架構
下圖顯示無伺服器擷取、載入及轉換 (ELT) 管道的整體架構,該管道使用 Workflows。

在上圖中,假設零售平台會定期從各家商店收集銷售事件做為檔案,然後將檔案寫入 Cloud Storage bucket。這些事件會匯入 BigQuery 並經過處理,以提供業務指標。這個架構提供可靠的無伺服器協調系統,可將檔案匯入 BigQuery,並分為下列兩個模組:
- 檔案清單:維護 Firestore 集合中新增至 Cloud Storage 值區的未處理檔案清單。這個模組會透過 Cloud Run 函式運作,並由「物件完成」儲存空間事件觸發,當新檔案新增至 Cloud Storage bucket 時,就會產生這個事件。檔案名稱會附加至 Firestore 中名為
new的集合陣列。files 工作流程:執行排定的工作流程。Cloud Scheduler 會觸發工作流程,根據 YAML 語法執行一系列步驟,協調載入作業,然後呼叫 Cloud Run 函式,轉換 BigQuery 中的資料。工作流程中的步驟會呼叫 Cloud Run functions,執行下列工作:
- 建立並啟動 BigQuery 載入工作。
- 輪詢載入工作狀態。
- 建立並啟動轉換查詢工作。
- 輪詢轉換工作狀態。
使用交易在 Firestore 中維護新檔案清單,有助於確保工作流程將檔案匯入 BigQuery 時不會遺漏任何檔案。工作流程的個別執行作業會將工作的中繼資料和狀態儲存在 Firestore 中,藉此確保冪等性。
準備環境
如要準備環境,請建立 Firestore 資料庫、從 GitHub 存放區複製程式碼範例、使用 Terraform 建立資源、編輯 Workflows YAML 檔案,以及安裝檔案產生器的必要條件。
如要建立 Firestore 資料庫,請按照下列步驟操作:
前往 Google Cloud 控制台的 Firestore 頁面。
按一下「選取原生模式」。
在「選取位置」選單中,選取要代管 Firestore 資料庫的區域。建議選擇靠近您實際位置的區域。
按一下 [Create database] (建立資料庫)。
在 Cloud Shell 中,複製來源存放區:
cd $HOME && git clone https://github.com/GoogleCloudPlatform/workflows-demos cd workflows-demos/workflows-bigquery-load在 Cloud Shell 中,使用 Terraform 建立下列資源:
terraform init terraform apply \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approve更改下列內容:
PROJECT_ID:您的 Google Cloud 專案 IDREGION:用於代管資源的特定 Google Cloud 地理位置,例如us-central1ZONE:區域內用於代管資源的位置,例如us-central1-b
畫面會顯示類似以下的訊息:
Apply complete! Resources: 7 added, 0 changed, 1 destroyed.Terraform 可協助您以安全且可預測的方式,大規模建立、變更及升級基礎架構。專案中會建立下列資源:
- 服務帳戶:具備必要權限,確保資源存取安全無虞。
- 名為
serverless_elt_dataset的 BigQuery 資料集和名為word_count的資料表,用於載入傳入的檔案。 - 名為
${project_id}-ordersbucket的 Cloud Storage bucket,用於暫存輸入檔案。 - 下列五個 Cloud Run 函式:
file_add_handler會將新增至 Cloud Storage bucket 的檔案名稱新增至 Firestore 集合。create_job會建立新的 BigQuery 載入工作,並將 Firebase 集合中的檔案與該工作建立關聯。create_query會建立新的 BigQuery 查詢工作。poll_bigquery_job會取得 BigQuery 工作的狀態。run_bigquery_job會啟動 BigQuery 工作。
取得您在上一個步驟中部署的
create_job、create_query、poll_job和run_bigquery_jobCloud Run 函式網址。gcloud functions describe create_job | grep url gcloud functions describe poll_bigquery_job | grep url gcloud functions describe run_bigquery_job | grep url gcloud functions describe create_query | grep url
輸出結果會與下列內容相似:
url: https://REGION-PROJECT_ID.cloudfunctions.net/create_job url: https://REGION-PROJECT_ID.cloudfunctions.net/poll_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/run_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/create_query
請記下這些網址,部署工作流程時會用到。
建立及部署工作流程
在 Cloud Shell 中開啟工作流程的來源檔案:
workflow.yaml:更改下列內容:
CREATE_JOB_URL:用於建立新工作的函式網址POLL_BIGQUERY_JOB_URL:輪詢執行中作業狀態的函式網址RUN_BIGQUERY_JOB_URL:啟動 BigQuery 載入工作的函式網址CREATE_QUERY_URL:啟動 BigQuery 查詢工作的函式網址BQ_REGION:資料儲存的 BigQuery 區域,例如USBQ_DATASET_TABLE_NAME:BigQuery 資料集資料表名稱,格式為PROJECT_ID.serverless_elt_dataset.word_count
部署
workflow檔案:gcloud workflows deploy WORKFLOW_NAME \ --location=WORKFLOW_REGION \ --description='WORKFLOW_DESCRIPTION' \ --service-account=workflow-runner@PROJECT_ID.iam.gserviceaccount.com \ --source=workflow.yaml更改下列內容:
WORKFLOW_NAME:工作流程的專屬名稱WORKFLOW_REGION:工作流程部署所在的區域,例如us-central1WORKFLOW_DESCRIPTION:工作流程的說明
建立 Python 3 虛擬環境,並安裝檔案產生器的必要條件:
sudo apt-get install -y python3-venv python3 -m venv env . env/bin/activate cd generator pip install -r requirements.txt
產生要匯入的檔案
gen.py Python 指令碼會以 Avro 格式產生隨機內容。結構定義與 BigQuery word_count 資料表相同。這些 Avro 檔案會複製到指定的 Cloud Storage bucket。
在 Cloud Shell 中產生檔案:
python gen.py -p PROJECT_ID \
-o PROJECT_ID-ordersbucket \
-n RECORDS_PER_FILE \
-f NUM_FILES \
-x FILE_PREFIX
更改下列內容:
RECORDS_PER_FILE:單一檔案中的記錄數NUM_FILES:要上傳的檔案總數FILE_PREFIX:產生檔案名稱的前置字串
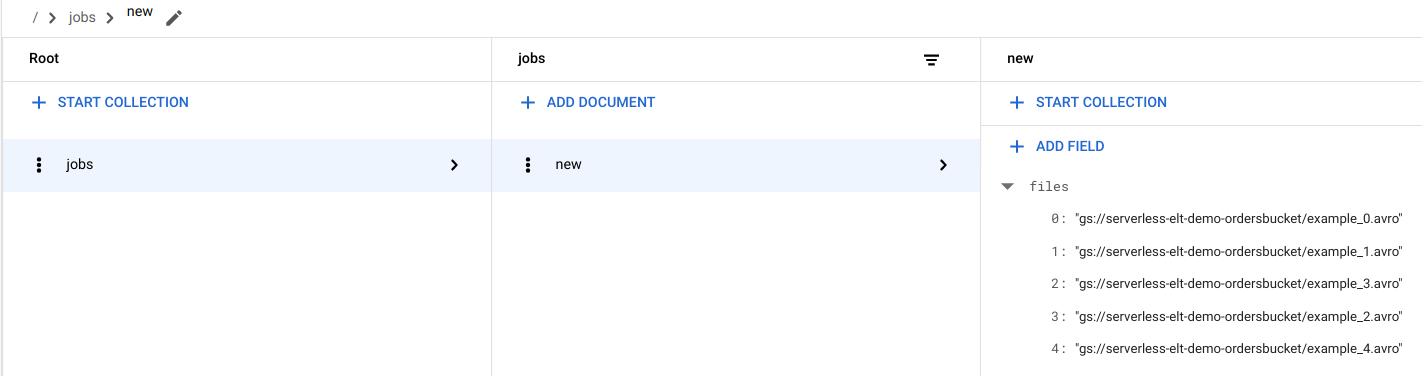
在 Firestore 中查看檔案項目
檔案複製到 Cloud Storage 時,會觸發 handle_new_file Cloud Run 函式。這個函式會將檔案清單新增至 Firestore jobs 集合中 new 文件內的檔案清單陣列。
如要查看檔案清單,請前往 Google Cloud 控制台的 Firestore「資料」頁面。
觸發工作流程
Workflows 會將一系列無伺服器工作串連在一起,這些工作來自Google Cloud 和 API 服務。這項工作流程中的個別步驟會以 Cloud Run 函式執行,狀態則儲存在 Firestore 中。所有對 Cloud Run 函式的呼叫都會使用工作流程的服務帳戶進行驗證。
在 Cloud Shell 中執行工作流程:
gcloud workflows execute WORKFLOW_NAME
下圖顯示工作流程中使用的步驟:

工作流程分為兩部分:主要工作流程和子工作流程。 主要工作流程會處理工作建立和條件式執行作業,而子工作流程則會執行 BigQuery 工作。工作流程會執行下列作業:
create_jobCloud Run 函式會建立新的工作物件、從 Firestore 文件取得新增至 Cloud Storage 的檔案清單,並將檔案與載入工作建立關聯。如果沒有要載入的檔案,函式就不會建立新工作。create_queryCloud Run 函式會接收需要執行的查詢,以及查詢應執行的 BigQuery 區域。函式會在 Firestore 中建立工作,並傳回工作 ID。run_bigquery_jobCloud Run 函式會取得需要執行的工作 ID,然後呼叫 BigQuery API 提交工作。- 您不必等待 Cloud Run 函式完成工作,可以定期輪詢工作狀態。
查看工作狀態
您可以查看檔案清單和工作狀態。
前往Google Cloud 控制台的 Firestore「資料」頁面。
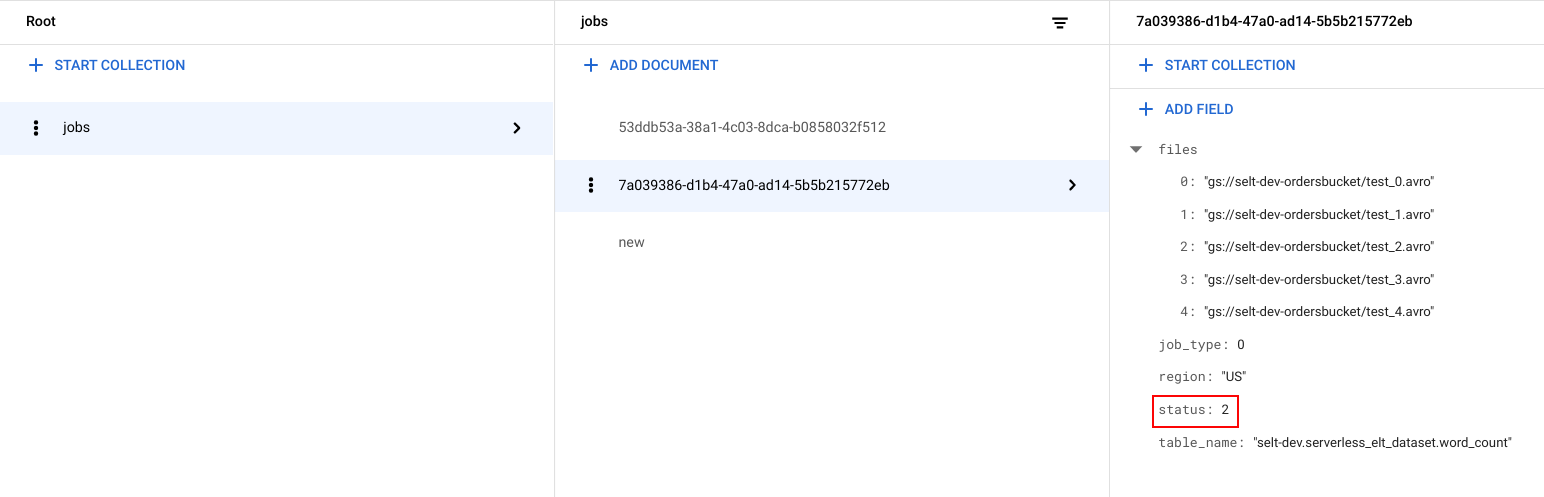
系統會為每項工作產生專屬 ID (UUID)。如要查看
job_type和status,請按一下工作 ID。每項工作可能會有下列其中一種類型和狀態:job_type:工作流程執行的工作類型,可使用下列其中一個值:- 0:將資料載入 BigQuery。
- 1:在 BigQuery 中執行查詢。
status:工作目前的狀態,可能的值如下:- 0:工作已建立,但尚未啟動。
- 1:工作正在執行。
- 2:工作已順利執行完畢。
- 3:發生錯誤,工作未順利完成。
工作物件也包含中繼資料屬性,例如 BigQuery 資料集所屬的區域、BigQuery 資料表的名稱,以及 (如果是查詢工作) 執行的查詢字串。
查看 BigQuery 中的資料
如要確認 ELT 工作是否成功,請確認資料是否顯示在資料表中。
前往 Google Cloud 控制台的「BigQuery 編輯器」頁面。
按一下「
serverless_elt_dataset.word_count」資料表。按一下「預覽」分頁標籤。

排定工作流程
如要依排程定期執行工作流程,可以使用 Cloud Scheduler。