Dopo aver creato un modello AutoML Vision Edge e averlo esportato in un modello Bucket Cloud Storage cui puoi utilizzare i servizi RESTful Modelli AutoML Vision Edge e Immagini Docker basate su TF.
Cosa creerai
I container Docker possono aiutarti a eseguire facilmente il deployment di modelli perimetrali su diverse dispositivi mobili. Puoi eseguire modelli perimetrali chiamando le API REST dai container nella lingua che preferisci, con l'ulteriore vantaggio di non dover installare di dipendenze o trovare le versioni TensorFlow appropriate.
In questo tutorial, troverai una spiegazione passo passo nell'esecuzione di modelli periferici sui dispositivi utilizzando container Docker.
Nello specifico, questo tutorial ti guiderà attraverso tre passaggi:
- Creazione di container predefiniti.
- Esecuzione di container con modelli Edge per avviare API REST.
- per fare previsioni.
Molti dispositivi hanno solo CPU, mentre alcuni potrebbero avere GPU per per ottenere previsioni più rapide. Forniamo quindi tutorial con modelli container di CPU e GPU.
Obiettivi
In questa procedura dettagliata end-to-end introduttiva, utilizzerai esempi di codice per:
- Recupera il container Docker.
- Avvia le API REST utilizzando container Docker con modelli perimetrali.
- Fai previsioni per ottenere i risultati analizzati.
Prima di iniziare
Per completare questo tutorial, devi:
- Addestra un modello Edge esportabile. Segui le Guida rapida ai modelli di dispositivi Edge per addestrare un modello Edge un modello di machine learning.
- Esporta un modello AutoML Vision Edge. Questo modello con container come API REST.
- Installa Docker. Questo è il software richiesto per eseguire e i container Docker.
- (Facoltativo) Installa il docker e il driver NVIDIA. Questo passaggio è facoltativo se hanno dispositivi con GPU e vorrebbe ottenere previsioni più rapide.
- Prepara le immagini di test. Queste immagini verranno inviate nelle richieste per ottenere i risultati analizzati.
I dettagli per l'esportazione dei modelli e l'installazione del software necessario sono disponibili in sezione successiva.
Esporta modello AutoML Vision Edge
Dopo aver addestrato un modello Edge, puoi esportarlo su dispositivi diversi.
I container supportano i modelli TensorFlow,
denominate saved_model.pb
al momento dell'esportazione.
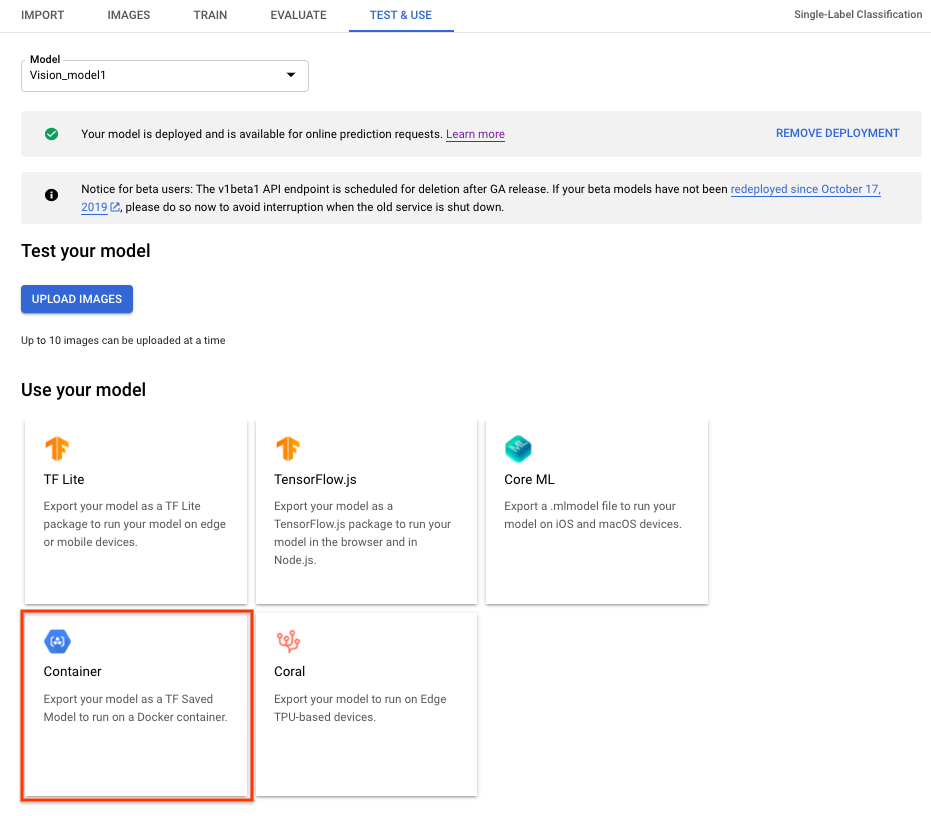
Per esportare un modello AutoML Vision Edge per i container, seleziona Container nella UI ed esporta modello per ${YOUR_MODEL_PATH} su Google di archiviazione ideale in Cloud Storage. Questo modello esportato in un secondo momento con i container come API REST.
Per scaricare il modello esportato in locale, esegui questo comando.
Dove:
- ${YOUR_MODEL_PATH} - La località del modello su Google Cloud Storage (ad esempio
gs://my-bucket-vcm/models/edge/ICN4245971651915048908/2020-01-20_01-27-14-064_tf-saved-model/) - ${YOUR_LOCAL_MODEL_PATH} - Il tuo percorso locale
dove vuoi scaricare il modello (ad esempio,
/tmp).
gcloud storage cp ${YOUR_MODEL_PATH} ${YOUR_LOCAL_MODEL_PATH}/saved_model.pb
Installa Docker
Docker è utilizzato per il deployment e l'esecuzione di applicazioni all'interno di container.
Installa Docker Community Edition (CE) sul tuo sistema. Potrai per gestire i modelli Edge come API REST.
Installa il driver NVIDIA e NVIDIA DOCKER (facoltativo, solo per GPU)
Alcuni dispositivi dispongono di GPU per fornire previsioni più rapide. Container Docker GPU supporta le GPU NVIDIA.
Per eseguire container GPU, devi installare il driver NVIDIA e NVIDIA Docker sul tuo sistema.
Esecuzione dell'inferenza del modello utilizzando la CPU
Questa sezione fornisce istruzioni dettagliate per eseguire le inferenze del modello utilizzando i container della CPU. Utilizzerai il Docker installato per recuperare ed eseguire il container della CPU per gestire i modelli Edge esportati come API REST, invia richieste di un'immagine di test alle API REST per ottenere i risultati analizzati.
Esegui il pull dell'immagine Docker
Innanzitutto, utilizzerai Docker per ottenere un container CPU predefinito. Il modello predefinito Il container della CPU include già l'intero ambiente per pubblicare i modelli Edge esportati, che non contiene ancora modelli Edge.
Il container con CPU predefinito è archiviato in Google Container Registry. Prima del giorno richiesta del container, imposta una variabile di ambiente per la località Google Container Registry:
export CPU_DOCKER_GCR_PATH=gcr.io/cloud-devrel-public-resources/gcloud-container-1.14.0:latest
Dopo aver impostato la variabile di ambiente per il percorso di Container Registry, esegui la seguente per ottenere il container della CPU:
sudo docker pull ${CPU_DOCKER_GCR_PATH}
Esegui il container Docker
Dopo aver ottenuto il container esistente, eseguirai questo container della CPU le inferenze del modello Edge con le API REST.
Prima di avviare il container della CPU, devi impostare le variabili di sistema:
- ${CONTAINER_NAME}: una stringa che indica il nome del container quando
in esecuzione, ad esempio
CONTAINER_NAME=automl_high_accuracy_model_cpu. - ${PORT}: un numero che indica la portabilità sul dispositivo da accettare
Chiamate API REST in un secondo momento, ad esempio
PORT=8501.
Dopo aver impostato le variabili, esegui Docker nella riga di comando per gestire il modello Edge le inferenze con le API REST:
sudo docker run --rm --name ${CONTAINER_NAME} -p ${PORT}:8501 -v ${YOUR_MODEL_PATH}:/tmp/mounted_model/0001 -t ${CPU_DOCKER_GCR_PATH}
Una volta che il container è in esecuzione, le API REST sono pronte
per la pubblicazione alle ore http://localhost:${PORT}/v1/models/default:predict. La
nella sezione seguente viene spiegato come inviare richieste di previsione a questa località.
Invia una richiesta di previsione
Ora che il container funziona correttamente, puoi inviare una previsione su un'immagine di test alle API REST.
Riga di comando
Il corpo della richiesta della riga di comando contiene image_bytes con codifica Base64 e una stringa key
per identificare l'immagine data. Consulta le
Argomento Codifica Base64 per saperne di più
informazioni sulla codifica delle immagini. Il formato del file JSON della richiesta è il seguente:
/tmp/request.json
{
"instances":
[
{
"image_bytes":
{
"b64": "/9j/7QBEUGhvdG9zaG9...base64-encoded-image-content...fXNWzvDEeYxxxzj/Coa6Bax//Z"
},
"key": "your-chosen-image-key"
}
]
}
Dopo aver creato un file di richiesta JSON locale, puoi inviare la previsione richiesta.
Utilizza il comando seguente per inviare la richiesta di previsione:
curl -X POST -d @/tmp/request.json http://localhost:${PORT}/v1/models/default:predict
Risposta
Dovresti vedere un output simile al seguente:
{
"predictions": [
{
"labels": ["Good", "Bad"],
"scores": [0.665018, 0.334982]
}
]
}
Python
Per ulteriori informazioni, consulta API AutoML Vision Python documentazione di riferimento.
Per eseguire l'autenticazione su AutoML Vision, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, vedi Configura l'autenticazione per un ambiente di sviluppo locale.
(Facoltativo) Esegui l'inferenza del modello utilizzando container GPU
Questa sezione mostra come eseguire le inferenze del modello utilizzando i container GPU. Questo è molto simile all'esecuzione dell'inferenza del modello utilizzando una CPU. La chiave le differenze sono il percorso del container GPU e il modo in cui vengono avviati i container GPU.
Esegui il pull dell'immagine Docker
Innanzitutto, utilizzerai Docker per ottenere un container GPU predefinito. Il modello predefinito Il container GPU dispone già dell'ambiente per gestire i modelli Edge esportati con GPU, che non contengono ancora modelli o driver Edge.
Il container con CPU predefinito è archiviato in Google Container Registry. Prima del giorno quando richiedi il container, imposta una variabile di ambiente per posizione in Google Container Registry:
export GPU_DOCKER_GCR_PATH=gcr.io/cloud-devrel-public-resources/gcloud-container-1.14.0-gpu:latest
Esegui questa riga di comando per recuperare il container GPU:
sudo docker pull ${GPU_DOCKER_GCR_PATH}
Esegui il container Docker
In questo passaggio verrà eseguito il container GPU per gestire le inferenze del modello Edge con le API REST. Devi installare il driver e la docker NVIDIA come indicato sopra. Devi inoltre impostare le seguenti variabili di sistema:
- ${CONTAINER_NAME}: una stringa che indica il nome del container quando
in esecuzione, ad esempio
CONTAINER_NAME=automl_high_accuracy_model_gpu. - ${PORT}: un numero che indica la portabilità sul dispositivo da accettare
Chiamate API REST in un secondo momento, ad esempio
PORT=8502.
Dopo aver impostato le variabili, esegui Docker nella riga di comando per gestire il modello Edge le inferenze con le API REST:
sudo docker run --runtime=nvidia --rm --name "${CONTAINER_NAME}" -v \
${YOUR_MODEL_PATH}:/tmp/mounted_model/0001 -p \
${PORT}:8501 -t ${GPU_DOCKER_GCR_PATH}
Una volta che il container è in esecuzione, le API REST sono pronte
per la pubblicazione in http://localhost:${PORT}/v1/models/default:predict. La
nella sezione seguente viene spiegato come inviare richieste di previsione a questa località.
Invia una richiesta di previsione
Ora che il container funziona correttamente, puoi inviare una previsione su un'immagine di test alle API REST.
Riga di comando
Il corpo della richiesta della riga di comando contiene image_bytes con codifica Base64 e una stringa key
per identificare l'immagine data. Consulta le
Argomento Codifica Base64 per saperne di più
informazioni sulla codifica delle immagini. Il formato del file JSON della richiesta è il seguente:
/tmp/request.json
{
"instances":
[
{
"image_bytes":
{
"b64": "/9j/7QBEUGhvdG9zaG9...base64-encoded-image-content...fXNWzvDEeYxxxzj/Coa6Bax//Z"
},
"key": "your-chosen-image-key"
}
]
}
Dopo aver creato un file di richiesta JSON locale, puoi inviare la previsione richiesta.
Utilizza il comando seguente per inviare la richiesta di previsione:
curl -X POST -d @/tmp/request.json http://localhost:${PORT}/v1/models/default:predict
Risposta
Dovresti vedere un output simile al seguente:
{
"predictions": [
{
"labels": ["Good", "Bad"],
"scores": [0.665018, 0.334982]
}
]
}
Python
Per ulteriori informazioni, consulta API AutoML Vision Python documentazione di riferimento.
Per eseguire l'autenticazione su AutoML Vision, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, vedi Configura l'autenticazione per un ambiente di sviluppo locale.
Riepilogo
In questo tutorial hai esaminato l'esecuzione di modelli Edge utilizzando la CPU o container Docker GPU. Ora puoi eseguire il deployment di questo container su più dispositivi.
Passaggi successivi
- Scopri di più su TensorFlow in generale nella documentazione Per iniziare di TensorFlow.
- Scopri di più sulla pubblicazione di TensorFlow.
- Scopri come utilizzare TensorFlow Serving con Kubernetes.