Questa guida per principianti introduce le tecnologie di base dell'AI generativa e spiega come si combinano per potenziare chatbot e applicazioni. L'IA generativa (nota anche come IA gen. o IA gen) è un campo del machine learning (ML) che sviluppa e utilizza modelli di ML per generare nuovi contenuti.
I modelli di IA generativa sono spesso chiamati modelli linguistici di grandi dimensioni (LLM) per le loro dimensioni elevate e la capacità di comprendere e generare un linguaggio naturale. Tuttavia, a seconda dei dati su cui vengono addestrati, questi modelli possono comprendere e generare contenuti da più modalità, tra cui testo, immagini, video e audio. I modelli che funzionano con più modalità di dati sono chiamati modelli multimodali.
Google fornisce la famiglia di modelli di AI generativa Gemini progettata per casi d'uso multimodali, in grado di elaborare informazioni da più modalità, tra cui immagini, video e testo.
Generazione di contenuti
Affinché i modelli di AI generativa generino contenuti utili nelle applicazioni reali, devono disporre delle seguenti funzionalità:
Scopri come eseguire nuove attività:
I modelli di IA generativa sono progettati per svolgere attività generali. Se vuoi che un modello esegua attività univoche per il tuo caso d'uso, devi essere in grado di personalizzarlo. su Vertex AI, puoi personalizzare il tuo modello tramite la regolazione del modello.
Accedere a informazioni esterne:
I modelli di IA generativa vengono addestrati su grandi quantità di dati. Tuttavia, per essere utili, questi modelli devono poter accedere a informazioni al di fuori dei dati di addestramento. Ad esempio, se vuoi creare un chatbot per l'assistenza clienti basato su un modello di AI generativa, il modello deve avere accesso alle informazioni sui prodotti e servizi che offri. In Vertex AI, utilizzi le funzionalità di grounding e chiamata di funzione per aiutare il modello ad accedere alle informazioni esterne.
Bloccare contenuti dannosi:
I modelli di IA generativa potrebbero generare output inaspettati, tra cui testo offensivo o insensibile. Per garantire la sicurezza e prevenire gli abusi, i modelli hanno bisogno di filtri di sicurezza per bloccare prompt e risposte che sono determinati come potenzialmente dannosi. Vertex AI dispone di funzionalità di sicurezza integrate che promuovono l'uso responsabile dei nostri servizi di IA generativa.
Il seguente diagramma mostra come queste diverse funzionalità interagiscono per generare i contenuti che preferisci:
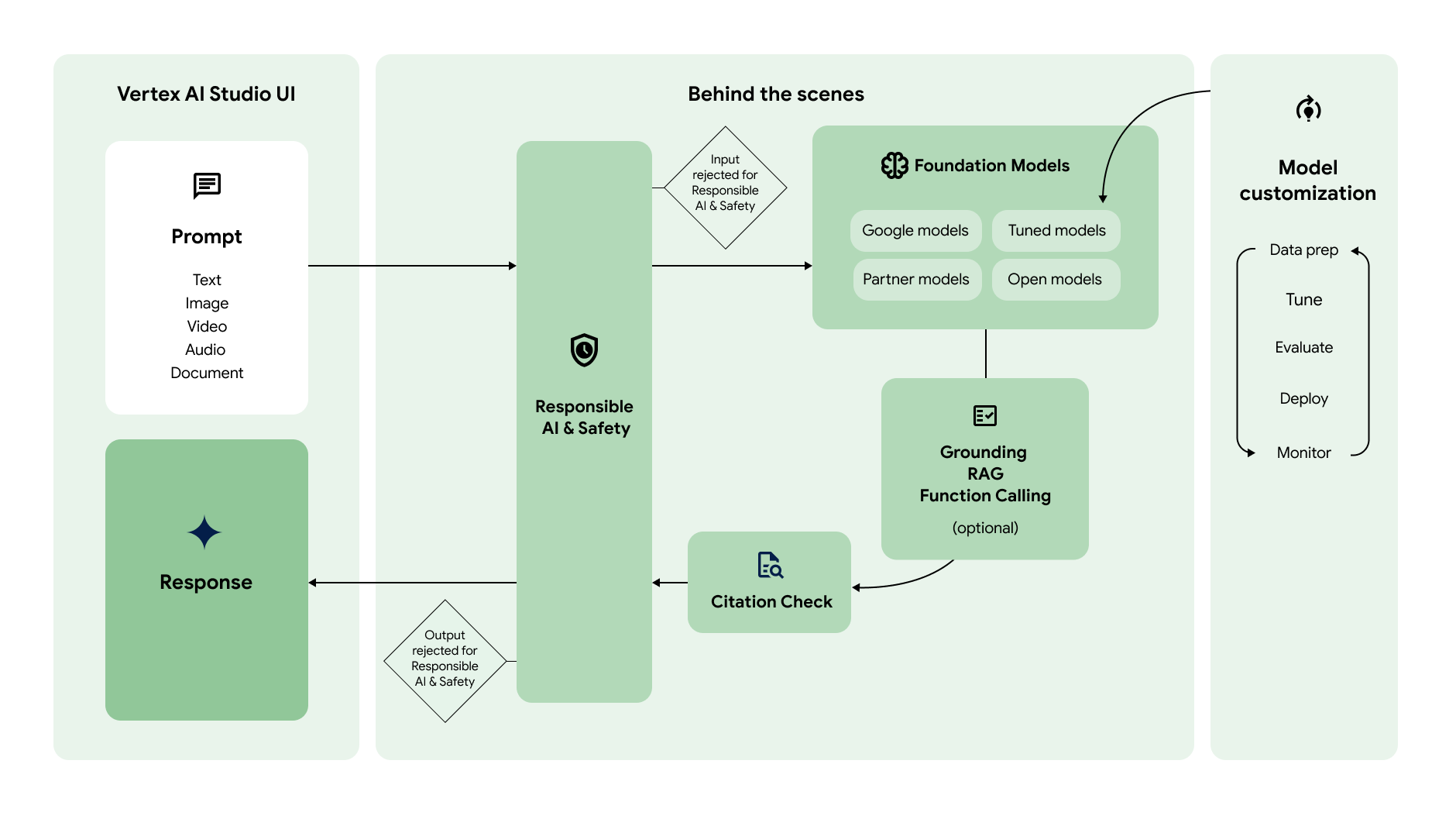
Prompt
|
|
In genere, il flusso di lavoro dell'AI generativa inizia con il prompt. Un prompt è una richiesta in linguaggio naturale inviata a un modello di AI generativa per ricevere una risposta. A seconda del modello, un prompt può contenere testo, immagini, video, audio, documenti e altre modalità o anche più modalità (multimodale). La creazione di un prompt per ottenere la risposta desiderata dal modello è una pratica chiamata progettazione dei prompt. Sebbene la progettazione dei prompt sia un processo di tentativi ed errori, esistono principi e strategie di progettazione dei prompt che puoi utilizzare per indurre il modello a comportarsi nel modo desiderato. Vertex AI Studio offre uno strumento di gestione dei prompt per aiutarti a gestirli. |
Modelli di base
|
|
I prompt vengono inviati a un modello di AI generativa per la generazione di risposte. Vertex AI offre una serie di modelli di base di IA generativa accessibili tramite un'API gestita, tra cui:
I modelli differiscono per dimensioni, modalità e costo. In Model Garden puoi esplorare i modelli di Google, nonché i modelli aperti e quelli dei partner di Google. |
Personalizzazione dei modelli
|
|
Puoi personalizzare il comportamento predefinito dei modelli di base di Google in modo che generino in modo coerente i risultati desiderati senza utilizzare prompt complessi. Questa procedura di personalizzazione è chiamata ottimizzazione del modello. La regolazione del modello ti aiuta a ridurre il costo e la latenza delle richieste consentendoti di semplificare i prompt. Vertex AI offre anche strumenti di valutazione dei modelli per aiutarti a valutare le prestazioni del modello ottimizzato. Una volta che il modello ottimizzato è pronto per la produzione, puoi eseguirne il deployment in un endpoint e monitorarne le prestazioni come nei flussi di lavoro MLOps standard. |
Accedere a informazioni esterne
|
|
Vertex AI offre diversi modi per dare al modello accesso ad API esterne e informazioni in tempo reale.
|
Verifica delle citazioni
|
|
Dopo aver generato la risposta, Vertex AI controlla se è necessario includere citazioni nella risposta. Se una parte significativa del testo nella risposta proviene da una determinata origine, questa viene aggiunta ai metadati della citazione nella risposta. |
AI responsabile e sicurezza
|
|
L'ultimo livello di controllo a cui vengono sottoposti il prompt e la risposta prima di essere restituiti sono i filtri di sicurezza. Vertex AI controlla sia il prompt sia la risposta per verificare quanto il prompt o la risposta appartengano a una categoria di sicurezza. Se la soglia viene superata per una o più categorie, la risposta viene bloccata e Vertex AI restituisce una risposta di riserva. |
Risposta
|
|
Se il prompt e la risposta superano i controlli del filtro di sicurezza, viene restituita la risposta. In genere, la risposta viene restituita tutta in una volta. Tuttavia, con Vertex AI puoi anche ricevere le risposte progressivamente man mano che vengono generate attivando lo streaming. |
Inizia
Prova una di queste guide rapide per iniziare a utilizzare l'IA generativa su Vertex AI.
-
 Generare testo utilizzando l'API Gemini in Vertex AI
Generare testo utilizzando l'API Gemini in Vertex AIUtilizza l'SDK per inviare richieste all'API Gemini in Vertex AI.
-
 Inviare prompt a Gemini utilizzando la Galleria di prompt di Vertex AI Studio
Inviare prompt a Gemini utilizzando la Galleria di prompt di Vertex AI StudioTesta i prompt senza alcuna configurazione richiesta.
-
 Genera un'immagine e verifica la relativa filigrana utilizzando Imagen
Genera un'immagine e verifica la relativa filigrana utilizzando ImagenCrea un'immagine con filigrana utilizzando Imagen su Vertex AI.