La mayoría de los balanceadores de carga usan un enfoque de hash basado en flujo o round-robin para distribuir el tráfico. Sin embargo, los balanceadores de carga que usan este enfoque pueden tener dificultades para adaptarse cuando la demanda supera la capacidad de servicio disponible. En este artículo se explica cómo Cloud Load Balancing puede solucionar estos problemas y optimizar la capacidad de tu aplicación global. Esto suele traducirse en una mejor experiencia de usuario y en costes más bajos en comparación con las implementaciones de balanceo de carga tradicionales.
Este artículo forma parte de una serie de prácticas recomendadas centrada en los productos de balanceo de carga de Google Cloud. Para ver un tutorial que acompaña a este artículo, consulta Gestión de la capacidad con balanceo de carga. Para obtener información detallada sobre la latencia, consulta el artículo Optimizar la latencia de las aplicaciones mediante el balanceo de carga.
Problemas de capacidad en aplicaciones globales
Escalar aplicaciones globales puede ser complicado, sobre todo si tienes presupuestos de TI limitados y cargas de trabajo impredecibles y con picos. En entornos de nube pública, como Google Cloud, la flexibilidad que ofrecen funciones como el autoescalado y el balanceo de carga puede ser de gran ayuda. Sin embargo, los escaladores automáticos tienen algunas limitaciones, tal como se explica en esta sección.
Latencia al iniciar nuevas instancias
El problema más habitual con el escalado automático es que la aplicación solicitada no está lista para atender tu tráfico con la suficiente rapidez. En función de las imágenes de las instancias de VM, normalmente se deben ejecutar secuencias de comandos y cargar información antes de que las instancias de VM estén listas. A menudo, se tarda unos minutos en que el balanceo de carga pueda dirigir a los usuarios a las nuevas instancias de VM. Durante ese tiempo, el tráfico se distribuye a las instancias de VM existentes, que ya pueden estar sobrecargadas.
Aplicaciones limitadas por la capacidad del backend
Algunas aplicaciones no se pueden escalar automáticamente. Por ejemplo, las bases de datos suelen tener una capacidad de backend limitada. Solo un número específico de front-ends puede acceder a una base de datos que no se escala horizontalmente. Si tu aplicación depende de APIs externas que solo admiten un número limitado de solicitudes por segundo, tampoco se podrá escalar automáticamente.
Licencias no elásticas
Cuando usas software con licencia, esta suele limitarte a una capacidad máxima predefinida. Por lo tanto, es posible que no puedas usar el escalado automático porque no puedes añadir licencias sobre la marcha.
Espacio libre de instancias de VM insuficiente
Para tener en cuenta los picos de tráfico repentinos, un autoescalador debe incluir un margen amplio (por ejemplo, el autoescalador se activa al 70% de la capacidad de la CPU). Para ahorrar costes, puede que te veas tentado a aumentar este objetivo, por ejemplo, al 90% de la capacidad de la CPU. Sin embargo, si los valores de activación son más altos, pueden producirse cuellos de botella en el escalado cuando se produzcan picos de tráfico, como en el caso de una campaña publicitaria que aumente la demanda de forma repentina. Debes equilibrar el tamaño del margen en función de la variabilidad del tráfico y del tiempo que tarden en prepararse las nuevas instancias de VM.
Cuotas regionales
Si se producen picos inesperados en una región, es posible que tus cuotas de recursos limiten el número de instancias que puedes escalar por debajo del nivel necesario para admitir el pico actual. El proceso para aumentar la cuota de recursos puede tardar unas horas o días.
Abordar estos retos con el balanceo de carga global
Los balanceadores de carga de aplicación externos y los balanceadores de carga de red con proxy externo son productos de balanceo de carga globales que se proxyizan a través de servidores de Google Front End (GFE) sincronizados a nivel mundial, lo que facilita la mitigación de este tipo de problemas de balanceo de carga. Estos productos ofrecen una solución a los problemas porque el tráfico se distribuye a los back-ends de forma diferente a la mayoría de las soluciones de balanceo de carga regionales.
Estas diferencias se describen en las siguientes secciones.
Algoritmos usados por otros balanceadores de carga
La mayoría de los balanceadores de carga usan los mismos algoritmos para distribuir el tráfico entre los back-ends:
- Round-robin. Los paquetes se distribuyen equitativamente entre todos los back-ends, independientemente del origen y el destino de los paquetes.
- Hashing. Los flujos de paquetes se identifican en función de los hashes de la información del tráfico, como la IP de origen, la IP de destino, el puerto y el protocolo. Todo el tráfico que genera el mismo valor de hash se dirige al mismo backend.
El balanceo de carga por hashing es el algoritmo que está disponible actualmente para los balanceadores de carga de red de paso a través externos. Este balanceador de carga admite el hashing de 2 tuplas (basado en la IP de origen y de destino), el hashing de 3 tuplas (basado en la IP de origen, la IP de destino y el protocolo) y el hashing de 5 tuplas (basado en la IP de origen, la IP de destino, el puerto de origen, el puerto de destino y el protocolo).
Con ambos algoritmos, las instancias no saludables se excluyen de la distribución. Sin embargo, la carga actual de los back-ends rara vez es un factor en la distribución de la carga.
Algunos balanceadores de carga de hardware o software usan algoritmos que reenvían el tráfico en función de otras métricas, como el round-robin ponderado, la carga más baja, el tiempo de respuesta más rápido o el número de conexiones activas. Sin embargo, si la carga aumenta por encima del nivel esperado debido a picos de tráfico repentinos, el tráfico se sigue distribuyendo a las instancias de backend que superan la capacidad, lo que provoca aumentos drásticos de la latencia.
Algunos balanceadores de carga permiten reglas avanzadas en las que el tráfico que supera la capacidad del backend se reenvía a otro grupo o se redirige a un sitio web estático. De esta forma, puedes rechazar este tráfico y enviar un mensaje que indique que el servicio no está disponible y que se vuelva a intentar más tarde. Algunos balanceadores de carga te ofrecen la opción de poner solicitudes en una cola.
Las soluciones de balanceo de carga global suelen implementarse con un algoritmo basado en DNS, que sirve diferentes IPs de balanceo de carga regionales en función de la ubicación del usuario y de la carga del backend. Estas soluciones ofrecen conmutación por error a otra región para todo o parte del tráfico de una implementación regional. Sin embargo, en cualquier solución basada en DNS, la conmutación por error suele tardar unos minutos, en función del valor de tiempo de vida (TTL) de las entradas DNS. Por lo general, una pequeña cantidad de tráfico seguirá dirigiéndose a los servidores antiguos mucho después de que el TTL haya caducado en todas partes. Por lo tanto, el balanceo de carga mundial basado en DNS no es la solución óptima para gestionar el tráfico en situaciones de picos.
Cómo funcionan los balanceadores de carga de aplicación externos
El balanceador de carga de aplicación externo usa un enfoque diferente. El tráfico se envía a través de servidores GFE desplegados en la mayoría de las ubicaciones de la red global de Google. Actualmente, hay más de 80 ubicaciones en todo el mundo. El algoritmo de balanceo de carga se aplica en los servidores de GFE.

El balanceador de carga de aplicaciones externo está disponible a través de una sola dirección IP estable que se anuncia de forma global en los nodos perimetrales, y las conexiones se terminan en cualquiera de los GFE.
Los GFEs están interconectados a través de la red mundial de Google. Los datos que describen los back-ends disponibles y la capacidad de servicio disponible de cada recurso con balanceo de carga se distribuyen continuamente a todos los GFEs mediante un plano de control global.
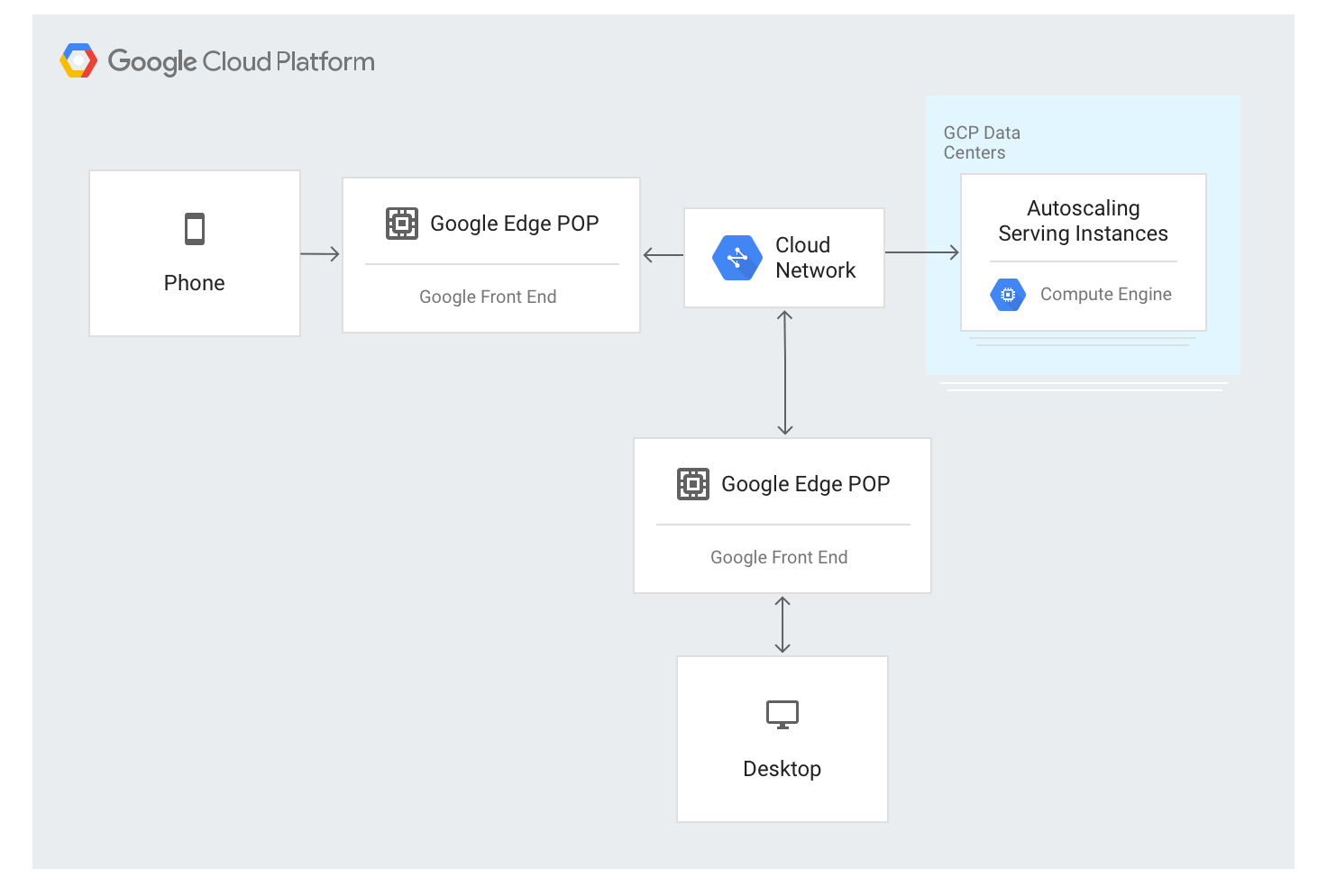
El tráfico a las direcciones IP balanceadas de carga se envía a las instancias de backend definidas en la configuración del balanceador de carga de aplicaciones externo mediante un algoritmo de balanceo de carga especial llamado Cascada por región. Este algoritmo determina el backend óptimo para atender la solicitud teniendo en cuenta la proximidad de las instancias a los usuarios, la carga entrante y la capacidad disponible de los backends en cada zona y región. Por último, también se tiene en cuenta la carga y la capacidad mundiales.
El balanceador de carga de aplicación externo distribuye el tráfico en función de las instancias disponibles. Para añadir nuevas instancias en función de la carga, el algoritmo funciona junto con los grupos de instancias de autoescalado.
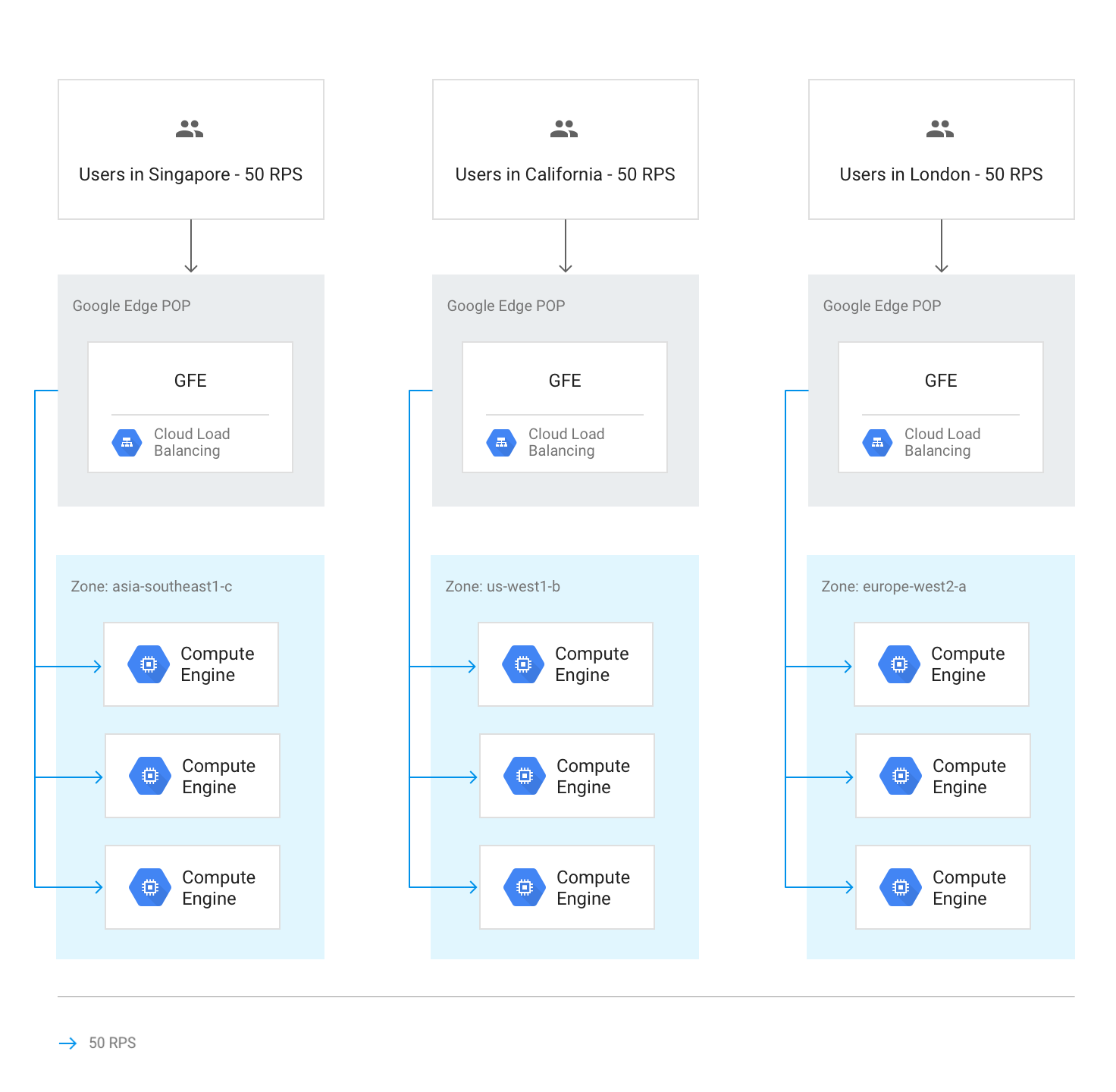
Flujo de tráfico dentro de una región
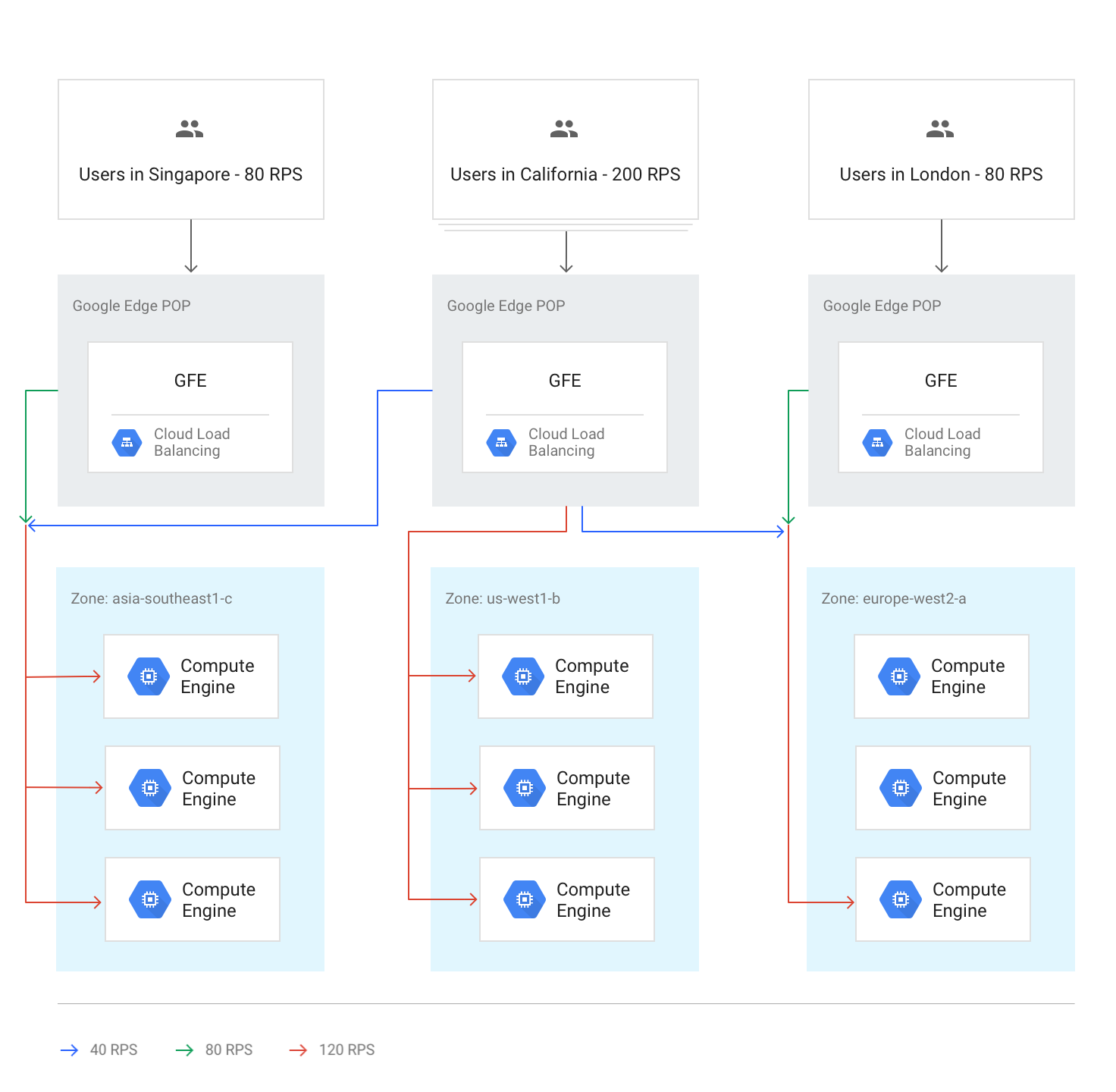
En circunstancias normales, todo el tráfico se envía a la región más cercana al usuario. El balanceo de carga se realiza de acuerdo con estas directrices:
En cada región, el tráfico se distribuye entre los grupos de instancias, que pueden estar en varias zonas según la capacidad de cada grupo.
Si la capacidad de las zonas es desigual, las zonas se cargan en proporción a su capacidad de servicio disponible.
Dentro de las zonas, las solicitudes se distribuyen de forma uniforme entre las instancias de cada grupo de instancias.
Las sesiones se conservan en función de la dirección IP del cliente o de un valor de cookie, según el ajuste de afinidad de sesión.
A menos que el backend deje de estar disponible, las conexiones TCP existentes nunca se transfieren a otro backend.
En el siguiente diagrama se muestra la distribución de la carga en este caso, en el que cada región tiene capacidad suficiente y puede gestionar la carga de los usuarios más cercanos a esa región.
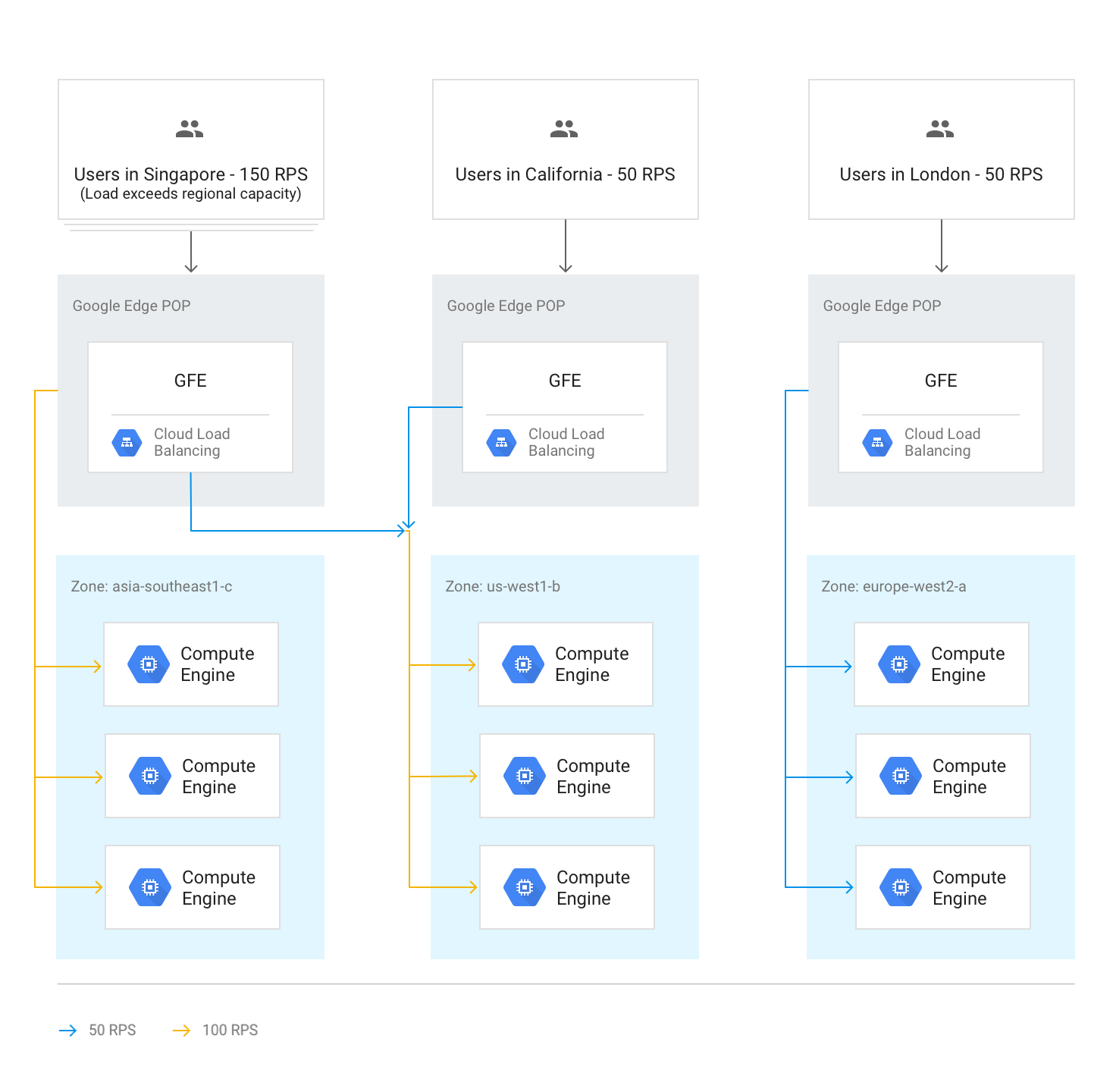
Traslado de tráfico a otras regiones
Si una región entera alcanza la capacidad determinada por la capacidad de servicio definida en los servicios backend, se activa el algoritmo de cascada por región y el tráfico se desvía a la región más cercana que tenga capacidad disponible. Cuando una región alcanza su capacidad, el tráfico se deriva a la siguiente región más cercana, y así sucesivamente. La proximidad de una región al usuario se define mediante el tiempo de ida y vuelta de la red desde el GFE hasta los back-ends de la instancia.
En el siguiente diagrama se muestra el desbordamiento a la región más cercana cuando una región recibe más tráfico del que puede gestionar a nivel regional.
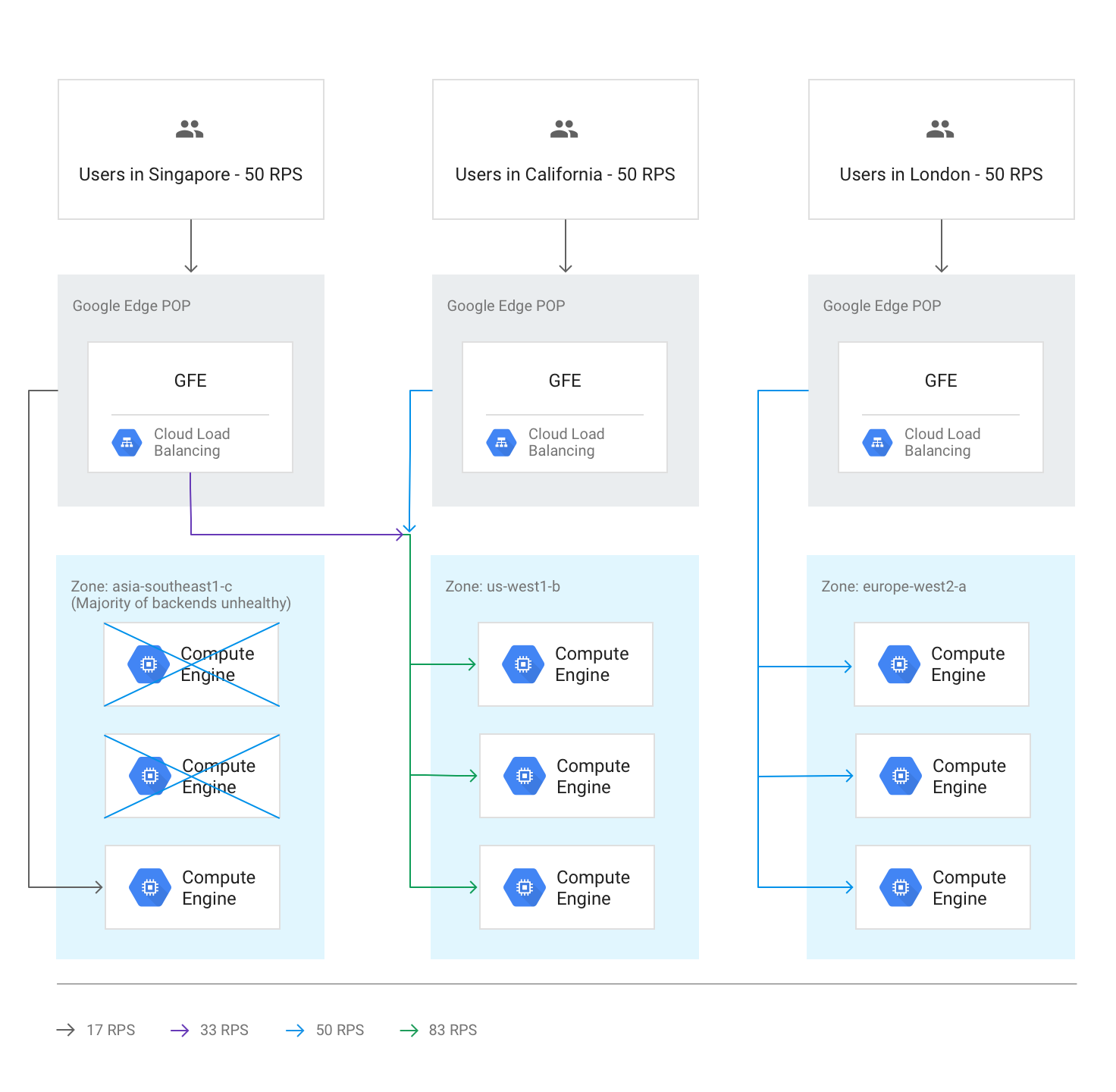
Desbordamiento entre regiones debido a backends en mal estado
Si las comprobaciones del estado detectan que más de la mitad de los backends de una región no están en buen estado, los GFEs desvían de forma preventiva parte del tráfico a la región más cercana. Esto ocurre para evitar que el tráfico falle por completo cuando la región no esté en buen estado. Este desbordamiento se produce aunque la capacidad restante de la región con los back-ends incorrectos sea suficiente.
En el siguiente diagrama se muestra el mecanismo de desbordamiento en funcionamiento, ya que la mayoría de los back-ends de una zona no están en buen estado.
Todas las regiones con capacidad superior
Cuando el tráfico a todas las regiones alcanza o supera la capacidad, se equilibra para que todas las regiones tengan el mismo nivel relativo de desbordamiento en comparación con su capacidad. Por ejemplo, si la demanda global supera la capacidad global en un 20%, el tráfico se distribuye de forma que todas las regiones reciban solicitudes con un 20% más de su capacidad regional, al tiempo que se mantiene el tráfico lo más local posible.
En el siguiente diagrama se muestra esta regla de desbordamiento global en funcionamiento. En este caso, una sola región recibe tanto tráfico que no se puede distribuir en absoluto con la capacidad de servicio disponible a nivel mundial.
Desbordamiento temporal durante el autoescalado
El autoescalado se basa en los límites de capacidad configurados en cada servicio de backend y crea nuevas instancias cuando el tráfico se acerca a los límites de capacidad configurados. En función de la rapidez con la que aumenten los niveles de solicitudes y de la velocidad con la que se pongan en línea las nuevas instancias, puede que no sea necesario derivar el tráfico a otras regiones. En otros casos, el desbordamiento puede actuar como un búfer temporal hasta que las nuevas instancias locales estén online y listas para atender el tráfico en tiempo real. Cuando la capacidad ampliada por el escalado automático es suficiente, todas las sesiones nuevas se distribuyen a la región más cercana.
Efectos de latencia del desbordamiento
Según el algoritmo de cascada por región, puede producirse un desbordamiento de parte del tráfico por parte del balanceador de carga de aplicación externo a otras regiones. Sin embargo, las sesiones TCP y el tráfico SSL siguen finalizando en el GFE más cercano al usuario. Esto es beneficioso para la latencia de las aplicaciones. Para obtener más información, consulta el artículo Optimizar la latencia de las aplicaciones mediante el balanceo de carga.
Práctica: medir los efectos de la gestión de la capacidad
Para saber cómo se produce el desbordamiento y cómo puedes gestionarlo con el balanceador de carga HTTP, consulta el tutorial Gestión de la capacidad con balanceo de carga que acompaña a este artículo.
Usar un balanceador de carga de aplicación externo para solucionar problemas de capacidad
Para hacer frente a los problemas que hemos comentado anteriormente, los balanceadores de carga de aplicaciones externos y los balanceadores de carga de red de proxy externos pueden desbordar la capacidad a otras regiones. En el caso de las aplicaciones globales, responder a los usuarios con una latencia general ligeramente superior ofrece una mejor experiencia que usar un backend regional. Las aplicaciones que usan un backend regional tienen una latencia nominalmente más baja, pero pueden sobrecargarse.
Vamos a repasar cómo puede ayudar un balanceador de carga de aplicación externo a abordar las situaciones que se han mencionado al principio del artículo:
Latencia al iniciar nuevas instancias. Si el escalador automático no puede añadir capacidad lo suficientemente rápido durante los picos de tráfico local, el balanceador de carga de aplicación externo desbordará temporalmente las conexiones a la región más cercana. De esta forma, las sesiones de usuario de la región original se gestionan a una velocidad óptima, ya que permanecen en los back-ends actuales, mientras que las nuevas sesiones de usuario solo experimentan un ligero aumento de la latencia. En cuanto se amplían las instancias de backend adicionales en la región original, el tráfico nuevo se vuelve a dirigir a la región más cercana a los usuarios.
Aplicaciones limitadas por la capacidad del backend. Las aplicaciones que no se pueden escalar automáticamente, pero que están disponibles en varias regiones, pueden seguir desbordándose a la región más cercana cuando la demanda de una región supere la capacidad implementada para las necesidades de tráfico habituales.
Licencias no elásticas. Si el número de licencias de software es limitado y el grupo de licencias de la región actual se ha agotado, el balanceador de carga de aplicaciones externo puede mover el tráfico a una región en la que haya licencias disponibles. Para que esto funcione, el número máximo de instancias se establece en el número máximo de licencias del escalador automático.
Espacio libre de VM demasiado pequeño. La posibilidad de que se produzca un desbordamiento regional ayuda a ahorrar dinero, ya que puedes configurar el escalado automático con un activador de uso elevado de la CPU. También puede configurar la capacidad de backend disponible debajo de cada pico regional, ya que el desbordamiento a otras regiones asegura que la capacidad global siempre sea suficiente.
Cuotas regionales. Si las cuotas de recursos de Compute Engine no se ajustan a la demanda, el desbordamiento del balanceador de carga de aplicaciones externo redirige automáticamente parte del tráfico a una región que aún puede escalar dentro de su cuota regional.
Siguientes pasos
En las siguientes páginas se ofrece más información sobre las opciones de balanceo de carga de Google:
- Tutorial sobre la gestión de la capacidad con balanceo de carga
- Optimizar la latencia de las aplicaciones mediante el balanceo de carga
- Codelab de redes para principiantes
- Balanceador de carga de red de paso a través externo
- Balanceador de carga de aplicación externo
- Balanceador de carga de red de proxy externo