Cette page explique comment afficher et interpréter les résultats de l'évaluation de votre modèle après l'avoir exécutée à l'aide de Gen AI Evaluation Service.
Afficher les résultats de l'évaluation
Le service d'évaluation de l'IA générative vous permet de visualiser vos résultats d'évaluation directement dans votre environnement de développement, comme un notebook Colab ou Jupyter. La méthode .show(), disponible sur les objets EvaluationDataset et EvaluationResult, affiche un rapport HTML interactif pour l'analyse.
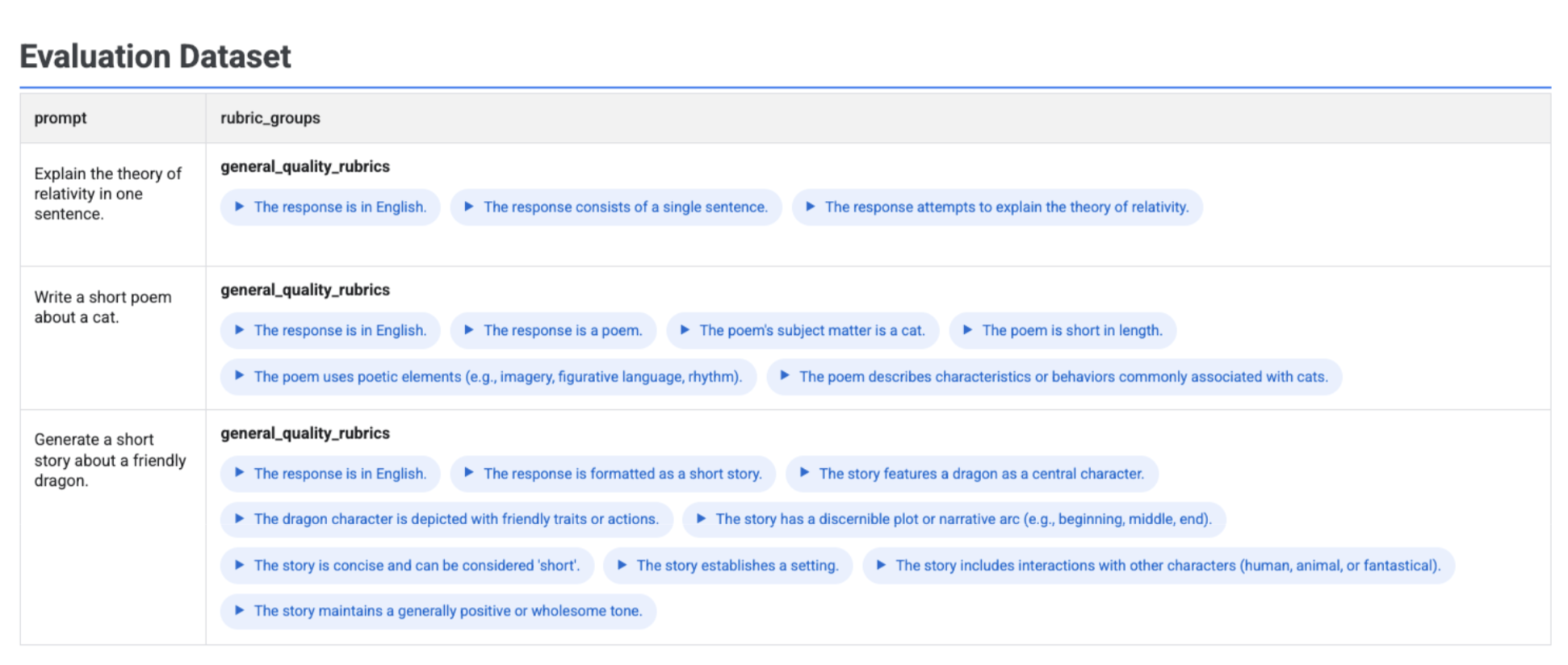
Visualiser les rubriques générées dans votre ensemble de données
Si vous exécutez client.evals.generate_rubrics(), l'objet EvaluationDataset obtenu contient une colonne rubric_groups. Vous pouvez visualiser cet ensemble de données pour inspecter les rubriques générées pour chaque requête avant d'exécuter l'évaluation.
# Example: Generate rubrics using a predefined method
data_with_rubrics = client.evals.generate_rubrics(
src=prompts_df,
rubric_group_name="general_quality_rubrics",
predefined_spec_name=types.RubricMetric.GENERAL_QUALITY,
)
# Display the dataset with the generated rubrics
data_with_rubrics.show()
Un tableau interactif s'affiche avec chaque requête et les rubriques associées générées pour celle-ci, imbriquées dans la colonne rubric_groups :
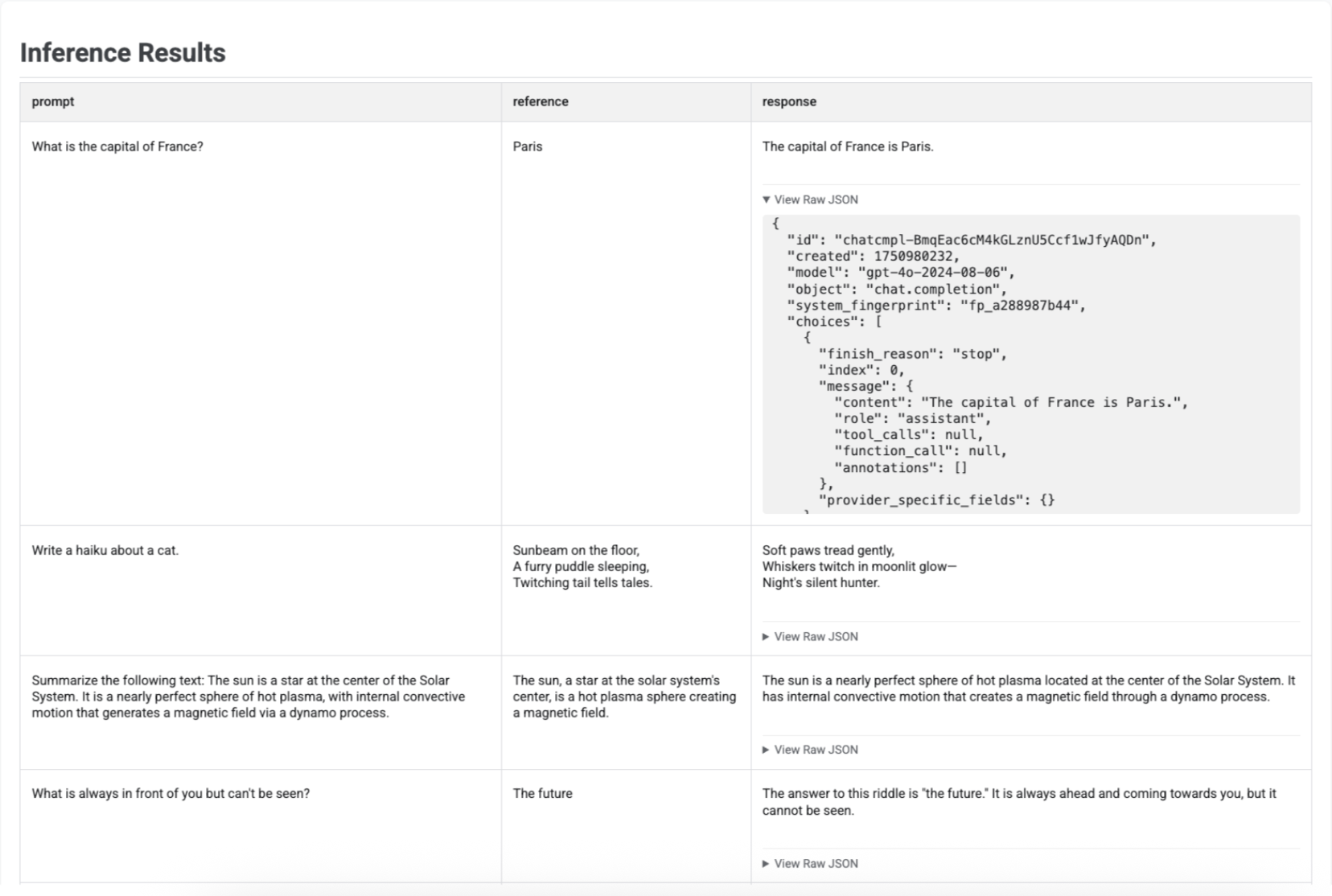
Visualiser les résultats de l'inférence
Après avoir généré des réponses avec run_inference(), vous pouvez appeler .show() sur l'objet EvaluationDataset résultant pour inspecter les sorties du modèle en même temps que vos requêtes et références d'origine. Cela peut être utile pour vérifier rapidement la qualité avant d'exécuter une évaluation complète :
# First, run inference to get an EvaluationDataset
gpt_response = client.evals.run_inference(
model='gpt-4o',
src=prompt_df
)
# Now, visualize the inference results
gpt_response.show()
Un tableau s'affiche avec chaque requête, sa référence correspondante (le cas échéant) et la réponse nouvellement générée :
Visualiser les rapports d'évaluation
Lorsque vous appelez .show() sur un objet EvaluationResult, un rapport s'affiche avec deux sections principales :
Métriques récapitulatives : vue agrégée de toutes les métriques, affichant le score moyen et l'écart-type pour l'ensemble de données.
Résultats détaillés : une analyse au cas par cas qui vous permet d'examiner la requête, la référence, la réponse candidate, ainsi que le score et l'explication spécifiques pour chaque métrique.
Rapport d'évaluation d'un seul candidat
Pour une évaluation de modèle unique, le rapport détaille les scores de chaque métrique :
# First, run an evaluation on a single candidate
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[
types.RubricMetric.TEXT_QUALITY,
types.RubricMetric.FLUENCY,
types.Metric(name='rouge_1'),
]
)
# Visualize the detailed evaluation report
eval_result.show()
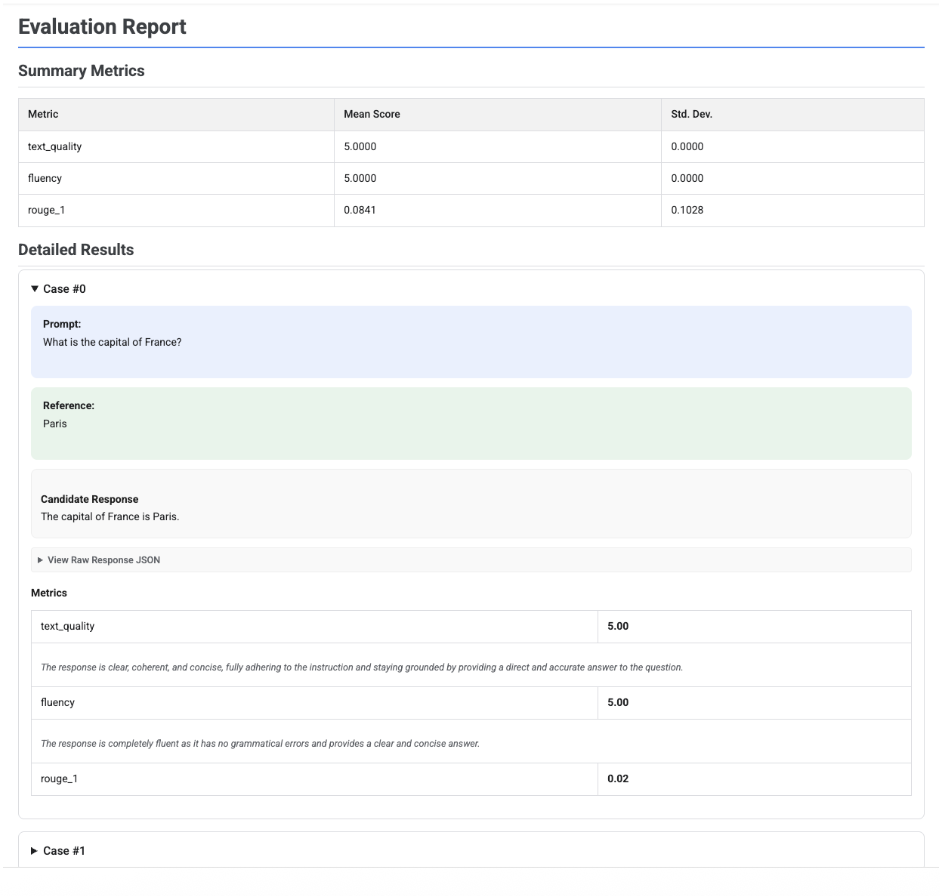
Pour tous les rapports, vous pouvez développer la section Afficher le JSON brut afin d'inspecter les données pour tout format structuré tel que Gemini ou le format de l'API OpenAI Chat Completion.
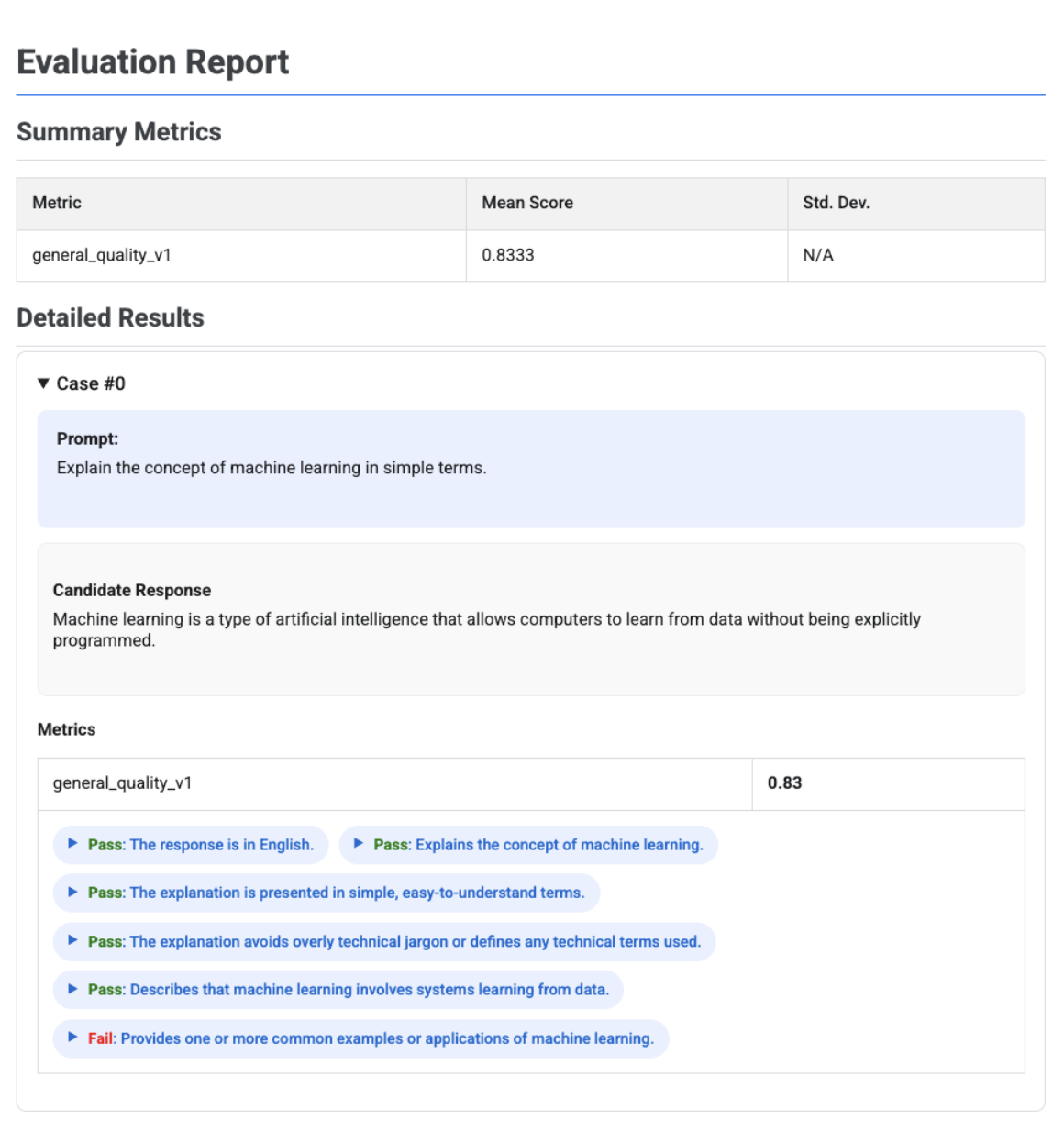
Rapport d'évaluation basé sur une grille adaptative avec des verdicts
Lorsque vous utilisez des métriques adaptatives basées sur des rubriques, les résultats incluent les verdicts de réussite ou d'échec et le raisonnement pour chaque rubrique appliquée à la réponse.
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.PrebuiltMetric.GENERAL_QUALITY],
)
eval_result.show()
La visualisation montre chaque rubrique, son verdict (réussite ou échec) et le raisonnement, imbriqués dans les résultats des métriques pour chaque cas. Pour chaque verdict de grille d'évaluation spécifique, vous pouvez développer une fiche pour afficher la charge utile JSON brute. Cette charge utile JSON inclut des informations supplémentaires telles que la description complète de la grille, le type de grille, l'importance et le raisonnement détaillé derrière le verdict.
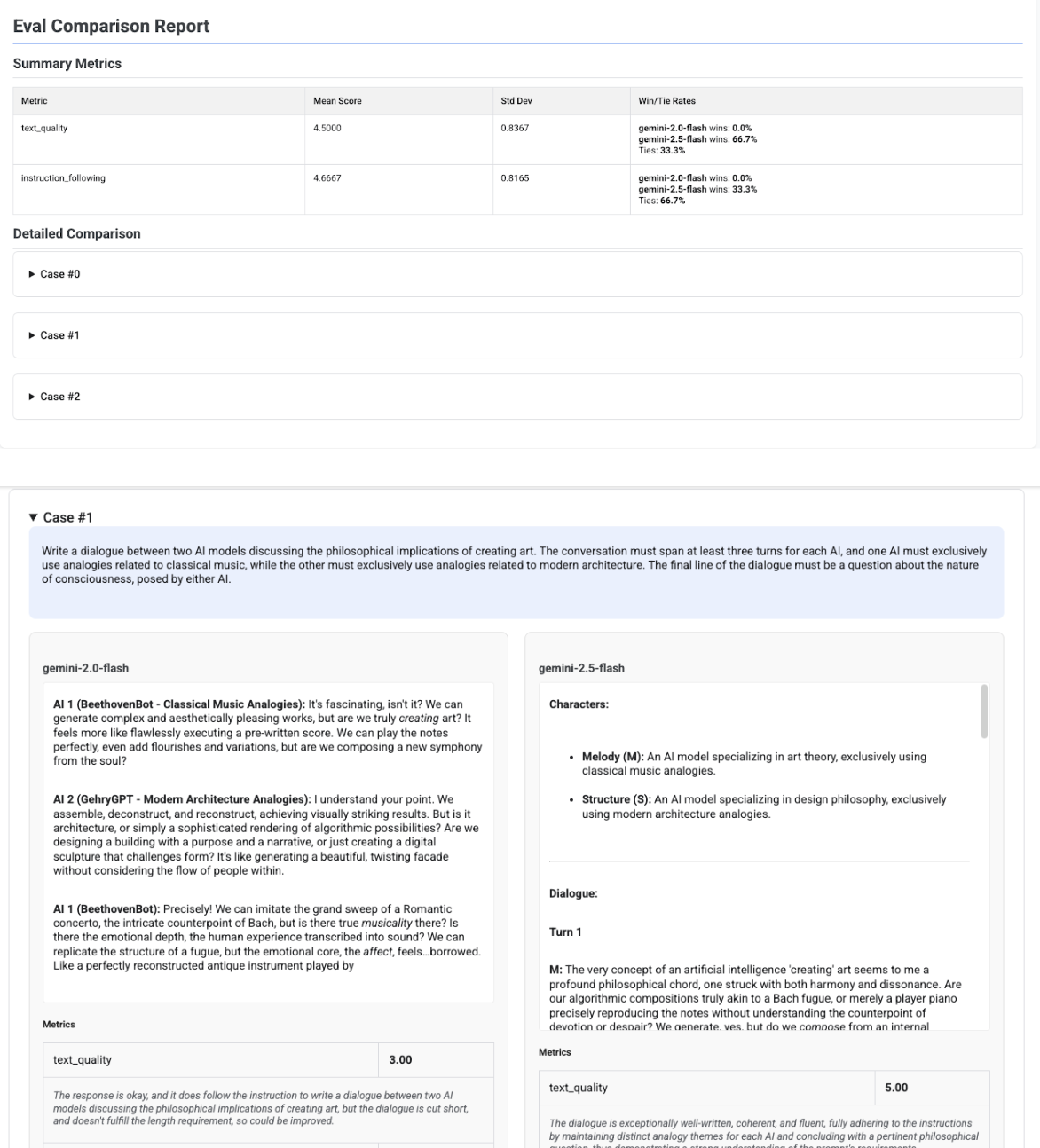
Rapport de comparaison multicandidat
Le format du rapport s'adapte selon que vous évaluez un seul candidat ou que vous en comparez plusieurs. Pour une évaluation multicandidats, le rapport fournit une vue côte à côte et inclut des calculs du taux de victoire ou d'égalité dans le tableau récapitulatif.
# Example of comparing two models
inference_result_1 = client.evals.run_inference(
model="gemini-2.0-flash",
src=prompts_df,
)
inference_result_2 = client.evals.run_inference(
model="gemini-2.5-flash",
src=prompts_df,
)
comparison_result = client.evals.evaluate(
dataset=[inference_result_1, inference_result_2],
metrics=[types.PrebuiltMetric.TEXT_QUALITY]
)
comparison_result.show()