이 문서에서는 VM의 AlloyDB Omni에서 성능 결과를 해석하는 방법을 설명합니다. 이 문서에서는 사용자가 PostgreSQL에 익숙하다고 가정합니다.
다른 변수가 수정됨에 따라 시간 경과에 따른 처리량을 그래프로 표시하면 일반적으로 처리량이 리소스 소진 지점에 도달할 때까지 증가하는 것을 볼 수 있습니다.
다음 그림은 일반적인 처리량 확장 그래프를 보여줍니다. 클라이언트 수가 증가하면 워크로드와 처리량이 증가하여 모든 리소스가 소진될 때까지 계속 증가합니다.
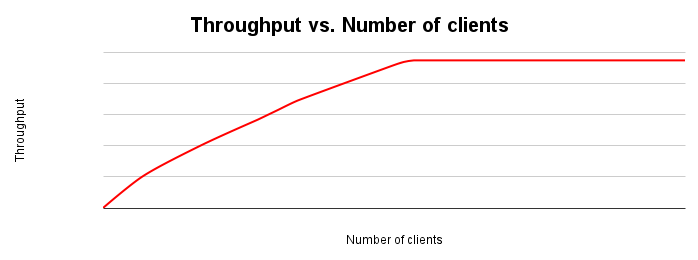
시스템의 부하를 두 배로 늘리면 처리량도 두 배로 늘어나는 것이 이상적입니다. 실제로는 리소스 경합이 발생하여 처리량이 더 적게 증가합니다. 어느 시점에서 리소스 소진 또는 경합으로 인해 처리량이 평탄해지거나 감소할 수 있습니다. 처리량을 위해 최적화하는 경우 이 지점이 중요합니다. 처리량을 개선하기 위해 애플리케이션 또는 데이터베이스 시스템을 조정할 위치를 파악하는 데 도움이 되기 때문입니다.
처리량이 안정화되거나 감소하는 일반적인 이유는 다음과 같습니다.
- 데이터베이스 서버의 CPU 리소스 소진
- 클라이언트의 CPU 리소스가 부족하여 데이터베이스 서버에 더 많은 작업이 전송되지 않음
- 데이터베이스 잠금 경합
- 데이터가 Postgres 버퍼 풀의 크기를 초과할 때의 I/O 대기 시간
- 스토리지 엔진 사용으로 인한 I/O 대기 시간
- 클라이언트에 데이터를 반환하는 네트워크 대역폭 병목 현상
지연 시간과 처리량은 반비례합니다. 지연 시간이 길어질수록 처리량은 감소합니다. 직관적으로도 이해가 됩니다. 병목 현상이 발생하기 시작하면 작업에 시간이 더 오래 걸리고 시스템에서 초당 실행하는 작업 수가 줄어듭니다.
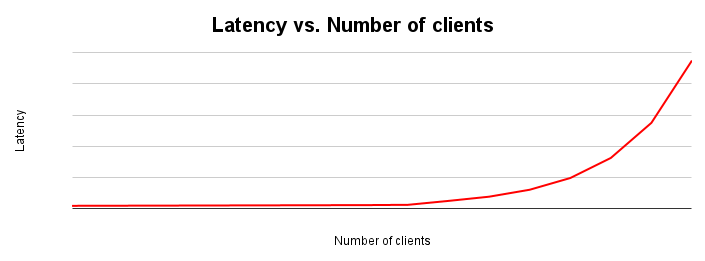
지연 시간 확장 그래프는 시스템에 가해지는 부하가 증가함에 따라 지연 시간이 어떻게 달라지는지 보여줍니다. 지연 시간은 리소스 경합으로 인해 마찰이 발생할 때까지 비교적 일정하게 유지됩니다. 이 곡선의 변곡점은 일반적으로 처리량 확장 그래프에서 처리량 곡선이 평탄해지는 지점에 해당합니다.
지연 시간을 평가하는 또 다른 유용한 방법은 히스토그램을 사용하는 것입니다. 이 표현에서는 지연 시간을 버킷으로 그룹화하고 각 버킷에 해당하는 요청 수를 계산합니다.
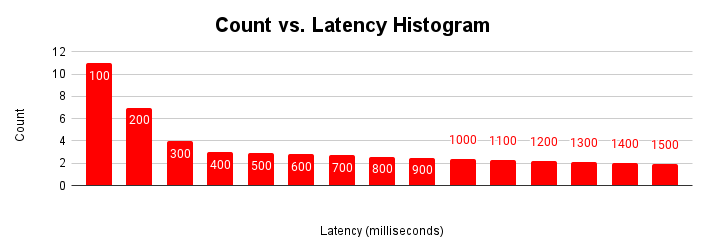
이 지연 시간 히스토그램은 대부분의 요청이 100밀리초 미만이고 100밀리초를 초과하는 지연 시간이 있음을 보여줍니다. 지연 시간 꼬리가 더 긴 요청의 원인을 이해하면 관찰된 애플리케이션 성능 변동을 설명하는 데 도움이 될 수 있습니다. 지연 시간 증가의 롱테일 원인은 일반적인 지연 시간 확장 그래프에서 볼 수 있는 지연 시간 증가와 처리량 그래프의 평탄화에 해당합니다.
지연 시간 히스토그램이 가장 유용한 경우는 애플리케이션에 여러 모달이 있는 경우입니다. 모달리티는 정상적인 작동 조건 집합입니다. 예를 들어 대부분의 경우 애플리케이션은 버퍼 캐시에 있는 페이지에 액세스합니다. 대부분의 경우 애플리케이션은 기존 행을 업데이트하지만 여러 모드가 있을 수 있습니다. 애플리케이션이 저장소에서 페이지를 가져오거나 새 행을 삽입하거나 잠금 경합이 발생하는 경우가 있습니다.
애플리케이션이 시간 경과에 따라 이러한 다양한 작동 모드를 접하게 되면 지연 시간 히스토그램에 이러한 여러 모달이 표시됩니다.
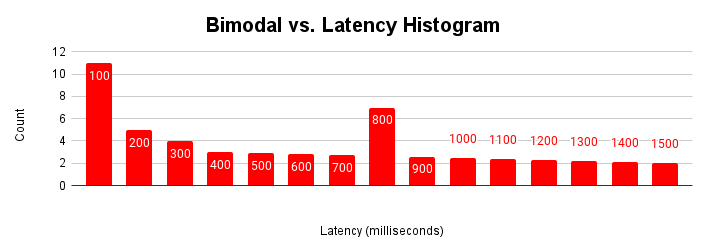
이 그림은 대부분의 요청이 100밀리초 미만으로 처리되지만 401~500밀리초가 소요되는 요청 클러스터가 있는 일반적인 바이모달 히스토그램을 보여줍니다. 이 두 번째 모달리티의 원인을 이해하면 애플리케이션 성능을 개선하는 데 도움이 될 수 있습니다. 두 가지 이상의 모달리티가 있을 수도 있습니다.
두 번째 모달리티는 일반적인 데이터베이스 작업, 이질적인 인프라 및 토폴로지 또는 애플리케이션 동작으로 인해 발생할 수 있습니다. 고려할 수 있는 몇 가지 예는 다음과 같습니다.
- 대부분의 데이터 액세스는 PostgreSQL 버퍼 풀에서 이루어지지만 일부는 저장소에서 이루어집니다.
- 일부 클라이언트와 데이터베이스 서버 간의 네트워크 지연 시간 차이
- 입력 또는 시간에 따라 다른 작업을 실행하는 애플리케이션 로직
- 산발적인 잠금 경합
- 클라이언트 활동 급증