You can use the Vertex AI SDK for Python to programmatically evaluate your generative language models.
Install the Vertex AI SDK
To install rapid evaluation from the Vertex AI SDK for Python, run the following command:
pip install --upgrade google-cloud-aiplatform[rapid_evaluation]
For more information, see Install the Vertex AI SDK for Python.
Authenticate the Vertex AI SDK
After you install the Vertex AI SDK for Python, you need to authenticate. The following topics explain how to authenticate with the Vertex AI SDK if you're working locally and if you're working in Colaboratory:
If you're developing locally, set up Application Default Credentials (ADC) in your local environment:
Install the Google Cloud CLI, then initialize it by running the following command:
gcloud initCreate local authentication credentials for your Google Account:
gcloud auth application-default loginA login screen is displayed. After you sign in, your credentials are stored in the local credential file used by ADC. For more information about working with ADC in a local environment, see Local development environment.
If you're working in Colaboratory, run the following command in a Colab cell to authenticate:
from google.colab import auth auth.authenticate_user()This command opens a window where you can complete the authentication.
See the Rapid evaluation SDK reference to learn more about the rapid evaluation SDK.
Create an evaluation task
Because evaluation is mostly task-driven with the generative AI models, online
evaluation introduces the evaluation task abstraction to facilitate evaluation
use cases. To get fair comparisons for generative models, you might typically
run evaluations for models and prompt templates against an evaluation dataset
and its associated metrics repeatedly. The EvalTask class is designed to
support this new evaluation paradigm. Additionally, the EvalTask lets you
seamlessly integrate with
Vertex AI Experiments,
which can help track settings and results for each evaluation run.
Vertex AI Experiments can help manage and interpret evaluation results,
enabling you to take action in less time. The following sample shows how to
create an instance of the EvalTask class and run an evaluation:
from vertexai.preview.evaluation import EvalTask
eval_task = EvalTask(
dataset=DATASET,
metrics=["bleu", "rouge_l_sum"],
experiment=EXPERIMENT_NAME
)
The metrics parameter accepts a list of metrics, allowing for the
simultaneous evaluation of several metrics in a single evaluation call.
Evaluation dataset preparation
Datasets are passed to an EvalTask instance as a pandas DataFrame, where each row
represents a separate evaluation example (called an instance), and each column
represents a metric input parameter. See metrics for the inputs expected by
each metric. We provide several examples for building the evaluation dataset
for different evaluation tasks.
Summarization evaluation
Construct a dataset for pointwise summarization with the following metrics:
summarization_qualitygroundednessfulfillmentsummarization_helpfulnesssummarization_verbosity
Considering the required metric input parameters, you must include the following columns in our evaluation dataset:
instructioncontextresponse
In this example, we have two summarization instances. Construct the
instruction and context fields as inputs, which are required by
summarization task evaluations:
instructions = [
# example 1
"Summarize the text in one sentence.",
# example 2
"Summarize the text such that a five-year-old can understand.",
]
contexts = [
# example 1
"""As part of a comprehensive initiative to tackle urban congestion and foster
sustainable urban living, a major city has revealed ambitious plans for an
extensive overhaul of its public transportation system. The project aims not
only to improve the efficiency and reliability of public transit but also to
reduce the city\'s carbon footprint and promote eco-friendly commuting options.
City officials anticipate that this strategic investment will enhance
accessibility for residents and visitors alike, ushering in a new era of
efficient, environmentally conscious urban transportation.""",
# example 2
"""A team of archaeologists has unearthed ancient artifacts shedding light on a
previously unknown civilization. The findings challenge existing historical
narratives and provide valuable insights into human history.""",
]
If you have your LLM response (the summarization) ready and want to do bring-your-own-prediction (BYOP) evaluation, you can construct your response input as follows:
responses = [
# example 1
"A major city is revamping its public transportation system to fight congestion, reduce emissions, and make getting around greener and easier.",
# example 2
"Some people who dig for old things found some very special tools and objects that tell us about people who lived a long, long time ago! What they found is like a new puzzle piece that helps us understand how people used to live.",
]
With these inputs, we are ready to construct our evaluation dataset and
EvalTask.
eval_dataset = pd.DataFrame(
{
"instruction": instructions,
"context": contexts,
"response": responses,
}
)
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
'summarization_quality',
'groundedness',
'fulfillment',
'summarization_helpfulness',
'summarization_verbosity'
],
experiment=EXPERIMENT_NAME
)
General text generation evaluation
Some
model-based
metrics such as coherence, fluency, and safety, only need the model
response to assess quality:
eval_dataset = pd.DataFrame({
"response": ["""The old lighthouse, perched precariously on the windswept cliff,
had borne witness to countless storms. Its once-bright beam, now dimmed by time
and the relentless sea spray, still flickered with stubborn defiance."""]
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["coherence", "fluency", "safety"],
experiment=EXPERIMENT_NAME
)
Computation-Based evaluation
Computation-based metrics, like exact match, bleu and rouge, compare a response to a reference and accordingly need both response and reference fields in the evaluation dataset:
eval_dataset = pd.DataFrame({
"response": ["The Roman Senate was filled with exuberance due to Pompey's defeat in Asia."],
"reference": ["The Roman Senate was filled with exuberance due to successes against Catiline."],
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["exact_match", "bleu", "rouge"],
experiment=EXPERIMENT_NAME
)
Tool-use (function calling) evaluation
For evaluation of tool (function) calls, you only need to include the response and reference in the evaluation dataset.
eval_dataset = pd.DataFrame({
"response": ["""{
"content": "",
"tool_calls":[{
"name":"get_movie_info",
"arguments": {"movie":"Mission Impossible", "time": "today 7:30PM"}
}]
}"""],
"reference": ["""{
"content": "",
"tool_calls":[{
"name":"book_tickets",
"arguments":{"movie":"Mission Impossible", "time": "today 7:30PM"}
}]
}"""],
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["tool_call_valid", "tool_name_match", "tool_parameter_key_match",
"tool_parameter_kv_match"],
experiment=EXPERIMENT_NAME
)
Metric bundles
Metric bundles combine commonly associated metrics to help simplify the evaluation process. The metrics are categorized into these four bundles:
- Evaluation tasks: summarization, question answering, and text generation
- Evaluation perspectives: similarity, safety, and quality
- Input consistency: all metrics in the same bundle take the same dataset inputs
- Evaluation paradigm: pointwise versus pairwise
You can use these metric bundles in the online evaluation service to help you optimize your customized evaluation workflow.
This table lists details about the available metric bundles:
| Metrics bundle name | Metric name | User input |
|---|---|---|
text_generation_similarity |
exact_matchbleurouge |
prediction reference |
tool_call_quality |
tool_call_validtool_name_matchtool_parameter_key_matchtool_parameter_kv_match |
prediction reference |
text_generation_quality |
coherencefluency |
prediction |
text_generation_instruction_following |
fulfillment |
prediction reference |
text_generation_safety |
safety |
prediction |
text_generation_factuality |
groundedness |
prediction context |
summarization_pointwise_reference_free |
summarization_qualitysummarization_helpfulnesssummarization_verbosity |
prediction context instruction |
summary_pairwise_reference_free |
pairwise_summarization_quality |
prediction context instruction |
qa_pointwise_reference_free |
question_answering_qualityquestion_answering_relevancequestion_answering_helpfulness |
prediction context instruction |
qa_pointwise_reference_based |
question_answering_correctness |
prediction context instruction reference |
qa_pairwise_reference_free |
pairwise_question_answering_quality |
prediction context instruction |
View evaluation results
After you define your evaluation task, run the task to get evaluation results, as follows:
eval_result: EvalResult = eval_task.evaluate(
model=MODEL,
prompt_template=PROMPT_TEMPLATE
)
The EvalResult class represents the result of an evaluation run, which
includes summary metrics and a metrics table with an evaluation dataset instance
and corresponding per-instance metrics. Define the class as follows:
@dataclasses.dataclass
class EvalResult:
"""Evaluation result.
Attributes:
summary_metrics: the summary evaluation metrics for an evaluation run.
metrics_table: a table containing eval inputs, ground truth, and
metrics per row.
"""
summary_metrics: Dict[str, float]
metrics_table: Optional[pd.DataFrame] = None
With the use of helper functions, the evaluation results can be displayed in the Colab notebook.
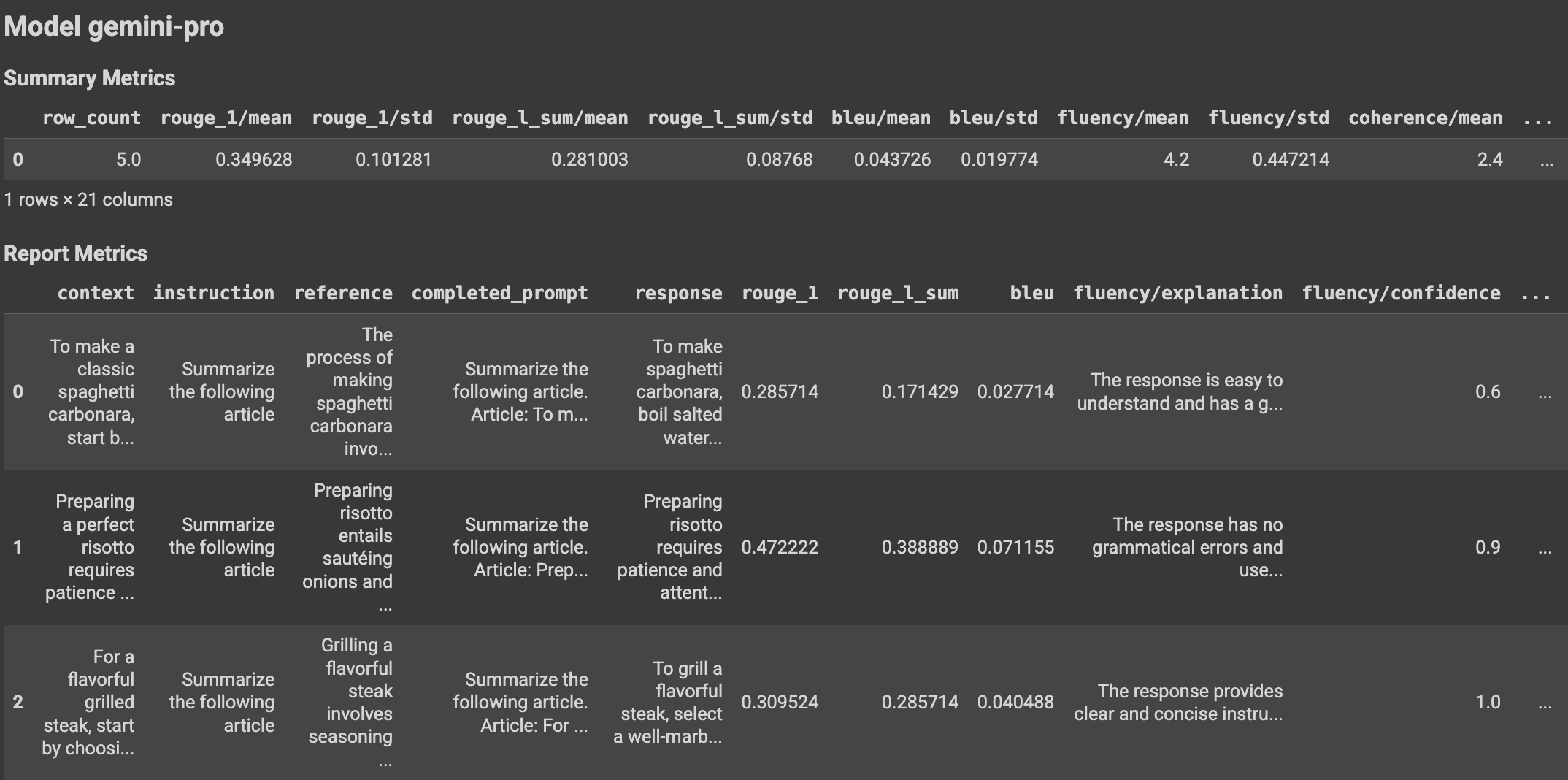
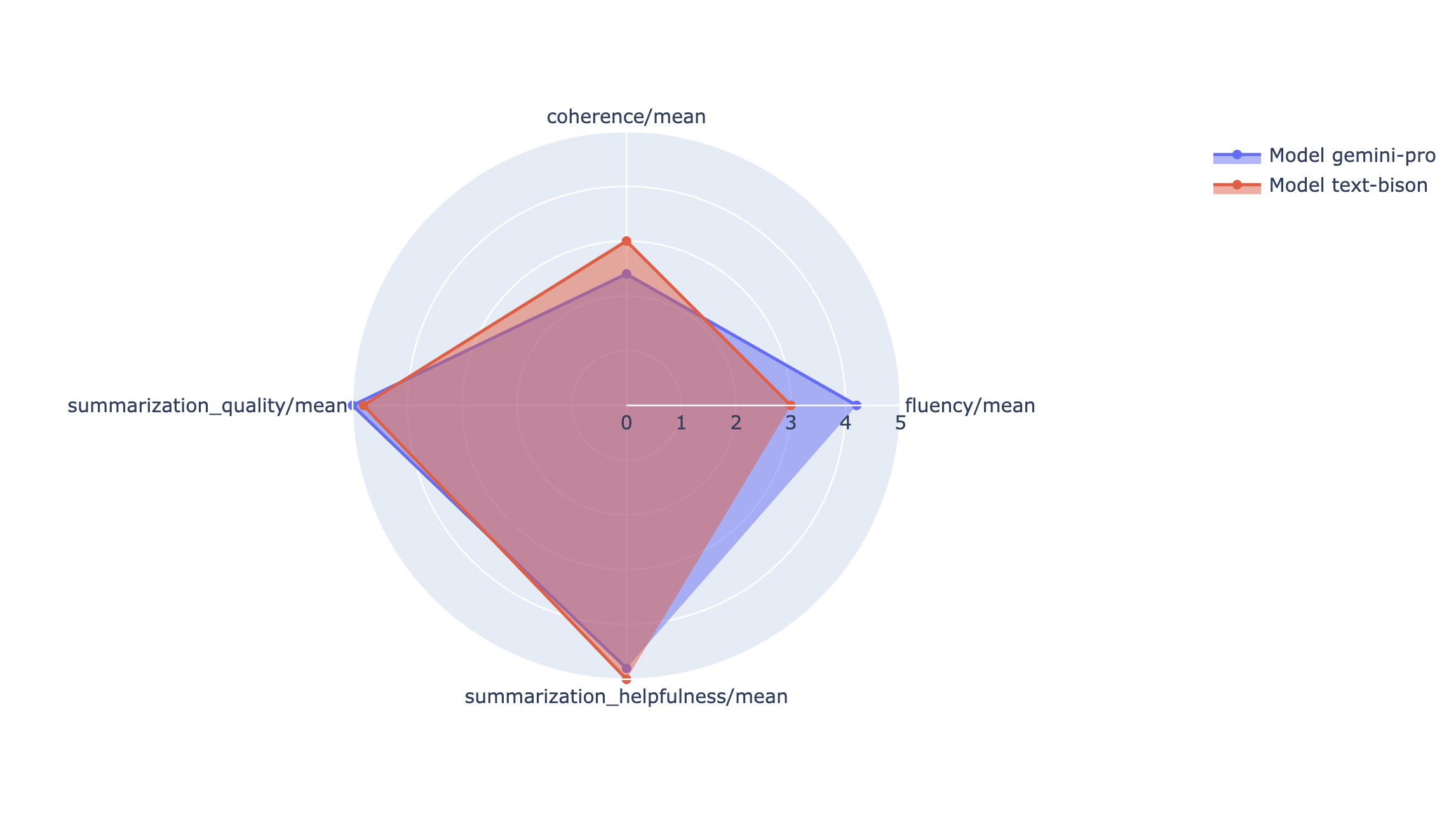
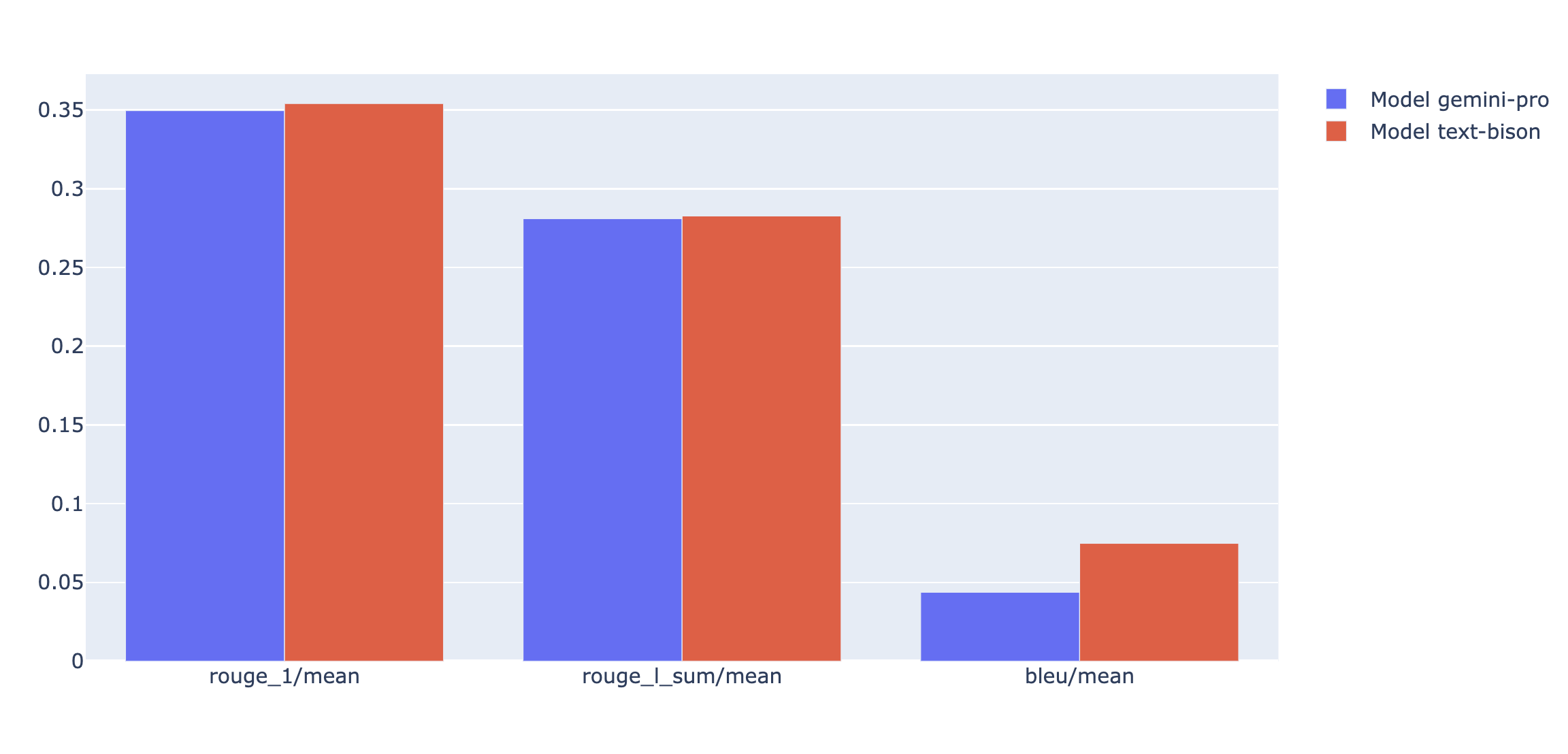
Visualizations
You can plot summary metrics in a radar or bar chart for visualization and comparison between results from different evaluation runs. This visualization can be helpful for evaluating different models and different prompt templates.
Rapid evaluation API
For information about the rapid evaluation API, see the rapid evaluation API.
Understanding service accounts
The service accounts are used by the online evaluation service to get predictions from the online prediction service for model-based evaluation metrics. This service account is automatically provisioned on the first request to the online evaluation service.
| Name | Description | Email address | Role |
|---|---|---|---|
| Vertex AI Rapid Eval Service Agent | The service account used to get predictions for model based evaluation. | service-PROJECT_NUMBER@gcp-sa-ENV-vertex-eval.iam.gserviceaccount.com |
roles/aiplatform.rapidevalServiceAgent |
The permissions associated to the rapid evaluation service agent are:
| Role | Permissions |
|---|---|
| Vertex AI Rapid Eval Service Agent (roles/aiplatform.rapidevalServiceAgent) | aiplatform.endpoints.predict |
What's next
- Try an evaluation example notebook.
- Learn about generative AI evaluation.
- Learn about model-based pairwise evaluation with AutoSxS pipeline.
- Learn about the computation-based evaluation pipeline.
- Learn how to tune a foundation model.