Halaman ini menjelaskan cara menggunakan metrik evaluasi untuk model Anda setelah dilatih, dan memberikan beberapa saran dasar tentang cara untuk meningkatkan performa model.
Pengantar
Setelah melatih model, AutoML Tables menggunakan set data pengujian untuk mengevaluasi kualitas dan akurasi model baru, serta memberikan kumpulan metrik evaluasi gabungan yang menunjukkan seberapa baik performa model pada set data pengujian.
Penggunaan metrik evaluasi untuk menentukan kualitas model bergantung pada kebutuhan bisnis Anda dan masalah yang dilatih untuk dipecahkan oleh model Anda. Misalnya, mungkin ada biaya yang lebih tinggi untuk positif palsu daripada negatif palsu, atau sebaliknya. Untuk model regresi, apakah delta antara prediksi dan jawaban yang benar penting atau tidak? Pertanyaan-pertanyaan semacam ini memengaruhi cara Anda melihat metrik evaluasi model.
Jika Anda menyertakan kolom bobot dalam data pelatihan, kolom tersebut tidak akan memengaruhi metrik evaluasi. Bobot hanya dipertimbangkan selama fase pelatihan.
Metrik evaluasi untuk model klasifikasi
Model klasifikasi menyediakan metrik berikut:
AUC PR: Area di bawah kurva presisi-recall (PR). Nilai ini berkisar dari nol hingga satu, dengan nilai yang lebih tinggi menunjukkan model yang berkualitas lebih tinggi.
AUC ROC: Area di bawah kurva karakteristik operasi penerima (ROC). Ini berkisar dari nol hingga satu, dengan nilai yang lebih tinggi menunjukkan model yang berkualitas lebih tinggi.
Akurasi: Bagian prediksi klasifikasi yang dihasilkan oleh model yang benar.
Kerugian log: Entropi silang antara prediksi model dan nilai target. Rentangnya dari nol hingga tak terbatas, dengan nilai yang lebih rendah menunjukkan model yang berkualitas lebih tinggi.
Skor F1: Rata-rata harmonis dari presisi dan perolehan. F1 adalah metrik yang berguna jika Anda mencari keseimbangan antara presisi dan perolehan serta terdapat distribusi class yang tidak merata.
Presisi: Fraksi prediksi positif yang dihasilkan oleh model yang benar. (Prediksi positif adalah positif palsu (PP) dan positif benar yang digabungkan).
Perolehan: Bagian baris dengan label ini yang diprediksi oleh model dengan benar. Juga disebut dengan "Rasio positif benar".
Rasio positif palsu: Pecahan baris yang diprediksi oleh model untuk menjadi label target, tetapi tidak menjadi label target (positif palsu).
Metrik ini ditampilkan untuk setiap nilai yang berbeda pada kolom target. Untuk model klasifikasi kelas multi, metrik ini dirata-rata mikro dan ditampilkan sebagai metrik ringkasan. Untuk model klasifikasi biner, metrik untuk class minoritas digunakan sebagai metrik ringkasan. Metrik rata-rata mikro adalah nilai yang diharapkan dari setiap metrik pada sampel acak dari set data Anda.
Selain metrik di atas, AutoML Tables menyediakan dua cara lain untuk memahami model klasifikasi Anda, yaitu matriks konfusi dan grafik nilai penting fitur.
Matriks konfusi: Matriks konfusi membantu Anda memahami tempat terjadinya kesalahan klasifikasi (kelas mana yang "tercampur" satu sama lain). Setiap baris mewakili kebenaran dasar untuk label tertentu, dan setiap kolom menampilkan label yang diprediksi oleh model.
Matriks konfusi hanya disediakan untuk model klasifikasi dengan nilai 10 atau lebih sedikit untuk kolom target.

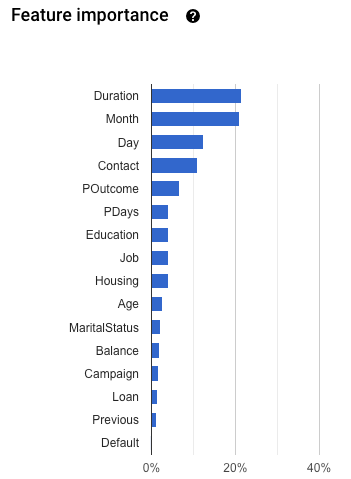
Tingkat kepentingan fitur: AutoML Tables memberi tahu Anda seberapa besar dampak setiap fitur terhadap model ini. Hal ini ditampilkan pada grafik Tingkat kepentingan fitur. Nilai ini diberikan sebagai persentase untuk setiap fitur: semakin tinggi persentasenya, semakin kuat fitur tersebut memengaruhi pelatihan model.
Anda harus meninjau informasi ini untuk memastikan bahwa semua fitur terpenting sesuai untuk masalah data dan bisnis Anda. Pelajari lebih lanjut penjelasan.
Cara penghitungan presisi rata-rata mikro
Presisi rata-rata mikro dihitung dengan menjumlahkan jumlah positif benar (TP) untuk setiap nilai potensial kolom target dan membaginya dengan jumlah positif benar (TP) dan negatif benar (TN) untuk setiap nilai potensial.
\[ presisi_{mikro} = \dfrac{TP_1 + \ldots + TP_n} {TP_1 + \ldots + TP_n + FP_1 + \ldots + FP_n} \]
dengan
- \(TP_1 + \ldots + TP_n\) adalah jumlah positif benar untuk setiap dari n class
- \(FP_1 + \ldots + FP_n\) adalah jumlah positif palsu untuk setiap n class
Nilai minimum skor
Nilai minimum skor adalah angka yang berkisar antara 0 hingga 1. Ini menyediakan cara untuk menentukan tingkat keyakinan minimum di mana nilai prediksi yang diberikan harus dianggap benar. Misalnya, jika Anda memiliki class yang sangat kecil kemungkinannya menjadi nilai sebenarnya, Anda dapat menurunkan nilai minimum untuk class tersebut .Menggunakan nilai minimum 0,5 atau lebih tinggi akan menyebabkan class tersebut sangat jarang diprediksi (atau tidak pernah).
Ambang batas yang lebih tinggi akan mengurangi positif palsu, dengan mengorbankan lebih banyak negatif palsu. Ambang batas yang lebih rendah akan mengurangi negatif palsu dengan mengorbankan lebih banyak positif palsu.
Dengan kata lain, nilai minimum skor memengaruhi presisi dan perolehan. Ambang batas yang lebih tinggi menghasilkan peningkatan presisi (karena model tidak pernah membuat prediksi kecuali jika benar-benar yakin), tetapi recall (persentase contoh positif yang dipahami model dengan benar) akan menurun.
Metrik evaluasi untuk model regresi
Model regresi menyediakan metrik berikut:
MAE: Rataan mutlak galat (MAE) adalah selisih mutlak rata-rata antara nilai target dan nilai yang diprediksi. Metrik ini berkisar dari nol hingga tak terbatas; nilai yang lebih rendah menunjukkan model yang berkualitas lebih tinggi.
RMSE: Metrik error akar rata-rata kuadrat adalah ukuran perbedaan yang sering digunakan antara nilai yang diprediksi oleh model atau estimator dan nilai yang diamati. Metrik ini berkisar dari nol hingga tak terbatas; nilai yang lebih rendah menunjukkan model yang berkualitas lebih tinggi.
RMSLE: Metrik galat logaritmik akar rataan kuadrat mirip dengan RMSE, tetapi metrik ini menggunakan logaritma natural dari nilai yang diprediksi dan nilai sebenarnya ditambah 1. RMSLE menghukum di bawah prediksi lebih berat daripada prediksi yang berlebihan. Ini juga bisa menjadi metrik yang baik jika Anda tidak ingin mengganjarkan perbedaan untuk nilai prediksi besar secara lebih besar daripada nilai prediksi kecil. Metrik ini berkisar dari nol hingga tak terbatas; nilai yang lebih rendah menunjukkan model yang berkualitas lebih tinggi. Metrik evaluasi RMSLE hanya ditampilkan jika semua label dan nilai yang diprediksi tidak negatif.
r^2: r kuadrat (r^2) adalah kuadrat dari koefisien korelasi Pearson antara label dan nilai yang diprediksi. Metrik ini memiliki rentang antara nol dan satu; nilai yang lebih tinggi menunjukkan model yang berkualitas lebih tinggi.
MAPE: Rataan galat persentase mutlak (MAPE) adalah selisih rata-rata persentase mutlak antara label dan nilai yang diprediksi. Metrik ini berkisar antara nol dan tidak terbatas; nilai yang lebih rendah menunjukkan model yang berkualitas lebih tinggi.
MAPE tidak ditampilkan jika kolom target berisi nilai 0. Dalam hal ini, MAPE tidak terdefinisi.
Tingkat kepentingan fitur: AutoML Tables memberi tahu Anda seberapa besar dampak setiap fitur terhadap model ini. Hal ini ditampilkan pada grafik Tingkat kepentingan fitur. Nilai ini diberikan sebagai persentase untuk setiap fitur: semakin tinggi persentasenya, semakin kuat fitur tersebut memengaruhi pelatihan model.
Anda harus meninjau informasi ini untuk memastikan bahwa semua fitur terpenting sesuai untuk masalah data dan bisnis Anda. Pelajari lebih lanjut penjelasan.
Mendapatkan metrik evaluasi untuk model Anda
Untuk mengevaluasi seberapa baik performa model Anda pada set data pengujian, periksa metrik evaluasi untuk model Anda.
Konsol
Untuk melihat metrik evaluasi model Anda menggunakan Konsol Google Cloud:
Buka halaman AutoML Tables di Konsol Google Cloud.
Pilih tab Models di panel navigasi sebelah kiri, lalu pilih model yang metrik evaluasinya ingin Anda dapatkan.
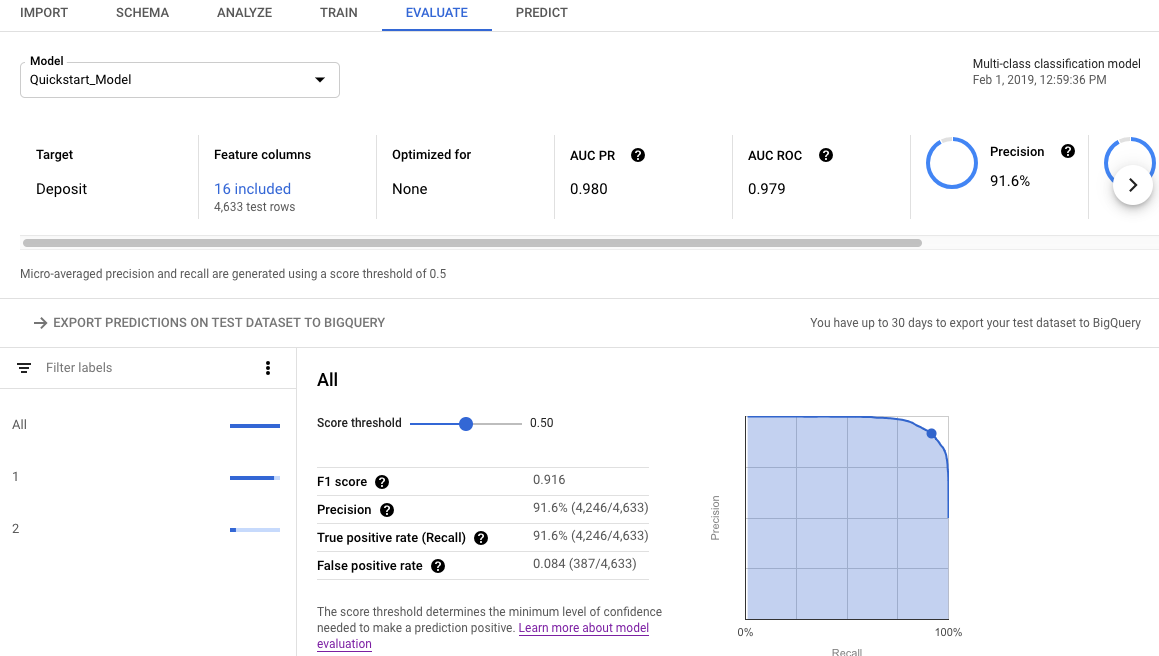
Buka tab Evaluate.
Metrik evaluasi ringkasan ditampilkan di bagian atas layar. Untuk model klasifikasi biner, metrik ringkasan adalah metrik kelas minoritas. Untuk model klasifikasi multi-kelas, metrik ringkasan adalah metrik rata-rata mikro.
Untuk metrik klasifikasi, Anda dapat mengklik nilai target individual guna melihat metrik untuk nilai tersebut.
REST
Guna mendapatkan metrik evaluasi untuk model Anda menggunakan Cloud AutoML API, gunakan metode modelEvaluations.list.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
-
endpoint:
automl.googleapis.comuntuk lokasi global, daneu-automl.googleapis.comuntuk region Uni Eropa. - project-id: Project ID Google Cloud Anda.
- location: lokasi untuk resource:
us-central1untuk Global ataueuuntuk Uni Eropa. -
model-id: ID model yang ingin Anda evaluasi. Contoh,
TBL543.
Metode HTTP dan URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/
Untuk mengirim permintaan Anda, pilih salah satu opsi berikut:
curl
Jalankan perintah berikut:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/"
PowerShell
Jalankan perintah berikut:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/" | Select-Object -Expand Content
Java
Jika resource Anda berada di region Uni Eropa, Anda harus menetapkan endpoint secara eksplisit. Pelajari lebih lanjut.
Node.js
Jika resource Anda berada di region Uni Eropa, Anda harus menetapkan endpoint secara eksplisit. Pelajari lebih lanjut.
Python
Library klien untuk AutoML Tables menyertakan metode Python tambahan yang menyederhanakan penggunaan AutoML Tables API. Metode ini merujuk pada set data dan model berdasarkan nama, bukan ID. Nama set data dan model Anda harus unik. Untuk mengetahui informasi selengkapnya, lihat Referensi klien.
Jika resource Anda berada di region Uni Eropa, Anda harus menetapkan endpoint secara eksplisit. Pelajari lebih lanjut.
Memahami hasil evaluasi menggunakan API
Saat Anda menggunakan Cloud AutoML API untuk mendapatkan metrik evaluasi model, sejumlah besar informasi akan ditampilkan. Memahami cara penyusunan hasil metrik dapat membantu Anda menafsirkan hasilnya dan menggunakannya untuk mengevaluasi model Anda.
Hasil klasifikasi
Untuk model klasifikasi, hasilnya mencakup beberapa objek ModelEvaluation, yang masing-masing berisi beberapa objek ConfidenceMetricsEntry. Memahami cara penyusunan hasil akan membantu Anda memilih objek yang tepat untuk digunakan saat mengevaluasi model.
Dua objek ModelEvaluation ditampilkan untuk setiap nilai kolom target yang berbeda yang ada dalam data pelatihan. Selain itu, ada dua objek ModelEvaluation ringkasan, dan satu objek ModelEvaluation kosong yang dapat diabaikan.
Dua objek ModelEvaluation yang ditampilkan untuk nilai label tertentu menunjukkan nilai label di kolom displayName. Masing-masing menggunakan nilai batas posisi yang berbeda: satu dan MAX_INT (angka tertinggi yang memungkinkan). Ambang batas posisi menentukan jumlah hasil yang dipertimbangkan untuk prediksi.
Untuk masalah klasifikasi, menggunakan batas posisi satu sering kali paling masuk akal, karena hanya ada satu label yang dipilih untuk setiap input. Untuk masalah multi-label, lebih dari satu label dapat dipilih per input, sehingga metrik evaluasi yang ditampilkan untuk batas posisi MAX_INT mungkin lebih berguna. Anda harus menentukan metrik yang akan digunakan berdasarkan kasus penggunaan spesifik dari model Anda.
Dua objek ModelEvaluation ringkasan tidak menyertakan kolom displayName, kecuali sebagai bagian dari matriks konfusi. Selain itu, nilainya untuk kolom evaluatedExampleCount adalah jumlah total baris dalam data pelatihan.
Untuk model klasifikasi multi-class, objek ringkasan memberikan metrik rata-rata mikro berdasarkan semua metrik per label.
Untuk model klasifikasi biner, metrik kelas minoritas digunakan sebagai metrik ringkasan. Gunakan objek ModelEvaluation dengan batas posisi satu untuk metrik ringkasan Anda.
Setiap objek ModelEvaluation berisi hingga 100 objek ConfidenceMetricsEntry, bergantung pada data pelatihan. Setiap objek ConfidenceMetricsEntry memberikan nilai yang berbeda untuk nilai minimum keyakinan (juga disebut ambang batas skor).
Objek ModelEvaluation terlihat mirip dengan contoh berikut. Perhatikan bahwa urutan tampilan kolom bisa berbeda.
model_evaluation {
name: "projects/8628/locations/us-central1/models/TBL328/modelEvaluations/18011"
create_time {
seconds: 1575513478
nanos: 163446000
}
evaluated_example_count: 1013
classification_evaluation_metrics {
au_roc: 0.99749845
log_loss: 0.01784837
au_prc: 0.99498594
confidence_metrics_entry {
recall: 0.99506414
precision: 0.99506414
f1_score: 0.99506414
false_positive_rate: 0.002467917
true_positive_count: 1008
false_positive_count: 5
false_negative_count: 5
true_negative_count: 2021
position_threshold: 1
}
confidence_metrics_entry {
confidence_threshold: 0.0149591835
recall: 0.99506414
precision: 0.99506414
f1_score: 0.99506414
false_positive_rate: 0.002467917
true_positive_count: 1008
false_positive_count: 5
false_negative_count: 5
true_negative_count: 2021
position_threshold: 1
}
...
confusion_matrix {
row {
example_count: 519
example_count: 2
example_count: 0
}
row {
example_count: 3
example_count: 75
example_count: 0
}
row {
example_count: 0
example_count: 0
example_count: 414
}
display_name: "RED"
display_name: "BLUE"
display_name: "GREEN"
}
}
}
Objek ModelEvaluation khusus label terlihat mirip dengan contoh berikut. Perhatikan bahwa urutan tampilan kolom dapat berbeda.
model_evaluation {
name: "projects/8628/locations/us-central1/models/TBL328/modelEvaluations/21860"
annotation_spec_id: "not available"
create_time {
seconds: 1575513478
nanos: 163446000
}
evaluated_example_count: 521
classification_evaluation_metrics {
au_prc: 0.99933827
au_roc: 0.99889404
log_loss: 0.014250426
confidence_metrics_entry {
recall: 1.0
precision: 0.51431394
f1_score: 0.6792699
false_positive_rate: 1.0
true_positive_count: 521
false_positive_count: 492
position_threshold: 2147483647
}
confidence_metrics_entry {
confidence_threshold: 0.10562216
recall: 0.9980806
precision: 0.9904762
f1_score: 0.9942639
false_positive_rate: 0.010162601
true_positive_count: 520
false_positive_count: 5
false_negative_count: 1
true_negative_count: 487
position_threshold: 2147483647
}
...
}
display_name: "RED"
}
Hasil regresi
Untuk model regresi, Anda akan melihat output yang mirip dengan contoh berikut:
{
"modelEvaluation": [
{
"name": "projects/1234/locations/us-central1/models/TBL2345/modelEvaluations/68066093",
"createTime": "2019-05-15T22:33:06.471561Z",
"evaluatedExampleCount": 418
},
{
"name": "projects/1234/locations/us-central1/models/TBL2345/modelEvaluations/852167724",
"createTime": "2019-05-15T22:33:06.471561Z",
"evaluatedExampleCount": 418,
"regressionEvaluationMetrics": {
"rootMeanSquaredError": 1.9845301,
"meanAbsoluteError": 1.48482,
"meanAbsolutePercentageError": 15.155516,
"rSquared": 0.6057632,
"rootMeanSquaredLogError": 0.16848126
}
}
]
}
Memecahkan masalah model
Metrik evaluasi model seharusnya baik, tetapi tidak sempurna. Performa model yang buruk dan performa model yang sempurna merupakan indikasi bahwa ada yang tidak beres dengan proses pelatihan.
Performa buruk
Jika model Anda tidak berperforma sebaik yang diinginkan, berikut beberapa hal yang bisa dicoba.
Tinjau skema Anda.
Pastikan semua kolom memiliki jenis yang benar, dan Anda mengecualikannya dari melatih kolom yang tidak prediktif, seperti kolom ID.
Tinjau data Anda
Nilai yang tidak ada di kolom non-nullable menyebabkan baris tersebut diabaikan. Pastikan data Anda tidak memiliki terlalu banyak kesalahan.
Ekspor set data pengujian dan periksa.
Dengan memeriksa data dan menganalisis kapan model membuat prediksi yang salah, Anda mungkin menentukan bahwa Anda memerlukan lebih banyak data pelatihan untuk hasil tertentu, atau data pelatihan Anda menyebabkan kebocoran.
Meningkatkan jumlah data pelatihan.
Jika Anda tidak memiliki data pelatihan yang cukup, kualitas model akan menurun. Pastikan data pelatihan Anda tidak bias.
Menambah waktu pelatihan
Jika waktu pelatihan Anda singkat, Anda mungkin akan mendapatkan model berkualitas lebih tinggi dengan memungkinkannya dilatih dalam jangka waktu yang lebih lama.
Performa sempurna
Jika model Anda menampilkan metrik evaluasi yang hampir sempurna, mungkin ada sesuatu yang salah dengan data pelatihan Anda. Berikut adalah beberapa hal yang harus diperhatikan:
Kebocoran target
Kebocoran target terjadi ketika sebuah fitur disertakan dalam data pelatihan yang tidak dapat diketahui saat pelatihan, dan yang didasarkan pada hasilnya. Misalnya, jika Anda menyertakan nomor Frequent Buyer untuk model yang dilatih untuk memutuskan apakah pengguna pertama kali akan melakukan pembelian, model tersebut akan memiliki metrik evaluasi yang sangat tinggi, tetapi akan berperforma buruk pada data sebenarnya, karena jumlah Frequent Buyer tidak dapat disertakan.
Untuk memeriksa kebocoran target, tinjau grafik Tingkat kepentingan fitur di tab Evaluate untuk model Anda. Pastikan kolom dengan nilai penting yang tinggi benar-benar prediktif dan tidak membocorkan informasi tentang target.
Kolom waktu
Jika waktu data Anda penting, pastikan Anda menggunakan kolom Waktu atau pemisahan manual berdasarkan waktu. Tidak melakukannya dapat mendistorsi metrik evaluasi Anda. Pelajari lebih lanjut.
Mendownload set data pengujian ke BigQuery
Anda dapat mendownload set data pengujian, termasuk kolom target, beserta hasil model untuk setiap baris. Memeriksa baris yang salah pada model dapat memberikan petunjuk tentang cara meningkatkan model.
Buka AutoML Tables di Konsol Google Cloud.
Pilih Models di panel navigasi sebelah kiri dan klik model Anda.
Buka tab Evaluate, lalu klik Export Predictions on test set data to BigQuery.
Setelah ekspor selesai, klik Lihat hasil evaluasi Anda di BigQuery untuk melihat data.
Langkah selanjutnya
- Deploy model untuk mendapatkan prediksi online.
- Dapatkan prediksi batch dari model Anda.