이 문서에서는 AI Platform Prediction에 배포되는 머신러닝(ML) 모델의 온라인 제공 성능을 테스트하고 모니터링하는 방법을 설명합니다. 이 문서는 부하 테스트를 위한 오픈소스 도구인 Locust를 사용합니다.
이 문서는 프로덕션에서 ML 모델의 서비스 워크로드, 지연 시간, 리소스 사용률을 모니터링하려는 데이터 과학자 및 MLOps 엔지니어를 위한 것입니다.
이 문서에서는 Google Cloud, TensorFlow, AI Platform Prediction, Cloud Monitoring, Jupyter 노트북에 익숙하다고 가정합니다.
이 문서는 문서에서 설명하는 시스템을 구현하기 위한 코드와 배포 가이드가 포함된 GitHub 저장소가 함께 제공됩니다. 태스크는 Jupyter 노트북에 통합됩니다.
비용
이 문서에서 다루는 노트북은 다음과 같은 청구 가능한 Google Cloud 구성요소를 사용합니다.
- Vertex AI Workbench 사용자 관리 노트북
- AI Platform Prediction
- Cloud Storage
- Cloud Monitoring
- Google Kubernetes Engine(GKE)
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용하세요.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
아키텍처 개요
다음 다이어그램은 온라인 예측을 위해 ML 모델을 배포하고 부하 테스트를 실행하며 ML 모델 제공 성능을 위한 측정항목을 수집하고 분석하는 시스템 아키텍처를 보여줍니다.
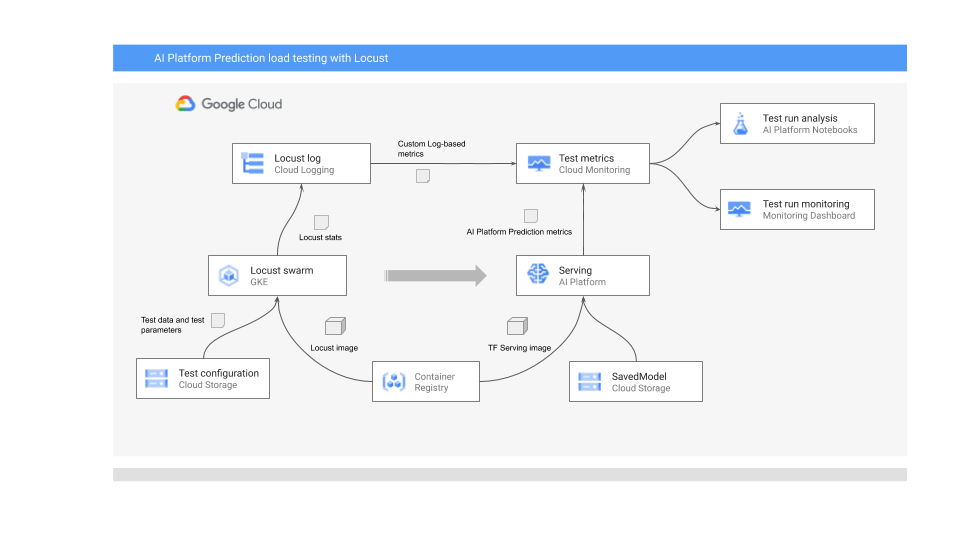
이 다이어그램은 다음 흐름을 보여줍니다.
- 학습된 모델은 Cloud Storage에 있을 수 있습니다(예: TensorFlow SavedModel 또는 scikit-learn joblib.). 또는 Container Registry의 커스텀 제공 컨테이너에 통합될 수 있습니다(예: PyTorch 모델 제공을 위한 TorchServe).
- 모델은 REST API로 AI Platform Prediction에 배포됩니다. AI Platform Prediction은 다양한 머신 유형을 지원하고 리소스 사용률에 따른 자동 확장을 지원하며 다양한 GPU 가속기를 지원하는 모델 제공을 위한 완전 관리형 서비스입니다.
- Locust는 테스트 태스크(즉, 사용자 행동)를 구현하는 데 사용됩니다. 이를 위해 AI Platform Prediction에 배포된 ML 모델을 호출하고 Google Kubernetes Engine(GKE)에서 대규모로 실행합니다. 이는 모델 예측 서비스의 부하 테스트를 위한 많은 동시 사용자 호출을 시뮬레이션합니다. Locust 웹 인터페이스를 사용하여 테스트 진행 상황을 모니터링할 수 있습니다.
- Locust는 Cloud Logging에 대한 테스트 통계를 기록합니다. Locust 테스트에서 생성된 로그 항목은 Cloud Monitoring에서 로그 기반 측정항목 집합을 정의하는 데 사용됩니다. 이러한 측정항목은 표준 AI Platform Prediction 측정항목을 보완합니다.
- AI Platform 측정항목과 커스텀 Locust 측정항목은 모두 Cloud Monitoring 대시보드에서 실시간으로 시각화에 사용할 수 있습니다. 테스트가 완료되면 Vertex AI Workbench 사용자 관리 노트북에서 측정항목을 분석 및 시각화할 수 있도록 측정항목이 프로그래매틱 방식으로도 수집됩니다.
이 시나리오의 Jupyter 노트북
모델 준비 및 배포, Locust 테스트 실행, 테스트 결과 수집 및 분석을 위한 모든 작업은 다음 Jupyter 노트북에 코딩되어 있습니다. 작업을 수행하려면 각 노트북에서 셀 시퀀스를 실행합니다.
01-prepare-and-deploy.ipynb. 이 노트북을 실행하여 제공을 위한 TensorFlow SavedModel을 준비하고 모델을 AI Platform Prediction에 배포합니다.02-perf-testing.ipynb. 이 노트북을 실행하여 Locust 테스트를 위해 Cloud Monitoring에 로그 기반 측정항목을 만들고 Locust 테스트를 GKE에 배포한 후 실행합니다.03-analyze-results.ipynb. 이 노트북을 실행하여 Cloud Monitoring에서 생성된 표준 AI Platform 측정항목 및 커스텀 Locust 측정항목의 Locust 부하 테스트 결과를 수집하고 분석합니다.
환경 초기화
연결된 GitHub 저장소의 README.md 파일에 설명된 대로 노트북을 실행할 환경을 준비하려면 다음 단계를 수행해야 합니다.
- Google Cloud 프로젝트에서 학습된 모델과 Locust 테스트 구성을 저장하는 데 필요한 Cloud Storage 버킷을 만듭니다. 나중에 필요하므로 버킷에 사용할 이름을 기록해 둡니다.
- 프로젝트에서 Cloud Monitoring 작업공간을 만듭니다.
- 필요한 CPU가 있는 Google Kubernetes Engine 클러스터를 만듭니다. 노드 풀은 Cloud API에 액세스할 수 있어야 합니다.
- TensorFlow 2를 사용하는 Vertex AI Workbench 사용자 관리 노트북 인스턴스를 만듭니다. 이 튜토리얼에서는 모델을 학습하지 않으므로 GPU가 필요하지 않습니다. (GPU는 다른 시나리오에서, 특히 모델 학습 속도를 높이는 데 유용할 수 있습니다.)
JupyterLab 열기
시나리오의 태스크를 진행하려면 JupyterLab 환경을 열고 노트북을 가져와야 합니다.
Google Cloud Console에서 Notebooks 페이지로 이동합니다.
사용자 관리 노트북 탭에서 만든 노트북 환경 옆에 있는 Jupyterlab 열기를 클릭합니다.
그러면 브라우저에서 JupyterLab 환경이 열립니다.
터미널 탭을 시작하기 위해 Launcher 탭에서 터미널 아이콘을 클릭합니다.
터미널에서
mlops-on-gcpGitHub 저장소를 클론합니다.git clone https://github.com/GoogleCloudPlatform/mlops-on-gcp.git명령어가 완료되면 파일 브라우저에
mlops-on-gcp폴더가 표시됩니다. 이 문서에서 작업 중인 노트북이 이 폴더에 표시됩니다.
노트북 설정 구성
이 섹션에서는 해당 컨텍스트와 관련된 값으로 노트북의 변수를 설정하고, 시나리오의 코드를 실행하도록 환경을 준비합니다.
model_serving/caip-load-testing디렉터리로 이동합니다.- 3개의 노트북 각각에 대해 다음을 수행합니다.
- 노트북을 엽니다.
- Google Cloud 환경 설정 구성에서 셀을 실행합니다.
다음 섹션에서는 이 프로세스의 핵심 부분을 강조해서 보여주고 디자인 및 코드 부분을 설명합니다.
온라인 예측을 위한 모델 제공
이 문서에 사용되는 ML 모델은 TensorFlow Hub의 사전 학습된 ResNet V2 101 이미지 분류 모델을 사용합니다. 하지만 이 문서의 시스템 설계 패턴 및 기법을 다른 도메인 및 다른 유형의 모델에 적용할 수 있습니다.
ResNet 101 모델을 준비하고 제공하기 위한 코드는 01-prepare-and-deploy.ipynb 노트북에 있습니다. 노트북에서 셀을 실행하여 다음 작업을 수행합니다.
- TensorFlow Hub에서 ResNet 모델을 다운로드하고 실행합니다.
- 모델의 제공 서명을 만듭니다.
- 모델을 SavedModel로 내보냅니다.
- SavedModel을 AI Platform Prediction에 배포합니다.
- 배포된 모델의 유효성을 검사합니다.
이 문서의 다음 섹션에서는 ResNet 모델 준비 및 배포에 대해 자세히 설명합니다.
배포용 ResNet 모델 준비
TensorFlow Hub의 ResNet 모델은 재구성 및 미세 조정에 최적화되어 있으므로 제공 서명이 없습니다. 따라서 온라인 예측을 위해 모델을 제공할 수 있도록 모델의 제공 서명을 만들어야 합니다.
또한 모델을 제공하는 경우 제공 인터페이스에 특성 추출 로직을 삽입하는 것이 좋습니다. 이렇게 하면 필요한 형식으로 데이터를 사전 처리하기 위해 클라이언트 애플리케이션에 의존하지 않고 사전 처리와 모델 제공 간의 어피니티를 보장할 수 있습니다. 또한 제공 인터페이스에 후처리(예: 클래스 ID를 클래스 라벨로 변환)를 포함해야 합니다.
ResNet 모델을 제공 가능하게 만들려면 모델의 추론 메서드를 설명하는 제공 서명을 구현해야 합니다. 따라서 노트북 코드는 다음과 같은 두 개의 서명을 추가합니다.
- 기본 서명 이 서명은 ResNet V2 101 모델의 기본
predict메서드를 노출합니다. 기본 메서드에는 전처리 또는 후처리 로직이 없습니다. - 전처리 및 후처리 서명 이 인터페이스에 예상되는 입력에는 인코딩, 확장, 이미지 정규화와 같이 상대적으로 복잡한 전처리가 필요합니다. 따라서 모델은 전처리 및 후처리 로직을 삽입하는 대체 서명도 노출합니다. 이 서명은 처리되지 않은 원시 이미지를 허용하고 순위가 지정된 클래스 라벨 및 관련 라벨 확률 목록을 반환합니다.
서명은 커스텀 모듈 클래스에 생성됩니다. 이 클래스는 ResNet 모델을 캡슐화하는 tf.Module 기본 클래스에서 파생됩니다. 커스텀 클래스는 이미지 전처리 및 출력 후처리 로직을 구현하는 메서드로 기본 클래스를 확장합니다. 커스텀 모듈의 기본 메서드는 유사한 인터페이스를 유지하기 위해 기본 ResNet 모델의 기본 메서드에 매핑됩니다. 커스텀 모듈은 원본 모델, 전처리 로직, 2개의 제공 서명을 포함하는 SavedModel로 내보냅니다.
커스텀 모듈 클래스의 구현은 다음 코드 스니펫에서 보여줍니다.
LABELS_KEY = 'labels'
PROBABILITIES_KEY = 'probabilities'
NUM_LABELS = 5
class ServingModule(tf.Module):
"""
A custom tf.Module that adds image preprocessing and output post processing to
a base TF 2 image classification model from TensorFlow Hub.
"""
def __init__(self, base_model, input_size, output_labels):
super(ServingModule, self).__init__()
self._model = base_model
self._input_size = input_size
self._output_labels = tf.constant(output_labels, dtype=tf.string)
def _decode_and_scale(self, raw_image):
"""
Decodes, crops, and resizes a single raw image.
"""
image = tf.image.decode_image(raw_image, dtype=tf.dtypes.uint8, expand_animations=False)
image_shape = tf.shape(image)
image_height = image_shape[0]
image_width = image_shape[1]
crop_size = tf.minimum(image_height, image_width)
offset_height = ((image_height - crop_size) + 1) // 2
offset_width = ((image_width - crop_size) + 1) // 2
image = tf.image.crop_to_bounding_box(image, offset_height, offset_width, crop_size, crop_size)
image = tf.image.resize(image, [self._input_size, self._input_size])
image = tf.cast(image, tf.uint8)
return image
def _preprocess(self, raw_inputs):
"""
Preprocesses raw inputs as sent by the client.
"""
# A mitigation for https://github.com/tensorflow/tensorflow/issues/28007
with tf.device('/cpu:0'):
images = tf.map_fn(self._decode_and_scale, raw_inputs, dtype=tf.uint8)
images = tf.image.convert_image_dtype(images, tf.float32)
return images
def _postprocess(self, model_outputs):
"""
Postprocess outputs returned by the base model.
"""
probabilities = tf.nn.softmax(model_outputs)
indices = tf.argsort(probabilities, axis=1, direction='DESCENDING')
return {
LABELS_KEY: tf.gather(self._output_labels, indices, axis=-1)[:,:NUM_LABELS],
PROBABILITIES_KEY: tf.sort(probabilities, direction='DESCENDING')[:,:NUM_LABELS]
}
@tf.function(input_signature=[tf.TensorSpec([None, 224, 224, 3], tf.float32)])
def __call__(self, x):
"""
A pass-through to the base model.
"""
return self._model(x)
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def predict_labels(self, raw_images):
"""
Preprocesses inputs, calls the base model
and postprocess outputs from the base model.
"""
# Call the preprocessing handler
images = self._preprocess(raw_images)
# Call the base model
logits = self._model(images)
# Call the postprocessing handler
outputs = self._postprocess(logits)
return outputs
serving_module = ServingModule(model, 224, imagenet_labels)
다음 코드 스니펫은 앞에서 정의한 제공 서명이 있는 SavedModel로 모델을 내보내는 방법을 보여줍니다.
...
default_signature = serving_module.__call__.get_concrete_function()
preprocess_signature = serving_module.predict_labels.get_concrete_function()
signatures = {
'serving_default': default_signature,
'serving_preprocess': preprocess_signature
}
tf.saved_model.save(serving_module, model_path, signatures=signatures)
AI Platform Prediction에 모델 배포
모델을 SavedModel로 내보내면 다음 태스크가 수행됩니다.
- 모델이 Cloud Storage에 업로드됩니다.
- 모델 객체는 AI Platform Prediction에서 생성됩니다.
- SavedModel의 모델 버전이 생성됩니다.
노트북의 다음 코드 스니펫은 이러한 태스크를 수행하는 명령어를 보여줍니다.
gcloud storage cp {model_path} {GCS_MODEL_LOCATION} --recursive
gcloud ai-platform models create {MODEL_NAME} \
--project {PROJECT_ID} \
--regions {REGION}
MACHINE_TYPE='n1-standard-8'
ACCELERATOR='count=1,type=nvidia-tesla-p4'
gcloud beta ai-platform versions create {MODEL_VERSION} \
--model={MODEL_NAME} \
--origin={GCS_MODEL_LOCATION} \
--runtime-version=2.1 \
--framework=TENSORFLOW \
--python-version=3.7 \
--machine-type={MACHINE_TYPE} \
--accelerator={ACCELERATOR} \
--project={PROJECT_ID}
이 명령어는 nvidia-tesla-p4 GPU 가속기와 함께 모델 예측 서비스를 위한 n1-standard-8 머신 유형을 만듭니다.
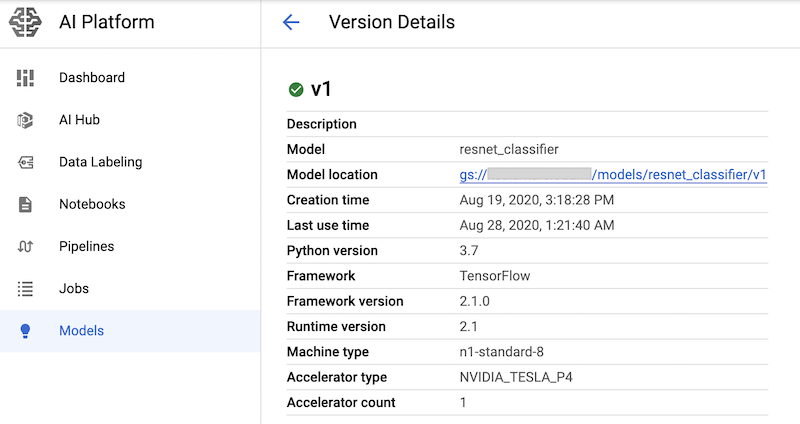
이러한 명령어가 포함된 노트북 셀을 실행한 후에는 Google Cloud 콘솔의 AI Platform 모델 페이지에서 모델 버전을 조회하여 배포되었는지 확인할 수 있습니다. 출력은 다음과 비슷합니다.
Cloud Monitoring 측정항목 만들기
모델을 제공하도록 설정한 후에는 제공 성능을 모니터링할 수 있는 측정항목을 구성할 수 있습니다. 측정항목을 구성하는 코드는 02-perf-testing.ipynb 노트북에 있습니다.
02-perf-testing.ipynb 노트북의 첫 번째 부분은 Python Cloud Logging SDK를 사용하여 Cloud Monitoring에서 커스텀 로그 기반 측정항목을 만듭니다.
측정항목은 Locust 태스크에서 생성된 로그 항목을 기반으로 합니다.
log_stats 메서드는 locust라는 Cloud Logging 로그에 로그 항목을 씁니다.
각 로그 항목에는 다음 표에 나열된 대로 JSON 형식의 키-값 쌍이 포함됩니다. 측정항목은 로그 항목의 키 하위 집합을 기반으로 합니다.
| 키 | 값 설명 | 사용 |
|---|---|---|
test_id
|
테스트 ID | 필터링 속성 |
model |
AI Platform Prediction 모델 이름 | |
model_version |
AI Platform Prediction 모델 버전 | |
latency
|
10초 슬라이딩 구간에서 계산되는 95번째 백분위수 응답 시간 | 측정항목 값 |
num_requests |
테스트가 시작된 이후 총 요청 수 | |
num_failures |
테스트가 시작된 이후 총 실패 수 | |
user_count |
시뮬레이션된 사용자 수 | |
rps |
초당 요청 |
다음 코드 스니펫은 커스텀 로그 기반 측정항목을 만드는 노트북의 create_locust_metric 함수를 보여줍니다.
def create_locust_metric(
metric_name:str,
log_path:str,
value_field:str,
bucket_bounds:List[int]):
metric_path = logging_client.metric_path(PROJECT_ID, metric_name)
log_entry_filter = 'resource.type=global AND logName={}'.format(log_path)
metric_descriptor = {
'metric_kind': 'DELTA',
'value_type': 'DISTRIBUTION',
'labels': [{'key': 'test_id', 'value_type': 'STRING'},
{'key': 'signature', 'value_type': 'STRING'}]}
bucket_options = {
'explicit_buckets': {'bounds': bucket_bounds}}
value_extractor = 'EXTRACT(jsonPayload.{})'.format(value_field)
label_extractors = {
'test_id': 'EXTRACT(jsonPayload.test_id)',
'signature': 'EXTRACT(jsonPayload.signature)'}
metric = logging_v2.types.LogMetric(
name=metric_name,
filter=log_entry_filter,
value_extractor=value_extractor,
bucket_options=bucket_options,
label_extractors=label_extractors,
metric_descriptor=metric_descriptor,
)
try:
logging_client.get_log_metric(metric_path)
print('Metric: {} already exists'.format(metric_path))
except:
logging_client.create_log_metric(parent, metric)
print('Created metric {}'.format(metric_path))
다음 코드 스니펫은 노트북에서 create_locust_metric 메서드가 호출되어 이전 표에 표시된 4개의 커스텀 Locust 측정항목을 만드는 방법을 보여줍니다.
# user count metric
metric_name = 'locust_users'
value_field = 'user_count'
bucket_bounds = [1, 16, 32, 64, 128]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# latency metric
metric_name = 'locust_latency'
value_field = 'latency'
bucket_bounds = [1, 50, 100, 200, 500]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# failure count metric
metric_name = 'num_failures'
value_field = 'num_failures'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# request count metric
metric_name = 'num_requests'
value_field = 'num_requests'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
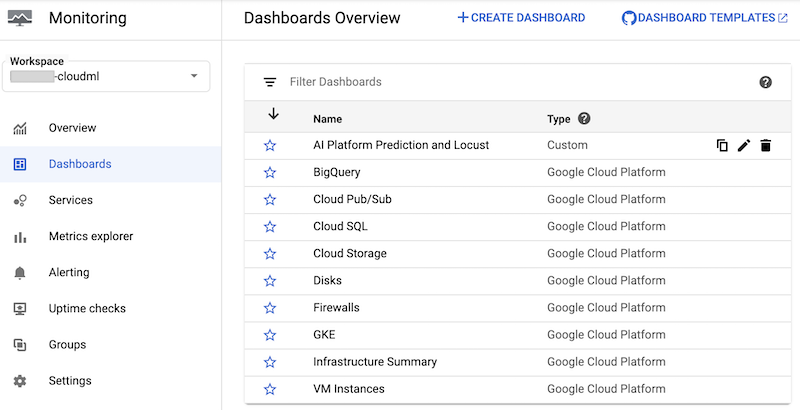
노트북은 AI Platform Prediction 및 Locust라는 커스텀 Cloud Monitoring 대시보드를 만듭니다. 대시보드는 Locust 로그를 기반으로 생성된 표준 AI Platform Prediction 측정항목과 커스텀 측정항목을 결합합니다.
자세한 내용은 Cloud Logging API 문서를 참조하세요.
이 대시보드 및 차트는 수동으로 작성할 수 있습니다.
하지만 노트북은 monitoring-template.json JSON 템플릿을 사용하여 이를 프로그래매틱 방식으로 만드는 방법을 제공합니다. 이 코드는 다음 코드 스니펫과 같이 DashboardsServiceClient 클래스를 사용하여 JSON 템플릿을 로드하고 Cloud Monitoring에서 대시보드를 만듭니다.
parent = 'projects/{}'.format(PROJECT_ID)
dashboard_template_file = 'monitoring-template.json'
with open(dashboard_template_file) as f:
dashboard_template = json.load(f)
dashboard_proto = Dashboard()
dashboard_proto = ParseDict(dashboard_template, dashboard_proto)
dashboard = dashboard_service_client.create_dashboard(parent, dashboard_proto)
대시보드가 만들어지면 Google Cloud 콘솔의 Cloud Monitoring 대시보드 목록에서 이 대시보드를 확인할 수 있습니다.
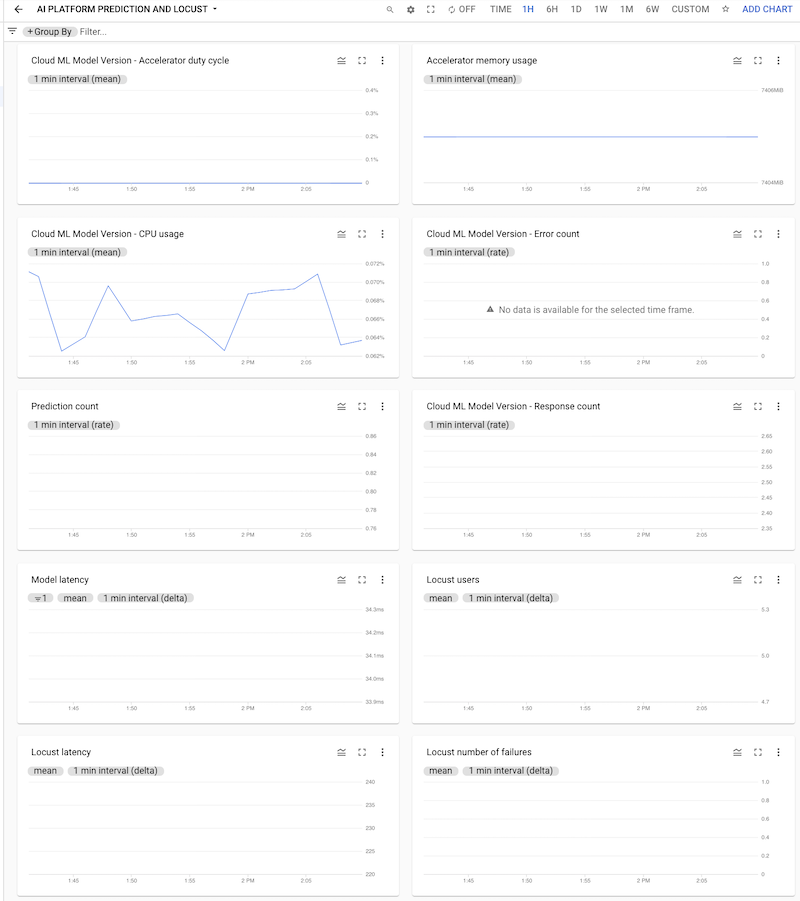
대시보드를 클릭하여 열면 차트를 볼 수 있습니다. 각 차트에는 다음 스크린샷과 같이 AI Platform Prediction 또는 Locust 로그의 측정항목이 표시됩니다.
GKE 클러스터에 Locust 테스트 배포
GKE에 Locust 시스템을 배포하기 전에 task.py 파일에 기본 제공되는 테스트 로직이 포함된 Docker 컨테이너 이미지를 빌드해야 합니다. 이미지는 baseline locust.io 이미지에서 파생되며 Locust 마스터 및 작업자 포드에 사용됩니다.
빌드 및 배포 로직은 3. GKE 클러스터에 Locust 배포의 노트북에 있습니다. 이미지는 다음 코드를 사용하여 빌드됩니다.
image_uri = 'gcr.io/{}/locust'.format(PROJECT_ID)
!gcloud builds submit --tag {image_uri} locust/locust-image
노트북에 설명된 배포 프로세스는 Kustomize를 사용하여 정의되었습니다. Locust Kustomize 배포 매니페스트는 구성요소를 정의하는 다음 파일을 정의합니다.
locust-master. 이 파일은 테스트를 시작하고 실시간 통계를 확인하는 웹 인터페이스를 호스팅하는 배포를 정의합니다.locust-worker. 이 파일은 ML 모델 예측 서비스의 부하 테스트를 위한 태스크를 실행하는 배포를 정의합니다. 일반적으로 여러 작업자가 동시에 생성되어 예측 서비스 API를 호출하는 여러 동시 사용자에게 미치는 영향을 시뮬레이션합니다.locust-worker-service. 이 파일은 HTTP 부하 분산기를 통해locust-master의 웹 인터페이스에 액세스하는 서비스를 정의합니다.
클러스터를 배포하기 전에 기본 매니페스트를 업데이트해야 합니다. 기본 매니페스트는 kustomization.yaml 및 patch.yaml 파일로 구성됩니다. 두 파일을 모두 변경해야 합니다.
kustomization.yaml 파일에서 다음을 수행합니다.
- 커스텀 Locust 이미지의 이름을 설정합니다.
images섹션의newName필드를 이전에 빌드한 커스텀 이미지의 이름으로 설정합니다. - 선택적으로 작업자 pod 수를 설정합니다. 기본 구성은 32개의 작업자 pod를 배포합니다. 개수를 변경하려면
replicas섹션의count필드를 수정합니다. GKE 클러스터에 Locust 작업자를 위한 CPU 개수가 충분한지 확인합니다. - 테스트 구성 및 페이로드 파일의 Cloud Storage 버킷을 설정합니다.
configMapGenerator섹션에서 다음이 설정되어 있는지 확인합니다.LOCUST_TEST_BUCKET. 이전에 만든 Cloud Storage 버킷의 이름으로 설정합니다.LOCUST_TEST_CONFIG. 테스트 구성 파일 이름으로 설정합니다. YAML 파일에서 이는test-config.json로 설정되지만 다른 이름을 사용하기 위해 변경할 수 있습니다.LOCUST_TEST_PAYLOAD. 테스트 페이로드 파일 이름으로 설정합니다. YAML 파일에서 이는test-payload.json로 설정되지만 다른 이름을 사용하기 위해 변경할 수 있습니다.
patch.yaml 파일에서 다음을 수행합니다.
- 선택적으로 Locust 마스터 및 작업자를 호스팅하는 노드 풀을 수정합니다. Locust 워크로드를
default-pool이외의 노드 풀에 배포하는 경우matchExpressions섹션을 찾은 다음values에서 Locust 워크로드가 배포되는 노드 풀 이름을 업데이트합니다.
변경한 후에는 Kustomize 매니페스트에 맞춤설정을 빌드하고 Locust 배포(locust-master, locust-worker, locust-master-service)를 GKE 클러스터에 적용할 수 있습니다. 노트북의 다음 명령어는 다음과 같은 태스크를 수행합니다.
!kustomize build locust/manifests | kubectl apply -f -
Google Cloud 콘솔에서 배포된 워크로드를 확인할 수 있습니다. 출력은 다음과 비슷합니다.
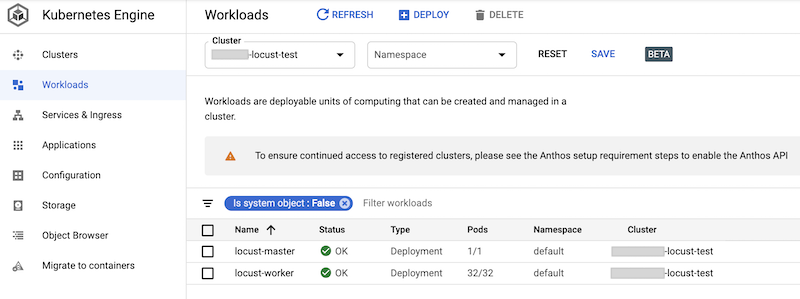
Locust 부하 테스트 구현
Locust의 테스트 태스크는 AI Platform Prediction에 배포된 모델을 호출하는 것입니다.
이 태스크는 /locust/locust-image/ 폴더에 있는 task.py 모듈의 AIPPClient 클래스에서 구현됩니다. 다음 코드 스니펫은 클래스 구현을 보여줍니다.
class AIPPClient(object):
"""
A convenience wrapper around AI Platform Prediction REST API.
"""
def __init__(self, service_endpoint):
logging.info(
"Setting the AI Platform Prediction service endpoint: {}".format(service_endpoint))
credentials, _ = google.auth.default()
self._authed_session = AuthorizedSession(credentials)
self._service_endpoint = service_endpoint
def predict(self, project_id, model, version, signature, instances):
"""
Invokes the predict method on the specified signature.
"""
url = '{}/v1/projects/{}/models/{}/versions/{}:predict'.format(
self._service_endpoint, project_id, model, version)
request_body = {
'signature_name': signature,
'instances': instances
}
response = self._authed_session.post(url, data=json.dumps(request_body))
return response
task.py 파일의 AIPPUser 클래스는 locust.User 클래스에서 상속되어 AI Platform Prediction 모델을 호출하는 사용자 행동을 시뮬레이션합니다. 이 행동은 predict_task 메서드에서 구현됩니다. AIPPUser 클래스의 on_start 메서드는 task.py 파일의 LOCUST_TEST_BUCKET 변수에 지정된 Cloud Storage 버킷에서 다음 파일을 다운로드합니다.
test-config.json. 이 JSON 파일에는test_id,project_id,model,version에 대한 테스트 구성이 포함되어 있습니다.test-payload.json. 이 JSON 파일에는 AI Platform Prediction에서 필요한 형식의 데이터 인스턴스와 대상 서명이 포함됩니다.
테스트 데이터 및 테스트 구성을 준비하는 코드는 02-perf-testing.ipynb 노트북(4. Locust 테스트 구성)에 포함되어 있습니다.
테스트 구성과 데이터 인스턴스는 AIPPClient 클래스의 predict 메서드 매개변수로 사용되어 필수 테스트 데이터로 타겟 모델을 테스트합니다. AIPPUser는 단일 사용자로부터의 호출 간에 1~2초의 대기 시간을 시뮬레이션합니다.
Locust 테스트 실행
노트북 셀을 실행하여 Locust 워크로드를 GKE 클러스터에 배포하고 test-config.json 및 test-payload.json 파일을 만들어 Cloud Storage에 업로드한 후에는 웹 인터페이스를 사용하여 새로운 Locust 부하 테스트를 시작, 중지, 구성할 수 있습니다.
노트북의 코드는 다음 명령어를 사용하여 웹 인터페이스를 노출하는 외부 부하 분산기의 URL을 검색합니다.
%%bash
IP_ADDRESS=$(kubectl get service locust-master | awk -v col=4 'FNR==2{print $col}')
echo http://$IP_ADDRESS:8089
테스트를 수행하려면 다음을 따릅니다.
- 브라우저에서 검색한 URL을 입력합니다.
다른 구성을 사용하여 테스트 워크로드를 시뮬레이션하려면 다음과 비슷한 값을 Locust 인터페이스에 입력합니다.
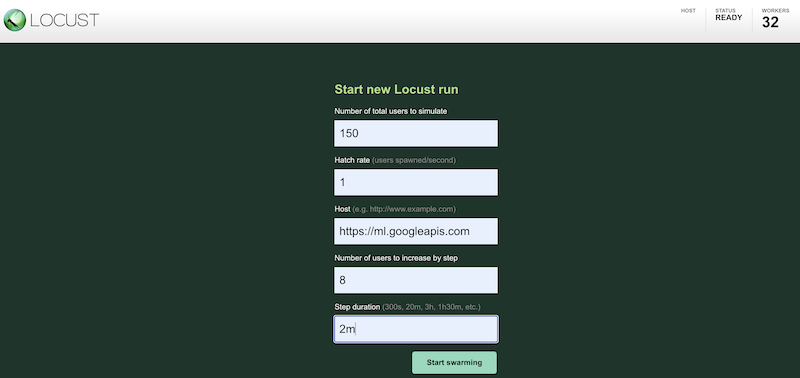
위 스크린샷에는 다음 구성 값이 나와 있습니다.
- 시뮬레이션할 총 사용자 수:
150 - 해치 비율:
1 - 호스트:
http://ml.googleapis.com - 단계별로 늘릴 사용자 수:
10 - 단계 지속 시간:
2m
- 시뮬레이션할 총 사용자 수:
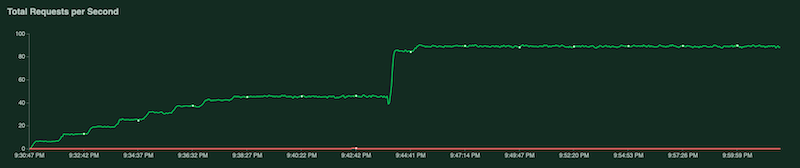
테스트가 실행되면 Locust 차트를 검사하여 테스트를 모니터링할 수 있습니다. 다음 스크린샷은 값이 표시되는 방식을 보여줍니다.
한 차트는 초당 총 요청 수를 보여줍니다.
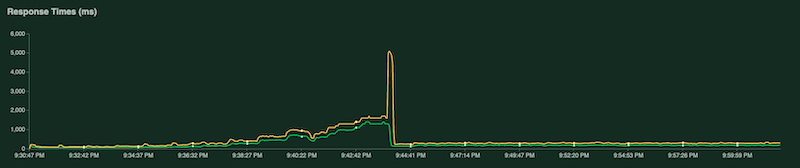
또 다른 차트는 응답 시간을 밀리초 단위로 보여줍니다.
앞에서 설명한 것처럼 이러한 통계는 Cloud Logging에 로깅되므로 커스텀 Cloud Monitoring 로그 기반 측정항목을 만들 수 있습니다.
테스트 결과 수집 및 분석
다음 태스크는 결과 로그에서 계산된 Cloud Monitoring 측정항목을 Pandas DataFrame 객체로 수집하고 분석하므로 노트북에서 결과를 시각화하고 분석할 수 있습니다. 이 태스크를 수행하는 코드는 03-analyze-results.ipynb 노트북에 있습니다.
이 코드는 Cloud Monitoring 쿼리 Python SDK를 사용하여 project_id, test_id, start_time, end_time, model, model_version, log_name 매개변수에 전달된 값을 기준으로 측정항목 값을 필터링하고 검색합니다.
다음 코드 스니펫은 AI Platform Prediction 측정항목과 커스텀 Locust 로그 기반 측정항목을 검색하는 메서드를 보여줍니다.
import pandas as pd
from google.cloud.monitoring_v3.query import Query
def _get_aipp_metric(metric_type: str, labels: List[str]=[], metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified AIPP metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_resources(model_id=model)
query = query.select_resources(version_id=model_version)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.set_index(df.index.round('T'))
return df
def _get_locust_metric(metric_type: str, labels: List[str]=[],
metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified custom logs-based metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_metrics(log=log_name)
query = query.select_metrics(test_id=test_id)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.apply(lambda row: [metric.mean for metric in row])
df = df.set_index(df.index.round('T'))
return df
측정항목 데이터는 각 측정항목의 Pandas DataFrame 객체로 검색된 후 개별 데이터 프레임은 단일 DataFrame 객체로 병합됩니다. 병합된 결과가 있는 최종 DataFrame 객체는 노트북에서 다음과 같습니다.
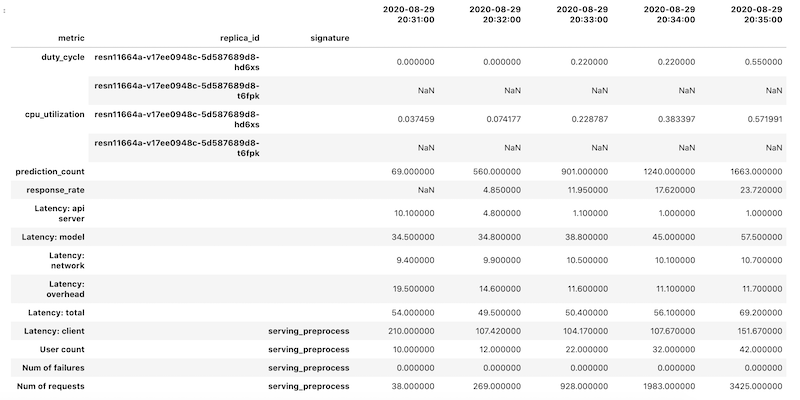
검색된 DataFrame 객체는 열 이름에 계층적 색인 생성을 사용합니다. 이유는 일부 측정항목에 여러 시계열이 포함되어 있기 때문입니다.
예를 들어 GPU duty_cycle 측정항목에는 배포에 사용된 각 GPU에 대한 시계열 측정값이 포함됩니다(replica_id로 표시). 열 색인의 최상위 수준은 개별 측정항목의 이름을 보여줍니다. 두 번째 수준은 복제본 ID입니다. 세 번째 수준은 모델의 서명을 보여줍니다. 모든 측정항목은 동일한 타임라인에 정렬됩니다.
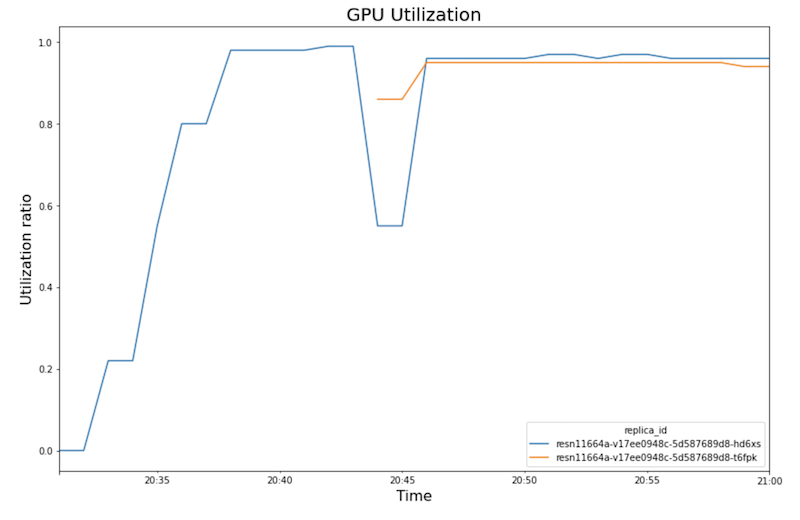
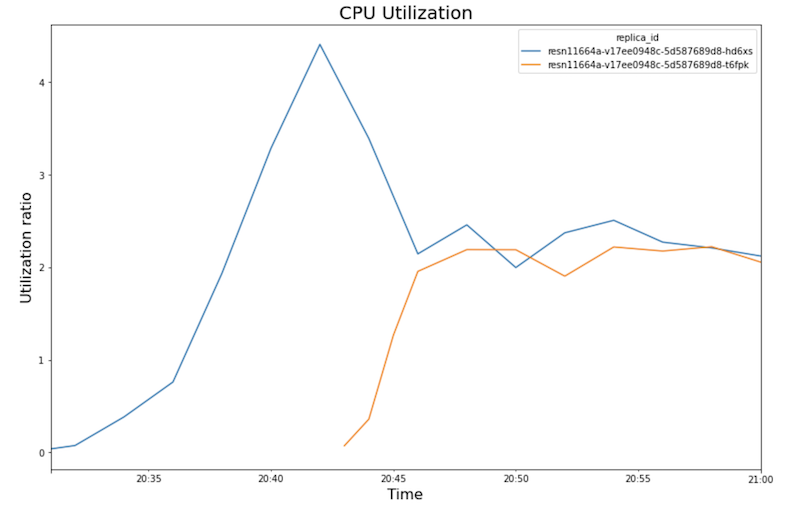
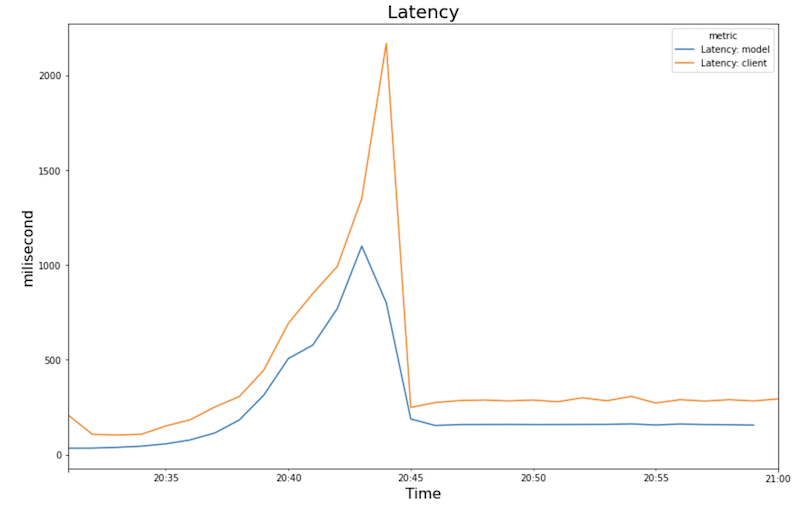
다음 차트는 노트북에서 볼 수 있는 GPU 사용률, CPU 사용률, 지연 시간을 보여줍니다.
GPU 사용률:
CPU 사용률:
지연 시간:
차트는 다음 행동과 순서를 보여줍니다.
- 워크로드(사용자 수)가 증가하면 CPU 및 GPU 사용률이 증가합니다. 따라서 지연 시간이 증가하고, 약 20:40 시점이 될 때까지 모델 지연 시간과 총 지연 시간 차이가 증가합니다.
- 20:40에 GPU 사용률이 100%에 도달하는 동안 CPU 차트에서는 사용률이 4에 도달하는 것을 보여줍니다. 샘플은 이 테스트에서 CPU가 8개인
n1-standard-8머신을 사용합니다. 따라서 CPU 사용률은 50%에 도달합니다. - 이 시점에서 자동 확장은 용량을 추가합니다. 이때 GPU 추가 복제본이 있는 새로운 제공 노드가 추가됩니다. 첫 번째 GPU 복제본 사용률은 감소하고 두 번째 GPU 복제본 사용률은 증가합니다.
- 예측을 제공하기 새 복제본이 시작되면 약 200밀리초에 걸쳐 수렴됩니다.
- CPU 사용률이 각 복제본에 대해 약 250%로 수렴됩니다. 즉, CPU 8개 중 2.5개의 CPU를 사용합니다. 이 값은
n1-standard-8머신 대신n1-standard-4머신을 사용할 수 있음을 나타냅니다.
삭제
이 문서에서 사용된 리소스 비용이 Google Cloud에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Google Cloud 프로젝트를 보존하면서 만든 리소스를 삭제하려면 Google Kubernetes Engine 클러스터와 배포된 AI Platform 모델을 삭제합니다.
다음 단계
- MLOps와 머신러닝의 지속적 배포 및 자동화 파이프라인에 대해 알아보세요.
- TFX, Kubeflow Pipelines, Cloud Build를 사용한 MLOps 아키텍처에 대해 알아보세요.
- 클라우드 아키텍처 센터에서 참조 아키텍처, 다이어그램, 권장사항 자세히 살펴보기