Déploiement du modèle initial
Après avoir créé (entraîné) un modèle, vous devez le déployer avant de pouvoir effectuer un appel en ligne (ou synchrone) au modèle.
Désormais, vous pouvez également mettre à jour le déploiement d'un modèle si vous avez besoin de davantage de capacité de prédiction en ligne.
UI Web
- Accédez à l'onglet Test et utilisation situé sous la barre de titre.
- Sélectionnez le bouton Déployer un modèle. Une nouvelle fenêtre s'affiche avec des options de déploiement.
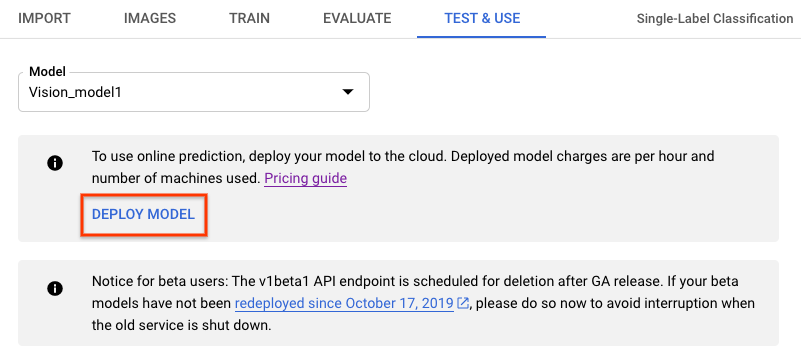
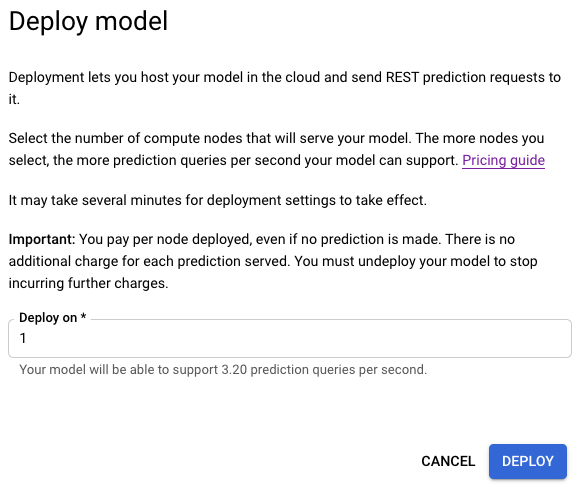
- Spécifiez-y le nombre de nœuds à utiliser pour le déploiement.
Chaque nœud accepte un certain nombre de requêtes de prédiction par seconde (RPS).
En général, un nœud est suffisant pour la majorité du trafic expérimental.
-
Sélectionnez Déployer pour lancer le déploiement du modèle.

- Vous recevrez un e-mail une fois l'opération de déploiement du modèle terminée.
REST
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- project-id : ID de votre projet GCP.
- model-id : ID de votre modèle, issu de la réponse obtenue lors de sa création. L'ID est le dernier élément du nom du modèle.
Exemple :
- Nom du modèle :
projects/project-id/locations/location-id/models/IOD4412217016962778756 - ID du modèle :
IOD4412217016962778756
- Nom du modèle :
Remarques sur les champs :
nodeCount: nombre de nœuds sur lesquels déployer le modèle. La valeur doit être comprise entre 1 et 100 inclus. Un nœud est une abstraction d'une ressource de machine, qui peut gérer le nombre de requêtes de prédiction en ligne par seconde (RPS) stipulé dans l'élémentqps_per_nodedu modèle.
Méthode HTTP et URL :
POST https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy
Corps JSON de la requête :
{
"imageClassificationModelDeploymentMetadata": {
"nodeCount": 2
}
}
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy"
PowerShell
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy" | Select-Object -Expand Content
Des résultats semblables aux lignes suivantes devraient s'afficher : Vous pouvez obtenir l'état de la tâche à l'aide de l'ID de tâche. Pour consulter un exemple, reportez-vous à la section Travailler avec des opérations de longue durée.
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-08-07T22:00:20.692109Z",
"updateTime": "2019-08-07T22:00:20.692109Z",
"deployModelDetails": {}
}
}
Vous pouvez obtenir l'état d'une opération avec la méthode HTTP et l'URL suivantes :
GET https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID
L'état d'une opération terminée ressemblera à ce qui suit :
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-06-21T16:47:21.704674Z",
"updateTime": "2019-06-21T17:01:00.802505Z",
"deployModelDetails": {}
},
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
Go
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Java
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Node.js
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Python
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Langages supplémentaires
C# : Veuillez suivre les Instructions de configuration pour C# sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Vision pour C#.
PHP : Veuillez suivre les Instructions de configuration pour PHP sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Vision pour PHP.
Ruby : Veuillez suivre les Instructions de configuration pour Ruby sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Vision pour Ruby.
Mettre à jour le numéro de nœud d'un modèle
Une fois que vous disposez d'un modèle déployé entraîné, vous pouvez mettre à jour le nombre de nœuds sur lesquels le modèle est déployé pour répondre à votre trafic spécifique. Par exemple, si vous constatez un nombre de requêtes par seconde (RPS) plus élevé que prévu, vous pouvez ajuster le nombre de nœuds déployés pour gérer ce trafic.
Vous pouvez modifier le nombre de nœuds sans annuler d'abord le déploiement du modèle. La mise à jour du déploiement modifie le nombre de nœuds sans interrompre le trafic de votre prédiction inférée.
UI Web
Sur la page Vision Dashboard, sélectionnez l'onglet Modèles dans la barre de navigation de gauche pour afficher les modèles disponibles.
Pour afficher les modèles d'un autre projet, sélectionnez le projet dans la liste déroulante située en haut à droite de la barre de titre.
- Sélectionnez le modèle entraîné que vous avez déployé.
- Sélectionnez l'onglet Test & Use (Test et utilisation) situé juste en dessous de la barre de titre.
-
Un message qui s'affiche dans une zone en haut de la page indique "Votre modèle est déployé. Vous pouvez vous en servir pour effectuer des requêtes de prédiction en ligne" ("Your model is deployed and is available for online prediction requests"). Sélectionnez l'option Update deployment (Mettre à jour le déploiement) à côté de ce message.
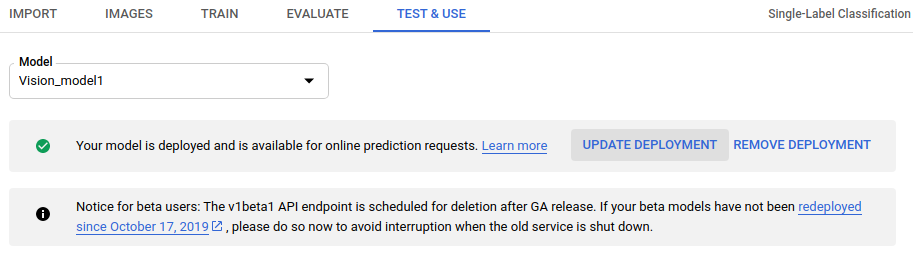
- Dans la fenêtre Mettre à jour le déploiement qui s'ouvre, sélectionnez le nouveau nombre de nœuds sur lesquels déployer votre modèle dans la liste. Les requêtes de prédiction estimées par seconde (RPS) sont affichées pour chaque nombre de nœuds.
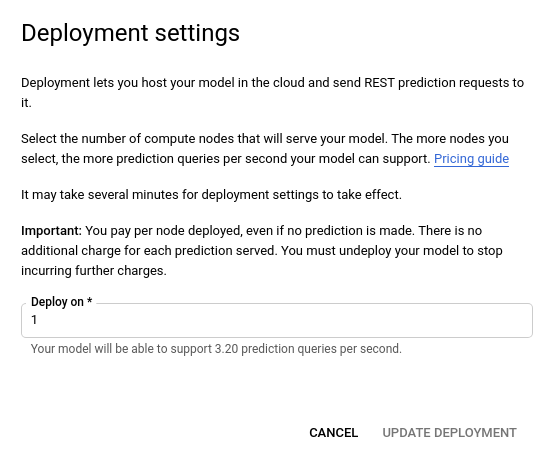
Après avoir sélectionné le nouveau nombre de nœuds dans la liste, sélectionnez Mettre à jour le déploiement pour mettre à jour le nombre de nœuds sur lesquels le modèle est déployé.
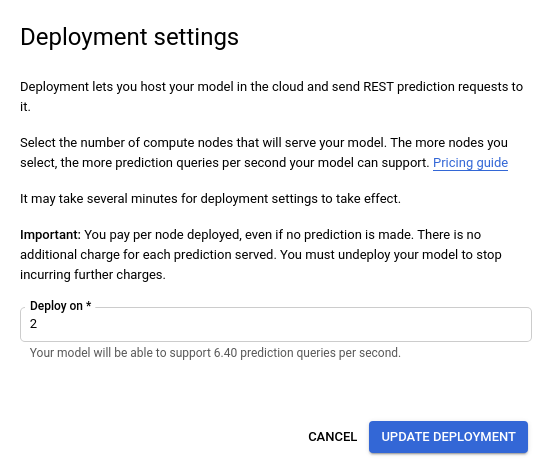
- Vous êtes redirigé vers la fenêtre Test et utilisation, qui affiche désormais la zone de texte "Déploiement du modèle…".
Une fois le modèle déployé sur le nouveau nombre de nœuds, vous recevez un e-mail à l'adresse associée à votre projet.
REST
La même méthode que celle utilisée initialement pour déployer un modèle sert également à modifier le numéro de nœud du modèle déployé.Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- project-id : ID de votre projet GCP.
- model-id : ID de votre modèle, issu de la réponse obtenue lors de sa création. L'ID est le dernier élément du nom du modèle.
Exemple :
- Nom du modèle :
projects/project-id/locations/location-id/models/IOD4412217016962778756 - ID du modèle :
IOD4412217016962778756
- Nom du modèle :
Remarques sur les champs :
nodeCount: nombre de nœuds sur lesquels déployer le modèle. La valeur doit être comprise entre 1 et 100 inclus. Un nœud est une abstraction d'une ressource de machine, qui peut gérer le nombre de requêtes de prédiction en ligne par seconde (RPS) stipulé dans l'élémentqps_per_nodedu modèle.
Méthode HTTP et URL :
POST https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy
Corps JSON de la requête :
{
"imageClassificationModelDeploymentMetadata": {
"nodeCount": 2
}
}
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy"
PowerShell
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy" | Select-Object -Expand Content
Des résultats semblables aux lignes suivantes devraient s'afficher : Vous pouvez obtenir l'état de la tâche à l'aide de l'ID de tâche. Pour consulter un exemple, reportez-vous à la section Travailler avec des opérations de longue durée.
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-08-07T22:00:20.692109Z",
"updateTime": "2019-08-07T22:00:20.692109Z",
"deployModelDetails": {}
}
}
Vous pouvez obtenir l'état d'une opération avec la méthode HTTP et l'URL suivantes :
GET https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID
L'état d'une opération terminée ressemblera à ce qui suit :
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-06-21T16:47:21.704674Z",
"updateTime": "2019-06-21T17:01:00.802505Z",
"deployModelDetails": {}
},
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
Go
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Java
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Node.js
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Python
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Langages supplémentaires
C# : Veuillez suivre les Instructions de configuration pour C# sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Vision pour C#.
PHP : Veuillez suivre les Instructions de configuration pour PHP sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Vision pour PHP.
Ruby : Veuillez suivre les Instructions de configuration pour Ruby sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Vision pour Ruby.