Puoi utilizzare lo SDK Vertex AI per Python per valutare in modo programmatico i modelli linguistici generativi.
Installa l'SDK Vertex AI
Per installare la valutazione rapida dall'SDK Vertex AI per Python, esegui questo comando: :
pip install --upgrade google-cloud-aiplatform[rapid_evaluation]
Per ulteriori informazioni, vedi Installa l'SDK Vertex AI per Python.
Autentica l'SDK Vertex AI
Dopo aver installato l'SDK Vertex AI per Python, devi eseguire l'autenticazione. Le seguenti in cui viene spiegato come eseguire l'autenticazione con l'SDK Vertex AI a livello locale e se lavori in Colaboratory:
Se stai sviluppando localmente, configura Credenziali predefinite dell'applicazione (ADC) nel tuo ambiente locale:
Installa Google Cloud CLI, quindi inizializzala eseguendo questo comando:
gcloud initCrea le credenziali di autenticazione locali per il tuo Account Google:
gcloud auth application-default loginViene visualizzata una schermata di accesso. Dopo aver eseguito l'accesso, le credenziali vengono memorizzate nel file delle credenziali locali utilizzato da ADC. Per ulteriori informazioni sul lavoro con ADC in un ambiente locale, vedi Ambiente di sviluppo locale.
Se stai lavorando in Colaboratory, esegui il comando seguente in un Cella Colab per l'autenticazione:
from google.colab import auth auth.authenticate_user()Questo comando apre una finestra in cui puoi completare l'autenticazione.
Consulta il riferimento per l'SDK di valutazione rapida per scoprire di più sull'SDK di valutazione rapida.
Crea un'attività di valutazione
Perché la valutazione è per lo più basata su attività grazie ai modelli di IA generativa,
La valutazione introduce l'astrazione delle attività di valutazione per facilitare la valutazione
e casi d'uso specifici. Per ottenere confronti equi tra i modelli generativi,
esegui valutazioni per modelli e modelli di prompt in base a un set di dati di valutazione
e le relative metriche associate ripetutamente. Il corso EvalTask è progettato per
supportano questo nuovo paradigma di valutazione. Inoltre, EvalTask ti consente
si integrano perfettamente con
Esperimenti Vertex AI,
che può aiutare a monitorare impostazioni e risultati per ogni esecuzione di valutazione.
Vertex AI Experiments può aiutarti a gestire e interpretare i risultati delle valutazioni,
consentendoti di intervenire in meno tempo. L'esempio seguente mostra come
crea un'istanza della classe EvalTask ed esegui una valutazione:
from vertexai.preview.evaluation import EvalTask
eval_task = EvalTask(
dataset=DATASET,
metrics=["bleu", "rouge_l_sum"],
experiment=EXPERIMENT_NAME
)
Il parametro metrics accetta un elenco di metriche, consentendo il
valutazione simultanea di più metriche in un'unica chiamata di valutazione.
Preparazione del set di dati di valutazione
I set di dati vengono passati a un'istanza EvalTask come DataFrame pandas, in cui ogni riga
rappresenta un esempio di valutazione separato (chiamato istanza) e ogni colonna
rappresenta un parametro di input della metrica. Vedi le metriche per gli input previsti da
ogni metrica. Forniamo diversi esempi per creare il set di dati di valutazione
per diverse attività di valutazione.
Valutazione del riassunto
Crea un set di dati per il riassunto puntuale con le seguenti metriche:
summarization_qualitygroundednessfulfillmentsummarization_helpfulnesssummarization_verbosity
Considerando i parametri di input della metrica richiesti, devi includere seguenti colonne nel nostro set di dati di valutazione:
instructioncontextresponse
In questo esempio, abbiamo due istanze di riassunto. Costruire il
instruction e context come input, obbligatori per
valutazioni delle attività di riepilogo:
instructions = [
# example 1
"Summarize the text in one sentence.",
# example 2
"Summarize the text such that a five-year-old can understand.",
]
contexts = [
# example 1
"""As part of a comprehensive initiative to tackle urban congestion and foster
sustainable urban living, a major city has revealed ambitious plans for an
extensive overhaul of its public transportation system. The project aims not
only to improve the efficiency and reliability of public transit but also to
reduce the city\'s carbon footprint and promote eco-friendly commuting options.
City officials anticipate that this strategic investment will enhance
accessibility for residents and visitors alike, ushering in a new era of
efficient, environmentally conscious urban transportation.""",
# example 2
"""A team of archaeologists has unearthed ancient artifacts shedding light on a
previously unknown civilization. The findings challenge existing historical
narratives and provide valuable insights into human history.""",
]
Se hai pronto la risposta LLM (il riassunto) e vuoi farlo la valutazione BYOP (Bring Your Own Prediction), puoi creare la risposta come segue:
responses = [
# example 1
"A major city is revamping its public transportation system to fight congestion, reduce emissions, and make getting around greener and easier.",
# example 2
"Some people who dig for old things found some very special tools and objects that tell us about people who lived a long, long time ago! What they found is like a new puzzle piece that helps us understand how people used to live.",
]
Con questi input, siamo pronti a costruire il nostro set di dati di valutazione
EvalTask.
eval_dataset = pd.DataFrame(
{
"instruction": instructions,
"context": contexts,
"response": responses,
}
)
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
'summarization_quality',
'groundedness',
'fulfillment',
'summarization_helpfulness',
'summarization_verbosity'
],
experiment=EXPERIMENT_NAME
)
Valutazione generale della generazione di testi
Alcune
basata su modello
come coherence, fluency e safety, hanno bisogno solo del modello
risposta per valutare la qualità:
eval_dataset = pd.DataFrame({
"response": ["""The old lighthouse, perched precariously on the windswept cliff,
had borne witness to countless storms. Its once-bright beam, now dimmed by time
and the relentless sea spray, still flickered with stubborn defiance."""]
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["coherence", "fluency", "safety"],
experiment=EXPERIMENT_NAME
)
Valutazione basata sul calcolo
Metriche basate sul calcolo, come esatta, bleu e rouge, confrontare una risposta con un riferimento e, di conseguenza, aver bisogno sia di campi di riferimento nel set di dati di valutazione:
eval_dataset = pd.DataFrame({
"response": ["The Roman Senate was filled with exuberance due to Pompey's defeat in Asia."],
"reference": ["The Roman Senate was filled with exuberance due to successes against Catiline."],
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["exact_match", "bleu", "rouge"],
experiment=EXPERIMENT_NAME
)
Valutazione dell'uso degli strumenti
Per la valutazione dell'uso degli strumenti, devi solo includere la risposta e come riferimento nel set di dati di valutazione.
eval_dataset = pd.DataFrame({
"response": ["""{
"content": "",
"tool_calls":[{
"name":"get_movie_info",
"arguments": {"movie":"Mission Impossible", "time": "today 7:30PM"}
}]
}"""],
"reference": ["""{
"content": "",
"tool_calls":[{
"name":"book_tickets",
"arguments":{"movie":"Mission Impossible", "time": "today 7:30PM"}
}]
}"""],
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["tool_call_valid", "tool_name_match", "tool_parameter_key_match",
"tool_parameter_kv_match"],
experiment=EXPERIMENT_NAME
)
Gruppi di metriche
I pacchetti di metriche combinano metriche associate comunemente per semplificare di valutazione. Le metriche sono classificate in questi quattro pacchetti:
- Attività di valutazione: sintesi, risposta alle domande e generazione di testi
- Prospettive di valutazione: somiglianza, sicurezza e qualità
- Coerenza dell'input: tutte le metriche nello stesso bundle utilizzano lo stesso set di dati input
- Paradigma di valutazione: puntuale e a coppie
Puoi utilizzare questi pacchetti di metriche nel servizio di valutazione online per ottimizzare il flusso di lavoro di valutazione personalizzata.
In questa tabella sono elencati i dettagli sui pacchetti di metriche disponibili:
| Nome pacchetto di metriche | Nome metrica | Colonna del set di dati obbligatoria |
|---|---|---|
text_generation_similarity |
exact_matchbleurouge |
riferimento risposta |
tool_call_quality |
tool_call_validtool_name_matchtool_parameter_key_matchtool_parameter_kv_match |
riferimento risposta |
text_generation_quality |
coherencefluency |
risposta |
text_generation_instruction_following |
fulfillment |
riferimento risposta |
text_generation_safety |
safety |
risposta |
text_generation_factuality |
groundedness |
response context |
summarization_pointwise_reference_free |
summarization_qualitysummarization_helpfulnesssummarization_verbosity |
response context instruction |
summary_pairwise_reference_free |
pairwise_summarization_quality |
response context instruction |
qa_pointwise_reference_free |
question_answering_qualityquestion_answering_relevancequestion_answering_helpfulness |
response context instruction |
qa_pointwise_reference_based |
question_answering_correctness |
response context instruction reference |
qa_pairwise_reference_free |
pairwise_question_answering_quality |
response context instruction |
Visualizza i risultati di una valutazione
Dopo aver definito l'attività di valutazione, eseguila per ottenere i risultati della valutazione, come segue:
eval_result: EvalResult = eval_task.evaluate(
model=MODEL,
prompt_template=PROMPT_TEMPLATE
)
La classe EvalResult rappresenta il risultato di un'esecuzione di valutazione, che
include metriche di riepilogo e una tabella delle metriche con un'istanza del set di dati di valutazione
e le metriche per istanza corrispondenti. Definisci la classe come segue:
@dataclasses.dataclass
class EvalResult:
"""Evaluation result.
Attributes:
summary_metrics: the summary evaluation metrics for an evaluation run.
metrics_table: a table containing eval inputs, ground truth, and
metrics per row.
"""
summary_metrics: Dict[str, float]
metrics_table: Optional[pd.DataFrame] = None
Con l'uso delle funzioni helper, i risultati della valutazione possono essere visualizzati Blocco note di Colab.

Visualizzazioni
Puoi tracciare metriche di riepilogo in un grafico radar o a barre per la visualizzazione e il confronto tra i risultati di diverse esecuzioni di valutazione. Questo la visualizzazione può essere utile per valutare modelli diversi e modelli di prompt.
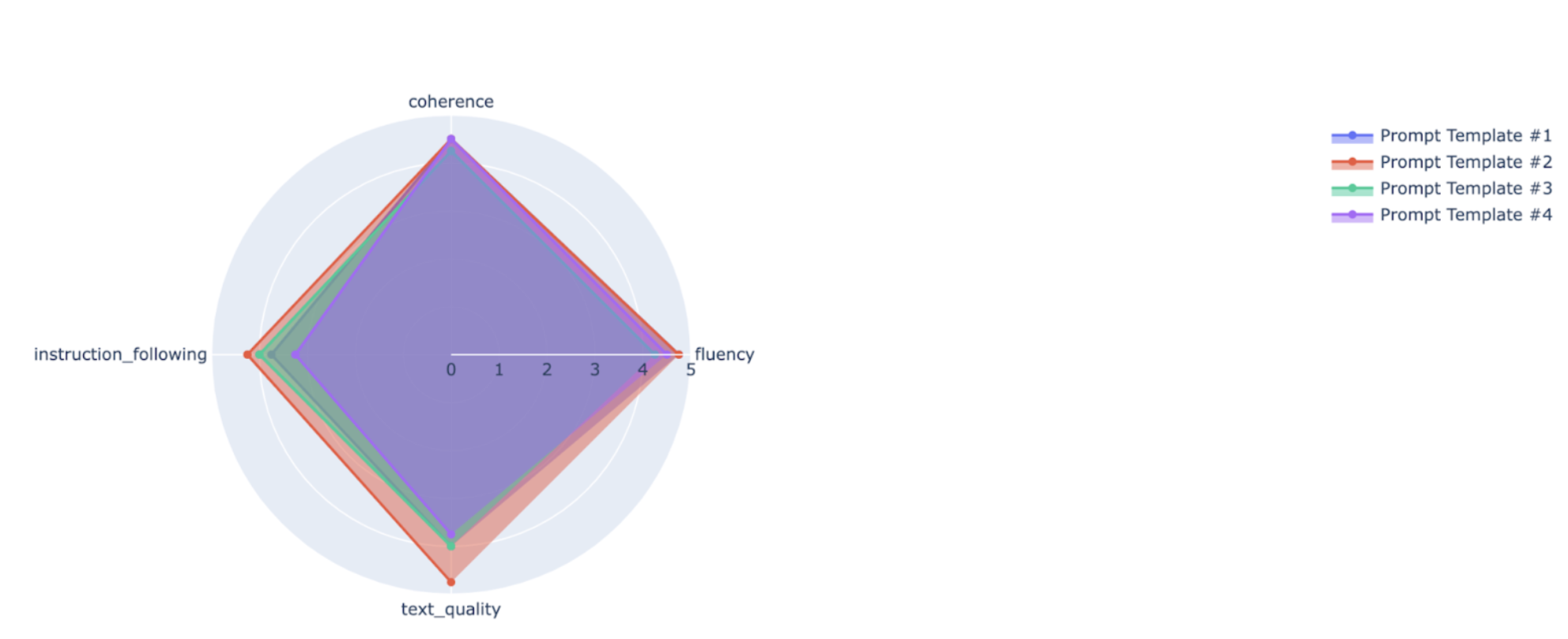
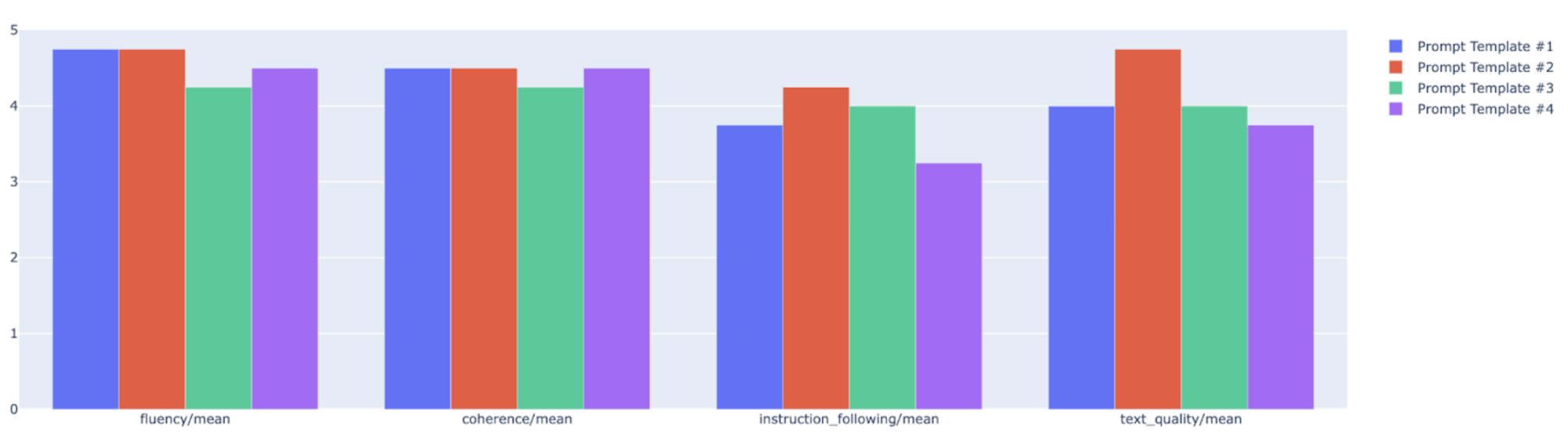
API Rapid Assessment
Per informazioni sull'API di valutazione rapida, consulta API di valutazione rapida.
Informazioni sugli account di servizio
Gli account di servizio vengono usati dal servizio di valutazione online per Previsioni del servizio di previsione online per la valutazione basata su modelli metriche di valutazione. Il provisioning di questo account di servizio viene eseguito automaticamente alla prima richiesta al servizio di valutazione online.
| Nome | Descrizione | Indirizzo email | Ruolo |
|---|---|---|---|
| Vertex AI Rapid Eval Service Agent | L'account di servizio utilizzato per ottenere previsioni per la valutazione basata sul modello. | service-PROJECT_NUMBER@gcp-sa-ENV-vertex-eval.iam.gserviceaccount.com |
roles/aiplatform.rapidevalServiceAgent |
Le autorizzazioni associate all'agente di servizio di valutazione rapida sono:
| Ruolo | Autorizzazioni |
|---|---|
| Agente di servizio Vertex AI Rapid Eval (roles/aiplatform.rapidevalServiceAgent) | aiplatform.endpoints.predict |
Passaggi successivi
- Prova un blocco note di esempio di valutazione.
- Scopri di più sulla valutazione dell'AI generativa.
- Scopri di più sulla valutazione della coppia basata su modello con la pipeline AutoSxS.
- Scopri di più sulla pipeline di valutazione basata sul calcolo.
- Scopri come ottimizzare un modello di base.