Puedes usar Imagen en Vertex AI para generar imágenes nuevas a partir de una instrucción de texto. Las interfaces compatibles incluyen la consola Google Cloud y la API de Vertex AI.
Si deseas obtener más información sobre cómo escribir mensajes de texto para la generación y edición de imágenes, consulta la guía de instrucciones.
Consulta la tarjeta del modelo de Imagen for Generation
Prueba la generación de imágenes (Vertex AI Studio)
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Configura la autenticación para tu entorno.
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
Python
Para usar las muestras de Python de esta página en un entorno de desarrollo local, instala e inicializa gcloud CLI y, luego, configura las credenciales predeterminadas de la aplicación con tus credenciales de usuario.
Instala Google Cloud CLI.
Si usas un proveedor de identidad externo (IdP), primero debes acceder a gcloud CLI con tu identidad federada.
If you're using a local shell, then create local authentication credentials for your user account:
gcloud auth application-default login
You don't need to do this if you're using Cloud Shell.
If an authentication error is returned, and you are using an external identity provider (IdP), confirm that you have signed in to the gcloud CLI with your federated identity.
Para obtener más información, consulta Configura ADC para un entorno de desarrollo local en la documentación de autenticación de Google Cloud .
REST
Para usar las muestras de la API de REST en esta página en un entorno de desarrollo local, debes usar las credenciales que proporciones a gcloud CLI.
Instala Google Cloud CLI.
Si usas un proveedor de identidad externo (IdP), primero debes acceder a gcloud CLI con tu identidad federada.
Para obtener más información, consulta Autentícate para usar REST en la documentación de autenticación de Google Cloud .
Genera imágenes con texto
Puedes generar imágenes nuevas solo con texto descriptivo como entrada. En los siguientes ejemplos, se muestran instrucciones básicas para generar imágenes.
Console
En la Google Cloud consola, ve a la página Vertex AI > Media Studio.
Haz clic en Imagen. Se mostrará la página de generación de imágenes de Imagen Media Studio.
Opcional: En el panel Configuración, establece los siguientes parámetros de configuración:
Modelo: Elige un modelo entre las opciones disponibles.
Para obtener más información sobre los modelos disponibles, consulta Modelos de Imagen.
Relación de aspecto: Elige una relación de aspecto entre las opciones disponibles.
Cantidad de resultados: Ajusta el control deslizante o ingresa un valor entre 1 y 4.
Resolución de salida: Elige una resolución entre las opciones disponibles.
Opcional: En la sección Opciones avanzadas, selecciona una región en la que generar tus imágenes.
En el cuadro Escribe tu instrucción, ingresa la instrucción de texto que describe las imágenes que se generarán. Por ejemplo, barco pequeño en el agua en la ilustración de acuarela matutina.
Para obtener más información sobre cómo escribir instrucciones eficaces, consulta la Guía de atributos de imágenes e instrucciones.
Haz clic en Generar .
Se agrega automáticamente una marca de agua digital a las imágenes generadas. No puedes inhabilitar la marca de agua digital para la generación de imágenes con la consola de Google Cloud .
Puedes seleccionar una imagen para verla en la ventana Detalles de la imagen. Las imágenes con marcas de agua contienen una insignia de marca de agua digital. También puedes verificar de manera explícita una marca de agua de imagen.
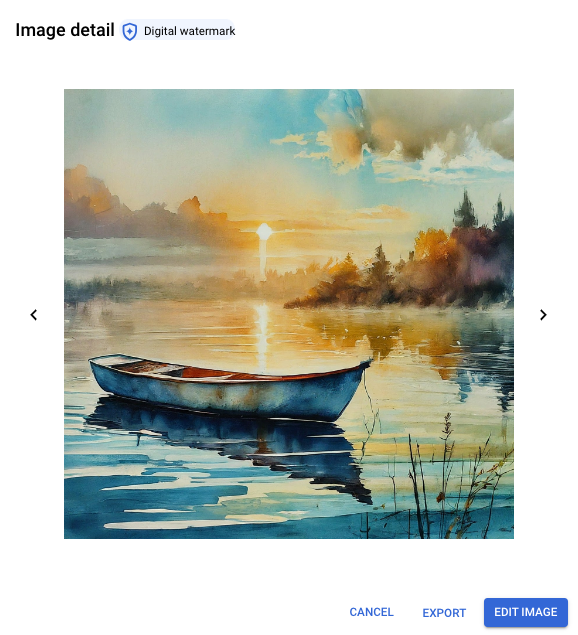
Detalles de la imagen vista de una imagen con marca de agua generada con Imagen 2 a partir de la instrucción: pequeño barco rojo en el agua en la ilustración de acuarela matutina con colores apagados.
Python
Instalar
pip install --upgrade google-genai
Para obtener más información, consulta la documentación de referencia del SDK.
Establece variables de entorno para usar el SDK de IA generativa con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
En este ejemplo, se llama al método
generate_imagesenImageGenerationModely se guardan las imágenes generadas de forma local. Luego, de forma opcional, puedes usar el métodoshow()en un notebook para mostrar las imágenes generadas. Para obtener más información sobre las versiones y las características de los modelos, consulta Modelos de Imagen.REST
Para obtener más información sobre las solicitudes del modelo
imagegeneration, consulta la referencia de la API del modeloimagegeneration.Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- PROJECT_ID: El Google Cloud ID del proyecto.
-
MODEL_VERSION: Es la versión del modelo Imagen que se usará. Para obtener más información sobre los modelos disponibles, consulta Modelos de Imagen.
- LOCATION: La región del proyecto. Por ejemplo,
us-central1,europe-west2oasia-northeast3. Para obtener una lista de las regiones disponibles, consulta IA generativa en ubicaciones de Vertex AI. - TEXT_PROMPT: Es la instrucción de texto que guía qué imágenes genera el modelo. Este campo es obligatorio para la generación y la edición.
- IMAGE_COUNT: La cantidad de imágenes generadas.
Valores de números enteros aceptados: 1-8 (
imagegeneration@002), 1-4 (todas las demás versiones del modelo). Valor predeterminado: 4. - ADD_WATERMARK: booleano. Opcional. Indica si se debe habilitar una marca de agua para las imágenes generadas.
Cualquier imagen generada cuando el campo se configura como
truecontiene un SynthID digital que puedes usar para verificar una imagen con marca de agua. Si omites este campo, se usa el valor predeterminado detrue. Debes establecer el valor enfalsepara inhabilitar esta función. Puedes usar el camposeedpara obtener una salida determinista solo cuando este campo se establece enfalse. - ASPECT_RATIO: cadena. Opcional. Es un parámetro del modo de generación que controla la relación de aspecto. Valores de proporción admitidos y su uso previsto:
1:1(predeterminado, cuadrado)3:4(anuncios y redes sociales)4:3(TV, fotografía)16:9(horizontal)9:16(vertical)
- ENABLE_PROMPT_REWRITING: booleano. Opcional. Es un parámetro para usar una función de reformulación de instrucciones basada en LLM para generar imágenes de mayor calidad que reflejen mejor la intención de la instrucción original. Inhabilitar esta función puede afectar la calidad de la imagen y el cumplimiento de las instrucciones. Valor predeterminado
true. -
INCLUDE_RAI_REASON: booleano. Opcional. Indica si se debe habilitar el código de motivo filtrado de IA responsable en respuestas con entrada o salida bloqueadas. Valor predeterminado:
true. - INCLUDE_SAFETY_ATTRIBUTES: booleano. Opcional. Indica si se deben habilitar las
puntuaciones redondeadas de IA responsable para obtener una lista de atributos de seguridad en las respuestas de entrada y salida
sin filtrar. Categorías de atributos de seguridad:
"Death, Harm & Tragedy","Firearms & Weapons","Hate","Health","Illicit Drugs","Politics","Porn","Religion & Belief","Toxic","Violence","Vulgarity","War & Conflict". Valor predeterminado:false. - MIME_TYPE: cadena. Opcional. El tipo de MIME del contenido de la imagen. Valores disponibles:
image/jpegimage/gifimage/pngimage/webpimage/bmpimage/tiffimage/vnd.microsoft.icon
- COMPRESSION_QUALITY: número entero. Opcional. Solo se aplica a los archivos de salida JPEG. Es el nivel de detalle que conserva el modelo para las imágenes generadas en formato de archivo JPEG. Valores:
0a100, donde un número más alto significa más compresión. Valor predeterminado:75. - PERSON_SETTING: cadena. Opcional. Es el parámetro de configuración de seguridad que controla el tipo de generación de personas o rostros que permite el modelo. Valores disponibles:
allow_adult(configuración predeterminada): permite la generación de adultos solamente, excepto la generación de celebridades. No se permite la generación de celebridades para ningún parámetro de configuración.dont_allow: Inhabilita la inclusión de personas o rostros en las imágenes generadas.
- SAFETY_SETTING: cadena. Opcional. Es un parámetro de configuración que controla los umbrales del filtro de seguridad para las imágenes generadas. Valores disponibles:
block_low_and_above: El umbral de seguridad más alto, que da como resultado la mayor cantidad de imágenes generadas que se filtran. Valor anterior:block_most.block_medium_and_above(configuración predeterminada): Un umbral de seguridad medio que equilibra el filtrado del contenido potencialmente dañino y seguro. Valor anterior:block_some.block_only_high: Es un umbral de seguridad que reduce la cantidad de solicitudes bloqueadas debido a los filtros de seguridad. Esta configuración puede aumentar el contenido censurable que genera Imagen. Valor anterior:block_few.
- SEED_NUMBER: número entero. Opcional. Cualquier número entero no negativo que proporciones para que las imágenes de salida sean determinísticas. Proporcionar el mismo número de origen siempre da como resultado las mismas imágenes de salida. Si el modelo que usas admite marcas de agua digitales, debes establecer
"addWatermark": falsepara usar este campo. Valores de números enteros aceptados:1a2147483647. - OUTPUT_STORAGE_URI: cadena. Opcional. Es el bucket de Cloud Storage para almacenar las imágenes de salida. Si no se proporciona, se devuelven los bytes de imagen codificados en base64 en la respuesta. Valor de ejemplo:
gs://image-bucket/output/.
Parámetros opcionales adicionales
Usa las siguientes variables opcionales según tu caso de uso. Agrega algunos o todos los siguientes parámetros en el objeto
"parameters": {}. Esta lista muestra parámetros opcionales comunes y no pretende ser exhaustiva. Para obtener más información sobre los parámetros opcionales, consulta la referencia de la API de Imagen: Genera imágenes."parameters": { "sampleCount": IMAGE_COUNT, "addWatermark": ADD_WATERMARK, "aspectRatio": "ASPECT_RATIO", "enhancePrompt": ENABLE_PROMPT_REWRITING, "includeRaiReason": INCLUDE_RAI_REASON, "includeSafetyAttributes": INCLUDE_SAFETY_ATTRIBUTES, "outputOptions": { "mimeType": "MIME_TYPE", "compressionQuality": COMPRESSION_QUALITY }, "personGeneration": "PERSON_SETTING", "safetySetting": "SAFETY_SETTING", "seed": SEED_NUMBER, "storageUri": "OUTPUT_STORAGE_URI" }Método HTTP y URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_VERSION:predict
Cuerpo JSON de la solicitud:
{ "instances": [ { "prompt": "TEXT_PROMPT" } ], "parameters": { "sampleCount": IMAGE_COUNT } }Para enviar tu solicitud, elige una de estas opciones:
La siguiente respuesta de muestra es para una solicitud concurl
Guarda el cuerpo de la solicitud en un archivo llamado
request.jsony ejecuta el siguiente comando:curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_VERSION:predict"PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado
request.jsony ejecuta el siguiente comando:$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_VERSION:predict" | Select-Object -Expand Content"sampleCount": 2. La respuesta muestra dos objetos de predicción, con los bytes de imagen generados codificados en base64.{ "predictions": [ { "bytesBase64Encoded": "BASE64_IMG_BYTES", "mimeType": "image/png" }, { "mimeType": "image/png", "bytesBase64Encoded": "BASE64_IMG_BYTES" } ] }
Si usas un modelo que admite la mejora de instrucciones, la respuesta incluye un campo
promptadicional con la instrucción mejorada que se usó para la generación:{ "predictions": [ { "mimeType": "MIME_TYPE", "prompt": "ENHANCED_PROMPT_1", "bytesBase64Encoded": "BASE64_IMG_BYTES_1" }, { "mimeType": "MIME_TYPE", "prompt": "ENHANCED_PROMPT_2", "bytesBase64Encoded": "BASE64_IMG_BYTES_2" } ] }¿Qué sigue?
Lee artículos sobre Imagen y otros productos de IA generativa en Vertex AI:
- Guía para desarrolladores para comenzar a usar Imagen 3 en Vertex AI
- Nuevos modelos y herramientas de medios generativos creados con y para los creadores
- Novedades de Gemini: Gemas personalizadas y generación de imágenes mejorada con Imagen 3
- Google DeepMind: Imagen 3: nuestro modelo de texto a imagen de mayor calidad
Salvo que se indique lo contrario, el contenido de esta página está sujeto a la licencia Atribución 4.0 de Creative Commons, y los ejemplos de código están sujetos a la licencia Apache 2.0. Para obtener más información, consulta las políticas del sitio de Google Developers. Java es una marca registrada de Oracle o sus afiliados.
Última actualización: 2025-09-16 (UTC)