Gemini API のコード実行機能を使用すると、モデルは Python コードを生成して実行し、最終的な出力に到達するまで結果から反復的に学習できます。このコード実行機能を使用すると、コードベースの推論を活用し、テキスト出力を生成するアプリケーションを構築できます。たとえば、方程式を解くアプリケーションやテキストを処理するアプリケーションでコード実行を使用できます。
Gemini API は、関数呼び出しと同様に、コード実行をツールとして提供します。コード実行をツールとして追加すると、モデルがコード実行を使用するタイミングを決定します。
コード実行環境には、次のライブラリが含まれています。独自のライブラリをインストールすることはできません。
- Altair
- Chess
- Cv2
- Matplotlib
- Mpmath
- NumPy
- Pandas
- Pdfminer
- Reportlab
- Seaborn
- Sklearn
- Statsmodels
- Striprtf
- SymPy
- Tabulate
サポートされているモデル
次のモデルはコード実行をサポートしています。
- Gemini 2.5 Flash (プレビュー)
- Gemini 2.5 Flash-Lite (プレビュー)
- Gemini 2.5 Flash-Lite
- Live API を使用した Gemini 2.0 Flash (プレビュー)
- Gemini 2.5 Pro
- Gemini 2.5 Flash
- Gemini 2.0 Flash
コード実行の開始
このセクションは、Gemini API のクイックスタートに記載されている設定と構成手順が完了していることを前提としています。
モデルでのコード実行を有効にする
基本的なコード実行は、次のように有効にできます。
Python
インストール
pip install --upgrade google-genai
詳しくは、SDK リファレンス ドキュメントをご覧ください。
Vertex AI で Gen AI SDK を使用するための環境変数を設定します。
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
Go をインストールまたは更新する方法について学びます。
詳しくは、SDK リファレンス ドキュメントをご覧ください。
Vertex AI で Gen AI SDK を使用するための環境変数を設定します。
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Node.js
インストール
npm install @google/genai
詳しくは、SDK リファレンス ドキュメントをご覧ください。
Vertex AI で Gen AI SDK を使用するための環境変数を設定します。
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Java
Java をインストールまたは更新します。
詳しくは、SDK リファレンス ドキュメントをご覧ください。
Vertex AI で Gen AI SDK を使用するための環境変数を設定します。
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
リクエストのデータを使用する前に、次のように置き換えます。
GENERATE_RESPONSE_METHOD: モデルに生成させるレスポンスのタイプ。モデルのレスポンスを返す方法を生成するメソッドを選択します。streamGenerateContent: レスポンスは生成時にストリーミングされます。ユーザーが遅延を感じることは少なくなります。generateContent: レスポンスは、完全に生成された後に返されます。
LOCATION: リクエストを処理するリージョン。使用できる選択肢は以下のとおりです。クリックして、利用可能なリージョンの一部を開く
us-central1us-west4northamerica-northeast1us-east4us-west1asia-northeast3asia-southeast1asia-northeast1
PROJECT_ID: 実際のプロジェクト ID。MODEL_ID: 使用するモデルのモデル ID。ROLE: コンテンツに関連付けられた会話におけるロール。単一ターンのユースケースでも、ロールの指定が必要です。指定できる値は以下のとおりです。USER: 送信するコンテンツを指定します。MODEL: モデルのレスポンスを指定します。
TEXT
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
リクエスト本文を request.json という名前のファイルに保存します。ターミナルで次のコマンドを実行して、このファイルを現在のディレクトリに作成または上書きします。
cat > request.json << 'EOF'
{
"tools": [{'codeExecution': {}}],
"contents": {
"role": "ROLE",
"parts": { "text": "TEXT" }
},
}
EOFその後、次のコマンドを実行して REST リクエストを送信します。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:GENERATE_RESPONSE_METHOD"
PowerShell
リクエスト本文を request.json という名前のファイルに保存します。ターミナルで次のコマンドを実行して、このファイルを現在のディレクトリに作成または上書きします。
@'
{
"tools": [{'codeExecution': {}}],
"contents": {
"role": "ROLE",
"parts": { "text": "TEXT" }
},
}
'@ | Out-File -FilePath request.json -Encoding utf8その後、次のコマンドを実行して REST リクエストを送信します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:GENERATE_RESPONSE_METHOD" | Select-Object -Expand Content
次のような JSON レスポンスが返されます。
チャットでコード実行を使用する
コード実行をチャットの一部として使用することもできます。
REST
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://aiplatform.googleapis.com/v1/projects/test-project/locations/global/publishers/google/models/gemini-2.0-flash-001:generateContent -d \
$'{
"tools": [{'code_execution': {}}],
"contents": [
{
"role": "user",
"parts": {
"text": "Can you print \"Hello world!\"?"
}
},
{
"role": "model",
"parts": [
{
"text": ""
},
{
"executable_code": {
"language": "PYTHON",
"code": "\nprint(\"hello world!\")\n"
}
},
{
"code_execution_result": {
"outcome": "OUTCOME_OK",
"output": "hello world!\n"
}
},
{
"text": "I have printed \"hello world!\" using the provided python code block. \n"
}
],
},
{
"role": "user",
"parts": {
"text": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50."
}
}
]
}'
コード実行と関数呼び出し
コード実行と関数呼び出しは類似した機能です。
- コード実行では、モデルは固定された隔離環境で API バックエンドのコードを実行できます。
- 関数呼び出しでは、モデルがリクエストする関数を任意の環境で実行できます。
一般に、ユースケースに対処できる場合は、コード実行を使用することをおすすめします。コード実行は使いやすく(有効にするだけです)、1 回の GenerateContent リクエストで解決されます。関数呼び出しでは、各関数呼び出しの出力を返すために追加の GenerateContent リクエストが必要です。
ほとんどの場合、ローカルで実行する独自の関数がある場合は関数呼び出しを使用し、API で Python コードを記述して実行し、結果を返すようにする場合はコード実行を使用する必要があります。
課金
Gemini API からのコード実行を有効にしても、追加料金は発生しません。使用している Gemini モデルに基づいて、入力トークンと出力トークンの現在のレートで課金されます。
コード実行の課金に関するその他の注意事項は次のとおりです。
- モデルに渡す入力トークンと、コード実行ツールの使用によって生成された中間入力トークンに対しては、一度だけ課金されます。
- API レスポンスで返された最終出力トークンに対して課金されます。
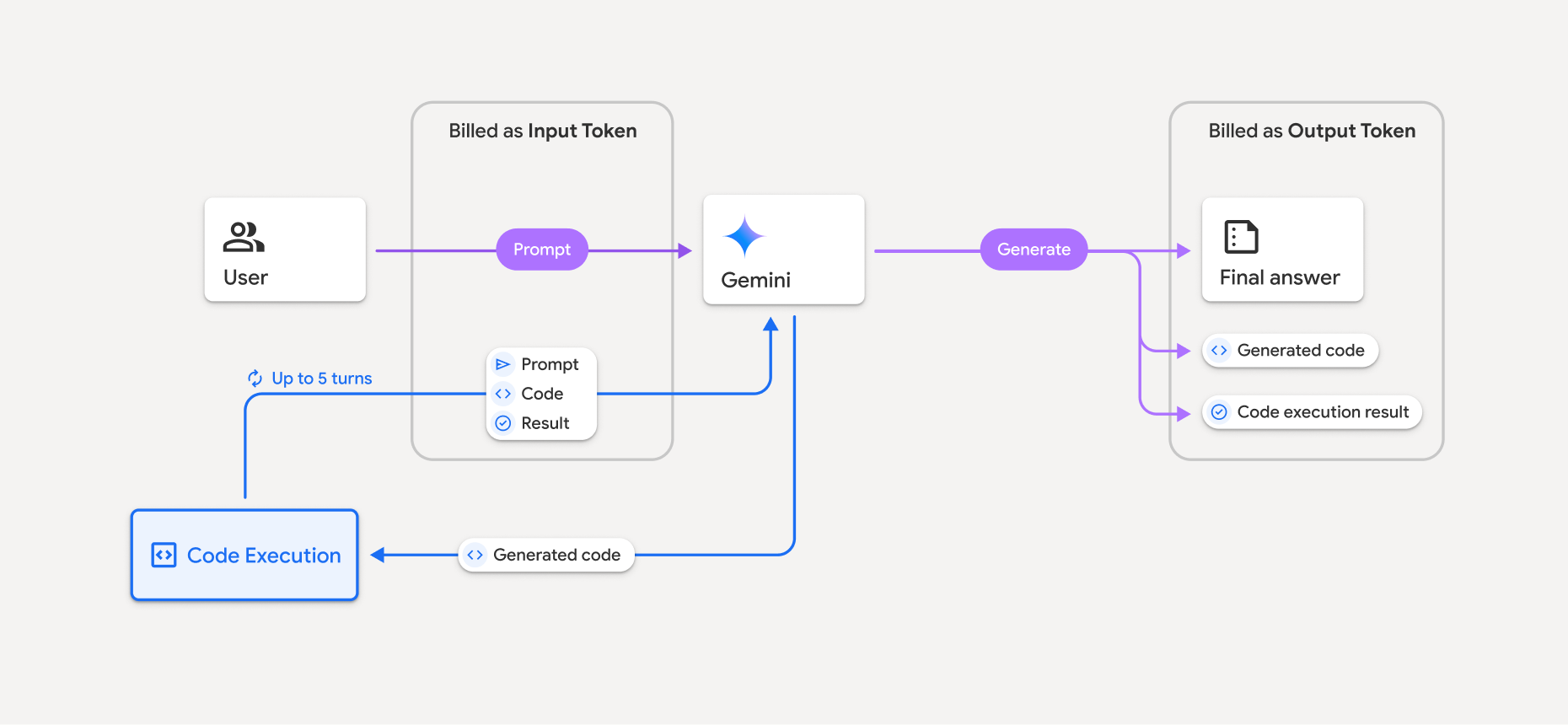
- 使用している Gemini モデルに基づいて、入力トークンと出力トークンの現在のレートで課金されます。
- Gemini がレスポンスの生成時にコード実行を使用する場合、元のプロンプト、生成されたコード、実行されたコードの結果には中間トークンというラベルが付けられ、入力トークンとして課金されます。
- Gemini は次に要約を生成し、生成されたコード、実行されたコードの結果、最終的な要約を返します。これらは出力トークンとして課金されます。
- Gemini API の API レスポンスには中間トークン数が含まれるため、最初のプロンプトで渡されたトークン以外の、追加の入力トークンを追跡できます。
生成されたコードには、テキストとマルチモーダル出力(画像など)の両方を含めることができます。
制限事項
- モデルはコードの生成と実行のみが可能です。メディア ファイルなど、他のアーティファクトを返すことはできません。
- コード実行ツールは、ファイル URI を入出力としては扱えません。ただし、ファイル入力と、グラフをインラインのバイトデータとして出力することは可能です。これらの入出力機能を使用すると、CSV ファイルとテキスト ファイルをアップロードし、ファイルに関する質問をしたり、コード実行結果の一部として Matplotlib グラフを生成したりできます。インライン バイトでサポートされている MIME タイプは、
.cpp、.csv、.java、.jpeg、.js、.png、.py、.ts、.xmlです。 - コード実行は、タイムアウトするまで最大 30 秒間実行できます。
- コード実行を有効にすると、モデル出力の他の領域(ストーリーの作成など)で回帰が発生することがあります。