Setelah membangun dan mengevaluasi model AI Generatif, Anda dapat menggunakan model tersebut untuk membangun agen seperti chatbot. Layanan evaluasi AI generatif memungkinkan Anda mengukur kemampuan agen dalam menyelesaikan tugas dan sasaran untuk kasus penggunaan Anda.
Ringkasan
Anda memiliki opsi berikut untuk mengevaluasi agen:
Evaluasi respons akhir: Mengevaluasi output akhir agen (apakah agen mencapai tujuannya atau tidak).
Evaluasi lintasan: Mengevaluasi jalur (urutan panggilan alat) yang diambil agen untuk mencapai respons akhir.
Dengan layanan evaluasi AI generatif, Anda dapat memicu eksekusi agen dan mendapatkan metrik untuk evaluasi lintasan dan evaluasi respons akhir dalam satu kueri Vertex AI SDK.
Agen yang didukung
Layanan evaluasi AI generatif mendukung kategori agen berikut:
| Agen yang didukung | Deskripsi |
|---|---|
| Agen yang dibuat dengan template Agent Engine | Agent Engine (LangChain di Vertex AI) adalah Google Cloud platform tempat Anda dapat men-deploy dan mengelola agen. |
| Agen LangChain yang dibuat menggunakan template Agent Engine yang dapat disesuaikan | LangChain adalah platform open source. |
| Fungsi agen kustom | Fungsi agen kustom adalah fungsi fleksibel yang menerima perintah untuk agen dan menampilkan respons serta lintasan dalam kamus. |
Menentukan metrik untuk evaluasi agen
Tentukan metrik Anda untuk respons akhir atau evaluasi lintasan:
Evaluasi respons akhir
Evaluasi respons akhir mengikuti proses yang sama dengan evaluasi respons model. Untuk mengetahui informasi selengkapnya, lihat Menentukan metrik evaluasi.
Evaluasi lintasan
Metrik berikut membantu Anda mengevaluasi kemampuan model untuk mengikuti lintasan yang diharapkan:
Pencocokan persis
Jika lintasan yang diprediksi identik dengan lintasan referensi, dengan panggilan alat yang sama persis dalam urutan yang sama persis, metrik trajectory_exact_match akan menampilkan skor 1, atau 0.
Parameter input metrik
| Parameter input | Deskripsi |
|---|---|
predicted_trajectory |
Daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir. |
reference_trajectory |
Penggunaan alat yang diharapkan untuk agen dalam memenuhi kueri. |
Skor output
| Nilai | Deskripsi |
|---|---|
| 0 | Trajektori yang diprediksi tidak cocok dengan referensi. |
| 1 | Trajektori yang diprediksi cocok dengan referensi. |
Pencocokan berurutan
Jika lintasan yang diprediksi berisi semua panggilan alat dari lintasan referensi dalam urutan yang sama, dan mungkin juga memiliki panggilan alat tambahan, metrik trajectory_in_order_match akan menampilkan skor 1, atau 0.
Parameter input metrik
| Parameter input | Deskripsi |
|---|---|
predicted_trajectory |
Trajektori yang diprediksi digunakan oleh agen untuk mencapai respons akhir. |
reference_trajectory |
Lintasan prediksi yang diharapkan bagi agen untuk memenuhi kueri. |
Skor output
| Nilai | Deskripsi |
|---|---|
| 0 | Panggilan alat dalam lintasan yang diprediksi tidak cocok dengan urutan dalam lintasan referensi. |
| 1 | Trajektori yang diprediksi cocok dengan referensi. |
Pencocokan dengan urutan apa pun
Jika lintasan yang diprediksi berisi semua panggilan alat dari lintasan referensi, tetapi urutannya tidak penting dan mungkin berisi panggilan alat tambahan, maka metrik trajectory_any_order_match akan menampilkan skor 1, atau 0.
Parameter input metrik
| Parameter input | Deskripsi |
|---|---|
predicted_trajectory |
Daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir. |
reference_trajectory |
Penggunaan alat yang diharapkan untuk agen dalam memenuhi kueri. |
Skor output
| Nilai | Deskripsi |
|---|---|
| 0 | Trajektori yang diprediksi tidak berisi semua panggilan alat dalam trajektori referensi. |
| 1 | Trajektori yang diprediksi cocok dengan referensi. |
Presisi
Metrik trajectory_precision mengukur berapa banyak panggilan alat dalam lintasan yang diprediksi yang sebenarnya relevan atau benar menurut lintasan referensi.
Presisi dihitung sebagai berikut: Hitung jumlah tindakan dalam lintasan yang diprediksi yang juga muncul dalam lintasan referensi. Bagi jumlah tersebut dengan jumlah total tindakan dalam lintasan yang diprediksi.
Parameter input metrik
| Parameter input | Deskripsi |
|---|---|
predicted_trajectory |
Daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir. |
reference_trajectory |
Penggunaan alat yang diharapkan untuk agen dalam memenuhi kueri. |
Skor output
| Nilai | Deskripsi |
|---|---|
| Float dalam rentang [0,1] | Makin tinggi skornya, makin presisi lintasan yang diprediksi. |
Recall
Metrik trajectory_recall mengukur berapa banyak panggilan alat penting dari lintasan referensi yang benar-benar tercakup dalam lintasan yang diprediksi.
Perolehan dihitung sebagai berikut: Hitung jumlah tindakan dalam lintasan referensi yang juga muncul dalam lintasan yang diprediksi. Bagi jumlah tersebut dengan jumlah total tindakan dalam lintasan referensi.
Parameter input metrik
| Parameter input | Deskripsi |
|---|---|
predicted_trajectory |
Daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir. |
reference_trajectory |
Penggunaan alat yang diharapkan untuk agen dalam memenuhi kueri. |
Skor output
| Nilai | Deskripsi |
|---|---|
| Float dalam rentang [0,1] | Makin tinggi skornya, makin baik perolehan lintasan yang diprediksi. |
Penggunaan satu alat
Metrik trajectory_single_tool_use memeriksa apakah alat tertentu yang ditentukan dalam spesifikasi metrik digunakan dalam lintasan yang diprediksi. Tidak memeriksa urutan panggilan alat atau berapa kali alat digunakan, hanya apakah ada atau tidak.
Parameter input metrik
| Parameter input | Deskripsi |
|---|---|
predicted_trajectory |
Daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir. |
Skor output
| Nilai | Deskripsi |
|---|---|
| 0 | Alat tidak ada |
| 1 | Alat ini ada. |
Selain itu, dua metrik performa agen berikut ditambahkan ke hasil evaluasi secara default. Anda tidak perlu menentukannya di EvalTask.
latency
Waktu yang dibutuhkan agen untuk memberikan respons.
| Nilai | Deskripsi |
|---|---|
| Float | Dihitung dalam detik. |
failure
Boolean untuk menjelaskan apakah pemanggilan agen menghasilkan error atau berhasil.
Skor output
| Nilai | Deskripsi |
|---|---|
| 1 | Error |
| 0 | Respons valid ditampilkan |
Menyiapkan set data untuk evaluasi agen
Siapkan set data Anda untuk evaluasi respons akhir atau lintasan.
Skema data untuk evaluasi respons akhir mirip dengan skema evaluasi respons model.
Untuk evaluasi lintasan berbasis komputasi, set data Anda harus memberikan informasi berikut:
| Jenis input | Isi kolom input |
|---|---|
predicted_trajectory |
Daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir. |
reference_trajectory (tidak diperlukan untuk trajectory_single_tool_use metric) |
Penggunaan alat yang diharapkan untuk agen dalam memenuhi kueri. |
Contoh set data evaluasi
Contoh berikut menunjukkan set data untuk evaluasi lintasan. Perhatikan bahwa reference_trajectory wajib diisi untuk semua metrik, kecuali trajectory_single_tool_use.
reference_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_2",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_y"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
predicted_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_3",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_z"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
eval_dataset = pd.DataFrame({
"predicted_trajectory": predicted_trajectory,
"reference_trajectory": reference_trajectory,
})
Mengimpor set data evaluasi
Anda dapat mengimpor set data dalam format berikut:
File JSONL atau CSV yang disimpan di Cloud Storage
Tabel BigQuery
DataFrame Pandas
Layanan evaluasi AI generatif menyediakan contoh set data publik untuk mendemonstrasikan cara Anda dapat mengevaluasi agen. Kode berikut menunjukkan cara mengimpor set data publik dari bucket Cloud Storage:
# dataset name to be imported
dataset = "on-device" # Alternatives: "customer-support", "content-creation"
# copy the tools and dataset file
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/tools.py .
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/eval_dataset.json .
# load the dataset examples
import json
eval_dataset = json.loads(open('eval_dataset.json').read())
# run the tools file
%run -i tools.py
dengan dataset adalah salah satu set data publik berikut:
"on-device"untuk Asisten Rumah Di Perangkat, yang mengontrol perangkat rumah. Agen ini membantu menjawab kueri seperti "Jadwalkan AC di kamar tidur agar menyala antara pukul 23.00 dan 08.00, dan mati di waktu lainnya"."customer-support"untuk Agen Dukungan Pelanggan. Agen membantu menjawab pertanyaan seperti "Dapatkah Anda membatalkan pesanan yang tertunda dan mengeskalasikan tiket dukungan yang masih terbuka?""content-creation"untuk Agen Pembuatan Konten Pemasaran. Agen membantu dengan kueri seperti "Jadwalkan ulang kampanye X menjadi kampanye satu kali di situs media sosial Y dengan anggaran yang dikurangi 50%, hanya pada 25 Desember 2024."
Menjalankan evaluasi agen
Menjalankan evaluasi untuk evaluasi respons akhir atau lintasan:
Untuk evaluasi agen, Anda dapat menggabungkan metrik evaluasi respons dan metrik evaluasi lintasan seperti dalam kode berikut:
single_tool_use_metric = TrajectorySingleToolUse(tool_name='tool_name')
eval_task = EvalTask(
dataset=EVAL_DATASET,
metrics=[
"rouge_l_sum",
"bleu",
custom_trajectory_eval_metric, # custom computation-based metric
"trajectory_exact_match",
"trajectory_precision",
single_tool_use_metric,
response_follows_trajectory_metric # llm-based metric
],
)
eval_result = eval_task.evaluate(
runnable=RUNNABLE,
)
Penyesuaian metrik
Anda dapat menyesuaikan metrik berbasis model bahasa besar untuk evaluasi trajektori menggunakan antarmuka berbasis template atau dari awal. Untuk mengetahui detail selengkapnya, lihat bagian tentang metrik berbasis model. Berikut contoh yang menggunakan template:
response_follows_trajectory_prompt_template = PointwiseMetricPromptTemplate(
criteria={
"Follows trajectory": (
"Evaluate whether the agent's response logically follows from the "
"sequence of actions it took. Consider these sub-points:\n"
" - Does the response reflect the information gathered during the trajectory?\n"
" - Is the response consistent with the goals and constraints of the task?\n"
" - Are there any unexpected or illogical jumps in reasoning?\n"
"Provide specific examples from the trajectory and response to support your evaluation."
)
},
rating_rubric={
"1": "Follows trajectory",
"0": "Does not follow trajectory",
},
input_variables=["prompt", "predicted_trajectory"],
)
response_follows_trajectory_metric = PointwiseMetric(
metric="response_follows_trajectory",
metric_prompt_template=response_follows_trajectory_prompt_template,
)
Anda juga dapat menentukan metrik berbasis komputasi kustom untuk evaluasi lintasan atau evaluasi respons sebagai berikut:
def essential_tools_present(instance, required_tools = ["tool1", "tool2"]):
trajectory = instance["predicted_trajectory"]
tools_present = [tool_used['tool_name'] for tool_used in trajectory]
if len(required_tools) == 0:
return {"essential_tools_present": 1}
score = 0
for tool in required_tools:
if tool in tools_present:
score += 1
return {
"essential_tools_present": score/len(required_tools),
}
custom_trajectory_eval_metric = CustomMetric(name="essential_tools_present", metric_function=essential_tools_present)
Melihat dan menafsirkan hasil
Untuk evaluasi lintasan atau evaluasi respons akhir, hasil evaluasi ditampilkan sebagai berikut:
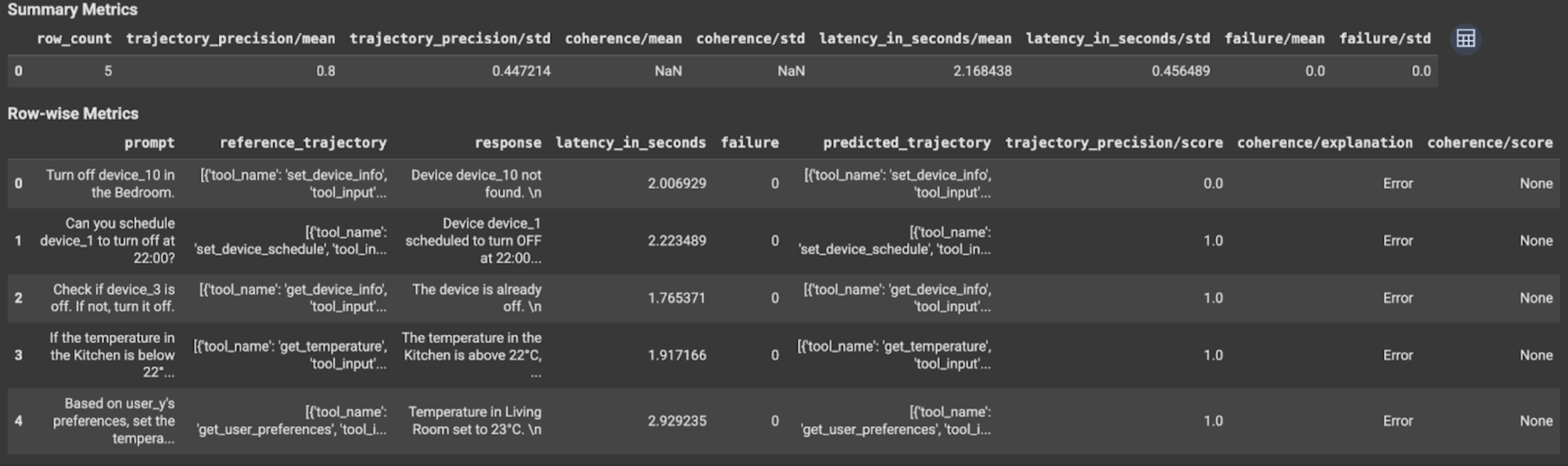
Hasil evaluasi berisi informasi berikut:
Metrik respons akhir
Hasil tingkat instance
| Kolom | Deskripsi |
|---|---|
| respons | Respons akhir yang dihasilkan oleh agen. |
| latency_in_seconds | Waktu yang diperlukan untuk membuat respons. |
| gagal | Menunjukkan apakah respons yang valid dibuat atau tidak. |
| skor | Skor yang dihitung untuk respons yang ditentukan dalam spesifikasi metrik. |
| penjelasan | Penjelasan untuk skor yang ditentukan dalam spesifikasi metrik. |
Hasil gabungan
| Kolom | Deskripsi |
|---|---|
| rata-rata | Skor rata-rata untuk semua instance. |
| simpangan baku | Simpangan baku untuk semua skor. |
Metrik lintasan
Hasil tingkat instance
| Kolom | Deskripsi |
|---|---|
| predicted_trajectory | Urutan panggilan alat yang diikuti oleh agen untuk mencapai respons akhir. |
| reference_trajectory | Urutan panggilan alat yang diharapkan. |
| skor | Skor yang dihitung untuk lintasan yang diprediksi dan lintasan referensi yang ditentukan dalam spesifikasi metrik. |
| latency_in_seconds | Waktu yang diperlukan untuk membuat respons. |
| gagal | Menunjukkan apakah respons yang valid dibuat atau tidak. |
Hasil gabungan
| Kolom | Deskripsi |
|---|---|
| rata-rata | Skor rata-rata untuk semua instance. |
| simpangan baku | Simpangan baku untuk semua skor. |
Protokol Agent2Agent (A2A)
Jika Anda membangun sistem multi-agen, sebaiknya tinjau Protokol A2A. Protokol A2A adalah standar terbuka yang memungkinkan komunikasi dan kolaborasi yang lancar antar-agen AI, terlepas dari framework yang mendasarinya. Disumbangkan oleh Google Cloud ke Linux Foundation pada Juni 2025. Untuk menggunakan SDK A2A, atau mencoba sampel, lihat repositori GitHub.
Langkah berikutnya
Coba notebook evaluasi agen berikut: