Auf dieser Seite werden die Hochverfügbarkeitsoptionen in Google Distributed Cloud beschrieben.
Hauptfunktion
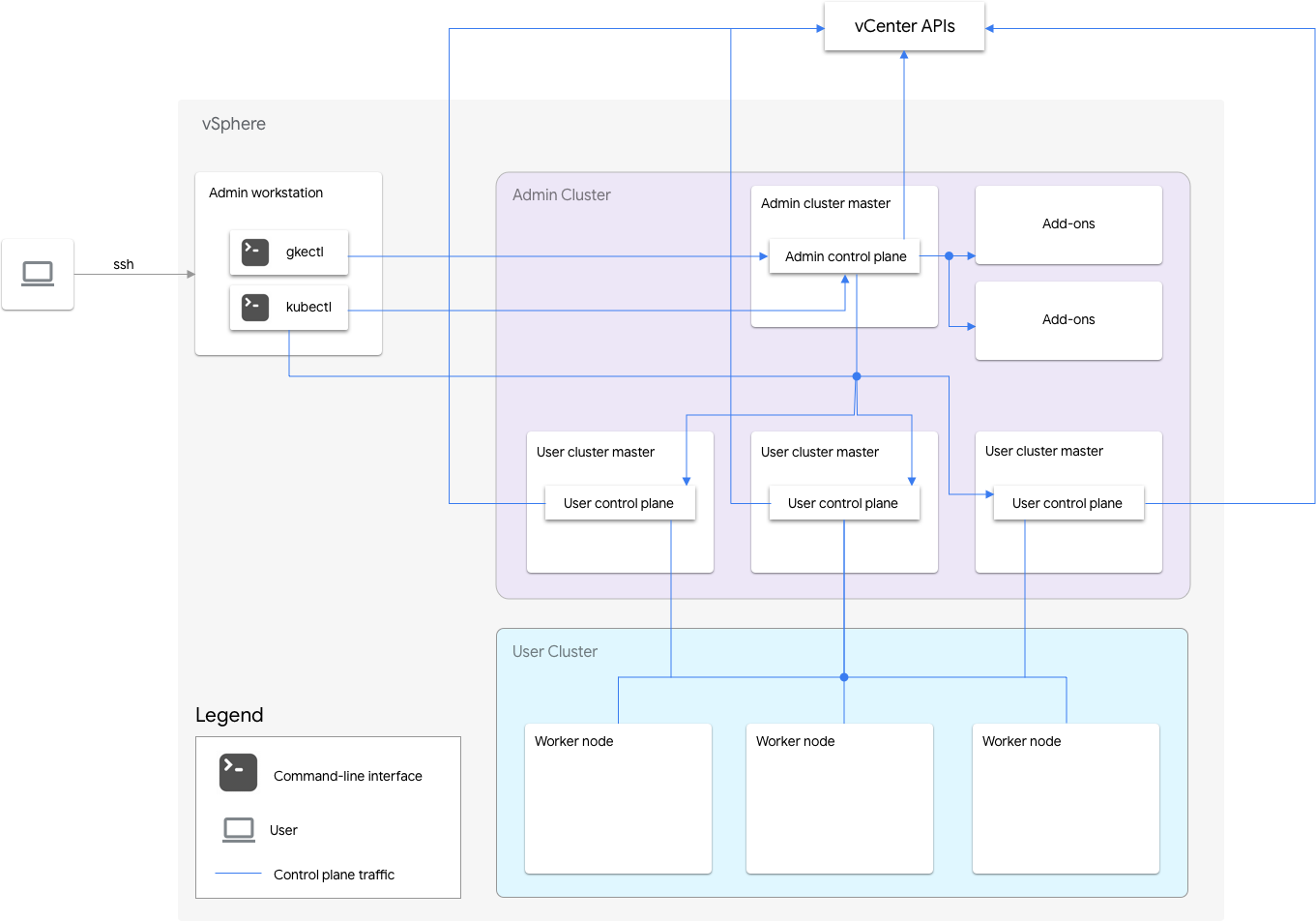
GKE on VMware enthält einen Administratorcluster und einen oder mehrere Nutzercluster.
Der Administratorcluster verwaltet den Lebenszyklus der Nutzercluster, einschließlich Erstellen, Aktualisieren, Upgrade und Löschen von Nutzerclustern. Im Administratorcluster verwaltet der Admin-Master die Admin-Worker-Knoten, zu denen Nutzer-Master (Knoten, auf denen die Steuerebene der verwalteten Nutzercluster läuft) und Add-on-Knoten (Knoten, auf denen die Add-on-Komponenten zur Unterstützung der Funktionalität des Administratorcluster laufen) gehören.
Für jeden Nutzercluster hat der Administratorcluster einen Nicht-HA-Knoten oder drei HA-Knoten, auf denen die Steuerungsebene ausgeführt wird. Die Steuerungsebene umfasst den Kubernetes API-Server, den Kubernetes-Planer, den Kubernetes-Controller-Manager und mehrere wichtige Controller für den Nutzercluster.
Die Verfügbarkeit der Steuerungsebene des Nutzerclusters ist für Arbeitslastvorgänge wichtig, wie das Erstellen von Arbeitslasten, das Hoch- und Herunterskalieren sowie das Abbrechen. Anders ausgedrückt: Ein Ausfall der Steuerungsebene beeinträchtigt nicht die ausgeführten Arbeitslasten. Die vorhandenen Arbeitslasten verlieren jedoch die Verwaltungsfunktionen des Kubernetes API-Servers, wenn keine Steuerungsebene vorhanden ist.
Containerisierte Arbeitslasten und Dienste werden in den Worker-Knoten des Nutzerclusters bereitgestellt. Einzelne Worker-Knoten sollten nicht für die Anwendungsverfügbarkeit entscheidend sein, solange die Anwendung mit redundanten Pods bereitgestellt wird, die auf mehreren Worker-Knoten geplant sind.
Hochverfügbarkeit aktivieren
vSphere und Google Distributed Cloud bieten eine Reihe von Features, die zu Hochverfügbarkeit (High Availability, HA) beitragen.
vSphere HA und vMotion
Wir empfehlen, die folgenden beiden Features im vCenter-Cluster zu aktivieren, der Ihre Google Distributed Cloud-Cluster hostet:
Diese Funktionen verbessern die Verfügbarkeit und Wiederherstellung, wenn ein ESXi-Host ausfällt.
vCenter HA verwendet mehrere ESXi-Hosts, die als Cluster konfiguriert sind, um eine schnelle Wiederherstellung nach Ausfällen und eine kostengünstige HA für Anwendungen zu ermöglichen, die in virtuellen Maschinen ausgeführt werden. Es wird empfohlen, den vCenter-Cluster mit zusätzlichen Hosts bereitzustellen und das vSphere-HA-Host-Monitoring zu aktivieren, wobei Host Failure Response auf Restart VMs gesetzt ist. Ihre VMs können dann bei einem ESXi-Hostfehler automatisch auf anderen verfügbaren Hosts neu gestartet werden.
vMotion ermöglicht eine reibungslose Migration von VMs von einem ESXi-Host zu einem anderen. Für die geplante Hostwartung können Sie mit der Live-Migration von vMotion die Anwendungsausfallzeiten vermeiden und Geschäftskontinuität gewährleisten.
Administratorcluster
Google Distributed Cloud unterstützt das Erstellen von Hochverfügbarkeits-Administratorclustern. Ein Hochverfügbarkeitsadministratorcluster hat drei Knoten, auf denen Komponenten der Steuerungsebene ausgeführt werden. Informationen zu Anforderungen und Einschränkungen finden Sie unter Administratorcluster mit hoher Verfügbarkeit.
Die Nichtverfügbarkeit der Steuerungsebene des Administratorclusters hat keine Auswirkungen auf die Funktionalität vorhandener Nutzercluster oder auf Arbeitslasten, die in Nutzerclustern ausgeführt werden.
In einem Administratorcluster gibt es zwei Add-on-Knoten. Wenn dieser ausfällt, kann der andere die Administratorclustervorgänge ausführen. Aus Gründen der Redundanz verteilt Google Distributed Cloud kritische Add-on-Dienste wie kube-dns auf beide Add-on-Knoten.
Wenn Sie antiAffinityGroups.enabled in der Konfigurationsdatei des Administratorclusters auf true setzen, erstellt Google Distributed Cloud automatisch vSphere DRS-Anti-Affinitätsregeln für die Add-on-Knoten. Dadurch werden sie für Hochverfügbarkeit auf zwei physische Hosts verteilt.
Nutzercluster
Sie können HA für einen Nutzercluster aktivieren, indem Sie masterNode.replicas in der Nutzercluster-Konfigurationsdatei auf 3 setzen. Wenn für den Nutzercluster die Steuerungsebene V2 aktiviert ist (empfohlen), werden die drei Knoten der Steuerungsebene im Nutzercluster ausgeführt.
Legacy-HA-kubeception-Nutzercluster führen die drei Knoten der Steuerungsebene im Administratorcluster aus. Jeder Knoten der Steuerungsebene führt auch ein etcd-Replikat aus. Der Nutzercluster funktioniert weiterhin, solange eine Steuerungsebene und ein etcd-Quorum ausgeführt wird. Für ein etcd Quorum müssen zwei der etcd-Replikate funktionieren.
Wenn Sie antiAffinityGroups.enabled in der Konfigurationsdatei des Administratorclusters auf true festlegen, erstellt Google Distributed Cloud automatisch vSphere DRS-Anti-Affinitätsregeln für die drei Knoten, auf denen die Steuerungsebene des Nutzerclusters ausgeführt wird.
Dadurch werden diese VMs auf drei physische Hosts verteilt.
Google Distributed Cloud erstellt außerdem vSphere DRS-Anti-Affinitätsregeln für die Worker-Knoten in Ihrem Nutzercluster. Dadurch werden diese Knoten auf mindestens drei physische Hosts verteilt. Mehrere DRS-Anti-Affinitätsregeln werden pro Nutzercluster-Knotenpool basierend auf der Anzahl der Knoten verwendet. Dadurch wird sichergestellt, dass die Worker-Knoten Hosts zum Ausführen finden können, auch wenn die Anzahl der Hosts geringer als die Anzahl der VMs im Knotenpool des Nutzerclusters ist. Wir empfehlen, zusätzliche physische Hosts in Ihren vCenter-Cluster aufzunehmen. Konfigurieren Sie DRS auch so, dass er vollständig automatisiert ist. Wenn ein Host nicht mehr verfügbar ist, kann DRS VMs auf anderen verfügbaren Hosts automatisch neu starten, ohne die Anti-Affinitätsregeln der VMs zu verletzen.
Google Distributed Cloud hat ein spezielles Knotenlabel, onprem.gke.io/failure-domain-name, dessen Wert auf den zugrunde liegenden ESXi-Hostnamen gesetzt wird. Nutzeranwendungen, die Hochverfügbarkeit gewährleisten möchten, können podAntiAffinity-Regeln mit diesem Label als topologyKey einrichten, um sicherzustellen, dass ihre Anwendungs-Pods über verschiedene VMs sowie physische Hosts verteilt werden.
Sie können auch mehrere Knotenpools für einen Nutzercluster mit unterschiedlichen Datenspeichern und speziellen Knotenlabels konfigurieren. Ebenso können Sie Regeln vom Typ podAntiAffinity mit diesem speziellen Knotenlabel als topologyKey einrichten, um eine höhere Verfügbarkeit bei Datenspeicherfehlern zu erreichen.
Um HA für Nutzerarbeitslasten zu verwenden, muss der Nutzercluster eine ausreichende Anzahl von Replikaten unter nodePools.replicas haben, wodurch sichergestellt wird, dass die gewünschte Anzahl von Nutzercluster-Worker-Knoten in ausführbarem Zustand sind.
Sie können für Admincluster und Nutzercluster separate Datenspeicher verwenden, um deren Fehler zu isolieren.
Load-Balancer
Es gibt zwei Arten von Load-Balancern, die Sie für Hochverfügbarkeit verwenden können.
Gebündelter MetalLB-Load-Balancer
Für den gebündelten MetalLB-Load-Balancer erreichen Sie Hochverfügbarkeit, indem Sie mehr als einen Knoten mit enableLoadBalancer: true haben.
MetalLB verteilt Dienste auf die Load-Balancer-Knoten. Für einen einzelnen Dienst gibt es jedoch nur einen Leader-Knoten, der den gesamten Traffic für diesen Dienst verarbeitet.
Während des Clusterupgrades kommt es zu einer Ausfallzeit, wenn die Load-Balancer-Knoten aktualisiert werden. Die Dauer der Failover-Unterbrechung des MetalLB nimmt mit der Anzahl der Load-Balancer-Knoten zu. Bei weniger als 5 Knoten erfolgt die Störung innerhalb von 10 Sekunden.
Gebündelter Seesaw-Load-Balancer
Für den Bundle-Seesaw-Load-Balancer können Sie HA aktivieren, indem Sie loadBalancer.seesaw.enableHA in der Cluster-Konfigurationsdatei auf true setzen.
Sie müssen auch eine Kombination aus MAC-Lernen, gefälschten Übertragungen und promiscous-Modus in Ihrer Load-Balancer-Portgruppe aktivieren.
Bei HA werden zwei Load-Balancer im Aktiv-Passiv-Modus eingerichtet. Wenn der aktive Load-Balancer ein Problem hat, schlägt der Traffic auf den passiven Load-Balancer um.
Während des Upgrades eines Load-Balancers kommt es zu Ausfallzeiten. Wenn für den Load-Balancer Hochverfügbarkeit aktiviert ist, beträgt die maximale Ausfallzeit zwei Sekunden.
Integrierter F5-BIG-IP-Load-Balancer
Die F5 BIG-IP-Plattform bietet verschiedene Dienste, mit denen Sie die Sicherheit, Verfügbarkeit und Leistung Ihrer Anwendungen verbessern können. Für Google Distributed Cloud bietet BIG-IP externen Zugriff und L3/4-Load-Balancing-Dienste.
Weitere Informationen finden Sie unter BIG-IP-Hochverfügbarkeit.
Mehrere Cluster für die Notfallwiederherstellung verwenden
Die Bereitstellung von Anwendungen in mehreren Clustern auf mehreren vCenters oder GKE Enterprise-Plattformen kann für eine höhere globale Verfügbarkeit sorgen und den Umfang der Manipulation bei Ausfällen begrenzen.
Bei dieser Einrichtung wird der vorhandene GKE Enterprise-Cluster im sekundären Rechenzentrum für die Notfallwiederherstellung verwendet, anstatt einen neuen Cluster einzurichten. Das geht in der folgenden Zusammenfassung:
Erstellen Sie im sekundären Rechenzentrum einen weiteren Administratorcluster und einen weiteren Nutzercluster. In dieser Multi-Cluster-Architektur müssen Nutzer zwei Administratorcluster in jedem Rechenzentrum haben und jeder Administratorcluster einen Nutzercluster ausführen.
Der sekundäre Nutzercluster hat eine minimale Anzahl von Worker-Knoten (drei) und ist dabei ein Hot-Standby.
Anwendungsbereitstellungen können mithilfe von Config Sync auf den beiden vCenters repliziert werden. Es wird aber auch bevorzugt, eine vorhandene Anwendungs-DevOps-Toolchain (CI/CD, Spinnaker) zu verwenden.
Im Notfall kann der Nutzercluster auf die Anzahl der Knoten skaliert werden.
Außerdem ist ein DNS-Switchover erforderlich, um Traffic zwischen den Clustern an das sekundäre Rechenzentrum zu leiten.