Wenn Sie Ihrer Vertex AI Vision App einen BigQuery-Connector hinzufügen, werden alle verbundenen App-Modellausgaben in die Zieltabelle aufgenommen.
Sie können entweder eine eigene BigQuery-Tabelle erstellen und diese angeben, wenn Sie der App einen BigQuery-Connector hinzufügen, oder die Tabelle automatisch von der Vertex AI Vision App-Plattform erstellen lassen.
Automatische Tabellenerstellung
Wenn Sie die Tabelle automatisch von der Vertex AI Vision App-Plattform erstellen lassen, können Sie diese Option beim Hinzufügen des BigQuery-Connector-Knotens angeben.
Die folgenden Dataset- und Tabellenbedingungen gelten, wenn Sie die automatische Tabellenerstellung verwenden möchten:
- Dataset: Der automatisch erstellte Name des Datasets lautet
visionai_dataset. - Tabelle: Der automatisch erstellte Tabellenname lautet
visionai_dataset.APPLICATION_ID. Fehlerbehandlung:
- Wenn die Tabelle mit demselben Namen im selben Dataset bereits vorhanden ist, wird sie nicht automatisch erstellt.
Console
Öffnen Sie den Tab Anwendungen des Vertex AI Vision-Dashboards.
Wählen Sie in der Liste neben dem Namen Ihrer Anwendung die Option App ansehen aus.
Wählen Sie auf der Seite „Application Builder“ im Bereich Connectors die Option BigQuery aus.
Lassen Sie das Feld BigQuery-Pfad leer.
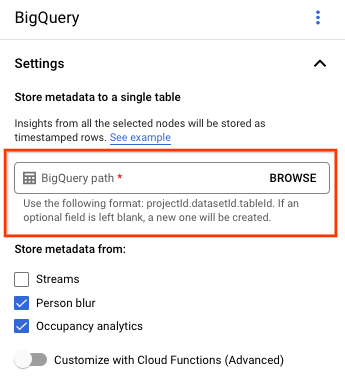
Ändern Sie sonst nichts.
REST UND BEFEHLSZEILE
Wenn Sie der App-Plattform erlauben möchten, ein Tabellenschema abzuleiten, verwenden Sie das Feld createDefaultTableIfNotExists von BigQueryConfig, wenn Sie eine App erstellen oder aktualisieren.
Tabelle manuell erstellen und angeben
Wenn Sie die Ausgabetabelle manuell verwalten möchten, muss die Tabelle das erforderliche Schema als Teil des Tabellenschemas haben.
Wenn die vorhandene Tabelle inkompatible Schemas hat, wird die Bereitstellung abgelehnt.
Standardschema verwenden
Wenn Sie das Standardschema für Modellausgabetabellen verwenden, muss Ihre Tabelle nur die folgenden erforderlichen Spalten enthalten. Sie können den folgenden Schematext direkt kopieren, wenn Sie die BigQuery-Tabelle erstellen. Weitere Informationen zum Erstellen einer BigQuery-Tabelle finden Sie unter Tabellen erstellen und verwenden. Weitere Informationen zur Schemaspezifikation beim Erstellen einer Tabelle finden Sie unter Schema angeben.
Verwenden Sie den folgenden Text, um das Schema beim Erstellen einer Tabelle zu beschreiben. Informationen zur Verwendung des Spaltentyps JSON ("type": "JSON") finden Sie unter Mit JSON-Daten in Standard-SQL arbeiten.
Der JSON-Spaltentyp wird für Annotationsabfragen empfohlen. Sie können aber auch "type" : "STRING" verwenden.
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "application",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "instance",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "node",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "annotation",
"type": "JSON",
"mode": "REQUIRED"
}
]
Google Cloud console
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Wählen Sie Ihr Projekt aus.
Wählen Sie das Dreipunkt-Menü aus.
Klicken Sie auf Tabelle erstellen.
Aktivieren Sie im Bereich „Schema“ die Option Als Text bearbeiten.
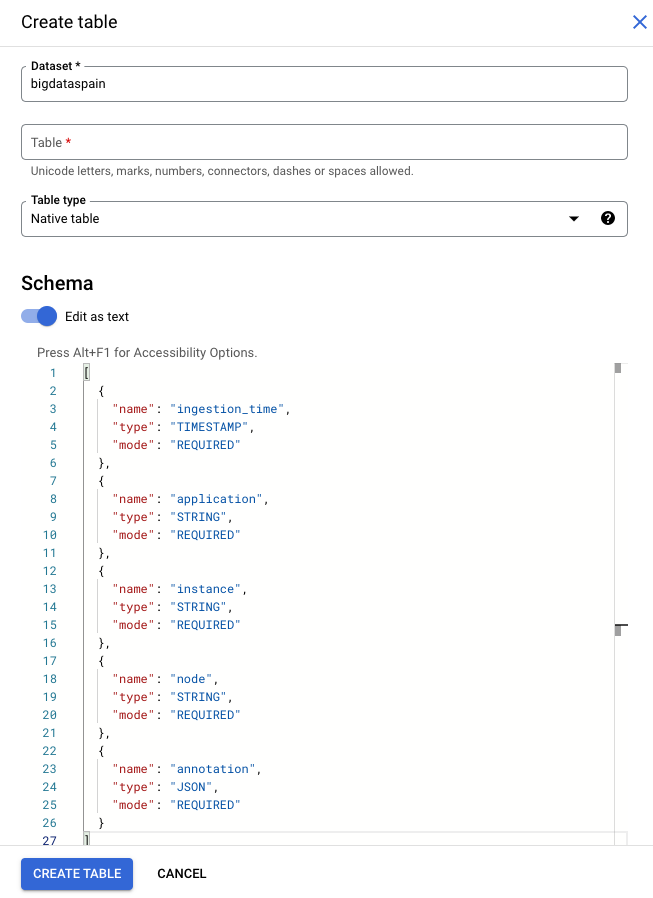
gcloud
Im folgenden Beispiel wird zuerst die JSON-Anfragedatei erstellt und dann der Befehl gcloud alpha bq tables create verwendet.
Erstellen Sie zuerst die JSON-Anfragedatei:
echo "{ \"schema\": [ { \"name\": \"ingestion_time\", \"type\": \"TIMESTAMP\", \"mode\": \"REQUIRED\" }, { \"name\": \"application\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"instance\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"node\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"annotation\", \"type\": \"JSON\", \"mode\": \"REQUIRED\" } ] } " >> bigquery_schema.jsonSenden Sie den Befehl
gcloud. Ersetzen Sie die folgenden Werte:TABLE_NAME: Die ID der Tabelle oder die voll qualifizierte Kennzeichnung für die Tabelle.
DATASET: Die ID des BigQuery-Datasets.
gcloud alpha bq tables create TABLE_NAME \ --dataset=DATASET \ --schema-file=./bigquery_schema.json
Beispiel für BigQuery-Zeilen, die von einer Vertex AI Vision-Anwendung generiert wurden:
| ingestion_time | Anwendung | Instanz | Knoten | Annotation |
|---|---|---|---|---|
| 2022-05-11 23:3211.911378 UTC | my_application | 5 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE1Eg5teV9hcHBsaWNhdGlvbgjS+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911338 UTC | my_application | 1 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgExEg5teV9hcHBsaWNhdGlvbgiq+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911313 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgiR+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3212.235327 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgi/3J3Ozdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
Benutzerdefiniertes Schema verwenden
Wenn das Standardschema für Ihren Anwendungsfall nicht geeignet ist, können Sie mit Cloud Run-Funktionen BigQuery-Zeilen mit einem benutzerdefinierten Schema generieren. Wenn Sie ein benutzerdefiniertes Schema verwenden, gibt es keine Voraussetzungen für das BigQuery-Tabellenschema.
App-Graph mit ausgewähltem BigQuery-Knoten
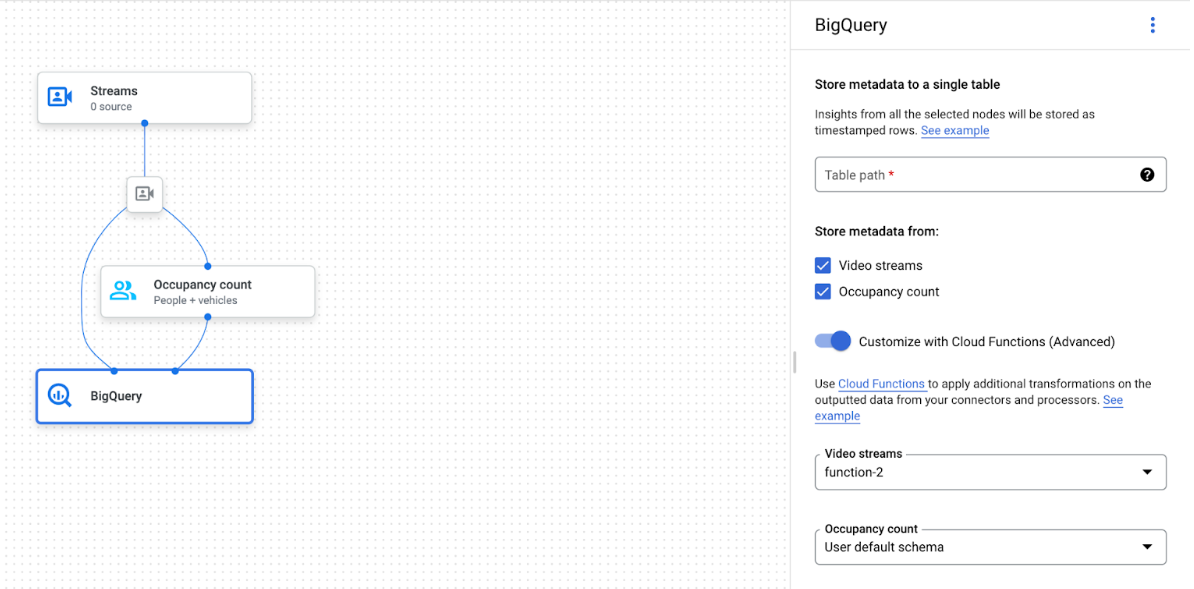
Der BigQuery-Connector kann mit jedem Modell verbunden werden, das video- oder protobasierte Anmerkungen ausgibt:
- Bei der Videoeingabe extrahiert der BigQuery-Connector nur die im Stream-Header gespeicherten Metadaten und nimmt diese Daten als andere Modellannotierungsausgaben in BigQuery auf. Das Video selbst wird nicht gespeichert.
- Wenn Ihr Stream keine Metadaten enthält, wird nichts in BigQuery gespeichert.
Tabellendaten abfragen
Mit dem Standardschema für BigQuery-Tabellen können Sie aussagekräftige Analysen durchführen, nachdem die Tabelle mit Daten gefüllt wurde.
Beispielabfragen
Mit den folgenden Beispielabfragen in BigQuery können Sie Statistiken zu Vertex AI Vision-Modellen abrufen.
Mit BigQuery können Sie beispielsweise mithilfe der folgenden Abfrage eine zeitbasierte Kurve für die maximale Anzahl der erkannten Personen pro Minute mit Daten aus dem Modell für Personen-/Fahrzeugerkennung zeichnen:
WITH nested3 AS( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["fullFrameCount"]) AS counts FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT ingestion_time, e FROM nested, UNNEST(nested.counts) AS e) SELECT STRING(TIMESTAMP_TRUNC(nested2.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested2.e["count"]), 0) AS person_count FROM nested2 WHERE JSON_VALUE(nested2.e["entity"]["labelString"])="Person") SELECT time, MAX(person_count) FROM nested3 GROUP BY time
Ebenso können Sie BigQuery und die Funktion „Anzahl der Fahrzeuge an der Haltelinie“ des Belegungsanalysemodells verwenden, um eine Abfrage zu erstellen, mit der die Gesamtzahl der Fahrzeuge gezählt wird, die pro Minute die Haltelinie passieren:
WITH nested4 AS ( WITH nested3 AS ( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["crossingLineCounts"]) AS lines FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT nested.ingestion_time, JSON_QUERY_ARRAY(line["positiveDirectionCounts"]) AS entities FROM nested, UNNEST(nested.lines) AS line WHERE JSON_VALUE(line.annotation.id) = "LINE_ANNOTATION_ID") SELECT ingestion_time, entity FROM nested2, UNNEST(nested2.entities) AS entity ) SELECT STRING(TIMESTAMP_TRUNC(nested3.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested3.entity["count"]), 0) AS vehicle_count FROM nested3 WHERE JSON_VALUE(nested3.entity["entity"]["labelString"])="Vehicle" ) SELECT time, SUM(vehicle_count) FROM nested4 GROUP BY time
Abfrage ausführen
Nachdem Sie Ihre Google Standard-SQL-Abfrage formatiert haben, können Sie sie über die Console ausführen:
Console
Öffnen Sie in der Google Cloud Console die Seite „BigQuery“.
Wählen Sie neben dem Namen des Datensatzes die Option Maximieren und dann den Namen der Tabelle aus.
Klicken Sie in der Detailansicht der Tabelle auf Neue Abfrage erstellen.

Geben Sie im Textbereich des Abfrageeditors eine Google Standard-SQL-Abfrage ein. Beispiele für Abfragen finden Sie hier.
Optional: Klicken Sie auf Mehr und dann auf Abfrageeinstellungen, um den Ort der Datenverarbeitung zu ändern. Klicken Sie unter Processing location (Verarbeitungsstandort) auf Auto-select (Automatische Auswahl) und wählen Sie den Standort Ihrer Daten aus. Klicken Sie abschließend auf Save (Speichern), um die Abfrageeinstellungen zu aktualisieren.
Klicken Sie auf Run (Ausführen).
Dies erstellt einen Abfragejob, der die Ausgabe in eine temporäre Tabelle schreibt.
Cloud Run-Funktionen-Integration
Sie können Cloud Run-Funktionen verwenden, die bei der benutzerdefinierten BigQuery-Aufnahme eine zusätzliche Datenverarbeitung auslösen. So verwenden Sie Cloud Run-Funktionen für die benutzerdefinierte BigQuery-Aufnahme:
Wählen Sie in der Google Cloud Console im Drop-down-Menü jedes verbundenen Modells die entsprechende Cloud-Funktion aus.
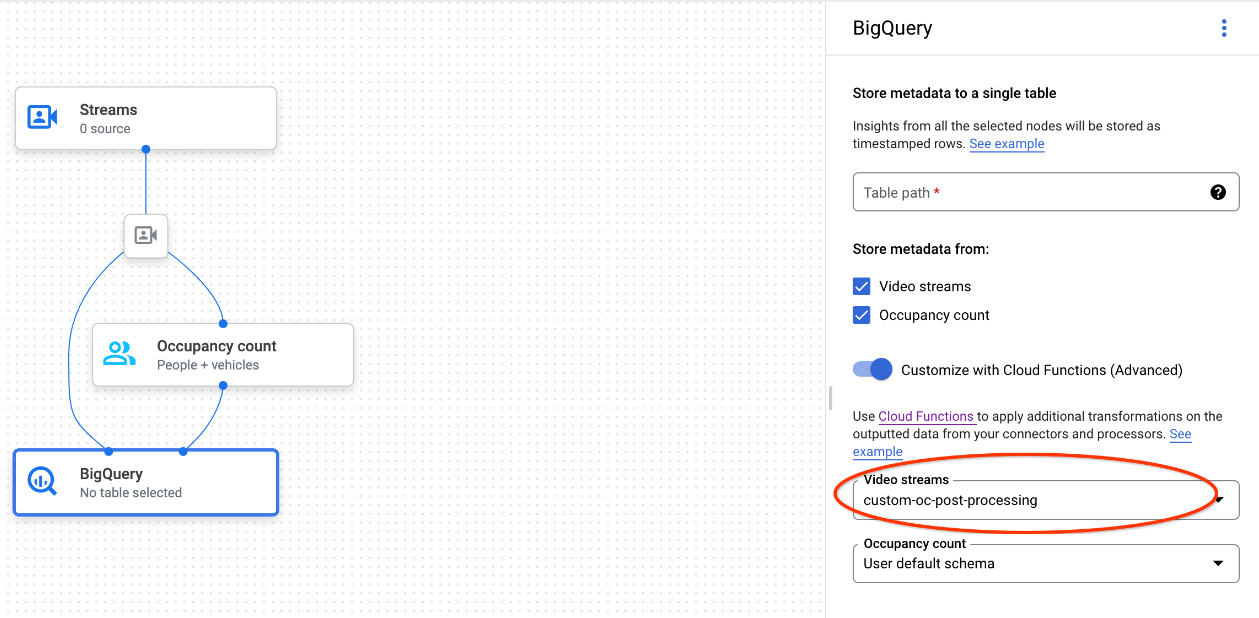
Wenn Sie die Vertex AI Vision API verwenden, fügen Sie dem Feld
cloud_function_mappingvonBigQueryConfigim BigQuery-Knoten ein Schlüssel/Wert-Paar hinzu. Der Schlüssel ist der Name des BigQuery-Knotens und der Wert ist der HTTP-Trigger der Zielfunktion.
Damit Sie Cloud Run-Funktionen mit Ihrer benutzerdefinierten BigQuery-Aufnahme verwenden können, muss die Funktion die folgenden Anforderungen erfüllen:
- Die Cloud Run-Funktions-Instanz muss erstellt werden, bevor Sie den BigQuery-Knoten erstellen.
- Die Vertex AI Vision API erwartet eine
AppendRowsRequest-Anmerkung, die von Cloud Run-Funktionen zurückgegeben wird. - Sie müssen das Feld
proto_rows.writer_schemafür alleCloudFunction-Antworten festlegen.write_streamkann ignoriert werden.
Beispiel für die Cloud Run Functions-Integration
Im folgenden Beispiel wird gezeigt, wie die Ausgabe des Knotens „Belegungszählung“ (OccupancyCountPredictionResult) geparst und daraus ein Tabellenschema für ingestion_time, person_count und vehicle_count extrahiert wird.
Das Ergebnis des folgenden Beispiels ist eine BigQuery-Tabelle mit dem Schema:
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "person_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "vehicle_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
]
Mit dem folgenden Code können Sie diese Tabelle erstellen:
Definieren Sie ein Proto (z. B.
test_table_schema.proto) für Tabellenfelder, die Sie schreiben möchten:syntax = "proto3"; package visionai.testing; message TestTableSchema { int64 ingestion_time = 1; int32 person_count = 2; int32 vehicle_count = 3; }Kompilieren Sie die Protodatei, um die Python-Datei für den Protokollpuffer zu generieren:
protoc -I=./ --python_out=./ ./test_table_schema.protoImportieren Sie die generierte Python-Datei und schreiben Sie die Cloud-Funktion.
Python
import base64 import sys from flask import jsonify import functions_framework from google.protobuf import descriptor_pb2 from google.protobuf.json_format import MessageToDict import test_table_schema_pb2 def table_schema(): schema = descriptor_pb2.DescriptorProto() test_table_schema_pb2.DESCRIPTOR.message_types_by_name[ 'TestTableSchema'].CopyToProto(schema) return schema def bigquery_append_row_request(row): append_row_request = {} append_row_request['protoRows'] = { 'writerSchema': { 'protoDescriptor': MessageToDict(table_schema()) }, 'rows': { 'serializedRows': base64.b64encode(row.SerializeToString()).decode('utf-8') } } return append_row_request @functions_framework.http def hello_http(request): request_json = request.get_json(silent=False) annotations = [] payloads = [] if request_json and 'annotations' in request_json: for annotation_with_timestamp in request_json['annotations']: row = test_table_schema_pb2.TestTableSchema() row.person_count = 0 row.vehicle_count = 0 if 'ingestionTimeMicros' in annotation_with_timestamp: row.ingestion_time = int( annotation_with_timestamp['ingestionTimeMicros']) if 'annotation' in annotation_with_timestamp: annotation = annotation_with_timestamp['annotation'] if 'stats' in annotation: stats = annotation['stats'] for count in stats['fullFrameCount']: if count['entity']['labelString'] == 'Person': if 'count' in count: row.person_count = count['count'] elif count['entity']['labelString'] == 'Vehicle': if 'count' in count: row.vehicle_count = count['count'] payloads.append(bigquery_append_row_request(row)) for payload in payloads: annotations.append({'annotation': payload}) return jsonify(annotations=annotations)
Wenn Sie Ihre Abhängigkeiten in Cloud Run-Funktionen einbeziehen möchten, müssen Sie auch die generierte
test_table_schema_pb2.py-Datei hochladen undrequirements.txtähnlich wie unten angegeben angeben:functions-framework==3.* click==7.1.2 cloudevents==1.2.0 deprecation==2.1.0 Flask==1.1.2 gunicorn==20.0.4 itsdangerous==1.1.0 Jinja2==2.11.2 MarkupSafe==1.1.1 pathtools==0.1.2 watchdog==1.0.2 Werkzeug==1.0.1 protobuf==3.12.2Stellen Sie die Cloud-Funktion bereit und legen Sie den entsprechenden HTTP-Trigger in
BigQueryConfigfest.