Este artículo es la segunda parte de una serie de cuatro en el que se analiza cómo puedes predecir el valor del ciclo de vida del cliente (CVC) con AI Platform en Google Cloud.
Los artículos de esta serie son los siguientes:
- Parte 1: Introducción. Se presentan el CVC y dos técnicas de modelado para predecirlo.
- Parte 2: Entrena el modelo (este artículo). Se analiza cómo preparar los datos y entrenar los modelos.
- Parte 3: Implementa en producción. Se describe cómo implementar los modelos analizados en la Parte 2 en un sistema de producción.
- Parte 4: Usa tablas de AutoML. Se muestra cómo usar las tablas de AutoML para compilar un modelo a fin de implementarlo.
El código para implementar este sistema está en un repositorio de GitHub. En esta serie, analizamos para qué sirve el código y cómo se usa.
Introducción
Este artículo le sigue a la Parte 1, en la que se aprende sobre dos modelos diferentes para predecir el valor del ciclo de vida del cliente (CVC):
- Modelos probabilísticos
- Modelos de red neuronal profunda (DNN), un tipo de modelo de aprendizaje automático
Como se indica en la Parte 1, uno de los objetivos de esta serie es comparar estos modelos para predecir el CVC. En esta parte de la serie, se describe cómo puedes preparar los datos, compilar y entrenar ambos tipos de modelo para predecir el CVC y se proporciona información de comparaciones.
Instala el código
Si quieres seguir el proceso descrito en este artículo, debes instalar el código de muestra de GitHub.
Si tienes la opción CLI de gcloud instalado, abre una ventana de terminal en tu computadora para ejecutar estos comandos. Si no tienes instalada la CLI de gcloud, abre una instancia de Cloud Shell.
Clona el repositorio de código de muestra:
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
Sigue las instrucciones de instalación de la sección Instalar del archivo README a fin de configurar tu entorno.
Preparación de datos
En esta sección, se describe cómo puedes obtener y limpiar los datos.
Obtén y limpia el conjunto de datos de origen
Antes de poder calcular el CVC, debes asegurarte de que tus datos de origen contengan, al menos, la siguiente información:
- Un ID de cliente que se usa para diferenciar clientes individuales
- Un importe de la compra por cliente que muestre cuánto gastó un cliente en un momento específico
- Una fecha para cada compra
En este artículo, analizaremos cómo entrenar modelos mediante los datos de ventas históricos disponibles públicamente del conjunto de datos de venta minorista en línea de UCI Machine Learning Repository.[1]
El primer paso es copiar el conjunto de datos como un archivo CSV en Cloud Storage.
Luego, se crea una tabla con el nombre data_source con una de las herramientas de carga de BigQuery (este nombre es arbitrario, pero el código en el repositorio de GitHub lo usa). El conjunto de datos está disponible en un bucket público asociado a esta serie y ya se convirtió al formato CSV.
- En tu computadora o en Cloud Shell, ejecuta los comandos que se según se documenta en el Sección de configuración del archivo README en el repositorio de GitHub.
El conjunto de datos de ejemplo contiene los campos que se enumeran en la tabla siguiente. Para el método que se describe en este artículo, solo debes usar los campos en los que la columna Usados está configurada como Sí. Algunos campos no se usan de forma directa, pero ayudan a crear campos nuevos, por ejemplo, UnitPrice y Quantity crean order_value.
| Usado | Campo | Tipo | Descripción |
|---|---|---|---|
| No | InvoiceNo |
STRING |
Nominal. Un número entero de 6 dígitos asignado de forma única a cada transacción.
Si este código comienza con la letra c, indica una cancelación. |
| No | StockCode |
STRING |
Código de producto (artículo) Nominal, un número entero de 5 dígitos asignado de manera única a cada uno de los productos |
| No | Description |
STRING |
Nombre del producto (artículo). Nominal. |
| Sí | Quantity |
INTEGER |
Las cantidades de cada producto (artículo) por transacción. Numérico. |
| Sí | InvoiceDate |
STRING |
Fecha y hora de la factura en formato mm/dd/aa hh:mm El día y la hora en que se generó cada transacción |
| Sí | UnitPrice |
FLOAT |
Precio unitario. Numérico. El precio del producto por unidad en libras esterlinas. |
| Sí | CustomerID |
STRING |
Número de cliente. Nominal. Un número entero de 5 dígitos asignado de forma única a cada cliente |
| No | Country |
STRING |
Nombre del país. Nominal. El nombre del país en el que reside cada cliente |
Limpia los datos
Sin importar el modelo que uses, debes llevar a cabo un conjunto de pasos de preparación y limpieza comunes a todos los modelos. Se requieren las operaciones siguientes a fin de obtener un conjunto de campos y registros posibles:
- Agrupa los pedidos por día, en lugar de usar
InvoiceNo, ya que la unidad mínima de tiempo que usan los modelos probabilísticos en esta solución es de un día. - Conserva solo los campos que sean útiles para los modelos probabilísticos.
- Mantén solo los registros que tengan cantidades positivas de pedidos y valores monetarios, como las compras.
- Mantén solo los registros con cantidades negativas de pedido, como las devoluciones.
- Mantén solo los registros con un ID de cliente.
- Mantén solo a los clientes que realizaron compras en los últimos 90 días.
- Mantén solo a los clientes que realizaron compras al menos dos veces durante el período que se usa para crear los atributos.
Puedes realizar todas estas operaciones con la siguiente consulta de BigQuery (al igual que con los comandos anteriores, este código se ejecuta donde clonaste el repositorio de GitHub). Debido a que los datos son antiguos, la fecha del 12 de diciembre de 2011 se considera la fecha del día de hoy para los fines de este artículo.
Esta consulta realiza dos tareas. Primero, si el conjunto de datos de trabajo es grande, la consulta lo reduce (el conjunto de datos de trabajo para esta solución es bastante pequeño, pero esta consulta puede reducir un conjunto de datos muy grande en dos pedidos de magnitud en unos segundos).
En segundo lugar, la consulta crea un conjunto de datos base para trabajar que se ve de la siguiente manera:
customer_id
|
order_date
|
order_value
|
order_qty_articles
|
|---|---|---|---|
| 16915 | 4/8/2011 | 173.7 | 6 |
| 15349 | 4/7/2011 | 107.7 | 77 |
| 14794 | 30/3/2011 | -33.9 | -2 |
El conjunto de datos que se limpió también contiene el campo order_qty_articles. Este campo se incluye solo para que lo use la red neuronal profunda (DNN) que se describe en la sección siguiente.
Define los intervalos de entrenamiento y objetivo
Si quieres prepararte para entrenar los modelos, debes elegir una fecha límite. Esa fecha separa los pedidos en dos particiones:
- Los pedidos anteriores a la fecha límite se usan para entrenar el modelo.
- Los pedidos posteriores a la fecha límite se usan para calcular el valor de segmentación.

La biblioteca de Lifetimes incluye los métodos para el procesamiento de los datos. Sin embargo, los conjuntos de datos que uses para CVC pueden ser muy grandes, por lo que no resulta práctico realizar el preprocesamiento de datos en una sola máquina. El método que se describe en este artículo usa consultas que se ejecutan de forma directa en BigQuery para dividir los pedidos en dos conjuntos. El AA y los modelos probabilísticos usan las mismas consultas, lo que garantiza que ambos modelos trabajen con los mismos datos.
La fecha límite óptima podría variar para los modelos de AA y los probabilísticos. Puedes actualizar este valor de fecha directo en la instrucción de SQL. Considera la fecha límite óptima como un hiperparámetro. Para encontrar el valor más apropiado, explora los datos y ejecuta algunos entrenamientos de prueba.
La fecha límite se usa en la cláusula WHERE de la consulta de SQL que selecciona los datos de entrenamiento de la tabla de datos limpia, como se muestra en el ejemplo siguiente:
Agrega datos
Después de dividir los datos en intervalos de entrenamiento y objetivo, debes agregarlos a fin de crear características y orientaciones reales para cada cliente. Para los modelos probabilísticos, la agregación se limita a los campos de las compras recientes, la frecuencia y el monetario (RFM). Para los modelos de DNN, los modelos también usan características de RFM, pero pueden usar características adicionales para realizar mejores predicciones.
La consulta siguiente muestra cómo crear características para DNN y modelos probabilísticos al mismo tiempo:
En la siguiente tabla, se enumeran las características que crea la consulta.
| Nombre de la característica | Descripción | Probabilístico | DNN |
|---|---|---|---|
monetary_dnn
|
La suma de los valores monetarios de todos los pedidos por cliente durante el período de atributos. | x | |
monetary_btyd
|
El promedio de los valores monetarios de todos los pedidos de cada cliente durante el período de atributos. Los modelos probabilísticos suponen que el valor del primer pedido es 0. La solicitud aplica esto. | x | |
recency
|
El tiempo transcurrido entre el primer y el último pedido que realizó un cliente durante el período de atributos. | x | |
frequency_dnn
|
La cantidad de pedidos que realizó un cliente durante el período de características. | x | |
frequency_btyd
|
La cantidad de pedidos que realizó un cliente durante el período de atributos menos el primero | x | |
T
|
El tiempo transcurrido entre el primer pedido que realizó un cliente y el final del período de atributos | x | x |
time_between
|
El tiempo promedio que transcurre entre los pedidos de un cliente durante el período de atributos | x | |
avg_basket_value
|
El valor monetario promedio de la cesta de compra del cliente durante el período de atributos. | x | |
avg_basket_size
|
La cantidad de artículos que el cliente tiene en promedio en su cesta durante el período de atributos | x | |
cnt_returns
|
La cantidad de pedidos que el cliente devolvió durante el período de atributos | x | |
has_returned
|
Si el cliente devolvió al menos un pedido durante el período de atributos | x | |
frequency_btyd_clipped
|
Igual que frequency_btyd, pero recortado por los valores atípicos límites. |
x | |
monetary_btyd_clipped
|
Igual que monetary_btyd, pero recortado por los valores atípicos límites. |
x | |
target_monetary_clipped
|
Igual que target_monetary, pero recortado por los valores atípicos límites. |
x | |
target_monetary
|
El importe total que gastó un cliente, incluidos los períodos de entrenamiento y objetivos | x |
La selección de estas columnas se realiza en el código. Para los modelos probabilísticos, la selección se realiza mediante un DataFrame de Pandas:
Para los modelos de DNN, las características de TensorFlow se definen en el archivo context.py. Para estos modelos, se ignoran los siguientes atributos:
customer_id. Este es un valor único que no es útil como atributo.target_monetary. Este es el objetivo que el modelo debe predecir y, por lo tanto, no se usa como entrada.
Crea los conjuntos de entrenamiento, evaluación y prueba para DNN
Esta sección aplica solo a los modelos de DNN. Para entrenar un modelo de AA, debes usar tres conjuntos de datos que no se superpongan:
El conjunto de datos de entrenamiento (70-80%) se usa para obtener información sobre las ponderaciones a fin de reducir una función de pérdida. El entrenamiento continúa hasta que la función de pérdida ya no disminuye.
El conjunto de datos de evaluación (10–15%) se usa durante la fase de entrenamiento para evitar el sobreajuste, que es cuando un modelo funciona bien con los datos de entrenamiento, pero no se generaliza bien.
El conjunto de datos de prueba (10–15%) debe usarse solo una vez, después de que se haya completado todo el entrenamiento y la evaluación, a fin de realizar una medición final del rendimiento del modelo. Este conjunto de datos es uno que el modelo nunca vio durante el proceso de entrenamiento, por lo que proporciona una medida válida a nivel estadístico de la exactitud del modelo.
La consulta siguiente crea un conjunto de entrenamiento con alrededor del 70% de los datos. La consulta segrega los datos mediante la técnica siguiente:
- Se calcula un hash del ID de cliente, que genera un número entero.
- Se usa una operación de módulo para seleccionar los valores de hash que están por debajo de un umbral determinado.
Se usa el mismo concepto para el conjunto de evaluación y los conjuntos de prueba, en el que se conservan los datos que están por encima del límite.
Entrenamiento
Como se vio en la sección anterior, puedes usar modelos diferentes para intentar predecir el CVC. El código que se usa en este artículo se diseñó para que puedas decidir qué modelo usar. Debes elegir el modelo mediante el parámetro model_type que pasas a la secuencia de comandos de shell del entrenamiento siguiente. El código se encarga del resto.
El primer objetivo del entrenamiento es que ambos modelos puedan superar las comparativas básicas, que definimos a continuación. Si ambos tipos de modelos pueden superar esa tendencia (y deberían hacerlo), puedes comparar el rendimiento de cada tipo con el otro.
Comparativas de los modelos
Para propósitos de esta serie, se define una comparativa básica con los parámetros siguientes:
- Valor promedio de la cesta. Esto se calcula en todos los pedidos que se realizan antes de la fecha límite.
- Recuento del pedido Esto se calcula para el intervalo de entrenamientos en todos los pedidos que se realizan antes de la fecha límite.
- Multiplicador de recuento Esto se calcula en función de la proporción de la cantidad de días que transcurren antes de la fecha límite y la cantidad de días entre la fecha límite y ahora.
La comparativa supone de forma simple que la tasa de compras que establece un cliente durante el intervalo de entrenamiento permanece constante durante el intervalo objetivo. Por lo tanto, si un cliente realizó 6 compras durante 40 días, se supone que realizará 9 compras durante 60 días (60/40 * 6 = 9). Cuando se multiplica el multiplicador de recuentos, el recuento de pedidos y el valor promedio de la cesta de cada cliente, se obtiene un valor de segmentación simple previsto para ese cliente.
El error de la comparativa es la raíz cuadrada del error cuadrático medio (RMSE): el promedio de todos los clientes de la diferencia absoluta entre el valor de segmentación previsto y el real. El RMSE se calcula mediante la consulta siguiente en BigQuery:
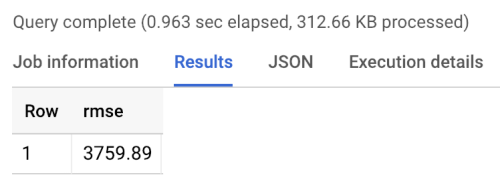
La comparativa muestra un RMSE de 3760, como se muestra en los resultados siguientes de ejecución de la comparativa. Los modelos deberían superar ese valor.
Modelos probabilísticos
Como se menciona en Parte 1 se usa una biblioteca de Python llamada Lifetimes que admite varios modelos, como la distribución binomial de Pareto/negativa (NBD) y modelos BG/NBD beta y geométricos. En el ejemplo de código siguiente, se muestra cómo usar la biblioteca Lifetimes para realizar predicciones de valor del ciclo de vida del cliente con modelos probabilísticos.
Para generar resultados de CVC mediante el modelo probabilístico en tu entorno local, puedes ejecutar la secuencia de comandos siguiente mltrain.sh. Debes proporcionar los parámetros para las fechas de inicio y finalización de la división del entrenamiento y el final del período de predicción.
./mltrain.sh local data --model_type paretonbd_model --threshold_date [YOUR_THRESHOLD_DATE] --predict_end [YOUR_END_DATE]
Modelos de DNN
El código de muestra incluye las implementaciones en TensorFlow de DNN con la clase de Estimator DNNRegressor prefabricada, así como un modelo Estimator personalizado. El DNNRegressor y el Estimator personalizado usan la misma cantidad de capas y de neuronas en cada capa. Esos valores son hiperparámetros que deben ajustarse. En el archivo siguiente task.py, encontrarás una lista de algunos de los hiperparámetros que se configuraron como valores y se probaron de forma manual y dieron buenos resultados.
Si usas AI Platform, puedes usar la ajuste de hiperparámetros atributo, que se probará en un rango de parámetros que definas en un archivo . AI Platform usa la Optimización bayesiana para buscar en el espacio de hiperparámetros.
Resultados de la comparación de modelos
En la tabla siguiente, se muestran los valores de RMSE para cada modelo, como se entrena en el conjunto de datos de muestra. Todos los modelos se entrenan con datos de RFM. Los valores de RMSE varían un poco entre las ejecuciones debido a la inicialización de parámetros aleatorios. El modelo de DNN usa atributos adicionales, como el valor promedio de la cesta y el recuento de devoluciones.
| Modelo | RMSE |
|---|---|
| DNN | 947.9 |
| BG/NBD | 1557 |
| Pareto/NBD | 1558 |
Los resultados muestran que en este conjunto de datos, el modelo de DNN obtiene un mejor rendimiento que los modelos probabilísticos cuando predice el valor monetario. Sin embargo, el tamaño un tanto pequeño del conjunto de datos de UCI limita la validez estadística de estos resultados. Debes probar cada una de las técnicas en tu conjunto de datos para ver cuál te brinda los mejores resultados. Todos los modelos se entrenaron con los mismos datos originales (incluido el ID de cliente, la fecha y el valor del pedido) en los valores RFM que se extrajeron de esos datos. Los datos de entrenamiento del DNN incluyeron algunas características adicionales, como el tamaño promedio de la cesta y el recuento de devoluciones.
El modelo de DNN da como resultado solo el valor monetario general del cliente. Si te interesa predecir la frecuencia o la deserción, debes realizar algunas tareas adicionales:
- Prepara los datos de manera diferente para cambiar el objetivo y, en lo posible, la fecha límite.
- Vuelve a entrenar un modelo de regresor a fin de predecir el objetivo que te interesa.
- Ajusta los hiperparámetros.
Lo que se intenta lograr es una comparación de los mismos atributos de entrada entre los dos tipos de modelos. Una de las ventajas de usar las DNN es que pueden mejorar los resultados si agregas más características que las que se usan en este ejemplo. Con las DNN, puedes aprovechar los datos de fuentes, como eventos de flujo de clics, perfiles de usuario o características del producto.
Agradecimientos
Dua, D. y Karra Taniskidou, E. (2017). UCI Machine Learning Repositoryhttp://archive.ics.uci.edu/ml. Irvine, CA: University of California, School of Information and Computer Science.
¿Qué sigue?
- Leído Parte 3: Implementa en producción de esta serie para entender cómo implementar esos modelos.
- Obtén más información sobre otras soluciones de previsión predictivas.
- Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.