You can make streaming requests to the Vertex AI Large Language Model (LLM) using the following:
- The Vertex AI REST API with server-sent events (SSE)
- The Vertex AI REST API
- The Vertex AI SDK for Python
- A client library
The streaming and non-streaming APIs use the same parameters, and there is no difference in pricing and quotas.
Vertex AI Studio
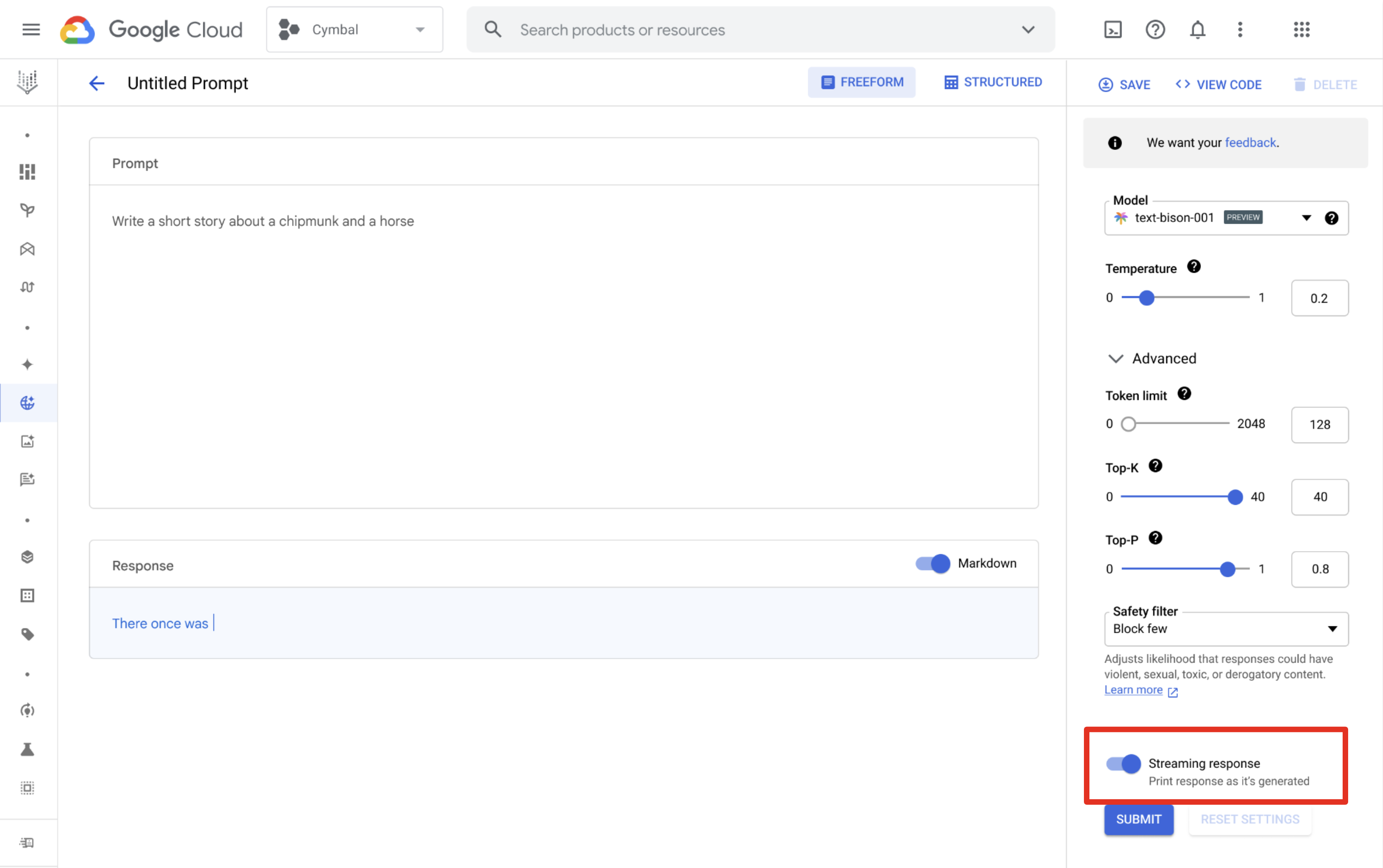
You can use Vertex AI Studio to design and run prompts and receive streamed responses. From the prompt design page, click the Streaming Response button to enable streaming.
Examples
You can call the Streaming API by using one of the following:
REST API with server-sent events (SSE)
The parameters are different across the model types used in the following examples:
Text
The current supported models are text-bison and text-unicorn. See available versions.
Request
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=text-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
'{
"inputs": [
{
"struct_val": {
"prompt": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Response
Responses are server-sent event messages.
data: {"outputs": [{"structVal": {"content": {"stringVal": [RESPONSE]},"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}},"citationMetadata": {"structVal": {"citations": {}}}}}]}
Chat
The current supported model is chat-bison. See available versions.
Request
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=chat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Response
Responses are server-sent event messages.
data: {"outputs": [{"structVal": {"candidates": {"listVal": [{"structVal": {"author": {"stringVal": [AUTHOR]},"content": {"stringVal": [RESPONSE]}}}]},"citationMetadata": {"listVal": [{"structVal": {"citations": {}}}]},"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}}}}]}
Code
The current supported model is code-bison. See available versions.
Request
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=code-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
$'{
"inputs": [
{
"struct_val": {
"prefix": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Response
Responses are server-sent event messages.
data: {"outputs": [{"structVal": {"citationMetadata": {"structVal": {"citations": {}}},"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}},"content": {"stringVal": [RESPONSE]}}}]}
Code chat
The current supported model is codechat-bison. See available versions.
Request
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=codechat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Response
Responses are server-sent event messages.
data: {"outputs": [{"structVal": {"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}},"citationMetadata": {"listVal": [{"structVal": {"citations": {}}}]},"candidates": {"listVal": [{"structVal": {"content": {"stringVal": [RESPONSE]},"author": {"stringVal": [AUTHOR]}}}]}}}]}
REST API
The parameters are different across the model types used in the following examples:
Text
The current supported models are text-bison and text-unicorn. See available versions.
Request
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=text-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
'{
"inputs": [
{
"struct_val": {
"prompt": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Response
{
"outputs": [
{
"structVal": {
"citationMetadata": {
"structVal": {
"citations": {}
}
},
"safetyAttributes": {
"structVal": {
"categories": {},
"scores": {},
"blocked": {
"boolVal": [
false
]
}
}
},
"content": {
"stringVal": [
RESPONSE
]
}
}
}
]
}
Chat
The current supported model is chat-bison. See available versions.
Request
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=chat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Response
{
"outputs": [
{
"structVal": {
"candidates": {
"listVal": [
{
"structVal": {
"content": {
"stringVal": [
RESPONSE
]
},
"author": {
"stringVal": [
AUTHOR
]
}
}
}
]
},
"citationMetadata": {
"listVal": [
{
"structVal": {
"citations": {}
}
}
]
},
"safetyAttributes": {
"listVal": [
{
"structVal": {
"categories": {},
"blocked": {
"boolVal": [
false
]
},
"scores": {}
}
}
]
}
}
}
]
}
Code
The current supported model is code-bison. See available versions.
Request
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=code-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
$'{
"inputs": [
{
"struct_val": {
"prefix": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Response
{
"outputs": [
{
"structVal": {
"safetyAttributes": {
"structVal": {
"categories": {},
"scores": {},
"blocked": {
"boolVal": [
false
]
}
}
},
"citationMetadata": {
"structVal": {
"citations": {}
}
},
"content": {
"stringVal": [
RESPONSE
]
}
}
}
]
}
Code chat
The current supported model is codechat-bison. See available versions.
Request
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=codechat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Response
{
"outputs": [
{
"structVal": {
"candidates": {
"listVal": [
{
"structVal": {
"content": {
"stringVal": [
RESPONSE
]
},
"author": {
"stringVal": [
AUTHOR
]
}
}
}
]
},
"citationMetadata": {
"listVal": [
{
"structVal": {
"citations": {}
}
}
]
},
"safetyAttributes": {
"listVal": [
{
"structVal": {
"categories": {},
"blocked": {
"boolVal": [
false
]
},
"scores": {}
}
}
]
}
}
}
]
}
Vertex AI SDK for Python
For information about installing the Vertex AI SDK for Python, see Install the Vertex AI SDK for Python.
Text
import vertexai
from vertexai.language_models import TextGenerationModel
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Text Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
text_generation_model = TextGenerationModel.from_pretrained("text-bison")
parameters = {
"temperature": temperature, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
"top_p": 0.8, # Tokens are selected from most probable to least until the sum of their probabilities equals the top_p value.
"top_k": 40, # A top_k of 1 means the selected token is the most probable among all tokens.
}
responses = text_generation_model.predict_streaming(prompt="Give me ten interview questions for the role of program manager.", **parameters)
for response in responses:
`print(response)`
Chat
import vertexai
from vertexai.language_models import ChatModel, InputOutputTextPair
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Chat Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
chat_model = ChatModel.from_pretrained("chat-bison")
parameters = {
"temperature": 0.8, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
"top_p": 0.95, # Tokens are selected from most probable to least until the sum of their probabilities equals the top_p value.
"top_k": 40, # A top_k of 1 means the selected token is the most probable among all tokens.
}
chat = chat_model.start_chat(
context="My name is Miles. You are an astronomer, knowledgeable about the solar system.",
examples=[
InputOutputTextPair(
input_text="How many moons does Mars have?",
output_text="The planet Mars has two moons, Phobos and Deimos.",
),
],
)
responses = chat.send_message_streaming(
message="How many planets are there in the solar system?", **parameters)
for response in responses:
`print(response)`
Code
import vertexai
from vertexai.language_models import CodeGenerationModel
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Chat Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
code_model = CodeGenerationModel.from_pretrained("code-bison")
parameters = {
"temperature": 0.8, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
}
responses = code_model.predict_streaming(
prefix="Write a function that checks if a year is a leap year.", **parameters)
for response in responses:
`print(response)`
Code chat
import vertexai
from vertexai.language_models import CodeChatModel
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Chat Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
codechat_model = CodeChatModel.from_pretrained("codechat-bison")
parameters = {
"temperature": 0.8, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 1024, # Token limit determines the maximum amount of text output.
}
codechat = codechat_model.start_chat()
responses = codechat.send_message_streaming(
message="Please help write a function to calculate the min of two numbers", **parameters)
for response in responses:
`print(response)`
Available client libraries
You can use one of the following client libraries to stream responses:
- Python
- Node.js
- Java
To view sample code requests and responses using the REST API, see Examples using the REST API.
To view sample code requests and responses using the Vertex AI SDK for Python, see Examples using Vertex AI SDK for Python.
Responsible AI
Responsible Artificial Intelligence (RAI) filters
scan the streaming output as the model generates it. If a violation is detected,
the filters block the offending output tokens, and return an output with a
blocked flag under safetyAttributes, which terminates the stream.
What's next
- Learn about designing text prompts. and text chat prompts.
- Learn how to test prompts in Vertex AI Studio.
- Learn about text embeddings.
- Try to tune a language foundation model.
- Learn about responsible AI best practices and Vertex AI's safety filters.