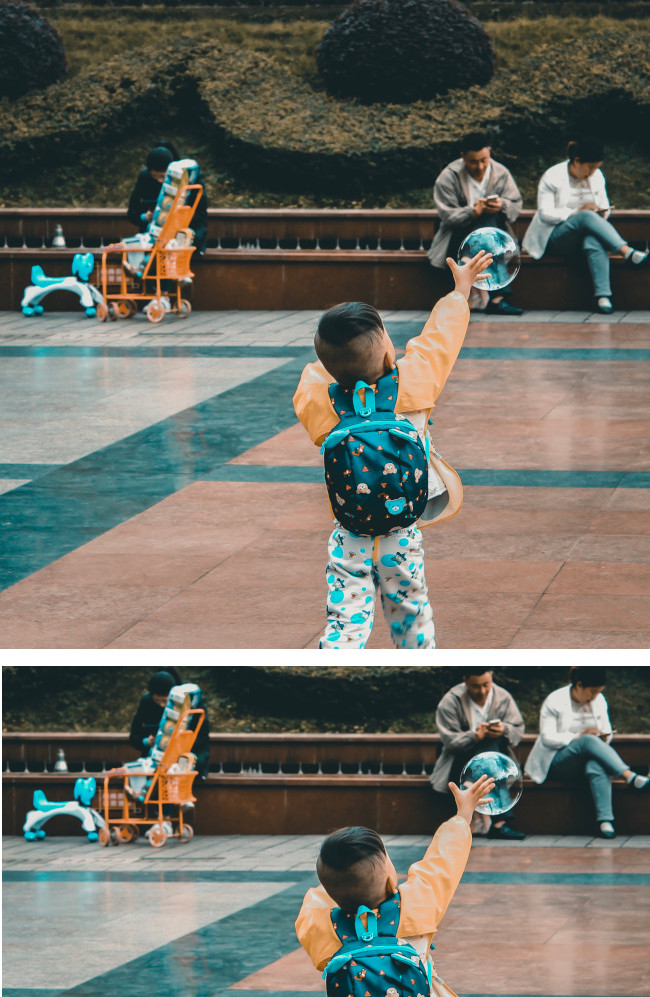Optical character recognition (OCR) for an image; text recognition and
conversion to machine-coded text. Identifies and extracts UTF-8 text in an
image.
Images: Optimized for sparse areas of text within a
larger image.
Response: Returns both a list of words identifed with text,
bounding boxes, and textAnnotations, as well as the structural
hierarchy for the OCR detected
text (fullTextAnnotation).
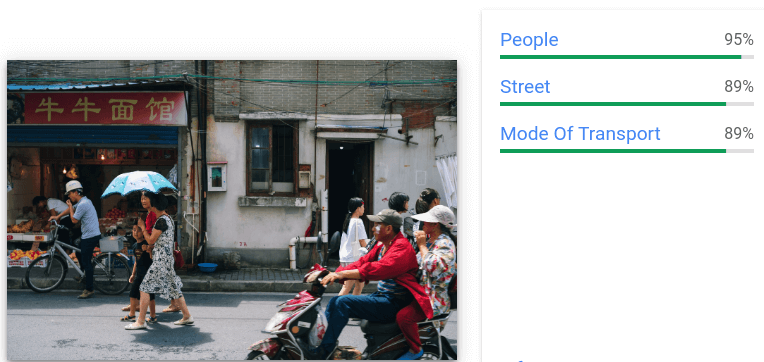
Provides general label and bounding box annotations for multiple objects
recognized in a single image.
For each object detected the following elements are returned: a textual
description, a confidence score, and normalized vertices [0,1] for
the bounding polygon around the object.
Provides a bounding polygon for the cropped image, a confidence score,
and an importance fraction of this salient region with respect to the
original image for each request.
You can provide up to 16 image ratio values (width:height)
for a single image.
Provides a series of related Web content to an image.
Returns the following information:
Web entities: Inferred entities (labels/descriptions) from
similar images on the Web.
Full matching images: A list of URLs for fully matching images
of any size on the Internet.
Partial matching images: A list of URLs for images that
share key-point features, such as a cropped version of the original
image.
Pages with matching images: A list of Webpages (identified by
page URL, page title, matching image URL) with an image that satisfies
the conditions described above.
Visually similar images: A list of URLs for images that share
some features with the original image.
Best guess label: A best guess as to the topic of the requested
image inferred from similar images on the Internet.
Locates faces with bounding polygons,
and identifies specific facial "landmarks" such as eyes, ears, nose, mouth,
etc. along with their corresponding confidence values.
Returns likelihood ratings for emotion
(joy, sorrow, anger, surprise) and general image properties
(underexposed, blurred, headwear present).
Likelihoods ratings are expressed
as 6 different values: UNKNOWN, VERY_UNLIKELY,
UNLIKELY, POSSIBLE, LIKELY, or
VERY_LIKELY.
[[["Easy to understand","easyToUnderstand","thumb-up"],["Solved my problem","solvedMyProblem","thumb-up"],["Other","otherUp","thumb-up"]],[["Hard to understand","hardToUnderstand","thumb-down"],["Incorrect information or sample code","incorrectInformationOrSampleCode","thumb-down"],["Missing the information/samples I need","missingTheInformationSamplesINeed","thumb-down"],["Other","otherDown","thumb-down"]],["Last updated 2025-10-30 UTC."],[],[]]