A partire dal 29 aprile 2025, i modelli Gemini 1.5 Pro e Gemini 1.5 Flash non sono disponibili nei progetti che non li hanno mai utilizzati, inclusi i nuovi progetti. Per maggiori dettagli, vedi Versioni e ciclo di vita dei modelli.
Vertex AI RAG Engine, un componente della piattaforma Vertex AI, facilita la generazione RAG (Retrieval-Augmented Generation).
Vertex AI RAG Engine è anche un framework di dati per lo sviluppo di applicazioni basate su modelli linguistici di grandi dimensioni (LLM) con aggiunta del contesto. L'aggiunta del contesto
si verifica quando un modello LLM viene applicato ai dati. È così che viene implementata la generazione
RAG (Retrieval-Augmented Generation).
Un problema comune con i modelli linguistici di grandi dimensioni è che non comprendono le conoscenze private, ovvero i dati della tua organizzazione. Con Vertex AI RAG Engine, puoi
arricchire il contesto del modello LLM con informazioni private aggiuntive, perché il modello
può ridurre le allucinazioni e rispondere alle domande in modo più preciso.
Combinando fonti di conoscenza aggiuntive con le conoscenze esistenti degli LLM, viene fornito un contesto migliore. Il contesto migliorato insieme alla query
migliora la qualità della risposta dell'LLM.
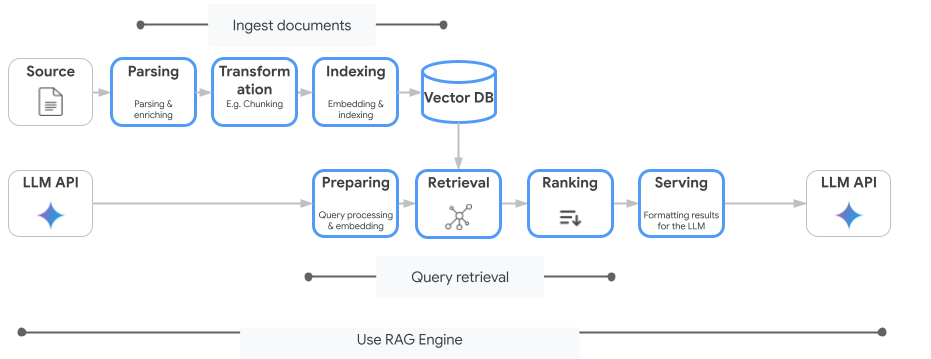
La seguente immagine illustra i concetti chiave per comprendere
Vertex AI RAG Engine.
Questi concetti sono elencati nell'ordine del processo di generazione RAG (Retrieval-Augmented Generation).
Importazione dei dati: importazione dei dati da diverse origini dati. Ad esempio,
file locali, Cloud Storage e Google Drive.
Trasformazione dei dati:
Conversione dei dati in preparazione dell'indicizzazione. Ad esempio, i dati
vengono suddivisi in blocchi.
Incorporamento: rappresentazioni numeriche di parole o parti di testo. Questi numeri acquisiscono il
significato semantico e il contesto del testo. Parole o testi simili o correlati
tendono ad avere incorporamenti simili, il che significa che sono più vicini nello
spazio vettoriale di grandi dimensioni.
Indicizzazione dei dati: Vertex AI RAG Engine crea un indice chiamato corpus.
L'indice struttura la knowledge base in modo che sia ottimizzata per la ricerca. Ad esempio, l'indice è come un indice dettagliato per un enorme libro di consultazione.
Recupero: quando un utente pone una domanda o fornisce un prompt, il componente di recupero in Vertex AI RAG Engine esegue ricerche nella sua knowledge base per trovare informazioni pertinenti alla query.
Generazione: le informazioni recuperate diventano il contesto aggiunto alla query utente originale come guida per il modello di AI generativa per generare risposte basate sui fatti e pertinenti.
Aree geografiche supportate
Vertex AI RAG Engine è supportato nelle seguenti regioni:
Regione
Località
Descrizione
Fase di avvio
us-central1
Iowa
Sono supportate le versioni v1 e v1beta1.
Lista consentita
us-east4
Virginia
Sono supportate le versioni v1 e v1beta1.
GA
europe-west3
Francoforte, Germania
Sono supportate le versioni v1 e v1beta1.
GA
europe-west4
Eemshaven, Paesi Bassi
Sono supportate le versioni v1 e v1beta1.
GA
us-central1 è stato modificato in Allowlist. Se vuoi sperimentare con
Vertex AI RAG Engine, prova altre regioni. Se prevedi di eseguire l'onboarding
del traffico di produzione su us-central1, contatta vertex-ai-rag-engine-support@google.com.
[[["Facile da capire","easyToUnderstand","thumb-up"],["Il problema è stato risolto","solvedMyProblem","thumb-up"],["Altra","otherUp","thumb-up"]],[["Difficile da capire","hardToUnderstand","thumb-down"],["Informazioni o codice di esempio errati","incorrectInformationOrSampleCode","thumb-down"],["Mancano le informazioni o gli esempi di cui ho bisogno","missingTheInformationSamplesINeed","thumb-down"],["Problema di traduzione","translationIssue","thumb-down"],["Altra","otherDown","thumb-down"]],["Ultimo aggiornamento 2025-09-04 UTC."],[],[],null,["# Vertex AI RAG Engine overview\n\n| The [VPC-SC security controls](/vertex-ai/generative-ai/docs/security-controls) and\n| CMEK are supported by Vertex AI RAG Engine. Data residency and AXT security controls aren't\n| supported.\n| You must be added to the allowlist to access\n| Vertex AI RAG Engine in `us-central1`. For users\n| with existing projects, there is no impact. For users with new projects, you\n| can try other regions, or contact\n| `vertex-ai-rag-engine-support@google.com` to onboard to\n| `us-central1`.\n\nThis page describes what Vertex AI RAG Engine is and how it\nworks.\n\nOverview\n--------\n\nVertex AI RAG Engine, a component of the Vertex AI\nPlatform, facilitates Retrieval-Augmented Generation (RAG).\nVertex AI RAG Engine is also a data framework for developing\ncontext-augmented large language model (LLM) applications. Context augmentation\noccurs when you apply an LLM to your data. This implements retrieval-augmented\ngeneration (RAG).\n\nA common problem with LLMs is that they don't understand private knowledge, that\nis, your organization's data. With Vertex AI RAG Engine, you can\nenrich the LLM context with additional private information, because the model\ncan reduce hallucination and answer questions more accurately.\n\nBy combining additional knowledge sources with the existing knowledge that LLMs\nhave, a better context is provided. The improved context along with the query\nenhances the quality of the LLM's response.\n\nThe following image illustrates the key concepts to understanding\nVertex AI RAG Engine.\n\nThese concepts are listed in the order of the retrieval-augmented generation\n(RAG) process.\n\n1. **Data ingestion**: Intake data from different data sources. For example,\n local files, Cloud Storage, and Google Drive.\n\n2. [**Data transformation**](/vertex-ai/generative-ai/docs/fine-tune-rag-transformations):\n Conversion of the data in preparation for indexing. For example, data is\n split into chunks.\n\n3. [**Embedding**](/vertex-ai/generative-ai/docs/embeddings/get-text-embeddings): Numerical\n representations of words or pieces of text. These numbers capture the\n semantic meaning and context of the text. Similar or related words or text\n tend to have similar embeddings, which means they are closer together in the\n high-dimensional vector space.\n\n4. **Data indexing** : Vertex AI RAG Engine creates an index called a [corpus](/vertex-ai/generative-ai/docs/manage-your-rag-corpus#corpus-management).\n The index structures the knowledge base so it's optimized for searching. For\n example, the index is like a detailed table of contents for a massive\n reference book.\n\n5. **Retrieval**: When a user asks a question or provides a prompt, the retrieval\n component in Vertex AI RAG Engine searches through its knowledge\n base to find information that is relevant to the query.\n\n6. **Generation** : The retrieved information becomes the context added to the\n original user query as a guide for the generative AI model to generate\n factually [grounded](/vertex-ai/generative-ai/docs/grounding/overview) and relevant responses.\n\nSupported regions\n-----------------\n\nVertex AI RAG Engine is supported in the following regions:\n\n- `us-central1` is changed to `Allowlist`. If you'd like to experiment with Vertex AI RAG Engine, try other regions. If you plan to onboard your production traffic to `us-central1`, contact `vertex-ai-rag-engine-support@google.com`.\n\nSubmit feedback\n---------------\n\nTo chat with Google support, go to the [Vertex AI RAG Engine\nsupport\ngroup](https://groups.google.com/a/google.com/g/vertex-ai-rag-engine-support).\n\nTo send an email, use the email address\n`vertex-ai-rag-engine-support@google.com`.\n\nWhat's next\n-----------\n\n- To learn how to use the Vertex AI SDK to run Vertex AI RAG Engine tasks, see [RAG quickstart for\n Python](/vertex-ai/generative-ai/docs/rag-quickstart).\n- To learn about grounding, see [Grounding\n overview](/vertex-ai/generative-ai/docs/grounding/overview).\n- To learn more about the responses from RAG, see [Retrieval and Generation Output of Vertex AI RAG Engine](/vertex-ai/generative-ai/docs/model-reference/rag-output-explained).\n- To learn about the RAG architecture:\n - [Infrastructure for a RAG-capable generative AI application using Vertex AI and Vector Search](/architecture/gen-ai-rag-vertex-ai-vector-search)\n - [Infrastructure for a RAG-capable generative AI application using Vertex AI and AlloyDB for PostgreSQL](/architecture/rag-capable-gen-ai-app-using-vertex-ai)."]]