Visualiza la latencia de las solicitudes de la app
Aprende a recopilar y ver datos de latencia de tus aplicaciones:
Crea un clúster de Google Kubernetes Engine (GKE) con Google Cloud CLI.
Descarga y, luego, implementa una aplicación de ejemplo en tu clúster.
Enviar una solicitud HTTP a la aplicación de ejemplo para crear un seguimiento.
Visualiza la información de latencia del seguimiento que creaste.
Realizar una limpieza.
Para seguir la guía paso a paso sobre esta tarea de forma directa en la consola de Google Cloud, haz clic en Guiarme:
Antes de comenzar
-
Es posible que las restricciones de seguridad que define tu organización no te permitan completar los siguientes pasos. Para obtener información sobre la solución de problemas, consulta Desarrolla aplicaciones en un entorno de Google Cloud restringido.
- Accede a tu cuenta de Google Cloud. Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
Habilita las API de Google Kubernetes Engine and Cloud Trace.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
Habilita las API de Google Kubernetes Engine and Cloud Trace.
Crea un clúster de GKE
En la barra de herramientas, haz clic en terminal
Activar Cloud Shell y, luego, realiza los siguientes pasos en Cloud Shell.Crea un clúster:
gcloud container clusters create cloud-trace-demo --zone us-central1-cEl comando anterior, que tarda varios minutos en completarse, crea un clúster estándar con el nombre
cloud-trace-demoen la zonaus-central1-c.Configura
kubectlpara que actualice sus credenciales de forma automática a fin de usar la misma identidad que Google Cloud CLI:gcloud container clusters get-credentials cloud-trace-demo --zone us-central1-cVerifica el acceso a tu clúster:
kubectl get nodesEl siguiente es un resultado de ejemplo de este comando:
NAME STATUS ROLES AGE VERSION gke-cloud-trace-demo-default-pool-063c0416-113s Ready <none> 78s v1.22.12-gke.2300 gke-cloud-trace-demo-default-pool-063c0416-1n27 Ready <none> 79s v1.22.12-gke.2300 gke-cloud-trace-demo-default-pool-063c0416-frkd Ready <none> 78s v1.22.12-gke.2300
Descarga e implementa una aplicación
Descarga y, luego, implementa una aplicación de Python, que use el framework de Flask y el paquete de OpenTelemetry. La aplicación se describe en la sección Acerca de la app de esta página.
En Cloud Shell, haz lo siguiente:
Clona una app de Python desde GitHub:
git clone https://github.com/GoogleCloudPlatform/python-docs-samples.gitEjecuta el siguiente comando para implementar la aplicación de muestra:
cd python-docs-samples/trace/cloud-trace-demo-app-opentelemetry && ./setup.shLa secuencia de comandos
setup.shtarda varios minutos en completarse.La secuencia de comandos configura tres servicios con una imagen compilada con anterioridad y, luego, espera a que se aprovisionen todos los recursos. Las cargas de trabajo se llaman
cloud-trace-demo-a,cloud-trace-demo-bycloud-trace-demo-c.El siguiente es un resultado de ejemplo de este comando:
deployment.apps/cloud-trace-demo-a is created service/cloud-trace-demo-a is created deployment.apps/cloud-trace-demo-b is created service/cloud-trace-demo-b is created deployment.apps/cloud-trace-demo-c is created service/cloud-trace-demo-c is created Wait for load balancer initialization complete...... Completed.
Cómo crear datos de seguimiento
Un trace describe el tiempo que tarda una aplicación en completar una sola operación.
Para crear un seguimiento, ejecuta el siguiente comando en Cloud Shell:
curl $(kubectl get svc -o=jsonpath='{.items[?(@.metadata.name=="cloud-trace-demo-a")].status.loadBalancer.ingress[0].ip}')
La respuesta del comando anterior se ve de la siguiente manera:
Hello, I am service A
And I am service B
Hello, I am service C
Puedes ejecutar el comando curl varias veces para generar múltiples seguimientos.
Consulta los datos de latencia
-
En el panel de navegación de la consola de Google Cloud, selecciona Trace y, luego, Explorador de seguimiento:
Ve al Explorador de seguimiento
Cada seguimiento se representa con un punto en el gráfico y una fila en la tabla.
En la siguiente captura de pantalla, se muestran varios seguimientos:
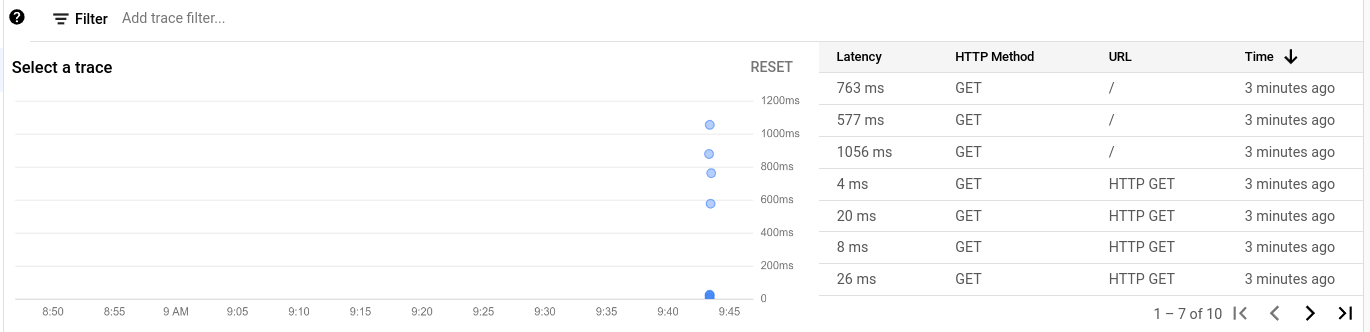
Para ver un seguimiento en detalle, selecciona un punto en el gráfico o una fila en la tabla.
El diagrama de dispersión se actualiza y el punto que seleccionaste se destaca con un círculo dibujado a su alrededor, y todos los demás puntos que representan todos los demás seguimientos se atenúan.
Un diagrama de Gantt muestra información sobre el seguimiento seleccionado. La primera fila en el diagrama de Gantt es para el seguimiento, y existe una fila para cada intervalo del seguimiento. Un intervalo describe cuánto tiempo se tarda en llevar a cabo una suboperación completa.
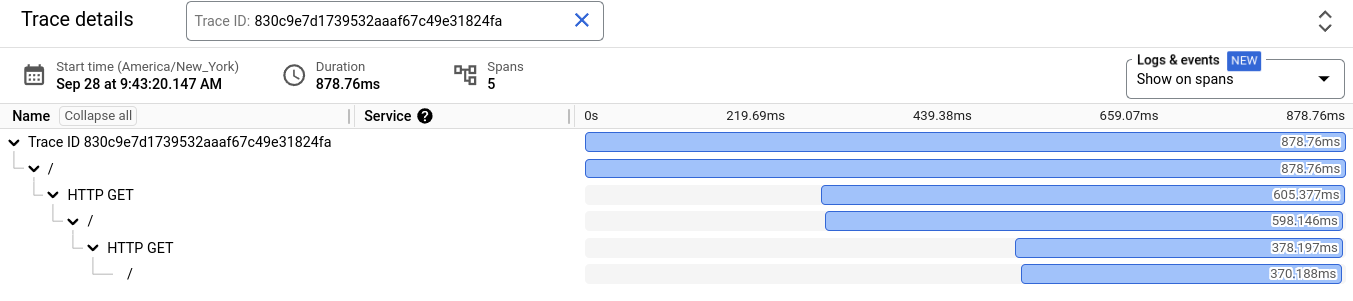
Para ver información detallada sobre un intervalo, selecciona el intervalo en el diagrama de Gantt.
Acerca de la aplicación
La aplicación de muestra que se usa en esta guía de inicio rápido está disponible en un repositorio de GitHub. Este repositorio contiene información sobre cómo usar la aplicación en entornos distintos de Cloud Shell. La aplicación de muestra está escrita en Python, usa el framework de Flask y los paquetes de OpenTelemetry, y se ejecuta en un clúster de GKE.
Instrumentación
El archivo app.py en el repositorio de GitHub contiene la instrumentación necesaria para capturar y enviar datos de seguimiento a tu proyecto de Google Cloud:
La aplicación importa varios paquetes de OpenTelemetry:
La aplicación instrumenta las solicitudes web con contexto de seguimiento y hace un seguimiento automático de los controladores y las solicitudes de Flask a otros servicios:
La aplicación configura el exportador de Cloud Trace como un proveedor de seguimiento, que propaga el contexto de seguimiento en el formato de Cloud Trace:
En el siguiente fragmento de código, se muestra cómo enviar solicitudes en Python. OpenTelemetry propaga de manera implícita el contexto de seguimiento con tus solicitudes salientes:
Cómo funciona la aplicación
Para mayor claridad, en esta sección, cloud-trace-demo se omite de los nombres de servicio. Por ejemplo, al servicio cloud-trace-demo-c se le hace referencia como c.
Esta aplicación crea tres servicios llamados a, b y c. El servicio a está configurado para llamar al servicio b y el servicio b está configurado para llamar al servicio c.
Para obtener más detalles sobre la configuración de los servicios, consulta los archivos YAML en el repositorio de GitHub.
Cuando emitiste una solicitud HTTP al servicio a en esta guía de inicio rápido, usaste el siguiente comando de curl:
curl $(kubectl get svc -o=jsonpath='{.items[?(@.metadata.name=="cloud-trace-demo-a")].status.loadBalancer.ingress[0].ip}')
El comando curl funciona de la siguiente manera:
kubectlrecupera la dirección IP del servicio llamadacloud-trace-demo-a.- Luego, el comando
curlenvía la solicitud HTTP al servicioa. - El servicio
arecibe la solicitud HTTP y envía una solicitud al serviciob. - El servicio
brecibe la solicitud HTTP y envía una solicitud al servicioc. - El servicio
crecibe la solicitud HTTP del servicioby muestra la cadenaHello, I am service Cal serviciob. - El servicio
brecibe la respuesta del servicioc, la agrega a la stringAnd I am service By muestra el resultado al servicioa. - El servicio
arecibe la respuesta del servicioby la agrega a la stringHello, I am service A. - La respuesta del servicio
ase muestra en Cloud Shell.
Limpia
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que se usaron en esta página.
Si creaste un proyecto nuevo y ya no lo necesitas, bórralo.
Si usaste un proyecto existente, haz lo siguiente:
Para borrar tu clúster, ejecuta el siguiente comando en Cloud Shell:
gcloud container clusters delete cloud-trace-demo --zone us-central1-c
¿Qué sigue?
- Para obtener información sobre los lenguajes y las plataformas compatibles, consulta Descripción general de Cloud Trace.
Para obtener detalles sobre cómo instrumentar tus aplicaciones, consulta:
Para obtener más información sobre la ventana del Explorador de seguimiento, consulta Cómo buscar y ver seguimientos.
Para obtener más información sobre cómo administrar clústeres de GKE, consulta kubectl.