After training a model, AutoML Vision Object Detection uses images from the TEST set to evaluate the quality and accuracy of the new model.
AutoML Vision Object Detection provides an aggregate set of evaluation metrics (evaluation process outputs) indicating how well the model performs overall, as well as evaluation metrics for each category label, indicating how well the model performs for that label.
Evaluation overview
Evaluation process inputs
IoU threshold : Intersection over Union, a value used in object detection to measure the overlap of a predicted versus actual bounding box for an object. The closer the predicted bounding box values are to the actual bounding box values the greater the intersection, and the greater the IoU value.
Score threshold: Output metrics (below) are computed with an assumption that the model never returns predictions with score lower than this value.
Evaluation process output
AuPRC : Area under Precision/Recall curve, also referred to as "average precision." Generally between 0.5 and 1.0. Higher values indicate more accurate models.
Confidence threshold curves: show how different confidence thresholds would affect precision, recall, true and false positive rates. Read about the relationship of precision and recall.
F1 score: The harmonic mean of precision and recall. F1 is a useful metric if you want to find a balance between precision and recall. F1 is also useful when you have an uneven class distribution in your training data.
Use this data to evaluate your model's readiness. High confusion, low AUC scores, or low precision and recall scores can indicate that your model needs additional training data or has inconsistent labels. A very high AUC score and perfect precision and recall can indicate that the data is too "easy" and may not generalize well: a high AUC may indicate that the model was trained on idealized data that would not represent future inferences well.
Managing model evaluations
List model evaluations
Once you have trained a model, you can list evaluation metrics for that model.
Web UI
Open the AutoML Vision Object Detection UI and click the Models tab (with lightbulb icon) in the left navigation bar to display the available models.
To view the models for a different project, select the project from the drop-down list in the upper right of the title bar.
Click the row for the model you want to evaluate.
If necessary, click the Evaluate tab just below the title bar.
If training has been completed for the model, AutoML Vision Object Detection shows its evaluation metrics.
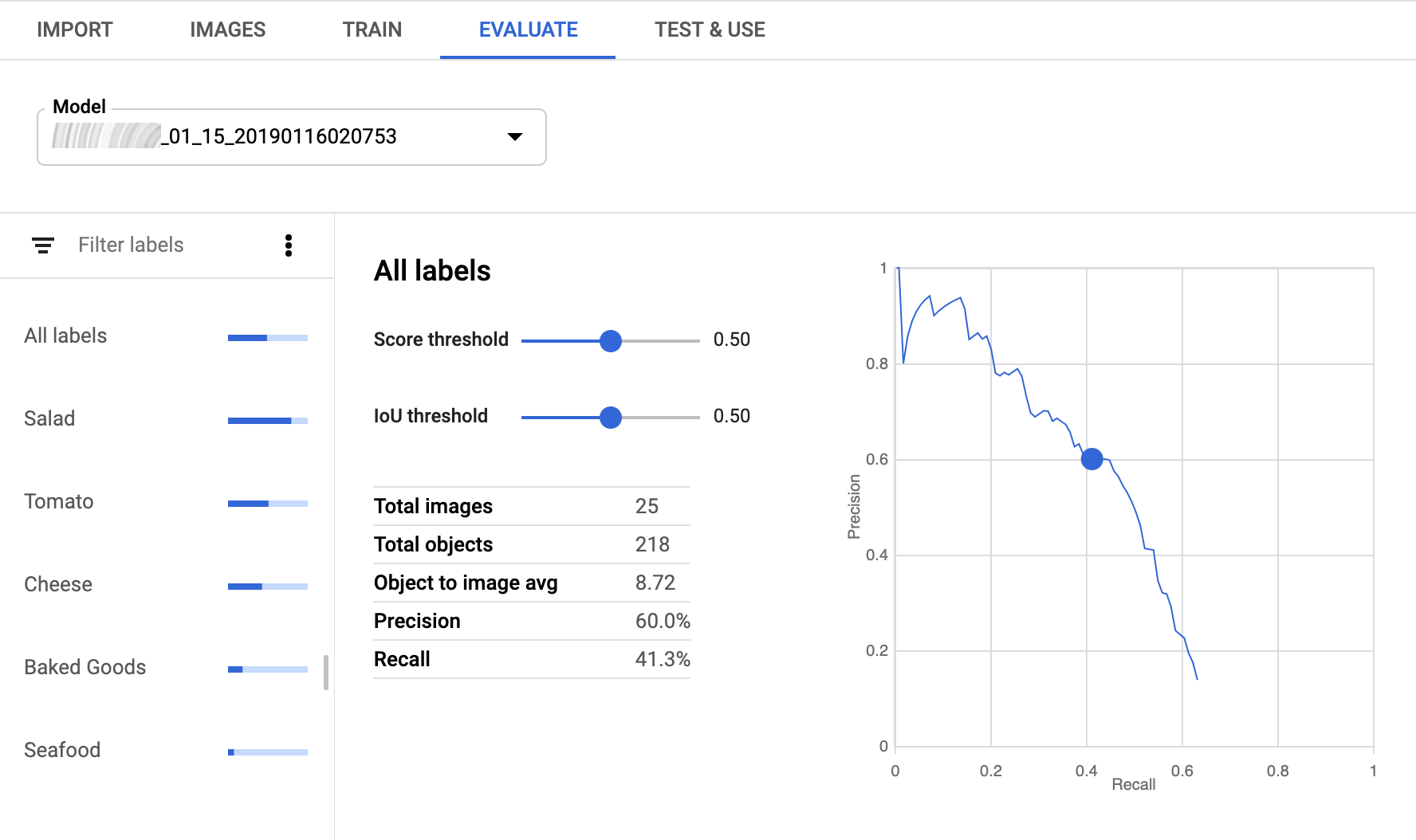
To view the metrics for a specific label, select the label name from the list of labels in the lower part of the page.
REST
Before using any of the request data, make the following replacements:
- project-id: your GCP project ID.
- model-id: the ID of your model, from the
response when you created the model. The ID is the last element of the name of your model.
For example:
- model name:
projects/project-id/locations/location-id/models/IOD4412217016962778756 - model id:
IOD4412217016962778756
- model name:
HTTP method and URL:
GET https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations
To send your request, choose one of these options:
curl
Execute the following command:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations"
PowerShell
Execute the following command:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations" | Select-Object -Expand Content
You should receive a JSON response similar to the following sample. Key object detection specific
fields are in bold, and varying amounts of boundingBoxMetricsEntries entries are
shown for clarity:
{
"modelEvaluation": [
{
"name": "projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVAL_ID",
"annotationSpecId": "6342510834593300480",
"createTime": "2019-07-26T22:28:56.890727Z",
"evaluatedExampleCount": 18,
"imageObjectDetectionEvaluationMetrics": {
"evaluatedBoundingBoxCount": 96,
"boundingBoxMetricsEntries": [
{
"iouThreshold": 0.15,
"meanAveragePrecision": 0.6317751,
"confidenceMetricsEntries": [
{
"confidenceThreshold": 0.101631254,
"recall": 0.84375,
"precision": 0.2555205,
"f1Score": 0.3922518
},
{
"confidenceThreshold": 0.10180253,
"recall": 0.8333333,
"precision": 0.25316456,
"f1Score": 0.3883495
},
...
{
"confidenceThreshold": 0.8791167,
"recall": 0.020833334,
"precision": 1,
"f1Score": 0.040816326
},
{
"confidenceThreshold": 0.8804436,
"recall": 0.010416667,
"precision": 1,
"f1Score": 0.020618558
}
]
},
{
"iouThreshold": 0.8,
"meanAveragePrecision": 0.15461995,
"confidenceMetricsEntries": [
{
"confidenceThreshold": 0.101631254,
"recall": 0.22916667,
"precision": 0.06940063,
"f1Score": 0.10653753
},
...
{
"confidenceThreshold": 0.8804436,
"recall": 0.010416667,
"precision": 1,
"f1Score": 0.020618558
}
]
},
{
"iouThreshold": 0.4,
"meanAveragePrecision": 0.56170964,
"confidenceMetricsEntries": [
{
"confidenceThreshold": 0.101631254,
"recall": 0.7604167,
"precision": 0.23028392,
"f1Score": 0.3535109
},
...
{
"confidenceThreshold": 0.8804436,
"recall": 0.010416667,
"precision": 1,
"f1Score": 0.020618558
}
]
},
...
],
"boundingBoxMeanAveragePrecision": 0.4306387
},
"displayName": "Tomato"
},
{
"name": "projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVAL_ID",
"annotationSpecId": "1730824816165912576",
"createTime": "2019-07-26T22:28:56.890727Z",
"evaluatedExampleCount": 9,
"imageObjectDetectionEvaluationMetrics": {
"evaluatedBoundingBoxCount": 51,
"boundingBoxMetricsEntries": [
{
...
}
],
"boundingBoxMeanAveragePrecision": 0.29565892
},
"displayName": "Cheese"
},
{
"name": "projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVAL_ID",
"annotationSpecId": "7495432339200147456",
"createTime": "2019-07-26T22:28:56.890727Z",
"evaluatedExampleCount": 4,
"imageObjectDetectionEvaluationMetrics": {
"evaluatedBoundingBoxCount": 22,
"boundingBoxMetricsEntries": [
{
"iouThreshold": 0.2,
"meanAveragePrecision": 0.104004614,
"confidenceMetricsEntries": [
{
"confidenceThreshold": 0.1008248,
"recall": 0.36363637,
"precision": 0.08888889,
"f1Score": 0.14285715
},
...
{
"confidenceThreshold": 0.47585258,
"recall": 0.045454547,
"precision": 1,
"f1Score": 0.08695653
}
]
},
...
],
"boundingBoxMeanAveragePrecision": 0.057070773
},
"displayName": "Seafood"
}
]
}
Go
Before trying this sample, follow the setup instructions for this language on the Client Libraries page.
Java
Before trying this sample, follow the setup instructions for this language on the Client Libraries page.
Node.js
Before trying this sample, follow the setup instructions for this language on the Client Libraries page.
Python
Before trying this sample, follow the setup instructions for this language on the Client Libraries page.
Additional languages
C#: Please follow the C# setup instructions on the client libraries page and then visit the AutoML Vision Object Detection reference documentation for .NET.
PHP: Please follow the PHP setup instructions on the client libraries page and then visit the AutoML Vision Object Detection reference documentation for PHP.
Ruby: Please follow the Ruby setup instructions on the client libraries page and then visit the AutoML Vision Object Detection reference documentation for Ruby.
Get model evaluations
You can also get a specific model evaluation for a label (displayName) using
an evaluation ID.
Web UI
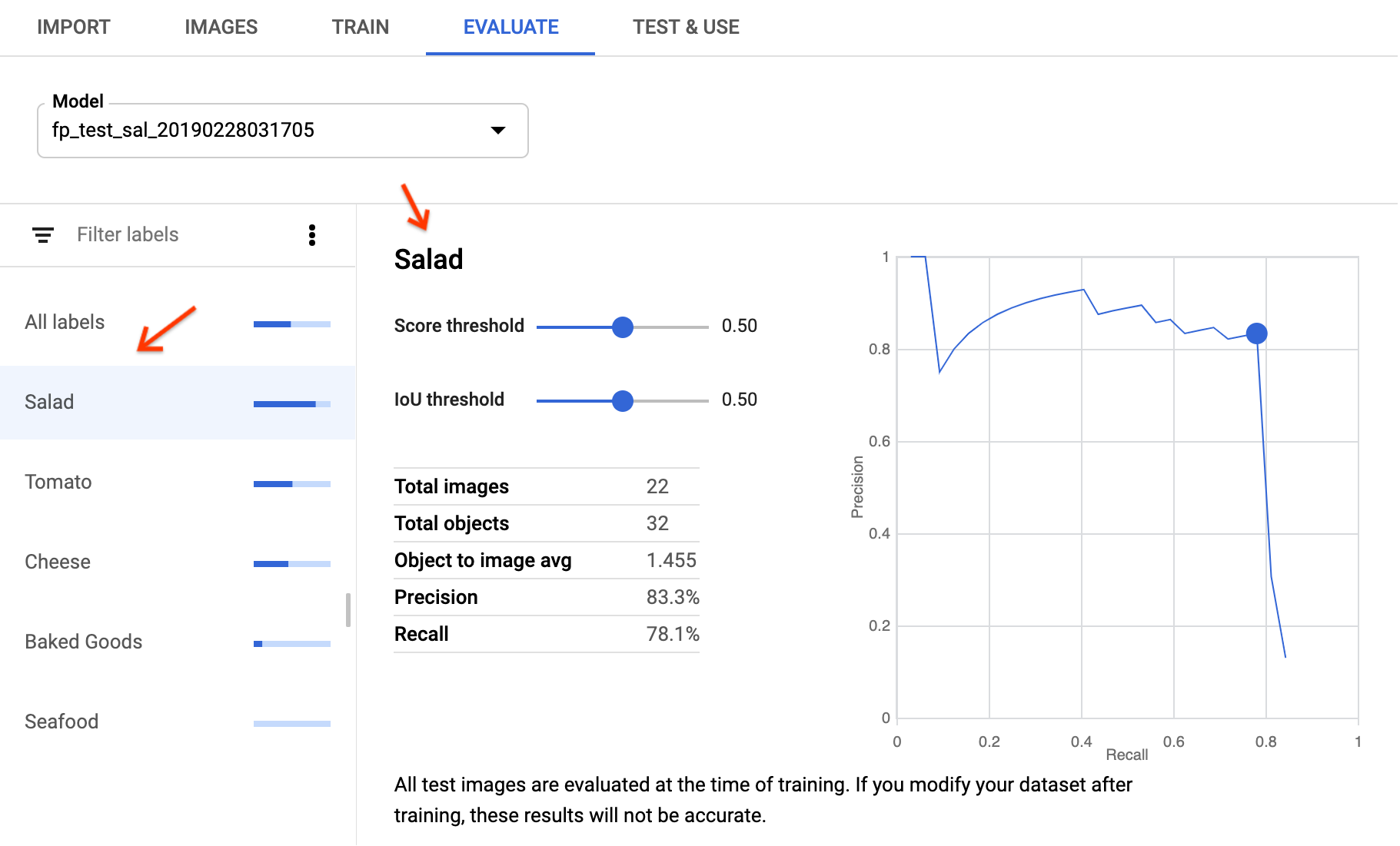
In the AutoML Vision Object Detection UI the equivalent operation is available by going to the Models page, and then selecting your model. After selecting your model, go to the Evaluate tab and select the label to view label-specific evaluations.
REST
Before using any of the request data, make the following replacements:
- project-id: your GCP project ID.
- model-id: the ID of your model, from the
response when you created the model. The ID is the last element of the name of your model.
For example:
- model name:
projects/project-id/locations/location-id/models/IOD4412217016962778756 - model id:
IOD4412217016962778756
- model name:
- model-evaluation-id: the ID value of the model
evaluation. You can get model evaluation IDs from the
listmodel evaluations operation.
HTTP method and URL:
GET https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVALUATION_ID
To send your request, choose one of these options:
curl
Execute the following command:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVALUATION_ID"
PowerShell
Execute the following command:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVALUATION_ID" | Select-Object -Expand Content
You should receive a JSON response similar to the following sample. Key object detection specific
fields are in bold, and a shortened version of boundingBoxMetricsEntries entries are
shown for clarity:
{
"name": "projects/PROJECT_ID/locations/us-
central1/models/MODEL_ID/modelEvaluations/MODEL-EVALUATION-
ID",
"annotationSpecId": "6342510834593300480",
"createTime": "2019-07-26T22:28:56.890727Z",
"evaluatedExampleCount": 18,
"imageObjectDetectionEvaluationMetrics": {
"evaluatedBoundingBoxCount": 96,
"boundingBoxMetricsEntries": [
{
"iouThreshold": 0.15,
"meanAveragePrecision": 0.6317751,
"confidenceMetricsEntries": [
{
"confidenceThreshold": 0.101631254,
"recall": 0.84375,
"precision": 0.2555205,
"f1Score": 0.3922518
},
...
{
"confidenceThreshold": 0.8804436,
"recall": 0.010416667,
"precision": 1,
"f1Score": 0.020618558
}
]
},
{
"iouThreshold": 0.8,
"meanAveragePrecision": 0.15461995,
"confidenceMetricsEntries": [
{
"confidenceThreshold": 0.101631254,
"recall": 0.22916667,
"precision": 0.06940063,
"f1Score": 0.10653753
},
...
{
"confidenceThreshold": 0.8804436,
"recall": 0.010416667,
"precision": 1,
"f1Score": 0.020618558
}
]
},
{
"iouThreshold": 0.4,
"meanAveragePrecision": 0.56170964,
"confidenceMetricsEntries": [
{
"confidenceThreshold": 0.101631254,
"recall": 0.7604167,
"precision": 0.23028392,
"f1Score": 0.3535109
},
...
{
"confidenceThreshold": 0.8804436,
"recall": 0.010416667,
"precision": 1,
"f1Score": 0.020618558
}
]
},
...
],
"boundingBoxMeanAveragePrecision": 0.4306387
},
"displayName": "Tomato"
}
Go
Before trying this sample, follow the setup instructions for this language on the Client Libraries page.
Java
Before trying this sample, follow the setup instructions for this language on the Client Libraries page.
Node.js
Before trying this sample, follow the setup instructions for this language on the Client Libraries page.
Python
Before trying this sample, follow the setup instructions for this language on the Client Libraries page.
Additional languages
C#: Please follow the C# setup instructions on the client libraries page and then visit the AutoML Vision Object Detection reference documentation for .NET.
PHP: Please follow the PHP setup instructions on the client libraries page and then visit the AutoML Vision Object Detection reference documentation for PHP.
Ruby: Please follow the Ruby setup instructions on the client libraries page and then visit the AutoML Vision Object Detection reference documentation for Ruby.
True Positives, False Negatives, and False Positives (UI only)
In the user interface you can observe specific examples of model performance, namely true positive (TP), false negative (FN), and false positive (FP) instances from your TRAINING and VALIDATION sets.
Web UI
You can access the TP, FN, and FP view in the UI by selecting the Evaluate tab, and then selecting any specific label.
By viewing trends in these predictions, you can modify your training set to improve model performance.
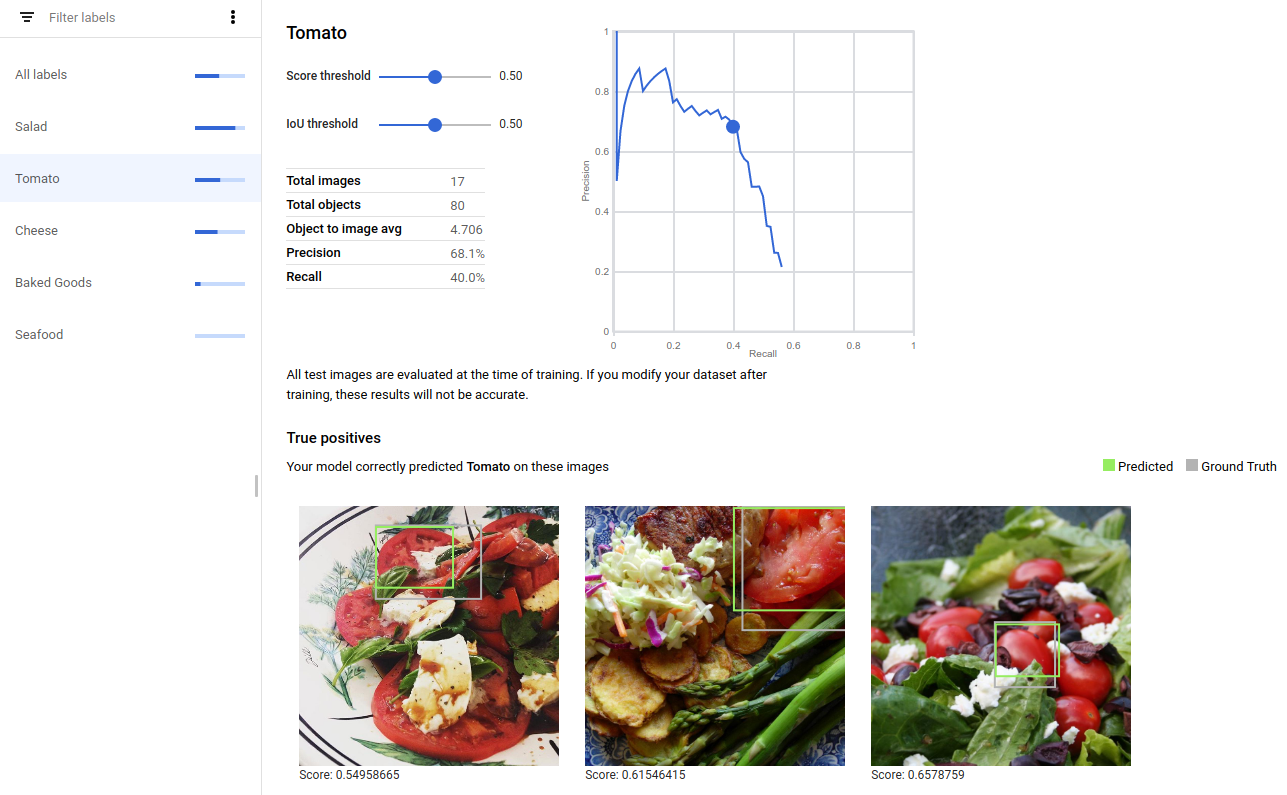
True positive images are validation boxes provided to the trained model that the model correctly annotated:
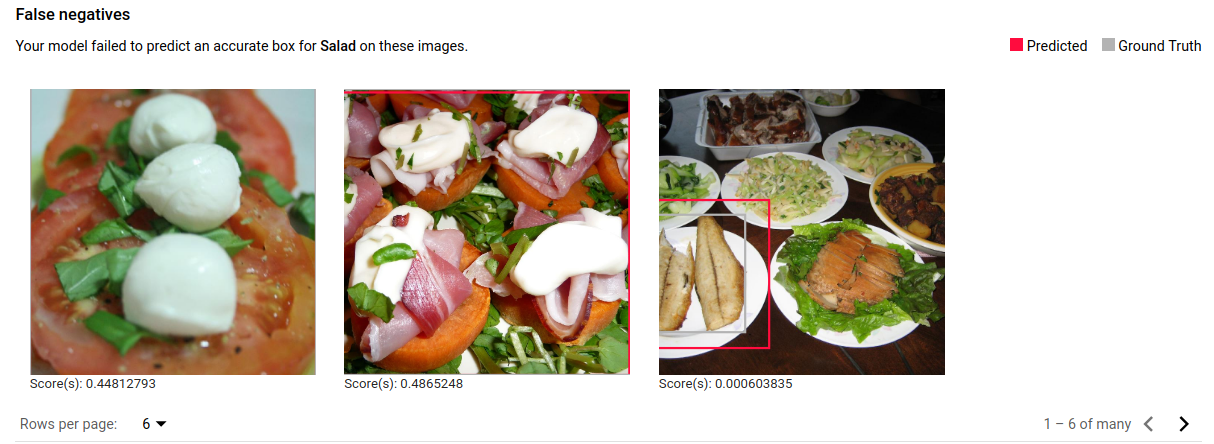
False negative images are similarly provided to the trained model, but the model failed to correctly annotate an instance of an object:
Lastly, false positive images are those provided to the trained model that annotated instances of an object that were not annotated in the area specified:
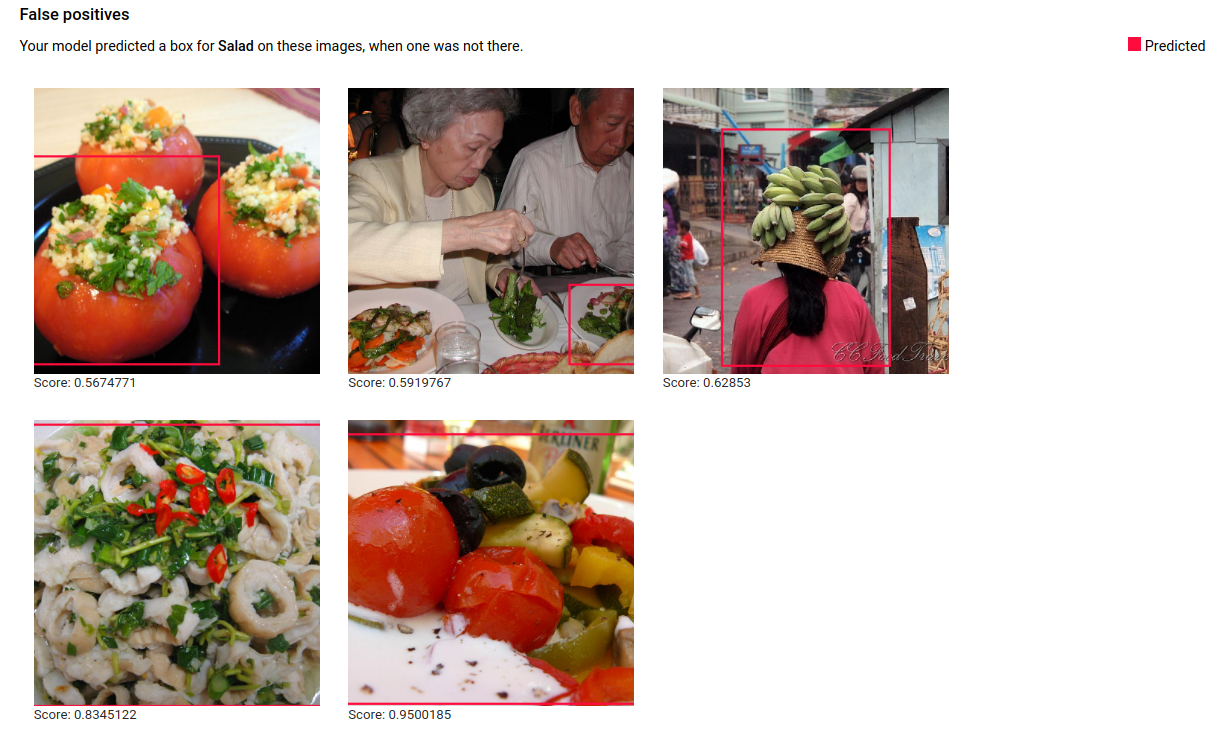
The model is selecting interesting corner cases, which presents an opportunity to refine your definitions and labels to help the model understand your label interpretations. For example, a stricter definition would help the model understand if you consider a stuffed bell pepper a "salad" (or not). With repeated label, train, and evaluate loops your model will surface other such ambiguities in your data.
You can also adjust the score threshold in this view in the user interface, and the TP, FN, and FP images displayed will reflect the threshold change:
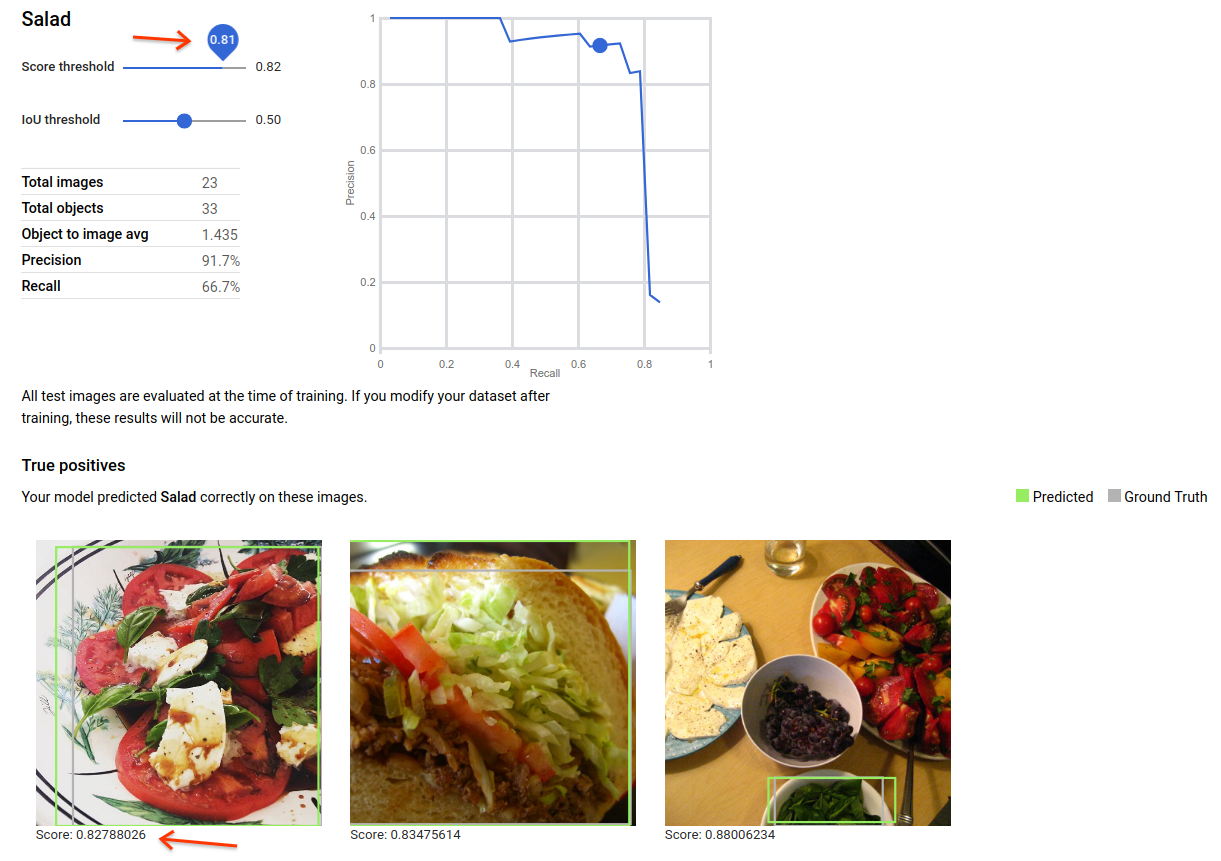
Interpreting evaluation metrics
Object detection models output many bounding boxes for an input image; each box comes with 1) a label and 2) a score or confidence. The evaluation metrics will help you answer several key performance questions about your model:
- Am I getting the right number of boxes?
- Does the model tend to give marginal cases lower scores?
- How closely do the predicted boxes match my ground truth boxes?
Note that these metrics, just like those in multi-label classification, will not point out any class confusion other than generically lower scores.
When examining the per-image model output you need a way to examine a pair of boxes (the ground truth box and the predicted box), and determine how good of a match they are. You must consider things like:
- Do both boxes have the same label?
- How well do the boxes overlap?, and
- How confidently did the model predict the box?
To address the second requirement we introduce a new measurement called the intersection-over-union, or IoU.
IoU and the IoU Threshold
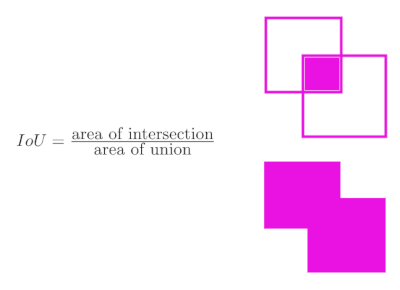
The intersection over union determines how closely two boxes match. The IoU value ranges from 0 (no overlap) to 1 (the boxes are identical) and is calculated by dividing the area in common between the two boxes by the area included in at least one of the boxes. The AutoML service lets you examine your model's performance at several IoU thresholds.
Why might you want to change the IoU threshold?
Consider the use case of counting cars in a parking lot. You don't care if the box coordinates are very accurate, you just care that you have the right total number of boxes. In this case a low IoU threshold is appropriate.

Alternatively, consider trying to measure the size of a fabric stain. In this case you need very precise coordinates, and thus a much higher IoU threshold is appropriate.

Note that you do not need to retrain your model if you change your mind as to the right threshold for your use case; you already have access to evaluation metrics at various IoU thresholds.
Score and Score Threshold
Similar to classification models, object detection model outputs (now boxes) come with scores. Also like image classification, there is a score threshold you can specify after training to determine what is (or is not) a "good" match. Changing the score threshold allows you to tune the false positive and true positive rates to your specific model needs. A user who wants very high recall would typically employ a lower score threshold in their processing of the model output.
Iterate on your model
If you're not happy with the quality levels, you can go back to earlier steps to improve the quality:
- Consider adding more images to any bounding box labels with low quality.
- You may need to add different types of images (e.g. wider angle, higher or lower resolution, different points of view).
- Consider removing bounding box labels altogether if you don't have enough training images.
- Our training algorithms do not use your label names. If you have one label that says "door" and another that says "door_with_knob" the algorithm has no way of figuring out the nuance other than the images you provide it.
- Augment your data with more examples of true positives and negatives. Especially important examples are the ones that are close to the decision boundary (i.e. likely to produce confusion, but still correctly labeled).
- Specify your own TRAIN, TEST, VALIDATE split. The tool randomly assigns images, but near-duplicates may end up in TRAIN and VALIDATE which could lead to overfitting and then poor performance on the TEST set.
Once you've made changes, train and evaluate a new model until you reach a high enough quality level.