Puoi pianificare l'esecuzione di una pipeline precompilata, utilizzando Cloud Scheduler, tramite la funzione Cloud basata su eventi con un trigger HTTP.
Crea e compila una semplice pipeline
Utilizzando l'SDK Kubeflow Pipelines, crea una pipeline pianificata e compilala in un file YAML.
Esempio di hello-world-scheduled-pipeline:
from kfp import compiler
from kfp import dsl
# A simple component that prints and returns a greeting string
@dsl.component
def hello_world(message: str) -> str:
greeting_str = f'Hello, {message}'
print(greeting_str)
return greeting_str
# A simple pipeline that contains a single hello_world task
@dsl.pipeline(
name='hello-world-scheduled-pipeline')
def hello_world_scheduled_pipeline(greet_name: str):
hello_world_task = hello_world(greet_name)
# Compile the pipeline and generate a YAML file
compiler.Compiler().compile(pipeline_func=hello_world_scheduled_pipeline,
package_path='hello_world_scheduled_pipeline.yaml')
Carica il file YAML della pipeline compilato nel bucket Cloud Storage
Apri il browser Cloud Storage nella console Google Cloud.
Fai clic sul bucket Cloud Storage creato durante la configurazione del progetto.
Utilizzando una cartella esistente o una nuova cartella, carica il file YAML della pipeline compilato (in questo esempio
hello_world_scheduled_pipeline.yaml) nella cartella selezionata.Fai clic sul file YAML caricato per accedere ai dettagli. Copia l'URI gsutil per utilizzarlo in seguito.
Crea una Cloud Function con HTTP Trigger
Visita la pagina Cloud Functions nella console.
Fai clic sul pulsante Crea funzione.
Nella sezione Nozioni di base, assegna un nome alla funzione (ad esempio
hello-world-scheduled-pipeline-function).Nella sezione Trigger, seleziona HTTP come tipo di attivatore.
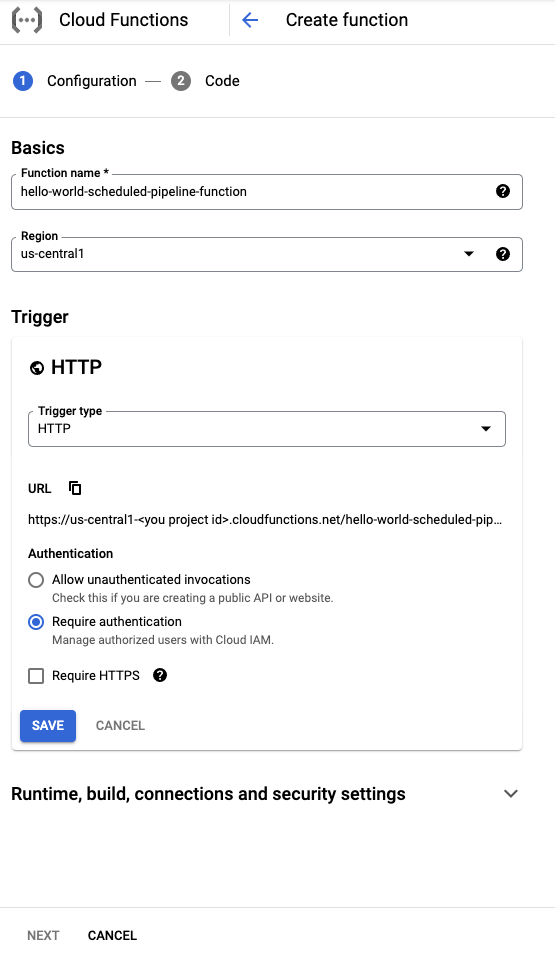
Prendi nota dell'URL generato per questo attivatore e salvalo per utilizzarlo nella sezione successiva.
Lascia tutti gli altri campi predefiniti e fai clic su Salva per salvare la configurazione della sezione Attivatore.
Lascia tutti gli altri campi predefiniti e fai clic su Avanti per passare alla sezione Codice.
In Runtime (Runtime), seleziona Python 3.7.
Nel punto di ingresso, inserisci process_request (il nome della funzione punto di ingresso del codice di esempio).
In Codice sorgente, seleziona l'editor incorporato se non è già selezionato.
Nel file
main.py, aggiungi il seguente codice:import json from google.cloud import aiplatform PROJECT_ID = 'your-project-id' # <---CHANGE THIS REGION = 'your-region' # <---CHANGE THIS PIPELINE_ROOT = 'your-cloud-storage-pipeline-root' # <---CHANGE THIS def process_request(request): """Processes the incoming HTTP request. Args: request (flask.Request): HTTP request object. Returns: The response text or any set of values that can be turned into a Response object using `make_response <http://flask.pocoo.org/docs/1.0/api/#flask.Flask.make_response>`. """ # decode http request payload and translate into JSON object request_str = request.data.decode('utf-8') request_json = json.loads(request_str) pipeline_spec_uri = request_json['pipeline_spec_uri'] parameter_values = request_json['parameter_values'] aiplatform.init( project=PROJECT_ID, location=REGION, ) job = aiplatform.PipelineJob( display_name=f'hello-world-cloud-function-pipeline', template_path=pipeline_spec_uri, pipeline_root=PIPELINE_ROOT, enable_caching=False, parameter_values=parameter_values ) job.submit() return "Job submitted"Sostituisci quanto segue:
- PROJECT_ID: il progetto Google Cloud in cui viene eseguita la pipeline.
- REGION: la regione in cui viene eseguita la pipeline.
- PIPELINE_ROOT: specifica un URI Cloud Storage a cui può accedere il tuo account di servizio della pipeline. Gli artefatti delle esecuzioni di pipeline sono archiviati nella radice della pipeline.
Nel file
requirements.txt, sostituisci i contenuti con i seguenti requisiti del pacchetto:google-api-python-client>=1.7.8,<2 google-cloud-aiplatformFai clic su deploy per eseguire il deployment della funzione.
Crea un job Cloud Scheduler
Visita la pagina Cloud Scheduler nella console.
Fai clic sul pulsante Crea job.
Assegna un nome al job (ad esempio
my-hello-world-schedule) e, se vuoi, aggiungi una descrizione.Specifica la frequenza del job, utilizzando il formato unicron-cron. Ad esempio:
0 9 * * 1Questo esempio di cron schedule viene eseguito ogni lunedì alle 09:00. Per saperne di più, consulta Configurare le pianificazioni dei cron job.
Seleziona il tuo fuso orario.
Fai clic su Continua per configurare l'esecuzione.
Seleziona HTTP dal menu Tipo di destinazione.
Nel campo URL, inserisci l'URL trigger salvato nella sezione precedente.
Seleziona POST come metodo HTTP se non è già selezionato.
Nella casella Corpo, inserisci una stringa JSON nel formato definito nel codice. Utilizzando l'esempio nella sezione precedente:
{ "pipeline_spec_uri": "<path-to-your-compiled-pipeline>", "parameter_values": { "greet_name": "<any-greet-string>" } }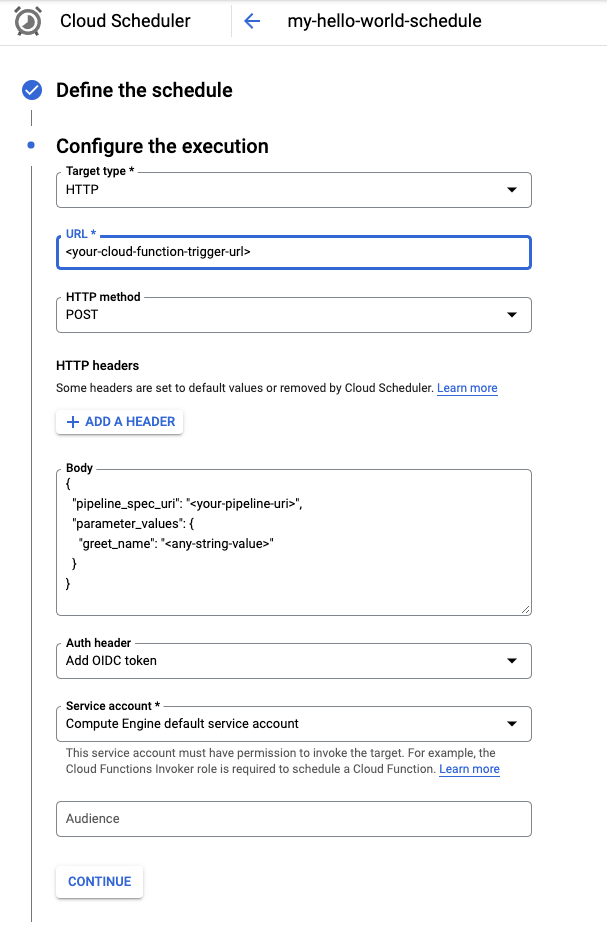
Nel menu a discesa dell'intestazione Auth, seleziona Aggiungi token OIDC.
Nel menu a discesa Account di servizio, seleziona un account di servizio che abbia l'autorizzazione per richiamare la Cloud Function. Per questo tutorial puoi utilizzare l'account di servizio predefinito di Compute Engine.
Lascia invariati gli altri campi per impostazione predefinita e fai clic su Crea.
Esegui manualmente il job (facoltativo)
Facoltativamente, puoi eseguire il job che hai appena creato per verificarne la funzionalità.
Apri la pagina della console di Cloud Scheduler.
Fai clic sul pulsante Esegui ora accanto al nome del job.
L'esecuzione del primo job creato in un progetto può richiedere alcuni minuti, a causa della configurazione richiesta.
Puoi visualizzare lo stato del job nella colonna Risultato.