La maggior parte dei bilanciatori del carico utilizza un approccio di hashing basato su round robin o su flusso per distribuire il traffico. Tuttavia, i bilanciatori del carico che utilizzano questo approccio possono avere difficoltà ad adattarsi quando i picchi di domanda superano la capacità di pubblicazione disponibile. Questo articolo spiega come l'utilizzo di Cloud Load Balancing può risolvere questi problemi e ottimizzare la capacità delle applicazioni a livello globale. Ciò spesso si traduce in un'esperienza utente migliore e in costi inferiori rispetto alle implementazioni di bilanciamento del carico tradizionali.
Questo articolo fa parte di una serie di best practice incentrata sui prodotti di bilanciamento del carico Cloud di Google. Per un tutorial che accompagna questo articolo, consulta Gestione della capacità con il bilanciamento del carico. Per un'analisi approfondita della latenza, consulta Ottimizzazione della latenza delle applicazioni con il bilanciamento del carico.
Problemi di capacità nelle applicazioni globali
La scalabilità delle applicazioni globali può essere complessa, soprattutto se hai budget IT limitati e carichi di lavoro imprevedibili e intermittenti. In ambienti cloud pubblico come Google Cloud, la flessibilità offerta da funzionalità come la scalabilità automatica e il bilanciamento del carico può essere utile. Tuttavia, gli autoscaler hanno alcune limitazioni, come spiegato in questa sezione.
Latenza nell'avvio di nuove istanze
Il problema più comune della scalabilità automatica è che l'applicazione richiesta non è pronta per gestire il traffico abbastanza rapidamente. A seconda delle immagini delle istanze VM, in genere gli script devono essere eseguiti e le informazioni caricate prima che le istanze VM siano pronte. Spesso sono necessari alcuni minuti prima che il bilanciamento del carico possa indirizzare gli utenti alle nuove istanze VM. Durante questo periodo, il traffico viene distribuito alle istanze VM esistenti, che potrebbero già superare la capacità.
Applicazioni limitate dalla capacità del backend
Alcune applicazioni non possono essere scalate automaticamente. Ad esempio, i database spesso hanno una capacità di backend limitata. Solo un numero specifico di frontend può accedere a un database che non è scalabile orizzontalmente. Se la tua applicazione si basa su API esterne che supportano solo un numero limitato di richieste al secondo, non può essere sottoposta ad autoscaling.
Licenze non elastiche
Quando utilizzi software concesso in licenza, la licenza spesso ti limita a una capacità massima preimpostata. La tua capacità di eseguire il ridimensionamento automatico potrebbe quindi essere limitata perché non puoi aggiungere licenze al volo.
Spazio di manovra delle istanze VM troppo ridotto
Per tenere conto di improvvisi picchi di traffico, un'autoscalabilità deve includere un ampio margine di manovra (ad esempio, l'autoscalabilità viene attivata al 70% della capacità della CPU). Per risparmiare sui costi, potresti essere tentato di impostare un target più elevato, ad esempio il 90% della capacità della CPU. Tuttavia, valori di attivazione più elevati potrebbero comportare colli di bottiglia di scalabilità quando si verificano picchi di traffico, ad esempio una campagna pubblicitaria che aumenta improvvisamente la domanda. Devi bilanciare le dimensioni del margine in base all'entità del picco del traffico e al tempo necessario per preparare le nuove istanze VM.
Quote regionali
Se si verificano picchi imprevisti in una regione, le quote di risorse esistenti potrebbero limitare il numero di istanze che puoi scalare al di sotto del livello richiesto per supportare il picco attuale. L'elaborazione di un aumento della quota delle risorse può richiedere alcune ore o alcuni giorni.
Risolvere questi problemi con il bilanciamento del carico globale
I bilanciatori del carico delle applicazioni esterni e i bilanciatori del carico di rete proxy esterni sono prodotti di bilanciamento del carico globale con proxy tramite server Google Front End (GFE) sincronizzati a livello globale, il che semplifica la mitigazione di questi tipi di problemi di bilanciamento del carico. Questi prodotti offrono una soluzione ai problemi perché il traffico viene distribuito ai backend in modo diverso rispetto alla maggior parte delle soluzioni di bilanciamento del carico a livello di regione.
Queste differenze sono descritte nelle sezioni seguenti.
Algoritmi utilizzati da altri bilanciatori del carico
La maggior parte dei bilanciatori del carico utilizza gli stessi algoritmi per distribuire il traffico tra i backend:
- Round-robin. I pacchetti vengono distribuiti equamente tra tutti i backend, indipendentemente dall'origine e dalla destinazione.
- Hashing. I flussi di pacchetti vengono identificati in base agli hash delle informazioni sul traffico, inclusi IP di origine, IP di destinazione, porta e protocollo. Tutto il traffico che produce lo stesso valore hash viene inviato allo stesso backend.
Il bilanciamento del carico tramite hashing è l'algoritmo attualmente disponibile per i bilanciatori del carico di rete passthrough esterni. Questo bilanciatore del carico supporta l'hashing a due tuple (in base all'IP di origine e di destinazione), l'hashing a tre tuple (in base all'IP di origine, all'IP di destinazione e al protocollo) e l'hashing a cinque tuple (in base all'IP di origine, all'IP di destinazione, alla porta di origine, alla porta di destinazione e al protocollo).
Con entrambi questi algoritmi, le istanze non sane vengono rimosse dalla distribuzione. Tuttavia, il carico corrente sui backend raramente è un fattore nella distribuzione del carico.
Alcuni bilanciatori del carico hardware o software utilizzano algoritmi che inoltrano il traffico in base ad altre metriche, come il round robin ponderato, il carico più basso, il tempo di risposta più rapido o il numero di connessioni attive. Tuttavia, se il carico aumenta oltre il livello previsto a causa di picchi di traffico improvvisi, il traffico viene comunque distribuito a istanze di backend che superano la capacità, con un conseguente aumento drastico della latenza.
Alcuni bilanciatori del carico consentono regole avanzate in cui il traffico che supera la capacità del backend viene inoltrato a un altro pool o reindirizzato a un sito web statico. In questo modo puoi rifiutare efficacemente questo traffico e inviare un messaggio "servizio non disponibile, riprova più tardi". Alcuni bilanciatori del carico ti consentono di mettere le richieste in coda.
Le soluzioni di bilanciamento del carico globale vengono spesso implementate con un algoritmo basato su DNS, che fornisce diversi IP di bilanciamento del carico regionale in base alla posizione dell'utente e al carico del backend. Queste soluzioni offrono il failover in un'altra regione per tutto o parte del traffico di un deployment regionale. Tuttavia, su qualsiasi soluzione basata su DNS, il failover richiede in genere alcuni minuti, a seconda del valore TTL (time-to-live) delle voci DNS. In generale, una piccola quantità di traffico continuerà a essere indirizzata ai vecchi server ben oltre il momento in cui il TTL dovrebbe essere scaduto ovunque. Pertanto, il bilanciamento del carico globale basato su DNS non è la soluzione ottimale per gestire il traffico in scenari di picchi.
Come funzionano i bilanciatori del carico delle applicazioni esterni
Il bilanciatore del carico delle applicazioni esterno utilizza un approccio diverso. Il traffico viene eseguito tramite proxy tramite i server GFE implementati nella maggior parte delle località perimetrali della rete globale di Google. Al momento, sono presenti più di 80 sedi in tutto il mondo. L'algoritmo di bilanciamento del carico viene applicato ai server GFE.

Il bilanciatore del carico delle applicazioni esterno è disponibile tramite un unico indirizzo IP stabile annunciato a livello globale nei nodi edge e le connessioni vengono terminate da uno dei GFE.
I GFE sono interconnessi tramite la rete globale di Google. I dati che descrivono i backend disponibili e la capacità di pubblicazione disponibile per ogni risorsa bilanciata in base al carico vengono distribuiti continuamente a tutti i GFE utilizzando un piano di controllo globale.
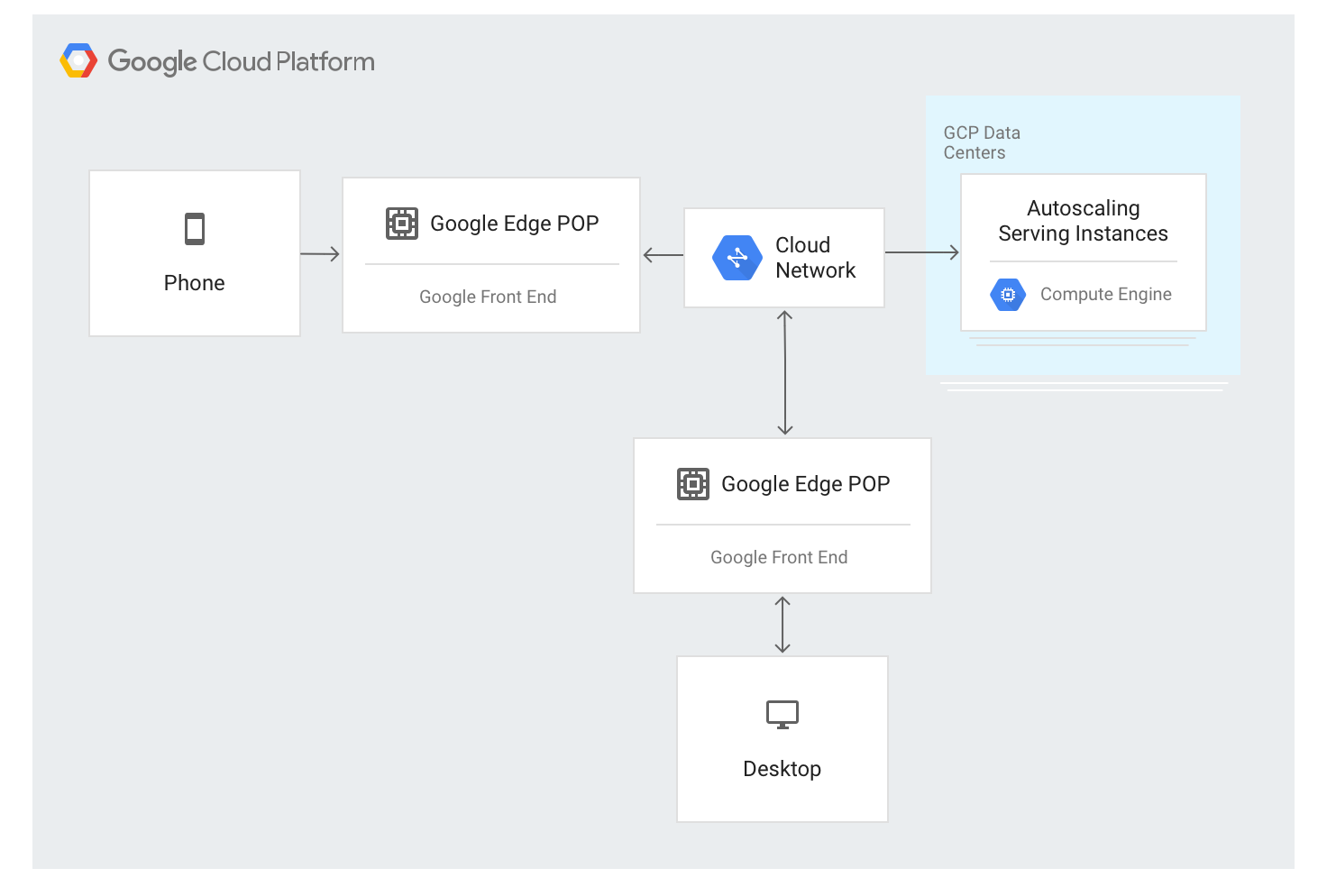
Il traffico verso gli indirizzi IP bilanciati in base al carico viene eseguito tramite proxy per le istanze di backend definite nella configurazione del bilanciatore del carico delle applicazioni esterno utilizzando un algoritmo di bilanciamento del carico speciale chiamato Waterfall per regione. Questo algoritmo determina il backend ottimale per soddisfare la richiesta tenendo conto della vicinanza delle istanze agli utenti, del carico in entrata e della capacità disponibile dei backend in ogni zona e regione. Infine, vengono presi in considerazione anche il carico e la capacità a livello mondiale.
Il bilanciatore del carico delle applicazioni esterno distribuisce il traffico in base alle istanze disponibili. Per aggiungere nuove istanze in base al carico, l'algoritmo funziona in combinazione con i gruppi di istanze con scalabilità automatica.
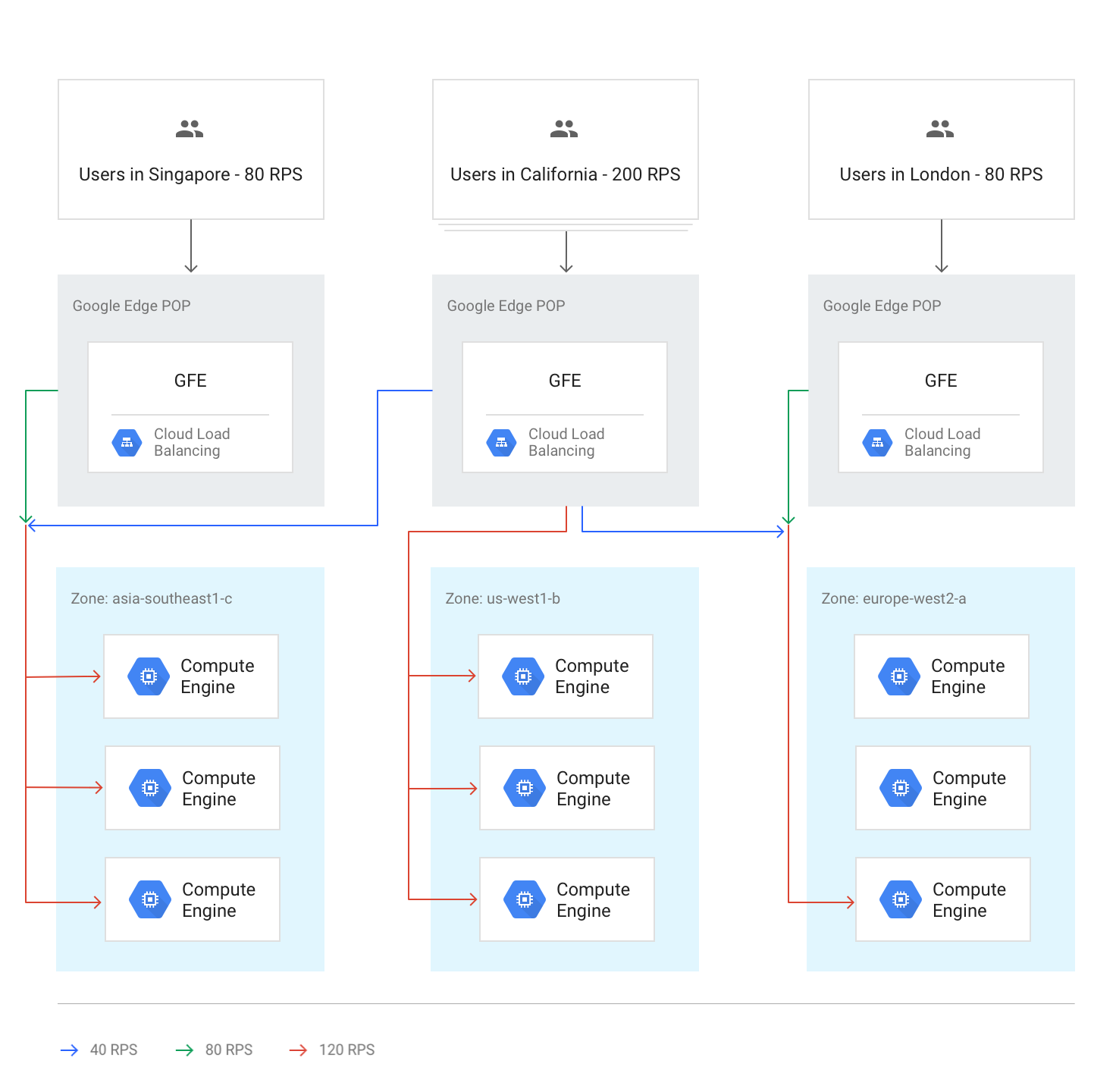
Flusso di traffico all'interno di una regione
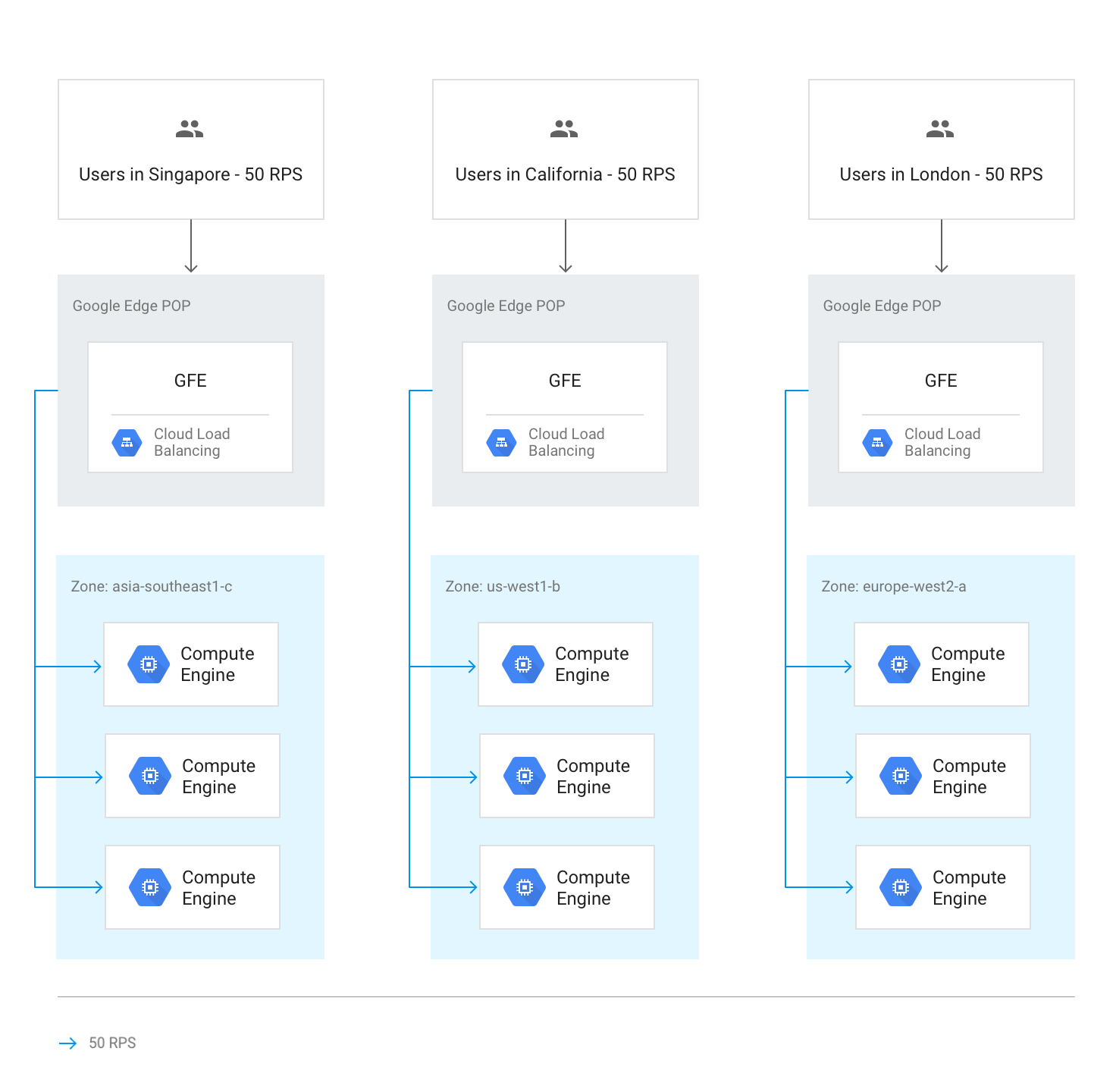
In circostanze normali, tutto il traffico viene inviato alla regione più vicina all'utente. Il bilanciamento del carico viene quindi eseguito in base alle seguenti linee guida:
All'interno di ogni regione, il traffico viene distribuito tra i gruppi di istanze, che possono trovarsi in più zone in base alla capacità di ciascun gruppo.
Se la capacità è diversa tra le zone, le zone vengono caricate in proporzione alla loro capacità di pubblicazione disponibile.
All'interno delle zone, le richieste vengono distribuite in modo uniforme tra le istanze di ciascun gruppo di istanze.
Le sessioni vengono conservate in base all'indirizzo IP del client o a un valore del cookie, a seconda dell'impostazione di affinità della sessione.
A meno che il backend non diventi non disponibile, le connessioni TCP esistenti non vengono mai spostate su un backend diverso.
Il seguente diagramma mostra la distribuzione del carico in questo caso, in cui ogni regione ha una capacità inferiore e può gestire il carico degli utenti più vicini.
Traffico in overflow in altre regioni
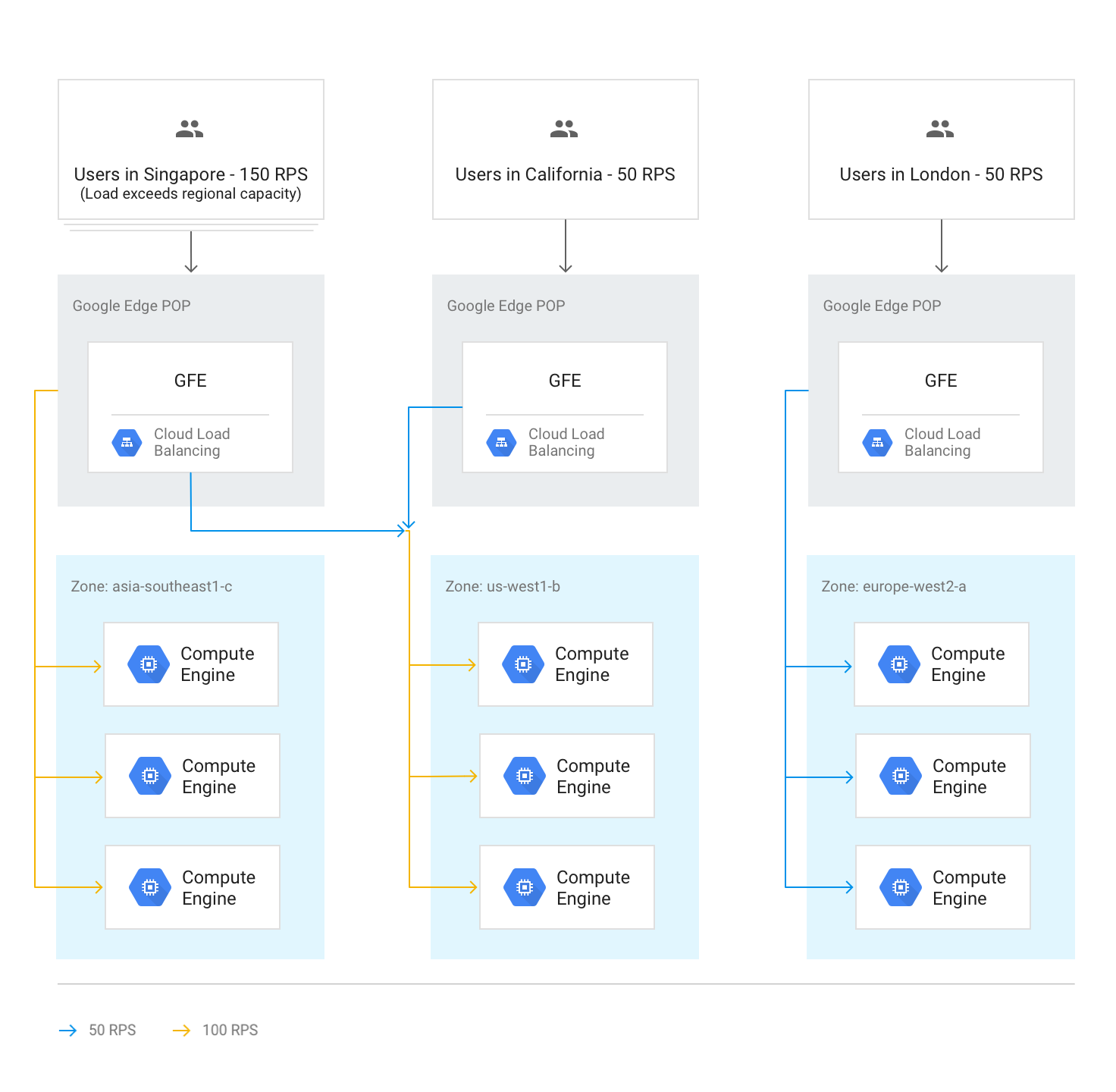
Se un'intera regione raggiunge la capacità in base alla capacità di pubblicazione impostata nei servizi di backend, viene attivato l'algoritmo a cascata per regione e il traffico viene trasferito alla regione più vicina con capacità disponibile. Quando ogni regione raggiunge la capacità massima, il traffico viene indirizzato alla regione più vicina e così via. La vicinanza di una regione all'utente è definita dal tempo di percorrenza della rete dal GFE ai backend dell'istanza.
Il seguente diagramma mostra il trasferimento alla regione più vicina quando una regione riceve più traffico di quanto possa gestire a livello regionale.
Sovraccarico tra regioni a causa di backend non integri
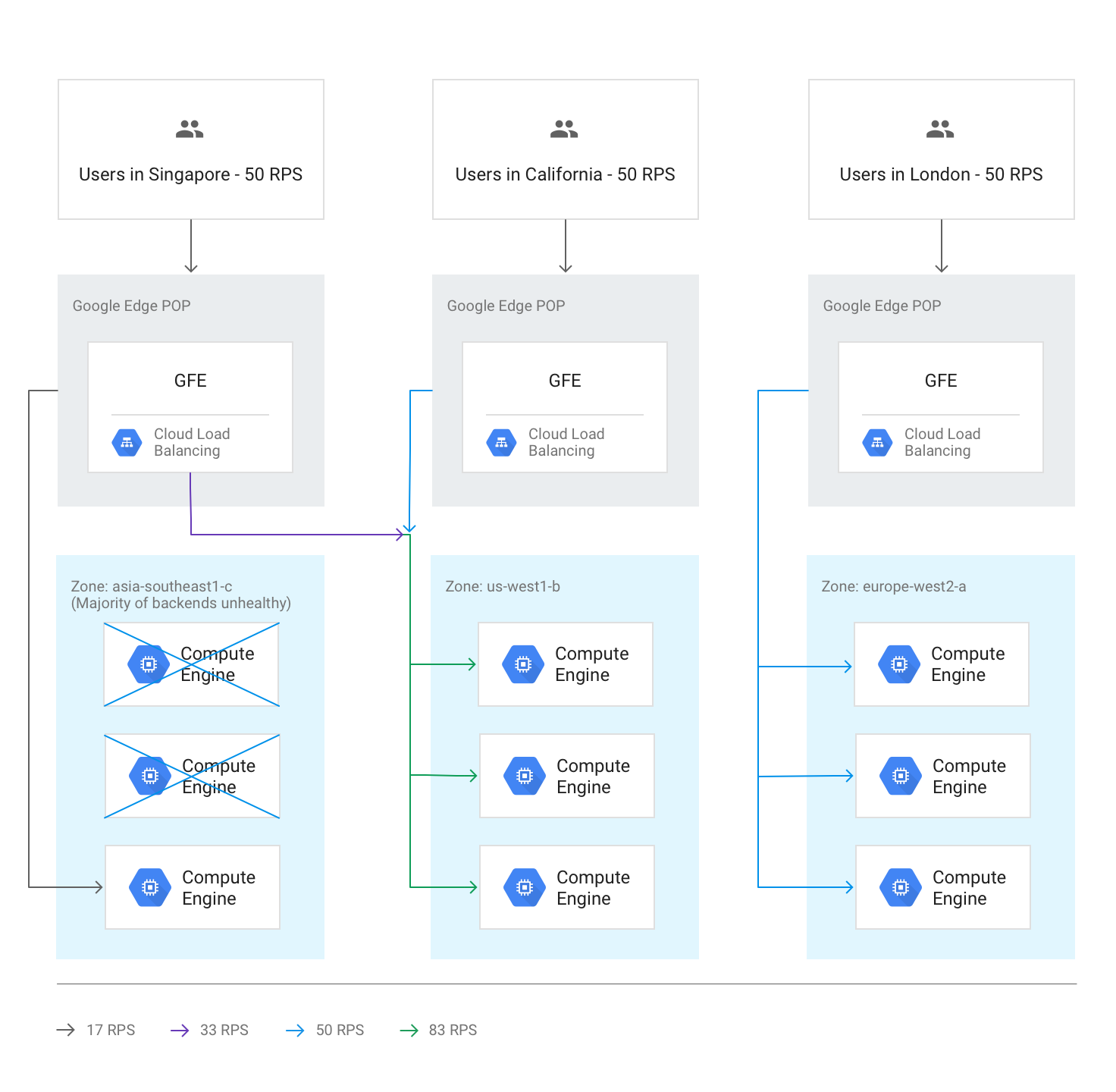
Se i controlli di integrità rilevano che più della metà dei backend di una regione non è in stato di integrità, i GFE indirizzano in modo preventivo parte del traffico alla regione più vicina. Questo accade per evitare che il traffico non funzioni completamente quando la regione diventa non integra. Questo overflow si verifica anche se la capacità rimanente nella regione con i backend non validi è sufficiente.
Il seguente diagramma mostra il meccanismo di overflow in azione, perché la maggior parte dei backend in una zona non è in stato normale.
Tutte le regioni sopra la capacità
Quando il traffico verso tutte le regioni raggiunge o supera la capacità, viene bilanciato in modo che ogni regione abbia lo stesso livello relativo di overflow rispetto alla sua capacità. Ad esempio, se la domanda globale supera la capacità globale del 20%, il traffico viene distribuito in modo che tutte le regioni ricevano richieste superiori del 20% alla loro capacità regionale, mantenendo il traffico il più locale possibile.
Il seguente diagramma mostra questa regola di overflow globale in vigore. In questo caso, una singola regione riceve così tanto traffico che non può essere distribuito con la capacità di pubblicazione disponibile a livello globale.
Sovraccarico temporaneo durante la scalabilità automatica
La scalabilità automatica si basa sui limiti di capacità configurati su ogni servizio di backend e avvia nuove istanze quando il traffico si avvicina ai limiti di capacità configurati. A seconda della velocità con cui aumentano i livelli di richiesta e della velocità con cui le nuove istanze vengono messe online, l'overflow in altre regioni potrebbe non essere necessario. In altri casi, l'overflow può fungere da buffer temporaneo finché le nuove istanze locali non sono online e pronte a gestire il traffico in tempo reale. Quando la capacità espansa dalla scalabilità automatica è sufficiente, tutte le nuove sessioni vengono distribuite nella regione più vicina.
Effetti della latenza dell'overflow
In base all'algoritmo a cascata per regione, può verificarsi il sovraccarico di parte del traffico da parte del bilanciatore del carico delle applicazioni esterno verso altre regioni. Tuttavia, le sessioni TCP e il traffico SSL vengono comunque terminati dal GFE più vicino all'utente. Questo è utile per la latenza delle applicazioni. Per maggiori dettagli, consulta Ottimizzazione della latenza delle applicazioni con il bilanciamento del carico.
Pratica: misurare gli effetti della gestione della capacità
Per capire come si verifica il sovraccarico e come gestirlo utilizzando il bilanciatore del carico HTTP, consulta il tutorial Gestione della capacità con il bilanciamento del carico allegato a questo articolo.
Utilizzo di un bilanciatore del carico delle applicazioni esterno per risolvere i problemi di capacità
Per contribuire a risolvere i problemi discussi in precedenza, i bilanciatori del carico delle applicazioni esterni e i bilanciatori del carico di rete proxy esterni possono trasferire la capacità in altre regioni. Per le applicazioni globali, rispondere agli utenti con una latenza complessiva leggermente superiore offre un'esperienza migliore rispetto all'utilizzo di un backend regionale. Le applicazioni che utilizzano un backend regionale hanno una latenza nominalmente inferiore, ma possono essere sovraccaricate.
Vediamo di nuovo in che modo un bilanciatore del carico delle applicazioni esterno può aiutarti a gestire gli scenari menzionati all'inizio dell'articolo:
Latenza nell'avvio di nuove istanze. Se l'autoscalatore non riesce ad aggiungere capacità sufficientemente rapidamente durante le punte di traffico locale, il bilanciatore del carico delle applicazioni esterno aggira temporaneamente le connessioni alla regione più vicina. In questo modo, le sessioni utente esistenti nella regione originale vengono gestite a una velocità ottimale poiché rimangono sui backend esistenti, mentre le sessioni dei nuovi utenti subiscono solo un leggero aumento della latenza. Non appena viene eseguito il ridimensionamento di altre istanze di backend nella regione originale, il nuovo traffico viene reindirizzato alla regione più vicina agli utenti.
Applicazioni limitate dalla capacità del backend. Le applicazioni che non possono essere scalate automaticamente, ma che sono disponibili in più regioni, possono comunque essere trasferite alla regione più vicina quando la domanda in una regione supera la capacità di deployment per le normali esigenze di traffico.
Licenze non elastiche. Se il numero di licenze software è limitato e il pool di licenze nella regione corrente è esaurito, il bilanciatore del carico delle applicazioni esterno può spostare il traffico in una regione in cui sono disponibili le licenze. Affinché funzioni, il numero massimo di istanze è impostato sul numero massimo di licenze nell'autoscaler.
Spazio VM insufficiente. La possibilità di overflow regionale consente di risparmiare, perché puoi configurare la scalabilità automatica con un attivatore per un utilizzo elevato della CPU. Puoi anche configurare la capacità di backend disponibile al di sotto di ogni picco regionale, perché il trasferimento in altre regioni garantisce che la capacità globale sia sempre sufficiente.
Quote regionali. Se le quote delle risorse di Compute Engine non soddisfano la domanda, il bilanciatore del carico delle applicazioni esterno reindirizza automaticamente parte del traffico a una regione che può ancora scalare entro la quota regionale.
Passaggi successivi
Le seguenti pagine forniscono ulteriori informazioni e informazioni di base sulle opzioni di bilanciamento del carico di Google:
- Tutorial sulla gestione della capacità con il bilanciamento del carico
- Ottimizzazione della latenza delle applicazioni con il bilanciamento del carico
- Codelab Networking 101
- Bilanciatore del carico di rete passthrough esterno
- Bilanciatore del carico delle applicazioni esterno
- Bilanciatore del carico di rete proxy esterno