Este artículo es la tercera parte de una serie de cuatro partes en la que se analiza cómo puedes predecir el valor del ciclo de vida del cliente (CVC) mediante AI Platform en Google Cloud.
Los artículos de esta serie son los siguientes:
- Parte 1: Introducción. Se presentan el CVC y dos técnicas de modelado para predecirlo.
- Parte 2: Entrena el modelo. Se analiza cómo preparar los datos y entrenar los modelos.
- Parte 3: Implementa en producción (este artículo). Se describe cómo implementar los modelos analizados en la Parte 2 en un sistema de producción.
- Parte 4: Usa tablas de AutoML. Se muestra cómo usar AutoML Tables para compilar un modelo a fin de implementarlo.
Instala el código
Si quieres seguir el proceso descrito en este artículo, debes instalar el código de muestra de GitHub.
Si tienes instalada la CLI de gcloud, abre una ventana de la terminal en tu computadora para ejecutar estos comandos. Si no tienes instalada la CLI de gcloud, abre una instancia de Cloud Shell.
Clona el repositorio de código de muestra:
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
Sigue las instrucciones de instalación en las secciones Instalación y Automatización del archivo README para implementar los componentes de la solución y configurar tu entorno. Esto incluye el conjunto de datos de ejemplo y el entorno de Cloud Composer.
En los ejemplos de comandos de las siguientes secciones se supone que completaste estos dos pasos.
Como parte de las instrucciones de instalación, configura variables para tu entorno como se describe en la sección de configuración del archivo README.
Cambia la variable REGION para que corresponda con la región de Google Cloud
que se encuentre geográficamente más cerca de ti. Para obtener una lista de regiones, consulta Regiones y zonas.
Implementación y arquitectura
En el siguiente diagrama, se muestra la arquitectura que se usa en esta discusión.

La arquitectura se divide en las siguientes funciones:
- Transferencia de datos: los datos se importan a BigQuery.
- Preparación de datos: los datos sin procesar se transforman para que los modelos puedan usarlos.
- Entrenamiento de modelos: los modelos se crean, entrenan y ajustan para que se puedan usar a fin de ejecutar predicciones.
- Deriva de predicciones: las predicciones sin conexión se almacenan y están disponibles con una latencia baja.
- Automatización: todas estas tareas se ejecutan y administran a través de Cloud Composer.
Transfiere datos
En esta serie de artículos, no se analiza una forma específica de realizar la transferencia de datos. BigQuery tiene muchas formas de transferir datos, lo que incluye servicios como Pub/Sub, Cloud Storage y el Servicio de transferencia de datos de BigQuery. Para obtener más información, consulta BigQuery para los profesionales de almacenes de datos. En el enfoque descrito en esta serie, se usa un conjunto de datos públicos. Importa este conjunto de datos a BigQuery, como se describe en el código de muestra en el archivo README.
Prepara datos
Para preparar los datos, ejecuta consultas en BigQuery como las que se muestran en la Parte 2 de esta serie. En una arquitectura de producción, debes ejecutar las consultas como parte de un grafo acíclico dirigido (DAG) de Apache Airflow. En la sección sobre automatización de este documento, se proporcionan más detalles sobre la ejecución de consultas para la preparación de datos.
Entrena el modelo en AI Platform
En esta sección, se proporciona una descripción general de la parte de entrenamiento de la arquitectura.
No importa qué tipo de modelo elijas, el código que se muestra en esta solución está empaquetado a fin de ejecutarse en AI Platform, para el entrenamiento y la predicción. AI Platform ofrece los siguientes beneficios:
- Se puede ejecutar de forma local o en la nube en un entorno distribuido.
- Ofrece conectividad integrada a otros productos de Google, como Cloud Storage.
- Para ejecutarlo, solo se necesitan pocos comandos.
- Facilita el ajuste de hiperparámetros.
- Se escala con cambios mínimos en la infraestructura, si es que los hay.
Para que AI Platform pueda entrenar y evaluar un modelo, debes proporcionar conjuntos de datos de entrenamiento, de evaluación y de prueba. Puedes crear los conjuntos de datos mediante la ejecución de consultas de SQL como las que se muestran en la parte 2 de esta serie. Puedes exportar esos conjuntos de datos de las tablas de BigQuery a Cloud Storage. En la arquitectura de producción descrita en este artículo, un DAG de Airflow ejecuta las consultas, lo que se describe con más detalle en la sección Automatización que aparece más adelante. Puedes ejecutar el DAG de forma manual como se describe en la sección Ejecuta DAG del archivo README.
Deriva de predicciones
Las predicciones se pueden crear en línea o sin conexión. Pero crear predicciones no es lo mismo que derivarlas. En este contexto de CVC, eventos como que un cliente acceda a un sitio web o visite una tienda minorista no afectarán de forma drástica el valor del ciclo de vida del cliente. Por lo tanto, las predicciones se pueden realizar sin conexión, incluso si los resultados deben presentarse en tiempo real. La predicción sin conexión tiene las siguientes características operativas:
- Puedes realizar los mismos pasos de procesamiento previo para el entrenamiento y la predicción. Si el entrenamiento y la predicción se procesan de manera diferente, las predicciones podrían ser menos precisas. Este fenómeno se denomina sesgo de entrenamiento y deriva.
- Puedes usar las mismas herramientas a fin de preparar los datos para el entrenamiento y la predicción. En el enfoque que se describe en esta serie, se usa principalmente BigQuery para preparar datos.
Puedes usar AI Platform para implementar el modelo y hacer predicciones sin conexión mediante un trabajo por lotes. Para la predicción, AI Platform facilita tareas como las siguientes:
- Administrar versiones
- Escalar con cambios mínimos de infraestructura
- Implementar a gran escala
- Interactuar con otros productos Google Cloud
- Proporcionar un ANS
En la tarea de predicción por lotes, se usan archivos que se almacenan en Cloud Storage para la entrada y la salida. Para el modelo de DNN, la siguiente función de deriva, definida en task.py, determina el formato de las entradas:
El formato de resultado de predicción se define en un EstimatorSpec que muestra la función de modelo del Estimador en este código de model.py:
Usa las predicciones
Una vez que hayas terminado de crear los modelos y de implementarlos, puedes usarlos para realizar predicciones de CVC. A continuación, se mencionan casos prácticos de CVC comunes:
- Un especialista en datos puede aprovechar las predicciones sin conexión cuando compila segmentos de usuarios.
- Tu organización puede hacer ofertas específicas en tiempo real, cuando un cliente interactúa con su marca en línea o en una tienda.
Estadísticas con BigQuery
Comprender el CVC es clave para las activaciones. En este artículo, se hace hincapié en el cálculo del valor del ciclo de vida del cliente en función de las ventas anteriores. Los datos de ventas suelen provenir de herramientas de administración de relaciones con clientes (CRM), pero la información sobre el comportamiento de los usuarios puede tener otras fuentes, como Google Analytics 360.
Debes usar BigQuery si te interesa realizar alguna de las siguientes tareas:
- Almacenar datos estructurados de muchas fuentes
- Transferir datos de forma automática desde herramientas de SaaS comunes como Google Analytics 360, YouTube o AdWords
- Ejecutar consultas ad hoc, incluidas las uniones en terabytes de datos del cliente
- Visualizar tus datos mediante herramientas de inteligencia empresarial líderes en la industria
Además de su función como un motor de consultas y almacenamiento administrado, BigQuery puede ejecutar algoritmos de aprendizaje automático de forma directa mediante BigQuery ML. Si cargas los valores de CVC de cada cliente en BigQuery, permites que ingenieros, científicos y analistas de datos aprovechen métricas adicionales en sus tareas. En el DAG de Airflow que se describe en la siguiente sección, se incluye una tarea para cargar las predicciones de CVC a BigQuery.
Deriva de latencia baja con Datastore
Las predicciones realizadas sin conexión a menudo se pueden volver a usar para ofrecer predicciones en tiempo real. Para esta situación, la actualidad de la predicción no es fundamental, pero obtener acceso a los datos en el momento adecuado y de manera apropiada sí lo es.
Almacenar la predicción sin conexión para la deriva en tiempo real significa que las acciones que realice un cliente no cambiarán su CVC de inmediato. Sin embargo, es importante obtener acceso a ese CVC con rapidez. Por ejemplo, puede que tu empresa quiera reaccionar rápido cuando un cliente use tu sitio web, haga una pregunta a tu equipo de asistencia o realice un pago a través de tu punto de venta. En casos como estos, una respuesta rápida puede mejorar tu relación con el cliente. Por lo tanto, almacenar el resultado de predicciones en una base de datos rápida y hacer que las consultas seguras estén disponibles en el frontend es clave para lograr el éxito.
Supongamos que tienes cientos de miles de clientes únicos. Datastore es una buena opción por los siguientes motivos:
- Admite bases de datos de documentos NoSQL.
- Proporciona acceso rápido a los datos mediante una clave (ID de cliente), pero también permite consultas de SQL.
- Se puede acceder a él a través de una API de REST.
- Está listo para usar, lo que significa que no hay sobrecarga de configuración.
- Se escala de forma automática.
Debido a que no hay forma de cargar directamente un conjunto de datos CSV a Datastore, en esta solución usamos Apache Beam en Dialogflow con una plantilla de JavaScript para cargar las predicciones de CVC a Datastore. En el siguiente fragmento de código de la plantilla de JavaScript, se muestra lo siguiente:
Cuando tus datos están en Datastore, puedes elegir cómo deseas interactuar con ellos, lo que puede incluir lo siguiente:
- Usar las bibliotecas cliente de Datastore desde tu app
- Compilar un extremo de API mediante Cloud Endpoints o la Plataforma de API de Apigee
- Usar Cloud Run Functions para tareas sin servidores
Automatiza la solución
Usa los pasos descritos hasta ahora cuando comiences con los datos para ejecutar los primeros pasos de procesamiento previo, entrenamiento y predicción. Sin embargo, tu plataforma aún no está lista para la producción, porque aún necesitas automatización y administración de fallas.
Algunas secuencias de comandos pueden ayudar a unir los pasos. Sin embargo, se recomienda automatizar los pasos con un administrador de flujo de trabajo. Apache Airflow es una herramienta de administración de flujos de trabajo popular, y puedes usar Cloud Composer para ejecutar una canalización de Airflow administrada en Google Cloud.
Airflow funciona con grafos acíclicos dirigidos (DAG), que te permiten especificar cada tarea y cómo se relaciona con otras. En el enfoque descrito en esta serie, debes ejecutar los siguientes pasos:
- Crea conjuntos de datos de BigQuery.
- Carga el conjunto de datos públicos de Cloud Storage a BigQuery.
- Limpia los datos de una tabla de BigQuery y escríbelos en una nueva.
- Crea características basadas en datos en una tabla de BigQuery y escríbelas en otra.
- Si el modelo es una red neuronal profunda (DNN), divide los datos en un conjunto de entrenamiento y un conjunto de evaluación en BigQuery.
- Exporta los conjuntos de datos a Cloud Storage y haz que estén disponibles en AI Platform.
- Haz que AI Platform entrene el modelo de forma periódica.
- Implementa el modelo actualizado en AI Platform.
- Ejecuta una predicción por lotes en los datos nuevos de forma periódica.
- Guarda en Datastore y BigQuery las predicciones que ya están guardadas en Cloud Storage.
Configura Cloud Composer
Para obtener información sobre cómo configurar Cloud Composer, consulta las instrucciones en el archivo README del repositorio de GitHub.
Grafos acíclicos dirigidos para esta solución
En esta solución se usan dos DAG. En el primer DAG, se incluyen los pasos del 1 al 8 de la secuencia que se mencionó antes:
En el siguiente diagrama, se muestra la IU de Cloud Composer/Airflow, en la que se resumen los pasos del 1 al 8 del DAG de Airflow.
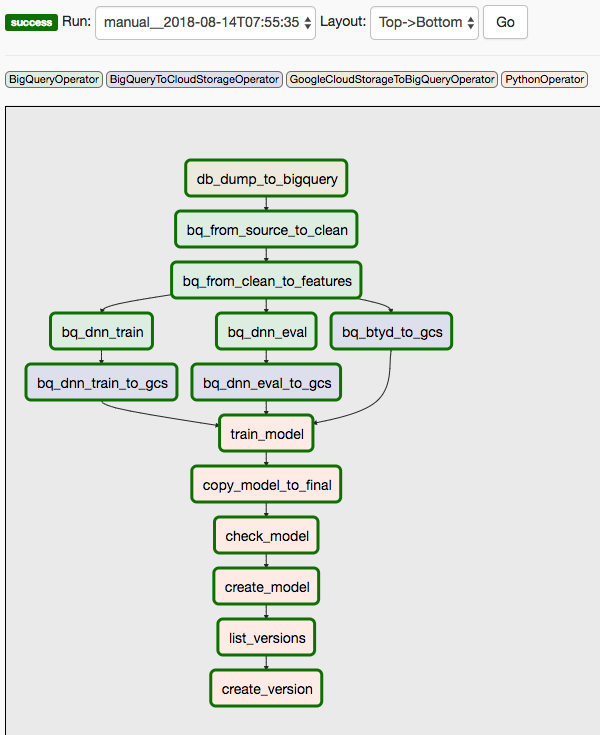
En el segundo DAG, se incluyen los pasos 9 y 10.
En el siguiente diagrama, se resumen los pasos 9 y 10 del proceso de DAG de Airflow.
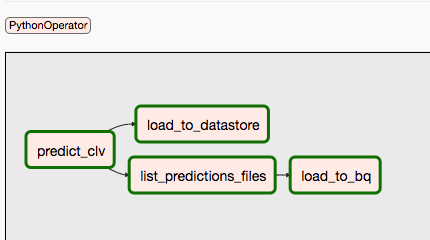
Los DAG están separados porque las predicciones y el entrenamiento pueden realizarse de forma independiente y en un horario distinto. Por ejemplo, puedes hacer lo siguiente:
- Predecir datos a diario sobre clientes nuevos o existentes
- Volver a entrenar el modelo cada semana para incorporar datos nuevos o activarlo después de que se reciba una cantidad específica de transacciones nuevas
Para activar el primer DAG de forma manual, puedes ejecutar el comando desde la sección Run Dags del archivo README en Cloud Shell o mediante la CLI de gcloud.
El parámetro conf pasa variables a diferentes partes de la automatización. Por ejemplo, en la siguiente consulta de SQL que se usa a fin de extraer características de los datos limpios, las variables se usan para parametrizar la cláusula FROM:
Puedes activar el segundo DAG mediante un comando similar. Para obtener más detalles, consulta el archivo README en el repositorio de GitHub.
¿Qué sigue?
- Ejecuta el ejemplo completo en el repositorio de GitHub.
- Incorpora características nuevas en el modelo de CVC con uno de los siguientes elementos:
- Datos de flujo de clics, que pueden ayudarte a predecir el CVC para clientes de los que no tienes datos históricos.
- Departamentos y categorías de productos que pueden agregar un contexto adicional y que podrían ayudar a la red neuronal.
- Características nuevas que creas con las mismas entradas que se usan en esta solución. Los ejemplos podrían ser tendencias de ventas de las últimas semanas o meses antes de la fecha límite.
- Consulta la Parte 4: usa AutoML Tables para el modelo
- Obtén más información sobre otras soluciones de previsión predictivas.
- Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.