É possível usar o Imagen na Vertex AI para gerar novas imagens com base em um comando de texto. As interfaces compatíveis incluem o console Google Cloud e a API Vertex AI.
Para mais informações sobre como escrever solicitações de texto para geração e edição de imagens, consulte o guia de solicitação.
Ver o card do modelo Imagen para geração
Testar a geração de imagens (Vertex AI Studio)
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Configure a autenticação do ambiente.
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
Python
Para usar os exemplos Python desta página em um ambiente de desenvolvimento local, instale e inicialize a CLI gcloud e configure o Application Default Credentials com suas credenciais de usuário.
Instale a CLI do Google Cloud.
Ao usar um provedor de identidade (IdP) externo, primeiro faça login na gcloud CLI com sua identidade federada.
If you're using a local shell, then create local authentication credentials for your user account:
gcloud auth application-default login
You don't need to do this if you're using Cloud Shell.
If an authentication error is returned, and you are using an external identity provider (IdP), confirm that you have signed in to the gcloud CLI with your federated identity.
Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local na documentação de autenticação do Google Cloud .
REST
Para usar as amostras da API REST nesta página em um ambiente de desenvolvimento local, use as credenciais fornecidas para a CLI gcloud.
Instale a CLI do Google Cloud.
Ao usar um provedor de identidade (IdP) externo, primeiro faça login na gcloud CLI com sua identidade federada.
Para mais informações, consulte Autenticar para usar REST na documentação de autenticação do Google Cloud .
Gerar imagens com texto
Você pode gerar novas imagens usando apenas texto descritivo como entrada. Os exemplos a seguir mostram instruções básicas para gerar imagens.
Console
No console do Google Cloud , acesse a página Vertex AI > Media Studio.
Clique em Imagen. A página de geração de imagens do Imagen Media Studio é mostrada.
Opcional: no painel Configurações, defina o seguinte:
Modelo: escolha um modelo entre as opções disponíveis.
Para mais informações sobre os modelos disponíveis, consulte Modelos do Imagen.
Proporção: escolha uma das opções disponíveis.
Número de resultados: ajuste o controle deslizante ou insira um valor entre 1 e 4.
Resolução de saída: escolha uma resolução entre as opções disponíveis.
Opcional: na seção Opções avançadas, selecione uma Região para gerar suas imagens.
Na caixa Escreva seu comando, insira o comando de texto que descreve as imagens a serem geradas. Por exemplo, ilustração em aquarela de pequeno barco na água durante a manhã.
Para mais informações sobre como escrever comandos eficazes, consulte o Guia de comandos e atributos de imagem.
Clique em Gerar.
Uma marca-d'água digital é adicionada automaticamente às imagens geradas. Não é possível desativar a marca-d'água digital para a geração de imagens usando o console Google Cloud .
É possível selecionar uma imagem para ver na janela Detalhes da imagem. As imagens com marca-d'água têm um selo de marca d'água digital. Também é possível verificar explicitamente uma marca-d'água de imagem.
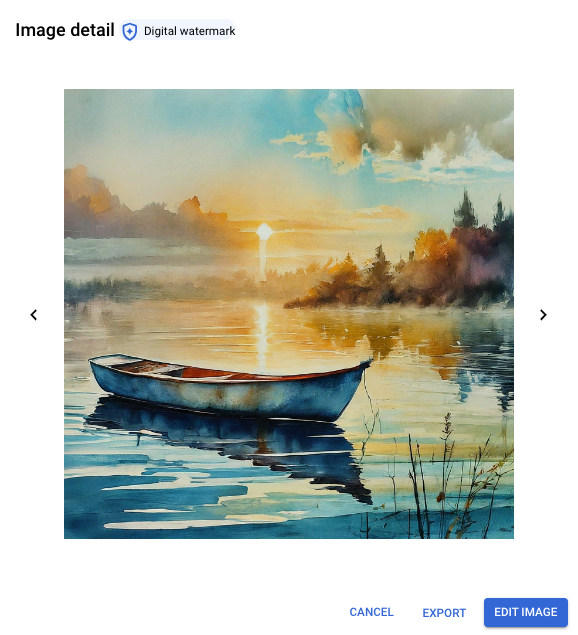
Visualização de detalhes de uma imagem com marca-d'água gerada com o Imagen 2 usando o comando: pequeno barco vermelho na água de manhã em aquarela com cores suaves.
Python
Instalar
pip install --upgrade google-genai
Para saber mais, consulte a documentação de referência do SDK.
Defina variáveis de ambiente para usar o SDK de IA generativa com a Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Neste exemplo, você chama o método
generate_imagesnoImageGenerationModele salva as imagens geradas localmente. Em seguida, é possível usar o métodoshow()em um notebook para mostrar as imagens geradas. Para mais informações sobre versões e atributos de modelos, consulte Modelos do Imagen.REST
Para mais informações sobre solicitações de modelo
imagegeneration, consulte a referência da API do modeloimagegeneration.Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- PROJECT_ID: o ID do projeto do Google Cloud .
-
MODEL_VERSION: a versão do modelo do Imagen a ser usada. Para mais informações sobre os modelos disponíveis, consulte Modelos do Imagen.
- LOCATION: a região do seu projeto. Por exemplo,
us-central1,europe-west2ouasia-northeast3. Para uma lista de regiões disponíveis, consulte IA generativa em locais da Vertex AI. - TEXT_PROMPT: o comando de texto que orienta quais imagens o modelo gera. Este campo é obrigatório para geração e edição.
- IMAGE_COUNT: o número de imagens geradas.
Valores inteiros aceitos: 1 a 8 (
imagegeneration@002), 1 a 4 (todas as outras versões de modelo). Valor padrão: 4. - ADD_WATERMARK: booleano. Opcional. Indica se uma marca-d'água será ativada para imagens geradas.
Qualquer imagem gerada quando o campo está definido como
truecontém um SynthID digital que você pode usar para verificar uma imagem de marca d'água. Se você omitir esse campo, o valor padrão detrueserá usado. Defina o valor comofalsepara desativar esse recurso. Só é possível usar o camposeedpara receber uma saída determinística quando ele estiver definido comofalse. - ASPECT_RATIO: string. Opcional. Um parâmetro do modo de geração que controla a proporção. Valores de proporção aceitos e o uso pretendido:
1:1(padrão, quadrado)3:4(anúncios, mídias sociais)4:3(TV, fotografia)16:9(paisagem)9:16(retrato)
- ENABLE_PROMPT_REWRITING: booleano. Opcional. Um parâmetro para usar um recurso de alteração de comando baseado em LLM para gerar imagens de melhor qualidade que reflitam melhor a intenção do comando original. Desativar esse recurso pode afetar a qualidade da imagem e a adesão ao comando. Valor padrão:
true -
INCLUDE_RAI_REASON: booleano. Opcional. Define se o código de motivo filtrado da IA responsável será ativado em respostas com entrada ou saída bloqueada. Valor padrão:
true. - INCLUDE_SAFETY_ATTRIBUTES: booleano. Opcional. Define se as pontuações de IA responsável arredondadas serão ativadas para uma lista de atributos de segurança nas respostas de entrada e saída não filtradas. Categorias de atributos de segurança:
"Death, Harm & Tragedy","Firearms & Weapons","Hate","Health","Illicit Drugs","Politics","Porn","Religion & Belief","Toxic","Violence","Vulgarity","War & Conflict". Valor padrão:false. - MIME_TYPE: string. Opcional. O tipo MIME do conteúdo da imagem. Valores disponíveis:
image/jpegimage/gifimage/pngimage/webpimage/bmpimage/tiffimage/vnd.microsoft.icon
- COMPRESSION_QUALITY: número inteiro. Opcional. Aplicável apenas a arquivos de saída JPEG. O nível de detalhes que o modelo preserva para imagens geradas no formato de arquivo JPEG. Valores:
0a100, em que um número maior significa mais compactação. Padrão:75. - PERSON_SETTING: string. Opcional. A configuração de segurança que controla o tipo de
pessoas ou geração de rostos permitida pelo modelo. Valores disponíveis:
allow_adult(padrão): permite a geração somente de adultos, exceto para celebridades. A geração de celebridades não é permitida em nenhuma configuração.dont_allow: desativa a inclusão de pessoas ou rostos nas imagens geradas.
- SAFETY_SETTING: string. Opcional. Uma configuração que controla os limites de filtro de segurança
para as imagens geradas. Valores disponíveis:
block_low_and_above: o limite de segurança mais alto, resultando na maior quantidade de imagens geradas que são filtradas. Valor anterior:block_most.block_medium_and_above(padrão): um limite de segurança médio que equilibra a filtragem de conteúdo potencialmente nocivo e seguro. Valor anterior:block_some.block_only_high: um limite de segurança que reduz o número de solicitações bloqueadas devido a filtros de segurança. Essa configuração pode aumentar o conteúdo censurável gerado pelo Imagen. Valor anterior:block_few.
- SEED_NUMBER: número inteiro. Opcional. Qualquer número inteiro não negativo fornecido para tornar as imagens de saída determinísticas. Fornecer o mesmo número de origem sempre resulta nas mesmas imagens de saída. Se o modelo que você está usando for compatível com marca d'água digital, defina
"addWatermark": falsepara usar esse campo. Valores inteiros aceitos:1a2147483647. - OUTPUT_STORAGE_URI: string. Opcional. O bucket do Cloud Storage para armazenar as imagens de saída. Se não for fornecido, os bytes de imagem codificados em base64 serão retornados na resposta. Exemplo de valor:
gs://image-bucket/output/.
Outros parâmetros opcionais
Use as seguintes variáveis opcionais dependendo do seu caso de uso. Adicione alguns ou todos os parâmetros a seguir no objeto
"parameters": {}. Esta lista mostra parâmetros opcionais comuns e não está completa. Para mais informações sobre parâmetros opcionais, consulte Referência da API Imagen: gerar imagens."parameters": { "sampleCount": IMAGE_COUNT, "addWatermark": ADD_WATERMARK, "aspectRatio": "ASPECT_RATIO", "enhancePrompt": ENABLE_PROMPT_REWRITING, "includeRaiReason": INCLUDE_RAI_REASON, "includeSafetyAttributes": INCLUDE_SAFETY_ATTRIBUTES, "outputOptions": { "mimeType": "MIME_TYPE", "compressionQuality": COMPRESSION_QUALITY }, "personGeneration": "PERSON_SETTING", "safetySetting": "SAFETY_SETTING", "seed": SEED_NUMBER, "storageUri": "OUTPUT_STORAGE_URI" }Método HTTP e URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_VERSION:predict
Corpo JSON da solicitação:
{ "instances": [ { "prompt": "TEXT_PROMPT" } ], "parameters": { "sampleCount": IMAGE_COUNT } }Para enviar a solicitação, escolha uma destas opções:
O exemplo de resposta a seguir é para uma solicitação comcurl
Salve o corpo da solicitação em um arquivo com o nome
request.jsone execute o comando a seguir:curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_VERSION:predict"PowerShell
Salve o corpo da solicitação em um arquivo com o nome
request.jsone execute o comando a seguir:$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_VERSION:predict" | Select-Object -Expand Content"sampleCount": 2. A resposta retorna dois objetos de previsão, com os bytes de imagem gerados codificados em base64.{ "predictions": [ { "bytesBase64Encoded": "BASE64_IMG_BYTES", "mimeType": "image/png" }, { "mimeType": "image/png", "bytesBase64Encoded": "BASE64_IMG_BYTES" } ] }
Se você usar um modelo que ofereça suporte ao aprimoramento de comandos, a resposta vai incluir um campo
promptadicional com o comando aprimorado usado para geração:{ "predictions": [ { "mimeType": "MIME_TYPE", "prompt": "ENHANCED_PROMPT_1", "bytesBase64Encoded": "BASE64_IMG_BYTES_1" }, { "mimeType": "MIME_TYPE", "prompt": "ENHANCED_PROMPT_2", "bytesBase64Encoded": "BASE64_IMG_BYTES_2" } ] }A seguir
Confira artigos sobre o Imagen e outras IAs generativas nos produtos da Vertex AI:
- Guia para desenvolvedores sobre como começar a usar o Imagen 3 na Vertex AI
- Novos modelos e ferramentas de mídia generativa criados com criadores para criadores
- Novidades no Gemini: Gems personalizados e geração de imagens aprimorada com o Imagen 3
- Google DeepMind: Imagen 3 — Nosso modelo de qualidade mais alta para conversão de texto em imagem
Exceto em caso de indicação contrária, o conteúdo desta página é licenciado de acordo com a Licença de atribuição 4.0 do Creative Commons, e as amostras de código são licenciadas de acordo com a Licença Apache 2.0. Para mais detalhes, consulte as políticas do site do Google Developers. Java é uma marca registrada da Oracle e/ou afiliadas.
Última atualização 2025-09-16 UTC.