Este artículo es la cuarta parte de una serie de cuatro en la que se analiza cómo puedes predecir el valor del ciclo de vida del cliente (CVC) mediante AI Platform en Google Cloud. En este artículo, se muestra cómo usar AutoML Tables para realizar las predicciones.
Los artículos de esta serie son los siguientes:
- Parte 1: Introducción. Se presentan el CVC y dos técnicas de modelado para predecirlo.
- Parte 2: Entrena el modelo Se analiza cómo preparar los datos y entrenar los modelos.
- Parte 3: Implementa en producción. Se describe cómo implementar los modelos analizados en la Parte 2 en un sistema de producción.
- Parte 4: Uso de tablas de AutoML (este artículo). Se muestra cómo usar AutoML Tables para compilar un modelo a fin de implementarlo.
El proceso descrito en este artículo se basa en los mismos pasos de procesamiento de datos en BigQuery que se describen en la Parte 2 de la serie. En este artículo, se muestra cómo subir ese conjunto de datos de BigQuery a AutoML Tables y crear un modelo. También se muestra cómo integrar el modelo de AutoML en el sistema de producción que se describe en la Parte 3.
El código para implementar este sistema está en el mismo repositorio de GitHub que la serie original. En este artículo, se describe cómo usar el código para AutoML Tables en ese repositorio.
Ventajas de AutoML Tables
En las partes anteriores de la serie, se vio cómo predecir el CVC con un modelo estadístico y un modelo DNN implementado en TensorFlow. AutoML Tables tiene varias ventajas sobre los otros dos métodos:
- No se requiere codificación para crear el modelo. Hay una IU de consola que te permite crear, entrenar, administrar y, luego, implementar tus conjuntos de datos y modelos.
- Agregar o cambiar funciones es fácil y se puede hacer de forma directa en la interfaz de la consola.
- El proceso de entrenamiento es automático, incluido el ajuste de hiperparámetros.
- AutoML Tables busca la mejor arquitectura para tu conjunto de datos, lo que te libera de la necesidad de elegir entre las muchas opciones disponibles.
- AutoML Tables proporciona un análisis detallado del rendimiento de un modelo entrenado, incluida la importancia de las características.
Como resultado, puede ser más rápido y barato desarrollar y entrenar un modelo con optimización completa si se usa AutoML Tables.
Una implementación de producción de una solución de AutoML Tables requiere que uses la API de cliente de Python para crear modelos, implementarlos y ejecutar predicciones. En este artículo, se muestra cómo crear y entrenar modelos de AutoML Tables con la API del cliente. Para obtener orientación sobre cómo seguir estos pasos con la consola de AutoML Tables, consulta la documentación de AutoML Tables.
Instala el código
Si no instalaste el código de la serie original, sigue los mismos pasos descritos en la Parte 2 de la serie original para instalar el código. En el archivo README del repositorio de GitHub, se describen todos los pasos necesarios para preparar tu entorno, instalar el código y configurar AutoML Tables en tu proyecto.
Si ya instalaste el código, debes seguir estos pasos adicionales a fin de completar la instalación para este artículo:
- Habilita la API de AutoML Tables en tu proyecto.
- Activa el entorno de miniconda que instalaste antes.
- Instala la biblioteca cliente de Python como se describe en la documentación de AutoML Tables.
- Crea y descarga un archivo de claves de API y guárdalo en una ubicación conocida para usarlo más adelante con la biblioteca cliente.
Ejecuta el código
Para muchos de los pasos de este artículo, debes ejecutar comandos de Python. Después de preparar tu entorno y de instalar el código, tienes las siguientes opciones para la llevar a cabo la ejecución del código:
Ejecuta el código en un notebook de Jupyter. Desde la ventana de la terminal en tu entorno de miniconda activado, ejecuta el comando siguiente:
$ (clv) jupyter notebook
El código para cada uno de los pasos de este artículo está en un notebook llamado
notebooks/clv_automl.ipynben el repositorio de código. Abre este notebook en la interfaz de Jupyter. Luego, puedes ejecutar cada uno de los pasos a medida que sigues el instructivo.Ejecuta el código como una secuencia de comandos de Python. Los pasos del código para este instructivo están en el repositorio del código del archivo
clv_automl/clv_automl.py. La secuencia de comandos toma argumentos en la línea de comandos para parámetros configurables, como el ID del proyecto, la ubicación del archivo de claves de API, la región de Google Cloud y el nombre del conjunto de datos de BigQuery. Debes ejecutar la secuencia de comandos desde la ventana de la terminal en tu entorno de miniconda activado y reemplazar el nombre de tu Google Cloud proyecto por[YOUR_PROJECT]:$ (clv) cd clv_automl $ (clv) python clv_automl.py --project_id [YOUR_PROJECT]
Para ver la lista completa de parámetros y valores predeterminados, consulta el método
create_parseren la secuencia de comandos o ejecuta esta última sin argumentos para ver la documentación de uso.Después de instalar el entorno de Cloud Composer como se describe en el archivo README, ejecuta el código mediante la ejecución de los DAG, como se describe más adelante en Ejecuta los DAG.
Prepara los datos
En este artículo, se usa el mismo conjunto de datos y pasos de preparación de datos en BigQuery que se describen en la Parte 2 de la serie original. Una vez que completes la agregación de datos como se describe en ese artículo, estarás listo para crear un conjunto de datos que se usará con AutoML Tables.
Crea el conjunto de datos de AutoML Tables
Para comenzar, sube los datos que preparaste en BigQuery a AutoML Tables.
Para inicializar el cliente, cambia el nombre del archivo de claves al nombre del archivo que descargaste en el paso de instalación:
keyfile_name = "mykey.json" client = automl_v1beta1.AutoMlClient.from_service_account_file(keyfile_name)Crea el conjunto de datos:
create_dataset_response = client.create_dataset( location_path, {'display_name': dataset_display_name, 'tables_dataset_metadata': {}}) dataset_name = create_dataset_response.name
Importa los datos de BigQuery
Después de crear el conjunto de datos, puedes importar los datos de BigQuery.
Importa los datos de BigQuery al conjunto de datos de AutoML Tables:
dataset_bq_input_uri = 'bq://{}.{}.{}'.format(args.project_id, args.bq_dataset, args.bq_table) input_config = { 'bigquery_source': { 'input_uri': dataset_bq_input_uri}} import_data_response = client.import_data(dataset_name, input_config)
Entrena el modelo
Después de crear el conjunto de datos de AutoML para los datos de CLV, puedes crear el modelo de AutoML Tables.
Obtén las especificaciones de columna de AutoML Tables para cada columna del conjunto de datos:
list_table_specs_response = client.list_table_specs(dataset_name) table_specs = [s for s in list_table_specs_response] table_spec_name = table_specs[0].name list_column_specs_response = client.list_column_specs(table_spec_name) column_specs = {s.display_name: s for s in list_column_specs_response}Las especificaciones de columna son necesarias en los pasos posteriores.
Asigna una de las columnas como etiqueta para el modelo de AutoML Tables:
TARGET_LABEL = 'target_monetary' ... label_column_name = TARGET_LABEL label_column_spec = column_specs[label_column_name] label_column_id = label_column_spec.name.rsplit('/', 1)[-1] update_dataset_dict = { 'name': dataset_name, 'tables_dataset_metadata': { 'target_column_spec_id': label_column_id } } update_dataset_response = client.update_dataset(update_dataset_dict)En este código, se usa la misma columna de etiqueta (
target_monetary) que en el modelo DNN de TensorFlow en la Parte 2.Define las funciones para entrenar el modelo:
feat_list = list(column_specs.keys()) feat_list.remove('target_monetary') feat_list.remove('customer_id') feat_list.remove('monetary_btyd') feat_list.remove('frequency_btyd') feat_list.remove('frequency_btyd_clipped') feat_list.remove('monetary_btyd_clipped') feat_list.remove('target_monetary_clipped')Las características usadas a fin de entrenar el modelo de AutoML Tables son las mismas que se usan para entrenar el modelo de DNN de TensorFlow en la Parte 2 de la serie original. Sin embargo, sumar o restar características del modelo es mucho más fácil con AutoML Tables. Después de crear una característica en BigQuery, se incluye de forma automática en el modelo, a menos que la quites de manera explícita como se muestra en el fragmento de código anterior.
Define las opciones para crear el modelo. Para este conjunto de datos, se recomienda el objetivo de optimización de minimizar el error absoluto medio, representado por el parámetro
MINIMIZE_MAE.model_display_name = args.automl_model model_training_budget = args.training_budget * 1000 model_dict = { 'display_name': model_display_name, 'dataset_id': dataset_name.rsplit('/', 1)[-1], 'tables_model_metadata': { 'target_column_spec': column_specs['target_monetary'], 'input_feature_column_specs': [ column_specs[x] for x in feat_list], 'train_budget_milli_node_hours': model_training_budget, 'optimization_objective': 'MINIMIZE_MAE' } }Para obtener más información, consulta la documentación de AutoML Tables sobre los objetivos de optimización.
Crea el modelo y comienza el entrenamiento:
create_model_response = client.create_model(location_path, model_dict) create_model_result = create_model_response.result() model_name = create_model_result.nameEl valor de retorno de la llamada del cliente (
create_model_response) se muestra de inmediato. El valorcreate_model_response.result()es una promesa que se bloquea hasta que se complete el entrenamiento. El valormodel_namees una ruta de acceso a recursos necesaria para otras llamadas de clientes que operen en el modelo.
Evalúa el modelo
Una vez completado el entrenamiento del modelo, puedes recuperar las estadísticas de evaluación del modelo. Puedes usar Google Cloud console o la API del cliente.
Para usar la consola, en la consola de AutoML Tables, ve a la pestaña Evaluar:

Para usar la API del cliente, recupera las estadísticas de evaluación del modelo:
model_evaluations = [e for e in client.list_model_evaluations(model_name)] model_evaluation = model_evaluations[0]Verás un resultado similar a este:
name: "projects/595920091534/locations/us-central1/models/TBL3912308662231629824/modelEvaluations/9140437057533851929" create_time { seconds: 1553108019 nanos: 804478000 } evaluated_example_count: 125 regression_evaluation_metrics: { mean_absolute_error: 591.091 root_mean_squared_error: 853.481 mean_absolute_percentage_error: 21.47 r_squared: 0.907 }
El error de la raíz cuadrada de la media de 853.481 se compara de forma favorable con los modelos probabilísticos y de TensorFlow usados en la serie original. Sin embargo, como se explicó en la Parte 2, es recomendable probar cada una de las técnicas proporcionadas con tus datos para ver cuál tiene el mejor rendimiento.
Implementa el modelo de AutoML
Los DAG de Cloud Composer de la serie original se actualizaron a fin de incluir el modelo de AutoML Tables para capacitación y predicción. Para obtener información general sobre el funcionamiento de los DAG de Cloud Composer, consulta la sección sobre automatización de la solución en la Parte 3 de los artículos originales.
Puedes instalar el sistema de organización de Cloud Composer para esta solución si sigues las instrucciones del archivo README.
Los DAG actualizados llaman a los métodos de la secuencia de comandos clv_automl/clv_automl.py que replican las llamadas de código del cliente antes mostradas para crear el modelo y ejecutar predicciones.
El DAG de entrenamiento
El DAG actualizado para el entrenamiento incluye tareas que crean un modelo de AutoML Tables. En el diagrama siguiente, se muestra el nuevo DAG para el entrenamiento.

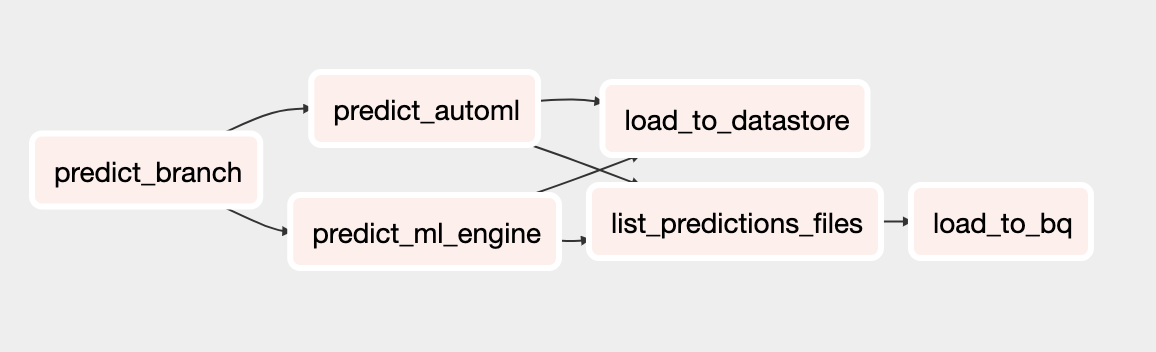
DAG de predicción
El DAG actualizado para la predicción incluye tareas que ejecutan predicciones por lotes con el modelo de AutoML Tables. En el diagrama siguiente, se muestra el DAG nuevo para las predicciones.
Ejecuta los DAG
Para activar los DAG de forma manual, puedes ejecutar los comandos desde la sección Run Dags del archivo README en Cloud Shell o mediante la CLI de Google Cloud.
Ejecuta el DAG
build_train_deploy:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ build_train_deploy \ --conf '{"model_type":"automl", "project":"'${PROJECT}'", "dataset":"'${DATASET_NAME}'", "threshold_date":"2011-08-08", "predict_end":"2011-12-12", "model_name":"automl_airflow", "model_version":"v1", "max_monetary":"15000"}'Ejecuta el DAG
predict_serve:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ predict_serve \ --conf '{"model_name":"automl_airflow", "model_version":"v1", "dataset":"'${DATASET_NAME}'"}'
¿Qué sigue?
- Revisa el conjunto completo de instructivos de CVC.
- Ejecuta el ejemplo completo en el repositorio de GitHub.
- Obtén más información sobre otras soluciones de previsión predictivas.
- Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.