本文档介绍了如何在虚拟机上解读 AlloyDB Omni 中的性能结果。本文档假定您熟悉 PostgreSQL。
当您在修改其他变量时绘制一段时间内的吞吐量图表时,通常会看到吞吐量会增加,直到达到资源耗尽的程度。
下图显示了典型的吞吐量扩缩图。随着客户端数量的增加,工作负载和吞吐量也会增加,直到所有资源耗尽。
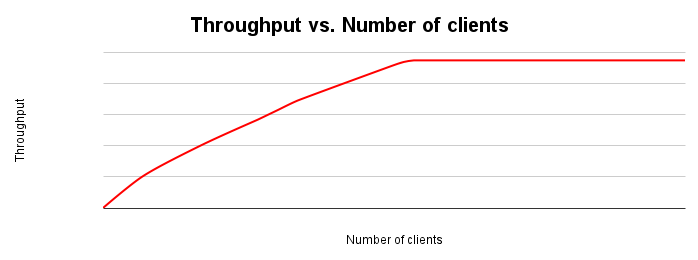
理想情况下,如果系统的负载翻倍,吞吐量也应翻倍。实际上,资源会出现争用,导致吞吐量增加幅度较小。在某个时间点,资源耗尽或争用将导致吞吐量趋于平稳甚至下降。如果您要针对吞吐量进行优化,则需要确定这一点,因为这有助于您确定在哪些方面调整应用或数据库系统以提高吞吐量。
吞吐量趋于稳定或下降的典型原因包括:
- 数据库服务器上的 CPU 资源耗尽
- 客户端上的 CPU 资源耗尽,因此无法向数据库服务器发送更多工作
- 数据库锁争用
- 当数据超出 Postgres 缓冲区大小时,I/O 等待时间
- 由于存储引擎利用率而导致的 I/O 等待时间
- 向客户端返回数据时出现网络带宽瓶颈
延迟时间和吞吐量成反比。延迟时间越长,吞吐量越低。直观上,这很有道理。随着瓶颈开始显现,操作开始需要更长时间,并且系统每秒执行的操作次数会减少。
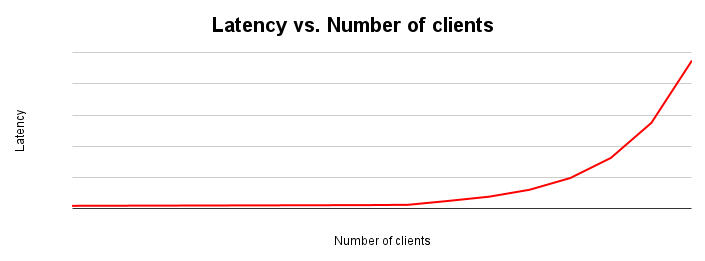
延迟时间缩放图表显示了随着系统负载增加,延迟时间的变化情况。在因资源争用而出现摩擦之前,延迟时间会保持相对不变。此曲线的拐点通常对应于吞吐量缩放图表中吞吐量曲线的趋于平缓。
评估延迟时间的另一种实用方法是使用直方图。在此表示法中,我们会将延迟时间划分到多个分桶中,并统计每个分桶中的请求数量。
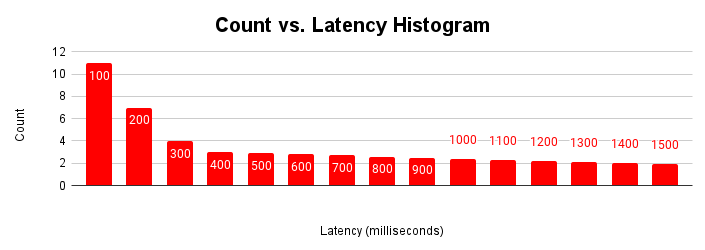
此延迟时间直方图显示,大多数请求的延迟时间都低于 100 毫秒,但也有延迟时间超过 100 毫秒的请求。了解延迟时间较长的请求的原因有助于解释所观察到的应用性能差异。延迟时间增加的长尾原因与典型延迟时间缩放图表中延迟时间增加的情况和吞吐量图表变平的情况相对应。
当应用中存在多种模态时,延迟时间直方图最有用。模态是一组正常的操作条件。例如,大多数情况下,应用会访问缓冲区缓存中的页面。大多数情况下,应用会更新现有行,但也可能存在多种模式。有时,应用会从存储空间检索页面、插入新行或遇到锁争用。
当应用在运行一段时间后遇到这些不同的操作模式时,延迟时间直方图会显示这些多种模式。
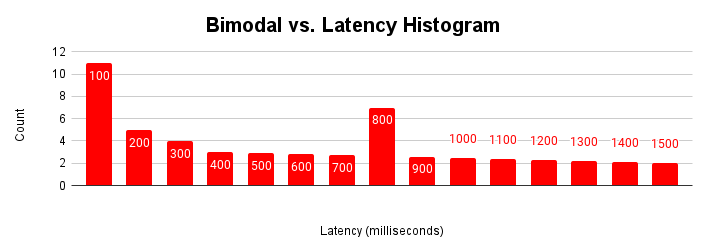
此图显示了典型的双峰直方图,其中大多数请求的服务时间不到 100 毫秒,但还有另一组请求的服务时间为 401-500 毫秒。了解第二种模式的原因有助于提升应用的性能。也可以有多个模态。
第二种模式可能是由正常的数据库操作、异构基础架构和拓扑或应用行为引起的。以下是一些示例:
- 大多数数据访问来自 PostgreSQL 缓冲区,但有些来自存储
- 某些客户端与数据库服务器之间的网络延迟时间存在差异
- 根据输入或时间执行不同操作的应用逻辑
- 间歇性锁争用
- 客户端活动激增