ID regione
REGION_ID è un codice abbreviato assegnato da Google in base alla regione selezionata quando crei l'app. Il codice non corrisponde a un paese o a una provincia, anche se alcuni ID regione possono sembrare simili ai codici di paesi e province di uso comune. Per le app create dopo febbraio 2020, REGION_ID.r è incluso negli URL di App Engine. Per le app esistenti create prima di questa data, l'ID regione è facoltativo nell'URL.
Scopri di più sugli ID regione.
Lo sviluppo software è incentrato sui compromessi e i microservizi non fanno eccezione. Ciò che guadagni in termini di implementazione del codice e indipendenza operativa, lo paghi in termini di overhead delle prestazioni. Questa sezione fornisce alcuni consigli su come minimizzare questo impatto.
Trasforma le operazioni CRUD in microservizi
I microservizi sono particolarmente adatti alle entità a cui si accede con il pattern create, retrieve, update, delete (CRUD). Quando lavori con queste entità, in genere ne utilizzi una alla volta, ad esempio un utente, e in genere esegui una sola delle azioni CRUD alla volta. Pertanto, è necessaria una sola chiamata al microservizio per l'operazione. Cerca entità con operazioni CRUD, oltre a un insieme di metodi aziendali che potrebbero essere utilizzati in molte parti dell'applicazione. Queste entità sono ottime candidate per i microservizi.
Fornire API batch
Oltre alle API in stile CRUD, puoi comunque offrire buone prestazioni dei microservizi per gruppi di entità fornendo API batch. Ad esempio, anziché esporre solo un metodo API GET che recupera un singolo utente, fornisci un'API che prende un insieme di ID utente e restituisce un dizionario di utenti corrispondenti:
Richiesta:
/user-service/v1/?userId=ABC123&userId=DEF456&userId=GHI789Risposta:
{
"ABC123": {
"userId": "ABC123",
"firstName": "Jake",
… },
"DEF456": {
"userId": "DEF456",
"firstName": "Sue",
… },
"GHI789": {
"userId": "GHI789",
"firstName": "Ted",
… }
}
L'SDK App Engine supporta molte API batch, ad esempio la possibilità di recuperare molte entità da Cloud Datastore tramite una singola RPC, pertanto la gestione di questi tipi di API batch può essere molto efficiente.
Utilizzare le richieste asincrone
Spesso, per comporre una risposta, dovrai interagire con molti microservizi.
Ad esempio, potresti dover recuperare le preferenze dell'utente che ha eseguito l'accesso, nonché i dettagli della sua azienda. Spesso queste informazioni non dipendono l'una dall'altra e puoi recuperarle in parallelo. La libreria Urlfetch nell'SDK App Engine supporta le richieste asincrone, consentendoti di chiamare i microservizi in parallelo.
from google.appengine.api import urlfetch
preferences_rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(preferences_rpc,
'https://preferences-service-dot-my-app.uc.r.appspot.com/preferences-service/v1/?userId=ABC123')
company_rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(company_rpc,
'https://company-service-dot-my-app.uc.r.appspot.com/company-service/v3/?companyId=ACME')
### microservice requests are now occurring in parallel
try:
preferences_response = preferences_rpc.get_result() # blocks until response
if preferences_response.status_code == 200:
# deserialize JSON, or whatever is appropriate
else:
# handle error
except urlfetch.DownloadError:
# timeout, or other transient error
try:
company_response = company_rpc.get_result() # blocks until response
if company_response.status_code == 200:
# deserialize JSON, or whatever is appropriate
else:
# handle error
except urlfetch.DownloadError:
# timeout, or other transient error
Lavorare in parallelo spesso è in contrasto con una buona struttura del codice perché, in uno scenario reale, spesso utilizzi una classe per incapsulare i metodi delle preferenze e un'altra per incapsulare i metodi dell'azienda. È difficile sfruttare
le chiamate Urlfetch asincrone senza rompere questa incapsulamento. Esiste una buona soluzione nel pacchetto NDB dell'SDK Python di App Engine: i tasklet.
I tasklet ti consentono di mantenere una buona incapsulazione nel codice, offrendo al contempo un meccanismo per eseguire chiamate di microservizi in parallelo. Tieni presente che i tasklet utilizzano
future anziché RPC, ma l'idea è simile.
Utilizza il percorso più breve
A seconda di come richiami Urlfetch, puoi utilizzare infrastrutture e percorsi diversi. Per utilizzare il percorso con il rendimento migliore, tieni conto dei seguenti consigli:
- Utilizza
REGION_ID.r.appspot.com, non un dominio personalizzato - Un dominio personalizzato fa sì che venga utilizzato un percorso diverso per il routing nell'infrastruttura Google. Poiché le chiamate ai microservizi sono interne, è facile da eseguire e ha un rendimento migliore se utilizzi
https://PROJECT_ID.REGION_ID.r.appspot.com. - Imposta
follow_redirectssuFalse - Imposta esplicitamente
follow_redirects=Falsequando chiamiUrlfetch, in quanto evita un servizio più pesante progettato per seguire i reindirizzamenti. Gli endpoint API non dovrebbero dover reindirizzare i client, perché sono i tuoi microservizi e gli endpoint dovrebbero restituire solo risposte HTTP della serie 200, 400 e 500. - Preferisci i servizi all'interno di un progetto rispetto a più progetti
- Esistono buoni motivi per utilizzare più progetti durante la creazione di un'applicazione basata su microservizi, ma se il tuo obiettivo principale è il rendimento, utilizza i servizi all'interno di un singolo progetto. I servizi di un progetto sono ospitati nello stesso data center e, anche se il throughput sulla rete inter-data center di Google è eccellente, le chiamate locali sono più veloci.
Evitare chiacchiere durante l'applicazione della sicurezza
L'utilizzo di meccanismi di sicurezza che richiedono molte comunicazioni avanti e indietro per autenticare l'API chiamante è dannoso per il rendimento. Ad esempio, se il tuo microservice deve convalidare un ticket dalla tua applicazione richiamando nuovamente l'applicazione, hai generato una serie di viaggi di andata e ritorno per recuperare i dati.
Un'implementazione OAuth2 può ammortizzare questo costo nel tempo utilizzando i token di aggiornamento e memorizzando nella cache un token di accesso tra le invocazioni di Urlfetch. Tuttavia, se il token di accesso memorizzato nella cache è archiviato in memcache, dovrai sostenere il sovraccarico di memcache per recuperarlo. Per evitare questo overhead, puoi memorizzare nella cache il token di accesso
nella memoria dell'istanza, ma l'attività OAuth2 verrà comunque eseguita frequentemente, poiché ogni nuova istanza negozia un token di accesso. Ricorda che le istanze App Engine vengono avviate e interrotte di frequente. Un ibrido di memcache e cache delle istanze contribuirà ad attenuare il problema, ma la soluzione inizierà a diventare più complessa.
Un altro approccio che offre buoni risultati è condividere un token segreto tra i microservizi, ad esempio trasmesso come intestazione HTTP personalizzata. In questo approccio, ogni microservizio potrebbe avere un token univoco per ogni chiamante. In genere, i secret condivisi sono una scelta discutibile per le implementazioni di sicurezza, ma poiché tutti i microservizi si trovano nella stessa applicazione, il problema diventa meno grave, dati i vantaggi in termini di prestazioni. Con un secret condiviso, il microservizio deve solo eseguire un confronto di stringhe del secret in entrata con un dizionario presumibilmente in memoria e l'applicazione della sicurezza è molto leggera.
Se tutti i tuoi microservizi sono su App Engine, puoi anche ispezionare l'intestazione X-Appengine-Inbound-Appid in entrata.
Questa intestazione viene aggiunta dall'infrastruttura Urlfetch quando viene effettuata una richiesta a un altro progetto App Engine e non può essere impostata da terze parti. A seconda del tuo requisito di sicurezza, i microservizi potrebbero ispezionare questo intestazione in entrata per applicare i tuoi criteri di sicurezza.
Traccia le richieste dei microservizi
Man mano che crei l'applicazione basata su microservizi, inizi ad accumulare il sovraccarico delle chiamate Urlfetch successive. In questi casi, puoi utilizzare
Cloud Trace
per capire quali chiamate vengono fatte
e dove si trova il sovraccarico. È importante sottolineare che Cloud Trace può anche aiutarti a identificare
dove vengono invocati in sequenza microservizi indipendenti, in modo da poter
eseguire il refactoring del codice per eseguire questi recuperi in parallelo.
Una funzionalità utile di Cloud Trace viene attivata quando utilizzi più servizi all'interno di un singolo progetto. Quando le chiamate vengono effettuate tra i servizi di microservizi nel tuo progetto, Cloud Trace le raggruppa in un unico grafico delle chiamate per consentirti di visualizzare l'intera richiesta end-to-end come una singola traccia.
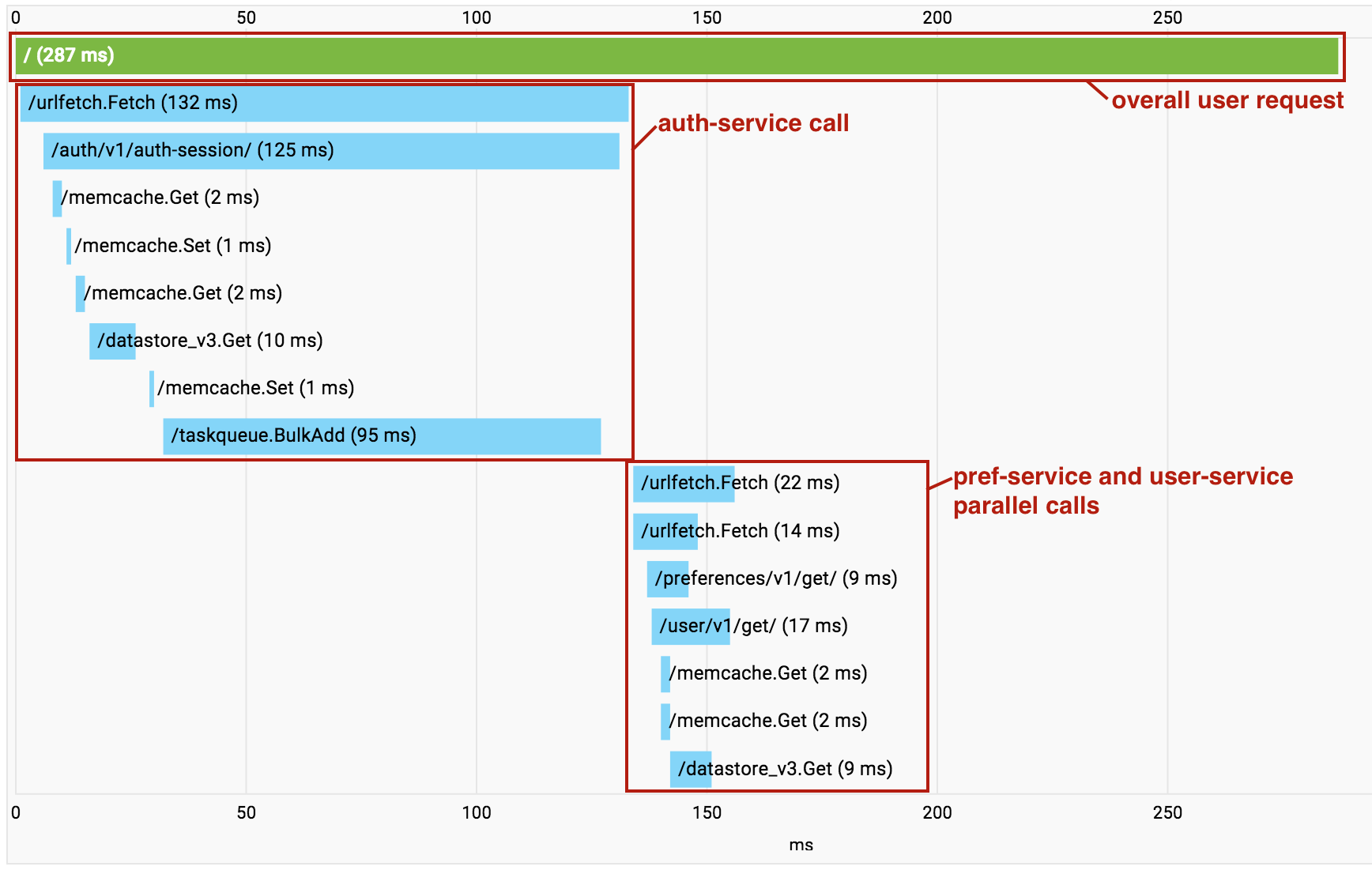
Tieni presente che nell'esempio precedente le chiamate a pref-service e user-service vengono eseguite in parallelo utilizzando un Urlfetch asincrono, pertanto le RPC appaiono confuse nella visualizzazione.
Tuttavia, rimane uno strumento prezioso per diagnosticare la latenza.
Passaggi successivi
- Consulta una panoramica dell'architettura dei microservizi su App Engine.
- Scopri come creare e assegnare un nome agli ambienti di sviluppo, test, QA, temporaneo e di produzione con microservizi in App Engine.
- Scopri le best practice per progettare API per la comunicazione tra microservizi.
- Scopri come eseguire la migrazione di un'applicazione monolitica esistente a un'applicazione con microservizi.