O LangChain na Vertex AI (Prévia) permite usar a biblioteca de código aberto LangChain para criar aplicativos personalizados de IA generativa e usar a Vertex AI para modelos, ferramentas e implantação. Com o LangChain na Vertex AI (pré-lançamento), é possível fazer o seguinte:
- Selecione o modelo de linguagem grande (LLM) com que você quer trabalhar.
- Definir as ferramentas para acessar APIs externas.
- Estruture a interface entre o usuário e os componentes do sistema em um framework de orquestração.
- Implantar o framework em um ambiente de execução gerenciado.
Benefícios
- Personalizável: usando as interfaces padronizadas do LangChain, o LangChain na Vertex AI pode ser adotado para criar diferentes tipos de aplicativos. É possível personalizar a lógica do aplicativo e incorporar qualquer framework, oferecendo um alto grau de flexibilidade.
- Simplifica a implantação: o LangChain na Vertex AI usa as mesmas APIs que o LangChain para interagir com LLMs e criar aplicativos. O LangChain na Vertex AI simplifica e acelera a implantação com LLMs da Vertex AI, já que o ambiente de execução do Reasoning Engine dá suporte à implantação de clique único para gerar uma API compatível com base na sua biblioteca.
- Integração com ecossistemas da Vertex AI: o Reasoning Engine para LangChain na Vertex AI usa a infraestrutura e os contêineres pré-criados da Vertex AI para ajudar na implantação do aplicativo LLM. É possível usar a API Vertex AI para integração com modelos do Gemini, chamadas de função e extensões.
- Seguro, particular e escalonável: é possível usar uma única chamada do SDK em vez de gerenciar o processo de desenvolvimento por conta própria. O ambiente de execução gerenciado do Reasoning Engine libera você de tarefas como desenvolvimento do servidor de aplicativos, criação de contêineres e configuração de autenticação, IAM e escalonamento. A Vertex AI lida com vulnerabilidades de contêiner, escalonamento automático e expansão regional.
Casos de uso
Para saber mais sobre o LangChain na Vertex AI com exemplos completos, consulte os seguintes recursos:
Componentes do sistema
Criar e implantar um aplicativo de IA personalizado usando o OSS LangChain e a Vertex Generative AI consiste em quatro componentes:
| Componente | Descrição |
|---|---|
| LLM |
Quando você envia uma consulta para seu aplicativo personalizado, o LLM a processa e fornece uma resposta. É possível definir um conjunto de ferramentas que se comuniquem com APIs externas e fornecê-las ao modelo. Ao processar uma consulta, o modelo delega algumas tarefas às ferramentas. Isso implica uma ou mais chamadas de modelo para modelos de fundação ou ajustados. Para saber mais, consulte Versões e ciclo de vida do modelo. |
| Ferramenta |
É possível definir um conjunto de ferramentas que se comunica com APIs externas (por exemplo, um banco de dados) e fornecê-las ao modelo. Ao processar uma consulta, o modelo pode delegar algumas tarefas às ferramentas. A implantação pelo ambiente de execução gerenciado da Vertex AI é otimizada para usar ferramentas baseadas na chamada de função do Gemini, mas oferece suporte à ferramenta LangChain/chamada de função. Para saber mais sobre como chamar uma função, consulte Chamada de função. |
| Framework de orquestração |
O LangChain na Vertex AI permite usar o framework de orquestração do LangChain na Vertex AI. Usar o LangChain para decidir o nível de determinismo do seu aplicativo. Se você já usa o LangChain, pode utilizar seu código existente do LangChain para implantar seu aplicativo na Vertex AI. Caso contrário, é possível criar seu próprio código de aplicativo e estruturá-lo em um framework de orquestração que usa os modelos LangChain da Vertex AI. Para saber mais, consulte Desenvolver um aplicativo. |
| Ambiente de execução gerenciado | O LangChain na Vertex AI permite implantar o aplicativo em um ambiente de execução gerenciado do Reasoning Engine. Esse ambiente de execução é um serviço da Vertex AI que tem todos os benefícios da integração da Vertex AI: segurança, privacidade, observabilidade e escalonabilidade. Você pode colocar o aplicativo em produção e escalonar o aplicativo com uma chamada de API, transformando rapidamente protótipos testados localmente em implantações prontas para a empresa. Para saber mais, consulte Implantar o aplicativo. |
Há muitas maneiras diferentes de prototipar e criar aplicativos personalizados de IA generativa que usam os recursos agentes, criando camadas para ferramentas, funções personalizadas e complementando modelos como o Gemini. Quando for a hora de mover o aplicativo para a produção, considere como implantar e gerenciar seu agente e todos os componentes subjacentes.
Com os componentes do LangChain na Vertex AI, o objetivo é ajudar você a se concentrar e personalizar os aspectos da funcionalidade do agente que são mais importantes para você, como funções personalizadas, comportamento do agente e parâmetros de modelos, enquanto o Google cuida da implantação, do empacotamento de escalonamento e das versões. Se você trabalha em um nível inferior na pilha, talvez precise gerenciar mais do que gostaria. Se você trabalha em um nível superior na pilha, talvez não tenha tanto controle do desenvolvedor quanto gostaria.
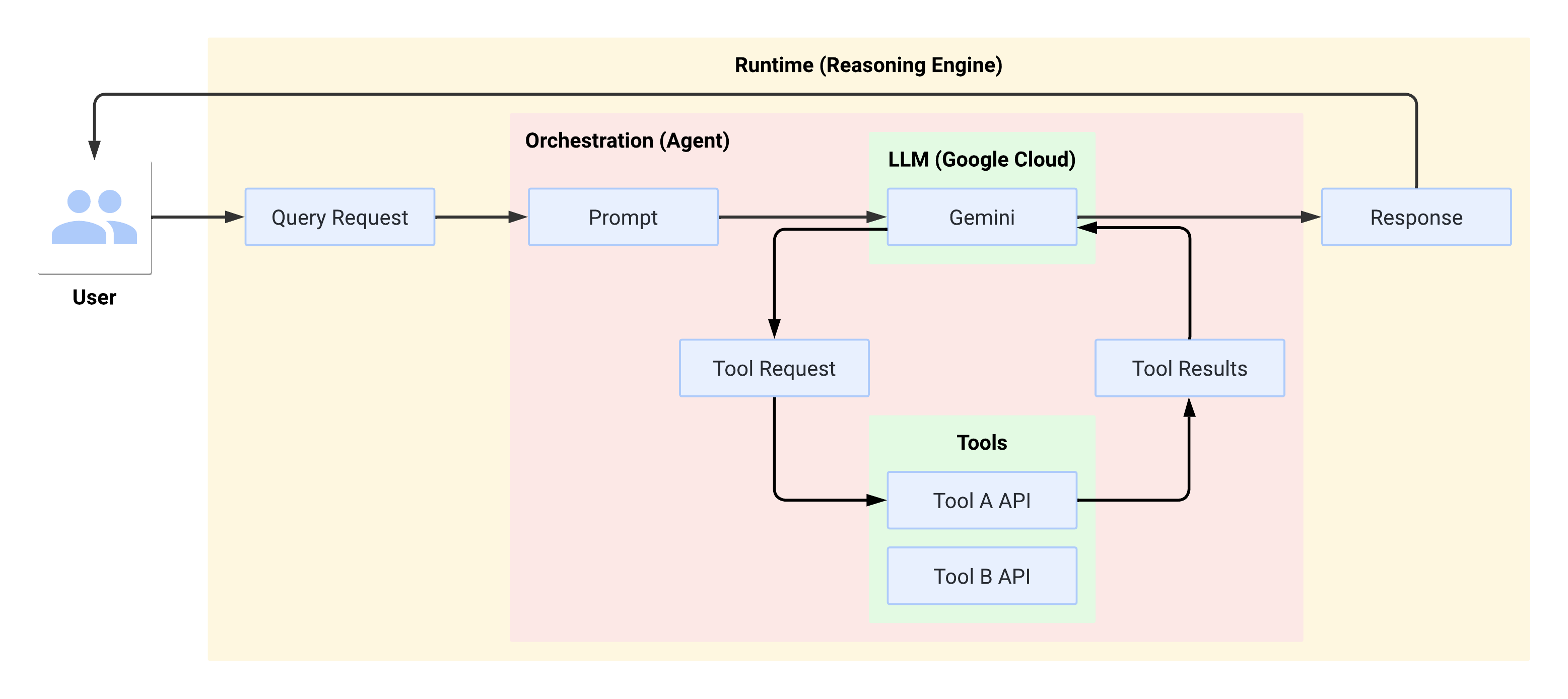
Fluxo do sistema no ambiente de execução
Quando o usuário faz uma consulta, ela é formatada pelo agente em um comando para o LLM. O LLM processa o comando e determina se quer usar alguma das ferramentas.
Se o LLM optar por usar uma ferramenta, ele gera um FunctionCall com o nome
e os parâmetros com que a ferramenta precisa ser chamada. O agente invoca a ferramenta
com o FunctionCall e fornece os resultados da ferramenta de volta ao LLM.
Se o LLM optar por não usar nenhuma ferramenta, ele vai gerar um conteúdo que será
transmitido pelo agente de volta ao usuário.
O diagrama a seguir ilustra o fluxo do sistema no ambiente de execução:
Criar e implantar um aplicativo de IA generativa
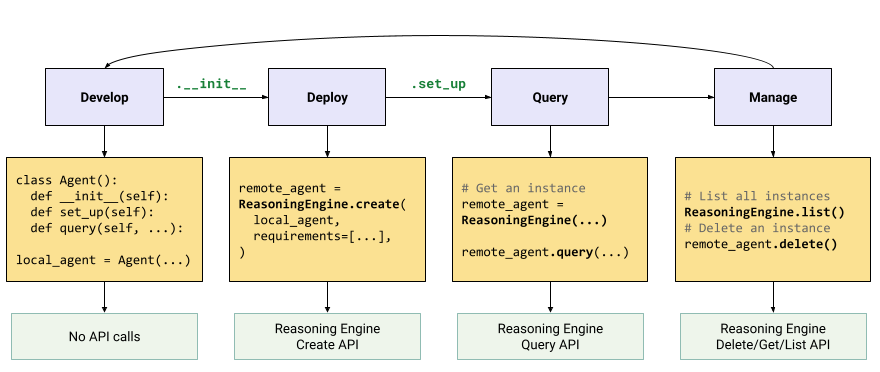
O fluxo de trabalho para criar aplicativos de IA generativa é:
| Etapas | Descrição |
|---|---|
| 1. configurar o ambiente | Configure o projeto do Google e instale a versão mais recente do SDK da Vertex AI para Python. |
| 2. desenvolver um aplicativo | Desenvolver um aplicativo LangChain que possa ser implantado no Reasoning Engine. |
| 3. Implante o aplicativo | Implantar o aplicativo no Reasoning Engine. |
| 4. usar o aplicativo | Mecanismo de raciocínio de consulta para uma resposta. |
| 5. gerenciar o aplicativo implantado | Gerencie e exclua os aplicativos que você implantou no Reasoning Engine. |
| 6. (Opcional) Personalizar um modelo de aplicativo | Personalize um modelo para novos aplicativos. |
As etapas estão ilustradas no diagrama a seguir:
Preços
A estrutura de preços é baseada em horas de vCPU e horas de GiB usadas durante o processamento da solicitação, a inicialização e o encerramento do contêiner. Isso significa que você vai receber cobranças pelos recursos de computação (vCPU) e memória consumidos pelas cargas de trabalho.
Recomendamos que você exclua os recursos não utilizados para evitar custos indesejados.