O que você criará
Neste tutorial, você fará o download de um modelo personalizado do TensorFlow Lite exportado do AutoML Vision Edge. Em seguida, você executará um app pré-desenvolvido para iOS que usa esse modelo para detectar vários objetos em uma imagem (com caixas delimitadoras) e fornecer uma classificação personalizada das categorias de objeto.
Objetivos
Neste tutorial de apresentação completo, você usará o código para fazer o seguinte:
- Executar um modelo de AutoML Vision Object Detection Edge em um app para iOS usando o interpretador do TF Lite.
Antes de começar
Clonar o repositório Git
Usando a linha de comando, clone o seguinte repositório Git com o comando abaixo:
git clone https://github.com/tensorflow/examples.git
Navegue até o diretório ios do clone local do repositório
(examples/lite/examples/object_detection/ios/). Você vai executar todos os
exemplo de código a seguir do diretório ios:
cd examples/lite/examples/object_detection/ios
Pré-requisitos
- É preciso ter o Git (em inglês) instalado.
- Versões do iOS compatíveis: iOS 12.0 e posteriores.
Configurar o app para iOS
Gerar e abrir o arquivo do espaço de trabalho
Para começar a configurar o app para iOS original, gere primeiro o arquivo de espaço de trabalho usando o software necessário:
Navegue até a pasta
ios, caso ainda não tenha feito isso:cd examples/lite/examples/object_detection/ios
Instale o pod para gerar o arquivo de espaço de trabalho:
pod install
Se você tiver instalado esse pod antes, use o seguinte comando:
pod update
Depois de gerar o arquivo de espaço de trabalho, é possível abrir o projeto com o Xcode. Para abrir o projeto pela linha de comando, execute o seguinte comando no diretório
ios:open ./ObjectDetection.xcworkspace
Crie um identificador exclusivo e desenvolver o app
Com o ObjectDetection.xcworkspace aberto no Xcode, altere primeiro o
identificador do pacote (ID do pacote) para um valor único.
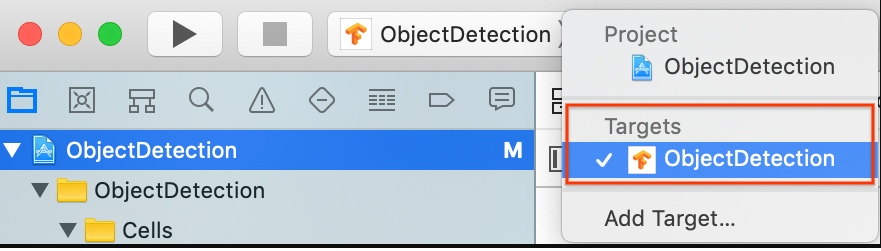
Selecione o primeiro item do projeto
ObjectDetectionno navegador de projetos à esquerda.
Confirme se você selecionou Targets > ObjectDetection.
Na seção General > Identity, altere o campo "Bundle Identifier" para um valor exclusivo. O estilo preferencial é notação reversa de nome de domínio (em inglês).

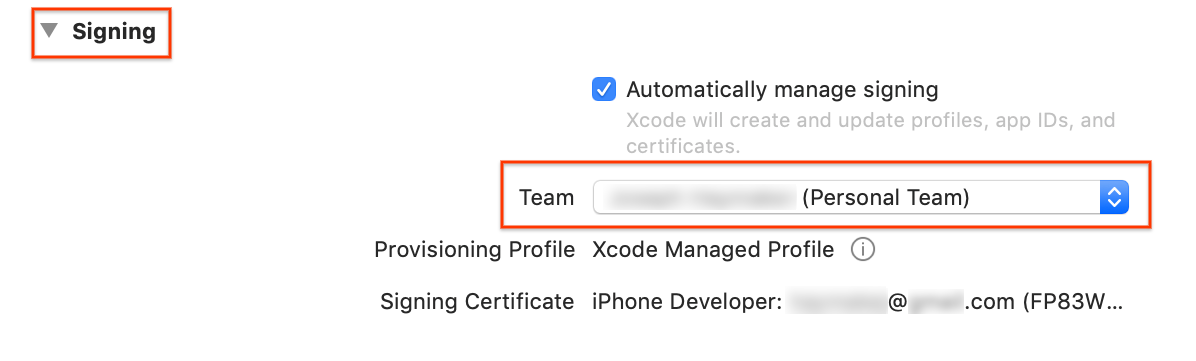
Na seção General > Signing abaixo de Identity, especifique uma equipe no menu suspenso. Esse valor é fornecido pelo seu ID de desenvolvedor.
Conecte um dispositivo iOS ao computador. Depois que o dispositivo for detectado, selecione-o na lista de dispositivos.
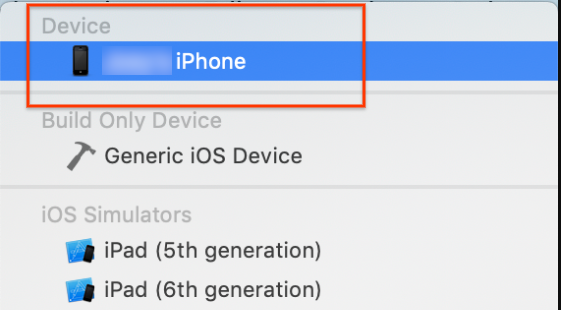
Depois de especificar todas as alterações de configuração, crie o app no Xcode usando o seguinte comando: comando + B.
Executar o app original
O app de amostra é um app de câmera que detecta continuamente os objetos (caixas delimitadoras e rótulos) nos frames vistos pela câmera traseira do seu dispositivo. Para isso, ele usa um modelo de SSD MobileNet quantificado treinado no conjunto de dados do COCO (em inglês).
Estas instruções ajudam você a criar e executar a demonstração em um dispositivo iOS.
O download de arquivos de modelo é feito por meio de scripts no Xcode quando você cria e executa a demonstração. Você não precisa executar nenhuma etapa explicitamente para fazer o download de modelos do TF Lite no projeto.
Antes de inserir o modelo personalizado, teste a versão de valor de referência do app que usa o modelo base treinado de "mobilenet".
Para iniciar o app no Simulator, selecione o botão de reprodução
 no canto superior esquerdo da janela do Xcode.
no canto superior esquerdo da janela do Xcode.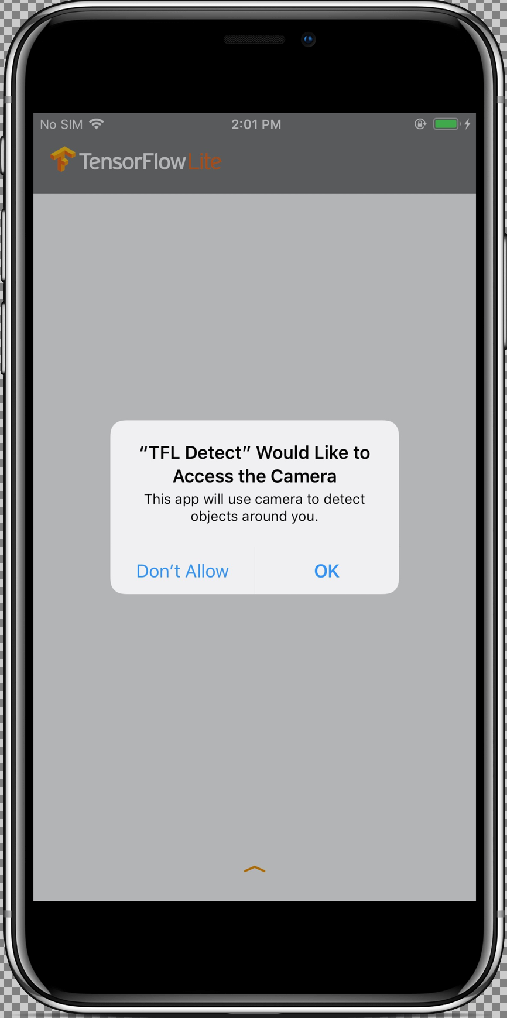
Depois de permitir o acesso do app à sua câmera ao selecionar o botão Allow, o app iniciará a detecção e anotação em tempo real. Os objetos serão detectados e marcados com uma caixa delimitadora e um rótulo em cada frame da câmera.
Mova o dispositivo para diferentes objetos ao seu redor e verifique se o app está detectando imagens corretamente.
Executar o app personalizado
Modifique o app para que ele use o modelo treinado novamente, com categorias de imagem de objeto personalizadas.
Adicionar arquivos de modelo ao projeto
O projeto de demonstração está configurado para pesquisar dois arquivos no diretório
ios/objectDetection/model:
detect.tflitelabelmap.txt
Para substituir esses dois arquivos por suas versões personalizadas, execute o seguinte comando:
cp tf_files/optimized_graph.lite ios/objectDetection/model/detect.tflite cp tf_files/retrained_labels.txt ios/objectDetection/model/labelmap.txt
Executar o app
Para reiniciar o app no seu dispositivo iOS, selecione o botão de reprodução
![]() no canto superior esquerdo da janela do Xcode.
no canto superior esquerdo da janela do Xcode.
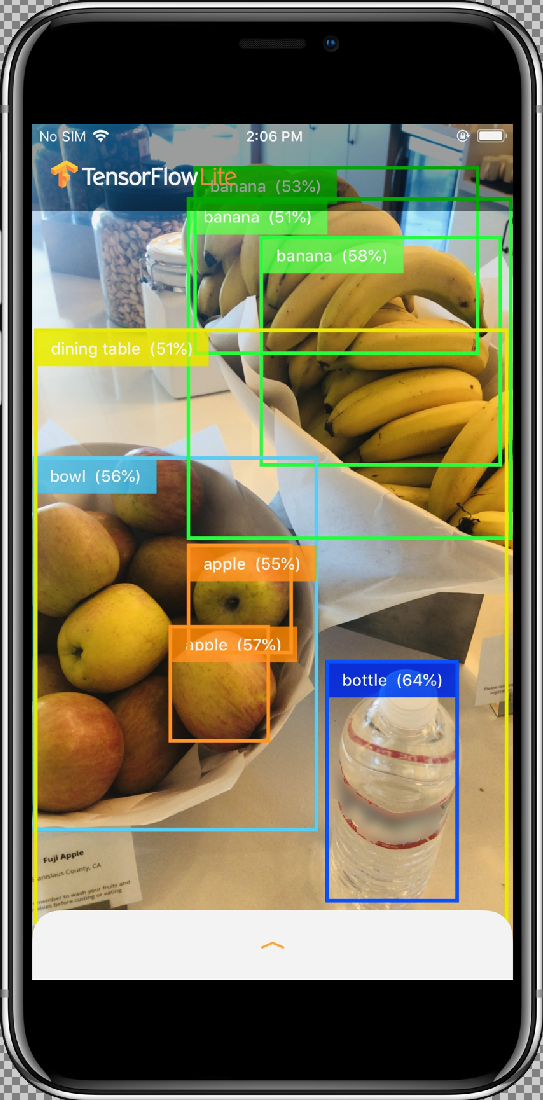
Para testar as modificações, aponte a câmera do dispositivo para diferentes objetos para ver previsões em tempo real.
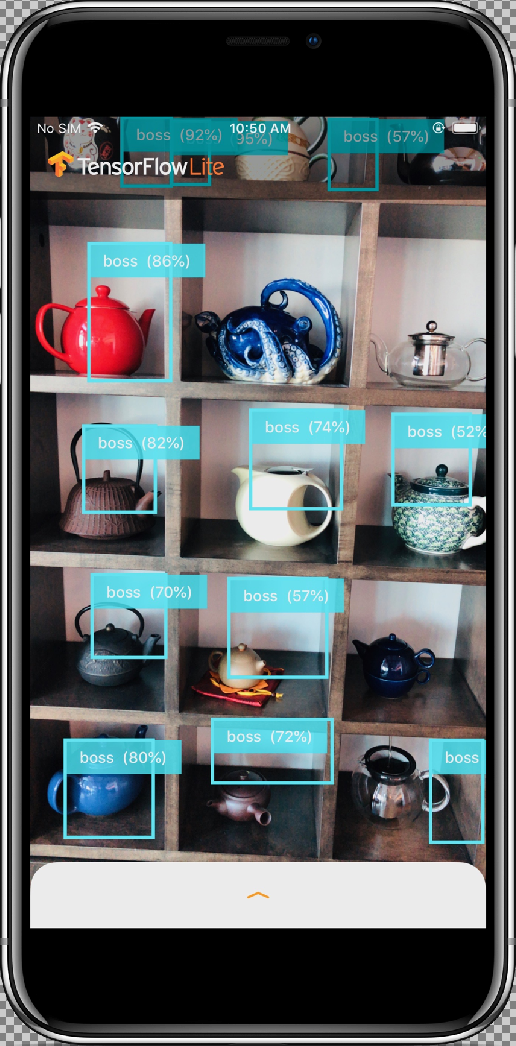
Os resultados serão assim:
Como funciona?
Agora que o app está em execução, analise o código específico do TensorFlow Lite.
Pod do TensorFlowLite
Neste app, um CocoaPod pré-compilado do TFLite é usado. O Podfile inclui o CocoaPod no projeto:
# Uncomment the next line to define a global platform for your project platform :ios, '12.0' target 'ObjectDetection' do # Comment the next line if you're not using Swift and don't want to use dynamic frameworks use_frameworks! # Pods for ObjectDetection pod 'TensorFlowLiteSwift' end
O código de interface do TF Lite está todo contido no
arquivo ModelDataHandler.swift. Essa classe manipula todo o pré-processamento de dados e
faz chamadas para executar a inferência em um determinado frame com a invocação de Interpreter.
Em seguida, ela formata as inferências obtidas e retorna os principais "N" resultados referentes a uma inferência bem-sucedida.
Como explorar o código
O primeiro bloco de interesse (após as importações necessárias)
são declarações de propriedade. Os parâmetros inputShape do modelo do TFLite (batchSize,
inputChannels, inputWidth e inputHeight) são encontrados em
tflite_metadata.json. Você terá esse arquivo assim que exportar o
modelo do TFLite. Para mais informações, acesse o tópico de procedimentos Como exportar modelos do Edge.
O exemplo de tflite_metadata.json é semelhante ao seguinte código:
{
"inferenceType": "QUANTIZED_UINT8",
"inputShape": [
1, // This represents batch size
512, // This represents image width
512, // This represents image Height
3 //This represents inputChannels
],
"inputTensor": "normalized_input_image_tensor",
"maxDetections": 20, // This represents max number of boxes.
"outputTensorRepresentation": [
"bounding_boxes",
"class_labels",
"class_confidences",
"num_of_boxes"
],
"outputTensors": [
"TFLite_Detection_PostProcess",
"TFLite_Detection_PostProcess:1",
"TFLite_Detection_PostProcess:2",
"TFLite_Detection_PostProcess:3"
]
}
...
Parâmetros de modelo:
Substitua os valores abaixo de acordo com o arquivo tflite_metadata.json
do seu modelo.
let batchSize = 1 //Number of images to get prediction, the model takes 1 image at a time let inputChannels = 3 //The pixels of the image input represented in RGB values let inputWidth = 300 //Width of the image let inputHeight = 300 //Height of the image ...
init
O método init (em inglês), que cria o Interpreter com o caminho Model
e InterpreterOptions, e, depois, aloca memória para a entrada do modelo.
init?(modelFileInfo: FileInfo, labelsFileInfo: FileInfo, threadCount: Int = 1) {
let modelFilename = modelFileInfo.name
// Construct the path to the model file.
guard let modelPath = Bundle.main.path(forResource: modelFilename,ofType: modelFileInfo.extension)
// Specify the options for the `Interpreter`.
var options = InterpreterOptions()
options.threadCount = threadCount
do {
// Create the `Interpreter`.
interpreter = try Interpreter(modelPath: modelPath, options: options)
// Allocate memory for the model's input `Tensor`s.
try interpreter.allocateTensors()
}
super.init()
// Load the classes listed in the labels file.
loadLabels(fileInfo: labelsFileInfo)
}
…
runModel
O método runModel (em inglês) abaixo faz o seguinte:
- Escalona a imagem de entrada para a proporção para qual modelo é treinado.
- Remove o componente Alfa do buffer de imagem para extrair os dados RGB.
- Copia os dados RGB para o Tensor de entrada.
- Executa inferência ao invocar o
Interpreter. - Consegue a saída do Interpreter.
- Formata a saída.
func runModel(onFrame pixelBuffer: CVPixelBuffer) -> Result? {
Corta a imagem para o maior quadrado no centro e reduz o tamanho para que fique com as dimensões do modelo:
let scaledSize = CGSize(width: inputWidth, height: inputHeight)
guard let scaledPixelBuffer = pixelBuffer.resized(to: scaledSize) else
{
return nil
}
...
do {
let inputTensor = try interpreter.input(at: 0)
Remove o componente Alfa do buffer de imagem para extrair os dados RGB:
guard let rgbData = rgbDataFromBuffer(
scaledPixelBuffer,
byteCount: batchSize * inputWidth * inputHeight * inputChannels,
isModelQuantized: inputTensor.dataType == .uInt8
) else {
print("Failed to convert the image buffer to RGB data.")
return nil
}
Copia os dados RGB para a entrada Tensor:
try interpreter.copy(rgbData, toInputAt: 0)
Executa a inferência ao invocar o Interpreter:
let startDate = Date()
try interpreter.invoke()
interval = Date().timeIntervalSince(startDate) * 1000
outputBoundingBox = try interpreter.output(at: 0)
outputClasses = try interpreter.output(at: 1)
outputScores = try interpreter.output(at: 2)
outputCount = try interpreter.output(at: 3)
}
Formata os resultados:
let resultArray = formatResults(
boundingBox: [Float](unsafeData: outputBoundingBox.data) ?? [],
outputClasses: [Float](unsafeData: outputClasses.data) ?? [],
outputScores: [Float](unsafeData: outputScores.data) ?? [],
outputCount: Int(([Float](unsafeData: outputCount.data) ?? [0])[0]),
width: CGFloat(imageWidth),
height: CGFloat(imageHeight)
)
...
}
Filtra todos os resultados com a pontuação de confiança inferior ao limite e retorna os principais "N" resultados classificados em ordem decrescente:
func formatResults(boundingBox: [Float], outputClasses: [Float],
outputScores: [Float], outputCount: Int, width: CGFloat, height: CGFloat)
-> [Inference]{
var resultsArray: [Inference] = []
for i in 0...outputCount - 1 {
let score = outputScores[i]
Filtra resultados com pontuação de confiança inferior ao limite:
guard score >= threshold else {
continue
}
Extrai os nomes das classes de saída detectadas da lista de rótulos:
let outputClassIndex = Int(outputClasses[i])
let outputClass = labels[outputClassIndex + 1]
var rect: CGRect = CGRect.zero
Traduz a caixa delimitadora detectada para CGRect.
rect.origin.y = CGFloat(boundingBox[4*i])
rect.origin.x = CGFloat(boundingBox[4*i+1])
rect.size.height = CGFloat(boundingBox[4*i+2]) - rect.origin.y
rect.size.width = CGFloat(boundingBox[4*i+3]) - rect.origin.x
Os cantos detectados são para as dimensões do modelo. Por isso, escalonamos rect
em relação às dimensões reais da imagem.
let newRect = rect.applying(CGAffineTransform(scaleX: width, y: height))
Extrai a cor atribuída à classe:
let colorToAssign = colorForClass(withIndex: outputClassIndex + 1)
let inference = Inference(confidence: score,
className: outputClass,
rect: newRect,
displayColor: colorToAssign)
resultsArray.append(inference)
}
// Sort results in descending order of confidence.
resultsArray.sort { (first, second) -> Bool in
return first.confidence > second.confidence
}
return resultsArray
}
CameraFeedManager
O método CameraFeedManager.swift (em inglês) gerencia toda a funcionalidade relacionada à câmera.
Ele inicializa e configura o AVCaptureSession:
private func configureSession() {session.beginConfiguration()
Em seguida, ele tenta incluir um
AVCaptureDeviceInpute adicionabuiltInWideAngleCameracomo a entrada de dispositivo da sessão.addVideoDeviceInput()
Em seguida, ele tenta adicionar um
AVCaptureVideoDataOutput:addVideoDataOutput()
session.commitConfiguration() self.cameraConfiguration = .success }Ele inicia a sessão (em inglês).
Ele interrompe a sessão (em inglês).
Adiciona e remove (links em inglês) as notificações
AVCaptureSession.
Tratamento de erros:
- NSNotification.Name.AVCaptureSessionRuntimeError: é
postado quando ocorre um
erro inesperado enquanto a instância
AVCaptureSessionestá em execução. O dicionário userInfo contém um objetoNSErrorpara a chaveAVCaptureSessionErrorKey. - NSNotification.Name.AVCaptureSessionWasInterrupted: é
postado quando ocorre uma interrupção.
Por exemplo, chamada telefônica, alarme etc. Quando apropriado, a instância
AVCaptureSessionautomaticamente deixará de ser executada como resposta à interrupção. O userInfo conteráAVCaptureSessionInterruptionReasonKeyindicando o motivo da interrupção. - NSNotification.Name.AVCaptureSessionInterruptionEnded: é
postado quando
AVCaptureSessioncessa a interrupção. A instância da sessão é reiniciada depois que a interrupção, como uma ligação telefônica, é cessada.
A classe InferenceViewController.swift (em inglês) é responsável pela tela abaixo, em que o foco principal é a parte destacada.
- Resolution: exibe a resolução do frame atual (imagem da sessão de vídeo).
- Crop: exibe o tamanho de corte do frame atual.
- InferenceTime: exibe quanto tempo o modelo está levando para detectar o objeto.
- Threads: exibe quantas linhas de execução estão em execução.
O usuário tem a opção de aumentar ou diminuir essa contagem. Para isso, basta tocar no sinal
+ou-do Stepper. A contagem de linhas de execução atual usada pelo TensorFlow Lite Interpreter.

A classe ViewController.swift contém a instância de CameraFeedManager,
que gerencia a funcionalidade relacionada à câmera e
ModelDataHandler. ModelDataHandler manipula o Model (modelo treinado) e
recebe a saída do frame de imagem da sessão de vídeo.
private lazy var cameraFeedManager = CameraFeedManager(previewView: previewView)
private var modelDataHandler: ModelDataHandler? =
ModelDataHandler(modelFileInfo: MobileNetSSD.modelInfo, labelsFileInfo: MobileNetSSD.labelsInfo)
Inicia a sessão da câmera ao chamar:
cameraFeedManager.checkCameraConfigurationAndStartSession()
Quando você altera a contagem de linhas de execução, essa classe reinicializa o modelo com
uma nova contagem na função didChangeThreadCount.
A classe CameraFeedManager enviará ImageFrame como CVPixelBuffer para
ViewController, que será enviado ao modelo para previsão.
Com este método, o pixelBuffer da câmera em tempo real é executado no TensorFlow para conseguir o
resultado.
@objc
func runModel(onPixelBuffer pixelBuffer: CVPixelBuffer) {
Executa o pixelBuffer da câmera em tempo real por meio do TensorFlow para conseguir o resultado:
result = self.modelDataHandler?.runModel(onFrame: pixelBuffer)
...
let displayResult = result
let width = CVPixelBufferGetWidth(pixelBuffer)
let height = CVPixelBufferGetHeight(pixelBuffer)
DispatchQueue.main.async {
Exibe resultados ao entregá-los para o InferenceViewController:
self.inferenceViewController?.resolution = CGSize(width: width, height: height) self.inferenceViewController?.inferenceTime = inferenceTime
Extrai as caixas delimitadoras e exibe nomes de classes e pontuações de confiança:
self.drawAfterPerformingCalculations(onInferences: displayResult.inferences, withImageSize: CGSize(width: CGFloat(width), height: CGFloat(height)))
}
}
A seguir
Você concluiu um tutorial de um app de detecção e anotação de objetos para iOS usando um modelo do Edge. Além disso, usou um modelo do Edge Tensorflow Lite treinado para testar um app de detecção de objetos antes de fazer modificações e receber anotações de amostra. Em seguida, você examinou o código específico do TensorFlow Lite para entender a funcionalidade subjacente.
Use os recursos a seguir para saber mais sobre os modelos do TensorFlow e o AutoML Vision Edge:
- Saiba mais sobre o TFLite na documentação oficial e no repositório de códigos (links em inglês).
- Tente usar outros modelos prontos para o TFLite, incluindo um detector de hotwords de fala e uma versão de resposta inteligente no dispositivo.
- Veja mais informações gerais sobre o TensorFlow na documentação de primeiros passos (em inglês) relacionada.