Esta é a documentação da Apigee e da Apigee híbrida.
Confira a documentação da Apigee Edge.
A política RaiseFault permite que os desenvolvedores de API iniciem um fluxo de erro, definam variáveis de erro
em uma mensagem de corpo de resposta e definam códigos de status de resposta apropriados. Também é possível usar a política RaiseFault
para definir variáveis de fluxo pertencentes à falha, como fault.name, fault.type
e fault.category. Como essas variáveis são visíveis em dados de análise e registros de acesso de roteador
usados para depuração, é importante identificar com precisão a falha.
Você pode usar a política RaiseFault para tratar condições específicas como erros, mesmo que um erro real
não tenha ocorrido em outra política ou no servidor de back-end do proxy de API. Por exemplo, se quiser
que o proxy envie uma mensagem de erro personalizada para o app cliente sempre que o corpo da
resposta de back-end contiver a string unavailable, invoque a política RaiseFault, conforme
mostrado em o snippet de código abaixo:
<!-- /antipatterns/examples/raise-fault-conditions-1.xml --> <TargetEndpoint name="default"> ... <Response> <Step> <Name>RF-Service-Unavailable</Name> <Condition>(message.content Like "*unavailable*")</Condition> </Step> </Response> ...
O nome da política RaiseFault está visível como fault.name no
Monitoramento de APIs e como x_apigee_fault_policy nos registros de acesso do Google Analytics e do roteador.
Isso ajuda a diagnosticar a causa do erro com facilidade.
Antipadrão
Como usar a política RaiseFault em FaultRules após outra política já ter gerado um erro
Considere o exemplo abaixo, em que uma política do OAuthV2 no fluxo do proxy de API falhou com um erro
InvalidAccessToken. Em caso de falha, a Apigee definirá fault.name como InvalidAccessToken, entrará no
fluxo de erros e executará quaisquer FaultRules definidas. Na FaultRule, há uma política RaiseFault, chamada
RaiseFault, que envia uma resposta de erro personalizada sempre que um erro InvalidAccessToken
ocorre. No entanto, o uso da política RaiseFault em uma FaultRule significa que a variável fault.name
é substituída e mascara a causa verdadeira da falha.
<!-- /antipatterns/examples/raise-fault-conditions-2.xml --> <FaultRules> <FaultRule name="generic_raisefault"> <Step> <Name>RaiseFault</Name> <Condition>(fault.name equals "invalid_access_token") or (fault.name equals "InvalidAccessToken")</Condition> </Step> </FaultRule> </FaultRules>
Como usar a política RaiseFault em uma FaultRule em todas as condições
No exemplo abaixo, uma política RaiseFault chamada RaiseFault será executada se fault.name
não for RaiseFault:
<!-- /antipatterns/examples/raise-fault-conditions-3.xml --> <FaultRules> <FaultRule name="fault_rule"> .... <Step> <Name>RaiseFault</Name> <Condition>!(fault.name equals "RaiseFault")</Condition> </Step> </FaultRule> </FaultRules>
Como no primeiro cenário, as variáveis de falha de chave fault.name,
fault.code e fault.policy são substituídas pelo nome da política RaiseFault. Esse comportamento torna
quase impossível determinar qual política realmente causou a falha sem acessar um arquivo de
rastreamento que mostra a falha ou reproduza o problema.
Como usar a política RaiseFault para retornar uma resposta HTTP 2xx fora do fluxo de erro.
No exemplo abaixo, uma política RaiseFault chamada HandleOptionsRequest é executada quando
o verbo da solicitação é OPTIONS:
<!-- /antipatterns/examples/raise-fault-conditions-4.xml --> <PreFlow name="PreFlow"> <Request> … <Step> <Name>HandleOptionsRequest</Name> <Condition>(request.verb Equals "OPTIONS")</Condition> </Step> … </PreFlow>
A intenção é retornar a resposta ao cliente da API imediatamente, sem processar outras políticas. No entanto, isso resultará em dados de análise incorretos, porque as variáveis de falha incluirão o nome da política RaiseFault, o que dificulta a depuração do proxy. A maneira correta de implementar o comportamento desejado é usar fluxos com condições especiais, conforme descrito em Como adicionar compatibilidade com CORS.
Impacto
O uso da política RaiseFault, conforme descrito acima, resulta na substituição de variáveis de falha importantes pelo
nome da política RaiseFault, em vez do nome da política com falha. Nos registros de acesso do Google Analytics e do NGINX,
as variáveis x_apigee_fault_code e x_apigee_fault_policy
são substituídas. No monitoramento da API, Fault Code
e Fault Policy são substituídos. Esse comportamento dificulta a solução de problemas e
determina qual política é a verdadeira causa da falha.
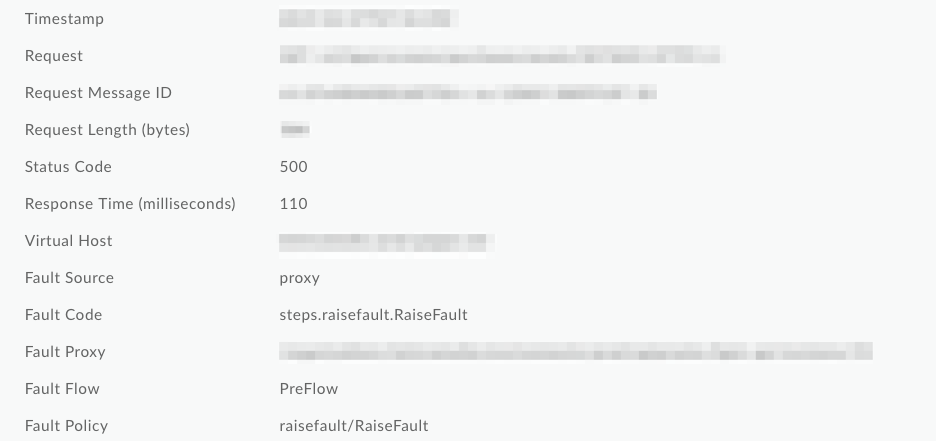
Na captura de tela abaixo, em Monitoramento de APIs,
é possível ver que a política de falha e a política de falha foram substituídas por valores RaiseFault
genéricos, o que impossibilita determinar a causa principal do falha dos registros:
Prática recomendada
Quando uma política da Apigee gerar uma falha e você quiser personalizar a mensagem de resposta de erro, use as políticas AssignMessage ou JavaScript em vez da política RaiseFault.
A política RaiseFault precisa ser usada em um fluxo sem erro. Ou seja, só use RaiseFault para tratar uma condição específica como erro, mesmo que um erro real não tenha ocorrido em uma política ou no servidor de back-end do proxy de API. Por exemplo, você pode usar a política RaiseFault para sinalizar que os parâmetros de entrada obrigatórios estão ausentes ou têm sintaxe incorreta.
Você também pode usar RaisFault em uma regra de falha se quiser detectar um erro durante o processamento de uma falha. Por exemplo, o próprio gerenciador de falhas pode causar um erro que você quer sinalizar usando RaiseFault.
Leitura adicional
- Como lidar com falhas
- Política RaiseFault
- Discussão da comunidade sobre padrões de tratamento de falhas