Depois que você criou (treinou) e implantou o modelo, é possível fazer solicitações de previsão on-line (ou síncrona) a ele.
Exemplo de previsão on-line (individual)
Depois de implantar o modelo treinado, é possível solicitar uma previsão para uma
imagem usando o método predict
(em inglês) ou a interface do usuário para fazer anotações de previsão. O método predict
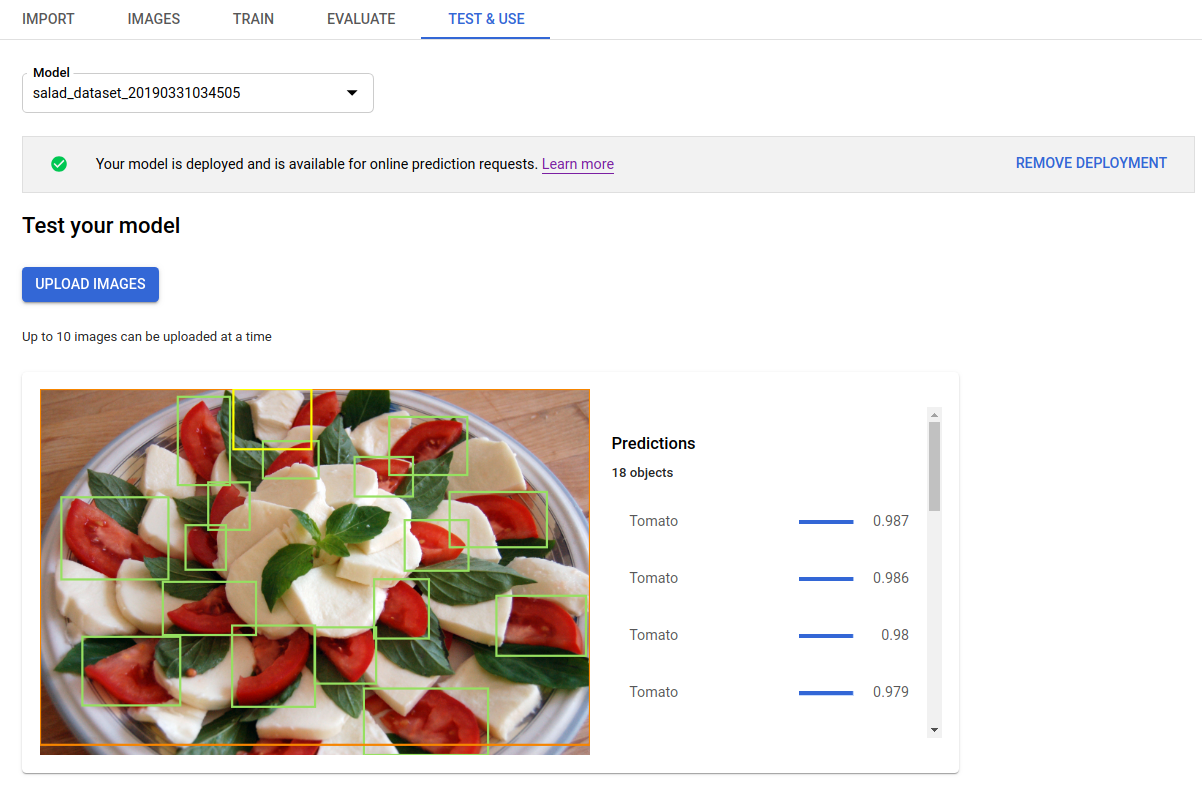
aplica rótulos às caixas delimitadoras de objeto na imagem.
O modelo gerará cobranças enquanto estiver implantado.. Depois de fazer previsões com o modelo treinado, será possível remover a implantação do modelo se você não quiser mais gerar cobranças de uso da hospedagem do modelo.
IU da Web
Para exibir os modelos disponíveis, abra a interface de usuário do AutoML Vision Object Detection e clique na guia Modelos (com o ícone de lâmpada) na barra de navegação à esquerda.
Para ver os modelos de outro projeto, selecione o projeto na lista suspensa na parte superior direita da barra de título.
Clique na linha do modelo que você quer usar para rotular suas imagens.
Se o modelo ainda não foi implantado, implante-o agora selecionando Implantar o modelo.
Para fazer previsões on-line, é necessário que o modelo seja implantado. A implantação do modelo gera custos. Para mais informações, consulte a página de preços.
Clique na guia Testar e usar logo abaixo da barra de título.
Clique em Fazer upload de imagens para fazer upload das imagens que você quer rotular.
REST
Para testar a previsão, primeiro implante o modelo hospedado na nuvem.
Antes de usar os dados da solicitação abaixo, faça estas substituições:
- project-id: o ID do projeto do GCP.
- model-id: o ID do seu modelo, a partir da
resposta de quando você o criou. Ele é o último elemento no nome do modelo.
Por exemplo:
- Nome do modelo:
projects/project-id/locations/location-id/models/IOD4412217016962778756 - ID do modelo:
IOD4412217016962778756
- Nome do modelo:
- base64-encoded-image: a representação base64 (string ASCII) dos dados da imagem binária. Essa string precisa ser semelhante à
seguinte string:
/9j/4QAYRXhpZgAA...9tAVx/zDQDlGxn//2Q==. Consulte o tópico Codificação Base64 para mais informações.
Considerações específicas de campo:
scoreThreshold: um valor de 0 a 1. Apenas valores com limites de pontuação de pelo menos esse valor serão exibidos. O valor padrão é 0,5.maxBoundingBoxCount: o maior número (limite superior) de caixas delimitadoras a serem retornadas em uma resposta. O valor padrão é 100 e o máximo é 500. Esse valor está sujeito a restrições de recursos e pode ser limitado pelo servidor.
Método HTTP e URL:
POST https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:predict
Corpo JSON da solicitação:
{
"payload": {
"image": {
"imageBytes": "BASE64_ENCODED_IMAGE"
}
},
"params": {
"scoreThreshold": "0.5",
"maxBoundingBoxCount": "100"
}
}
Para enviar a solicitação, escolha uma destas opções:
curl
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:predict"
PowerShell
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:predict" | Select-Object -Expand Content
A saída é retornada no formato JSON. As previsões do modelo do
AutoML Vision Object Detection estão contidas no campo payload:
boundingBoxde um objeto é especificado por vértices diagonalmente opostos.displayNameé o rótulo do objeto previsto pelo modelo do AutoML Vision Object Detection.scorerepresenta um nível de confiança que o rótulo especificado aplica à imagem. Varia de0(sem confiança) a1(alta confiança).
{
"payload": [
{
"imageObjectDetection": {
"boundingBox": {
"normalizedVertices": [
{
"x": 0.034553755,
"y": 0.015524037
},
{
"x": 0.941527,
"y": 0.9912563
}
]
},
"score": 0.9997793
},
"displayName": "Salad"
},
{
"imageObjectDetection": {
"boundingBox": {
"normalizedVertices": [
{
"x": 0.11737197,
"y": 0.7098793
},
{
"x": 0.510878,
"y": 0.87987
}
]
},
"score": 0.63219965
},
"displayName": "Tomato"
}
]
}
Go
Antes de testar esta amostra, siga as instruções de configuração dessa linguagem na página Bibliotecas de cliente.
Java
Antes de testar esta amostra, siga as instruções de configuração dessa linguagem na página Bibliotecas de cliente.
Node.js
Antes de testar esta amostra, siga as instruções de configuração dessa linguagem na página Bibliotecas de cliente.
Python
Antes de testar esta amostra, siga as instruções de configuração dessa linguagem na página Bibliotecas de cliente.
Outras linguagens
C#: Siga as Instruções de configuração do C# na página das bibliotecas de cliente e acesse a Documentação de referência do AutoML Vision Object Detection para .NET.
PHP: Siga as Instruções de configuração do PHP na página das bibliotecas de cliente e acesse a Documentação de referência do AutoML Vision Object Detection para PHP.
Ruby: Siga as Instruções de configuração do Ruby na página das bibliotecas de cliente e acesse a Documentação de referência do AutoML Vision Object Detection para Ruby.