ukuran relatif dan bukan nilai absolut. Hal ini sangat membantu terutama ketika nilai aktual dan yang diprediksi cukup besar. |
Langkah selanjutnya
- Pelajari arsitektur model.
- Mengevaluasi model Anda.
- Dapatkan prediksi batch dari model Anda.
- Dapatkan prediksi online dari model Anda.
- Ekspor model Anda.
- Pelajari lebih lanjut cara menggunakan operasi yang berjalan lama.