Les modèles d'embeddings Vertex AI peuvent générer des embeddings optimisés pour différents types de tâches, tels que la récupération de documents, l'établissement de systèmes de questions-réponses et la vérification des faits. Les types de tâches sont des étiquettes qui optimisent les embeddings générés par le modèle en fonction de votre cas d'utilisation. Ce document explique comment choisir le type de tâche optimal pour vos embeddings.
Modèles compatibles
Les types de tâches sont compatibles avec les modèles suivants :
text-embedding-005text-multilingual-embedding-002gemini-embedding-001
Avantages des types de tâches
Les types de tâches peuvent améliorer la qualité des embeddings générés par un modèle d'embeddings.
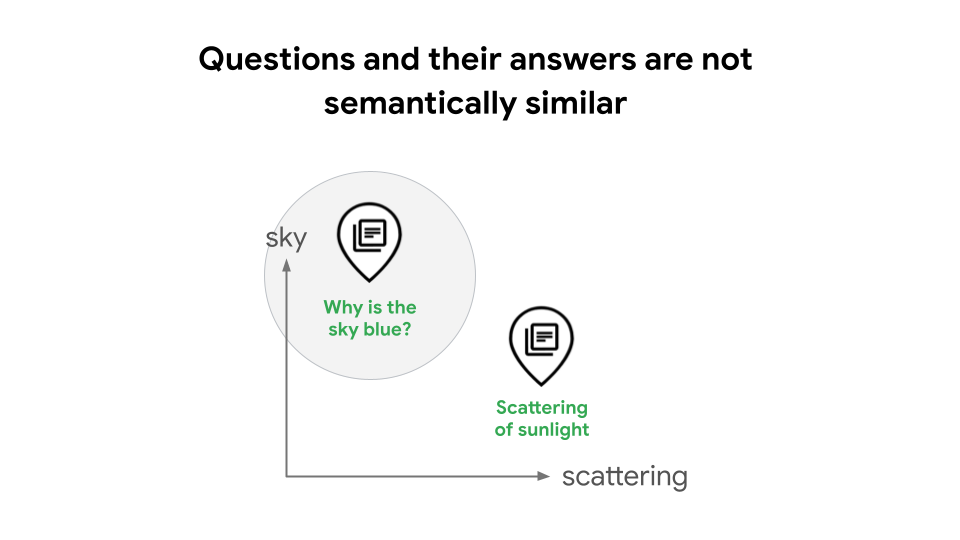
Par exemple, lors de la création de systèmes de génération augmentée par récupération (RAG), il est courant d'utiliser des embeddings textuels et la recherche vectorielle pour effectuer une recherche de similitude. Dans certains cas, cela peut entraîner une dégradation de la qualité de la recherche, car les questions et leurs réponses ne sont pas sémantiquement similaires. Par exemple, une question comme "Pourquoi le ciel est-il bleu ?" et sa réponse "La diffusion de la lumière du soleil provoque la couleur bleue" ont des significations distinctes en tant qu'énoncés. Cela signifie qu'un système RAG ne reconnaîtra pas automatiquement leur relation, comme illustré dans la figure 1. Sans types de tâches, un développeur RAG doit entraîner son modèle pour apprendre la relation entre les requêtes et les réponses. Cela nécessite des compétences et une expérience avancées en data science, ou l'utilisation de l'extension des requêtes basée sur un LLM ou HyDE, qui peut entraîner une latence et des coûts élevés.

Les types de tâches vous permettent de générer des embeddings optimisés pour des tâches spécifiques. Vous pouvez ainsi gagner du temps et éviter les coûts nécessaires pour développer vos propres embeddings spécifiques à des tâches. L'embedding généré pour la requête "Pourquoi le ciel est-il bleu ?" et sa réponse "La couleur bleue est due à la diffusion de la lumière du soleil" se trouveraient dans l'espace d'embedding partagé qui représente la relation entre eux, comme illustré dans la figure 2. Dans cet exemple de RAG, les embeddings optimisés permettent d'améliorer les recherches de similitude.
En plus du cas d'utilisation de la requête et de la réponse, les types de tâches fournissent également un espace d'embeddings optimisé pour des tâches telles que la classification, le clustering et la vérification des faits.
Types de tâches compatibles
Les modèles d'embeddings qui utilisent des types de tâches sont compatibles avec les types de tâches suivants :
| Type de tâche | Description |
|---|---|
CLASSIFICATION |
Permet de générer des embeddings optimisés pour classer des textes en fonction d'étiquettes prédéfinies |
CLUSTERING |
Permet de générer des embeddings optimisés pour regrouper des textes en fonction de leurs similitudes |
RETRIEVAL_DOCUMENT, RETRIEVAL_QUERY, QUESTION_ANSWERING et FACT_VERIFICATION |
Permettent de générer des embeddings optimisés pour la recherche de documents ou la récupération d'informations |
CODE_RETRIEVAL_QUERY |
Permet de récupérer un bloc de code en fonction d'une requête en langage naturel, par exemple trier un tableau ou inverser une liste associée. Les embeddings des blocs de code sont calculés à l'aide de RETRIEVAL_DOCUMENT. |
SEMANTIC_SIMILARITY |
Permet de générer des embeddings optimisés pour évaluer la similitude de texte. Il n'est pas destiné aux cas d'utilisation de récupération. |
Le type de tâche le plus adapté à votre job d'embeddings dépend du cas d'utilisation de vos embeddings. Avant de sélectionner un type de tâche, déterminez le cas d'utilisation de vos embeddings.
Déterminer le cas d'utilisation de vos embeddings
Les cas d'utilisation des embeddings appartiennent généralement à l'une des quatre catégories suivantes : évaluer la similitude des textes, classer les textes, regrouper les textes ou récupérer des informations à partir de textes. Si votre cas d'utilisation ne correspond à aucune des catégories précédentes, utilisez le type de tâche RETRIEVAL_QUERY par défaut.
Il existe deux types de mise en forme des instructions de tâches : le format asymétrique et le format symétrique. Vous devrez utiliser le bon en fonction de votre cas d'utilisation.
| Cas d'utilisation de la récupération (format asymétrique) |
Type de tâche de requête | Type de tâche de document |
|---|---|---|
| Requête de recherche | RETRIEVAL_QUERY | RETRIEVAL_DOCUMENT |
| Systèmes de questions-réponses | QUESTION_ANSWERING | |
| Fact-checking | FACT_VERIFICATION | |
| Récupération du code | CODE_RETRIEVAL_QUERY |
| Cas d'utilisation à entrée unique (format symétrique) |
Type de tâche d'entrée |
|---|---|
| Classification | CLASSIFICATION |
| Clustering | CLUSTERING |
| Similarité sémantique (Ne pas utiliser pour les cas d'utilisation de récupération ; destiné à la STS) |
SEMANTIC_SIMILARITY |
Classer des textes
Si vous souhaitez utiliser des embeddings pour classer des textes en fonction d'étiquettes prédéfinies, utilisez le type de tâche CLASSIFICATION. Ce type de tâche génère des embeddings dans un espace d'embeddings optimisé pour la classification.
Par exemple, supposons que vous souhaitiez générer des embeddings pour des posts sur les réseaux sociaux que vous pourrez ensuite utiliser pour classer leur sentiment comme positif, négatif ou neutre. Lors de la classification des embeddings du post sur les réseaux sociaux : "Je n'aime pas voyager en avion", le sentiment est classé comme négatif.
Regrouper des textes
Si vous souhaitez utiliser des embeddings pour regrouper des textes en fonction de leurs similitudes, utilisez le type de tâche CLUSTERING. Ce type de tâche génère des embeddings optimisés pour être regroupés en fonction de leurs similitudes.
Par exemple, supposons que vous souhaitiez générer des embeddings pour des articles d'actualité afin de pouvoir présenter aux utilisateurs des articles qui sont liés aux sujets qu'ils ont déjà lus. Une fois les embeddings générés et regroupés, vous pouvez suggérer d'autres articles sur le sport aux utilisateurs qui lisent beaucoup d'articles sur ce sujet.
Voici d'autres cas d'utilisation du clustering :
- Segmentation de la clientèle : regroupez les clients dont les embeddings générés à partir de leurs profils ou de leurs activités sont similaires pour des campagnes marketing ciblées et des expériences personnalisées.
- Segmentation des produits : regrouper les embeddings de produits en fonction de leur titre et de leur description, de leurs images ou des avis clients peut aider les entreprises à analyser leurs produits par segment.
- Études de marché : regrouper les réponses à des enquêtes auprès des consommateurs ou les données intégrées des réseaux sociaux peut révéler des tendances et des modèles cachés dans les opinions, les préférences et les comportements des consommateurs, ce qui permet d'améliorer les études de marché et d'orienter les stratégies de développement de produits.
- Santé : regrouper les embeddings de patients issus de données médicales peut aider à identifier des groupes présentant des états de santé ou des réponses au traitement similaires, ce qui permet de proposer des protocoles de soin et des traitements ciblés plus personnalisés.
- Tendances des commentaires des clients : regrouper les commentaires des clients provenant de différents canaux (enquêtes, réseaux sociaux, demandes d'assistance) peut aider à identifier les problèmes courants, les demandes de fonctionnalités et les domaines à améliorer d'un produit.
Récupérer des informations à partir de textes
Lorsque vous créez un système de recherche ou de récupération, vous travaillez avec deux types de texte :
- Corpus : ensemble de documents dans lesquels vous souhaitez effectuer une recherche.
- Requête : texte fourni par un utilisateur pour rechercher des informations dans le corpus.
Pour obtenir les meilleures performances, vous devez utiliser différents types de tâches pour générer des embeddings pour votre corpus et vos requêtes.
Commencez par générer des embeddings pour l'ensemble de votre collection de documents. Il s'agit du contenu qui sera récupéré par les requêtes utilisateur. Lorsque vous intégrez ces documents, utilisez le type de tâche RETRIEVAL_DOCUMENT. Vous effectuez généralement cette étape une fois pour indexer l'ensemble de votre corpus, puis stocker les embeddings obtenus dans une base de données vectorielle.
Ensuite, lorsqu'un utilisateur envoie une recherche, vous générez un embedding pour le texte de sa requête en temps réel. Pour ce faire, vous devez utiliser un type de tâche qui correspond à l'intention de l'utilisateur. Votre système utilisera ensuite cet embedding de requête pour trouver les embeddings de documents les plus similaires dans votre base de données vectorielle.
Les types de tâches suivants sont utilisés pour les requêtes :
RETRIEVAL_QUERY: utilisez cette option pour une requête de recherche standard lorsque vous souhaitez trouver des documents pertinents. Le modèle recherche des embeddings de documents qui sont sémantiquement proches de l'embedding de la requête.QUESTION_ANSWERING: à utiliser lorsque toutes les requêtes sont formulées comme des questions, par exemple "Pourquoi le ciel est-il bleu ?" ou "Comment nouer mes lacets ?".FACT_VERIFICATION: à utiliser lorsque vous souhaitez récupérer un document de votre corpus qui confirme ou réfute une affirmation. Par exemple, la requête "les pommes poussent sous terre" peut renvoyer un article sur les pommes qui réfutera en fin de compte l'affirmation.
Prenons les scénarios concrets suivants, où les requêtes de récupération seraient utiles :
- Pour une plate-forme d'e-commerce, vous pouvez utiliser des embeddings pour permettre aux utilisateurs de rechercher des produits à l'aide de requêtes textuelles et d'images. Vous offrirez ainsi une expérience d'achat plus intuitive et engageante.
- Pour une plate-forme éducative, vous pouvez créer un système de questions-réponses capable de répondre aux questions des élèves en fonction du contenu des manuels ou des ressources éducatives. Cela vous permettra d'offrir des expériences d'apprentissage personnalisées et d'aider les élèves à comprendre des concepts complexes.
Récupération du code
text-embedding-005 est compatible avec le nouveau type de tâche CODE_RETRIEVAL_QUERY, qui permet de récupérer des blocs de code pertinents à l'aide de requêtes en texte brut. Pour utiliser cette fonctionnalité, les blocs de code doivent être intégrés à l'aide du type de tâche RETRIEVAL_DOCUMENT, tandis que les requêtes textuelles sont intégrées à l'aide de CODE_RETRIEVAL_QUERY.
Pour explorer tous les types de tâches, consultez la documentation de référence sur les modèles.
Voici un exemple :
REST
PROJECT_ID=PROJECT_ID
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-005:predict -d \
$'{
"instances": [
{
"task_type": "CODE_RETRIEVAL_QUERY",
"content": "Function to add two numbers"
}
],
}'
Python
Pour savoir comment installer ou mettre à jour le SDK Vertex AI pour Python, consultez la section Installer le SDK Vertex AI pour Python. Pour en savoir plus, consultez la documentation de référence de l'API Python.
Évaluer la similitude de texte
Si vous souhaitez utiliser des embeddings pour évaluer la similitude des textes, utilisez le type de tâche SEMANTIC_SIMILARITY. Ce type de tâche génère des embeddings optimisés pour générer des scores de similitude.
Par exemple, supposons que vous souhaitiez générer des embeddings pour comparer la similitude des textes suivants :
- Le chat dort
- Le félin fait la sieste
Lorsque les embeddings sont utilisés pour créer un score de similitude, ce score est élevé, car les deux textes ont presque le même sens.
Considérez les scénarios réels suivants où il serait utile d'évaluer la similitude des entrées :
- Pour un système de recommandation, vous devez identifier les éléments (produits, articles, films, etc.) qui sont sémantiquement similaires aux éléments préférés d'un utilisateur, en fournissant des recommandations personnalisées et en améliorant la satisfaction des utilisateurs.
Les limites suivantes s'appliquent lorsque vous utilisez ces modèles :
- N'utilisez pas ces modèles en version preview sur des systèmes critiques ou de production.
- Ces modèles ne sont disponibles que dans la zone
us-central1. - Les prédictions par lots ne sont pas prises en charge.
- La personnalisation n'est pas prise en charge.
Étape suivante
- Découvrez comment obtenir des embeddings textuels.