TPU v4
このドキュメントでは、Cloud TPU v4 のアーキテクチャとサポートされている構成について説明します。
システム アーキテクチャ
各 TPU v4 チップには、2 つの TensorCore が含まれています。各 TensorCore には、4 つのマトリックス乗算ユニット(MXU)、1 つのベクトル ユニット、1 つのスカラー ユニットがあります。次の表に、v4 TPU Pod の主な仕様を示します。
| 主な仕様 | v4 Pod 値 |
|---|---|
| チップあたりのピーク コンピューティング | 275 TFLOPS(bf16 または int8) |
| HBM2 の容量と帯域幅 | 32 GiB、1,200 GBps |
| 最小 / 平均 / 最大電力の測定値 | 90 / 170 / 192 W |
| TPU Pod のサイズ | 4,096 チップ |
| 相互接続トポロジ | 3D メッシュ |
| Pod あたりのピーク コンピューティング | 1.1 エクサフロップ(bf16 または int8) |
| Pod あたりの all-reduce 帯域幅 | 1.1 PB/秒 |
| Pod あたりの二分割帯域幅 | 24 TB/秒 |
次の図は、TPU v4 チップを示しています。
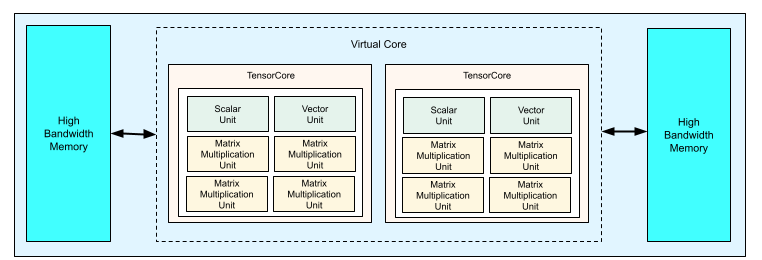
TPU v4 のアーキテクチャとパフォーマンス特性の詳細については、TPU v4: エンベディングのハードウェア サポートを備え、光学的に再構成可能な ML 用スーパーコンピュータをご覧ください。
3D メッシュと 3 次元トーラス
v4 TPU は 3 次元の最近傍チップに直接接続され、ネットワーク接続の 3D メッシュを形成します。接続は、トポロジ AxBxC が 2A=B=C または 2A=2B=C(各次元は 4 の倍数)のスライス上で 3 次元トーラスとして構成されます。たとえば、4x4x8、4x8x8、12x12x24 です。一般に、3 次元トーラス構成のパフォーマンスは 3D メッシュ構成よりも優れています。詳細については、ツイスト トリ トポロジをご覧ください。
TPU v3 に対する TPU v4 のパフォーマンス上の利点
このセクションでは、TPU v4 でメモリを効率的に使用してサンプル トレーニング スクリプトを実行する方法と、TPU v3 と比較した TPU v4 のパフォーマンスの向上について説明します。
メモリシステム
不均一メモリアクセス(NUMA)は、複数の CPU を搭載したマシンのコンピュータ メモリ アーキテクチャです。各 CPU は、高速メモリのブロックに直接アクセスできます。CPU とそのメモリは NUMA ノードと呼ばれます。NUMA ノードは、互いに直接隣接している別の NUMA ノードに接続されます。ある NUMA ノードの CPU が別の NUMA ノードのメモリにアクセスすることは可能ですが、こうしたアクセスは NUMA ノード内のメモリにアクセスするよりも時間がかかります。
マルチ CPU マシン上で稼働するソフトウェアは、CPU が必要とするデータをその NUMA ノード内に配置し、メモリのスループットを向上させます。NUMA の詳細については、Wikipedia の 不均一メモリアクセスをご覧ください。
トレーニング スクリプトを NUMA ノード 0 にバインドすることで、NUMA-locality の利点を活用できます。
NUMA ノード バインディングを有効にするには:
TPU v4 を作成します。
numactl コマンドライン ツールをインストールします。numactl を使用すると、特定の NUMA スケジューリングまたはメモリ配置ポリシーでプロセスを実行できます。
$ sudo apt-get update $ sudo apt-get install numactl
スクリプト コードを NUMA ノード 0 にバインドします。your-training-script は、トレーニング スクリプトのパスに置き換えます。
$ numactl --cpunodebind=0 python3 your-training-script
次の場合は、NUMA ノード バインディングを有効にします。
- フレームワークに関係なく、ワークロードが CPU ワークロードに大きく依存している場合(例: 画像分類、レコメンデーション ワークロード)。
- -pod 接尾辞のない TPU ランタイム バージョンを使用している場合(例:
tpu-vm-tf-2.10.0-v4)。
その他のメモリシステムの違い:
- v4 TPU チップには、チップ全体で統合された 32 GiB HBM メモリ空間があり、2 つのオンチップ TensorCore 間の調整を改善できます。
- 最新のメモリ標準と速度を使用した HBM パフォーマンスの向上。
- 512B の粒度での高パフォーマンス ストライプ化を組み込みでサポートすることで、DMA のパフォーマンス プロファイルを向上。
TensorCore
- 2 倍の MXU とより高いクロックレートで最大 275 TFLOPS を実現。
- 2 倍の転移および置換の帯域幅。
- Common Memory(Cmem)のロードストア メモリ アクセス モデル。
- MXU 重み付け読み込みの高速化と 8 ビットモードのサポートにより、バッチサイズを小さくし、推論のレイテンシを改善。
チップ間相互接続
チップあたり 6 個の相互接続リンクにより、ネットワーク直径がより小さいネットワーク トポロジを実現。
その他
- ホスト用の x16 PCIE gen3 インターフェース(直接接続)。
- セキュリティ モデルの改善。
- エネルギー効率の向上。
構成
TPU v4 Pod は、再構成可能な高速リンクで相互接続された 4,096 のチップで構成されます。TPU v4 の柔軟なネットワーキングでは、さまざまな方法で同じサイズのスライスにチップを接続できます。TPU スライスを作成する場合は、TPU のバージョンと必要な TPU リソースの数を指定します。TPU v4 スライスを作成する際は、AcceleratorType と AccleratorConfig のいずれかの方法でタイプとサイズを指定できます。
AcceleratorType の使用
トポロジを指定しない場合は、AcceleratorType を使用します。AcceleratorType を使用して v4 TPU を構成するには、TPU スライスの作成時に --accelerator-type フラグを使用します。--accelerator-type を、TPU のバージョンと使用する TensorCore の数を含む文字列に設定します。たとえば、32 個の TensorCore を使用して v4 スライスを作成するには、--accelerator-type=v4-32 を使用します。
gcloud compute tpus tpu-vm create コマンドを使用して、--accelerator-type フラグを指定して 512 個の TensorCore を持つ v4 TPU スライスを作成します。
$ gcloud compute tpus tpu-vm create your-tpu-name \ --zone=us-central2-b \ --accelerator-type=v4-512 \ --version=tpu-ubuntu2204-base
TPU バージョン(v4)の後の数字は、TensorCore の数を指定しています。v4 TPU には 2 つの TensorCore があるため、TPU チップの数は 512÷2 = 256 になります。
TPU の管理の詳細については、TPU の管理をご覧ください。Cloud TPU のシステム アーキテクチャの詳細については、システム アーキテクチャをご覧ください。
AcceleratorConfig の使用
TPU スライスの物理トポロジをカスタマイズする場合は、AcceleratorConfig を使用します。これは通常、スライス数が 256 チップ以上のパフォーマンス チューニングに必要です。
AcceleratorConfig を使用して v4 TPU を構成するには、--type フラグと --topology フラグを使用します。--type を、使用する TPU バージョンに設定し、--topology をスライスの TPU チップの物理配置に設定します。
3 タプル AxBxC を使用して TPU トポロジを指定します。ここで、A<=B<=C で、A、B、C はすべて 4 以下または 4 の整数倍です。値 A、B、C は、3 つのディメンションのチップ数です。たとえば、16 チップの v4 スライスを作成するには、--type=v4 と --topology=2x2x4 を設定します。
gcloud compute tpus tpu-vm create コマンドを使用して、128 個の TPU チップを 4x4x8 アレイに配置した v4 TPU スライスを作成します。
$ gcloud compute tpus tpu-vm create your-tpu-name \ --zone=us-central2-b \ --type=v4 \ --topology=4x4x8 \ --version=tpu-ubuntu2204-base
2A=B=C または 2A=2B=C のトポロジでも、すべての通信用に最適化されたトポロジ バリアントがあります(例: 4×4×8、8×8x16、12×12×24)。これらをツイスト トリ トポロジといいます。
次の図は、一般的な TPU v4 トポロジを示しています。
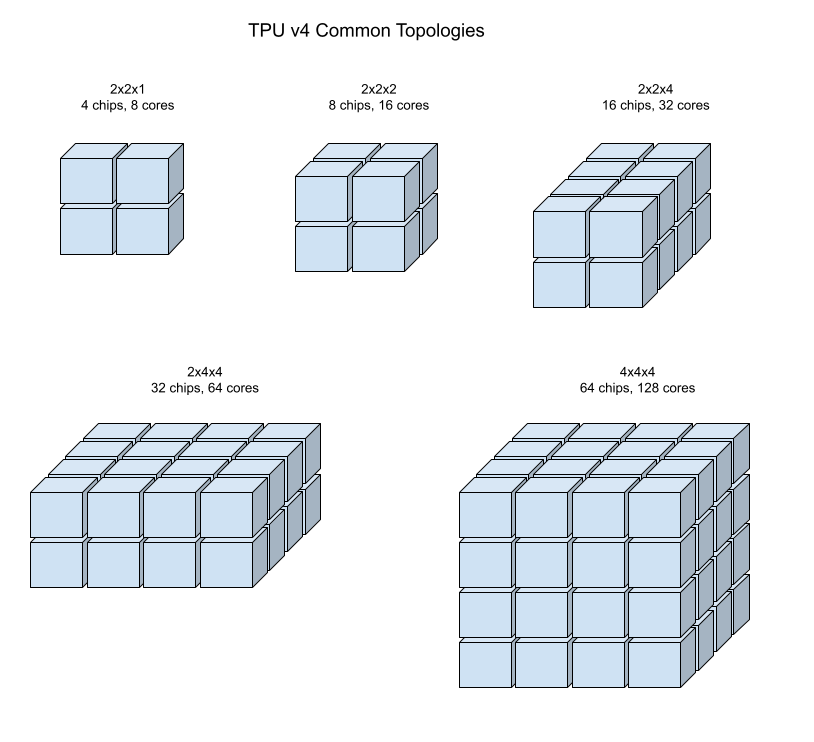
より大きなスライスを、1 つまたは複数の 4x4x4 の「キューブ」チップから構築できます。
TPU の管理の詳細については、TPU の管理をご覧ください。Cloud TPU のシステム アーキテクチャの詳細については、システム アーキテクチャをご覧ください。
ツイスト トリ トポロジ
一部の v4 3 次元トーラス スライスの形状には、ツイスト トーラス トポロジとして知られるオプションがあります。たとえば、2 つの v4 キューブは 4x4x8 スライスまたは 4x4x8_ツイストとして配置できます。ツイスト トポロジでは、非常に大きな二分帯域幅が提供されます。たとえば、4x4x8_twisted トポロジのスライスは、ツイストされていない 4x4x8 スライスと比較して、理論上の二分帯域幅が 70% 増加します。二分帯域幅の増加は、グローバル通信パターンを使用するワークロードに役立ちます。ツイスト トポロジでは、ほとんどのモデルでパフォーマンスが向上しますが、最もメリットがあるのは大規模な TPU エンベディング ワークロードです。
データ並列処理を唯一の並列処理戦略として使用するワークロードの場合、ツイスト トポロジのほうがパフォーマンスがわずかに向上する可能性があります。LLM の場合、ツイスト トポロジを使用したパフォーマンスは、並列処理の種類(DP、MP など)によって異なります。モデルに最適なパフォーマンスが得られるかどうか判断するために、ツイスト トポロジの有無にかかわらず LLM をトレーニングすることをおすすめします。FSDP MaxText モデルの一部の実験では、ツイスト トポロジを使用して MFU が 1~2 回改善されました。
ツイスト トポロジの主なメリットは、非対称トーラス トポロジ(4×4×8 など)を、密接に関連する対称トポロジに変換することです。対称トポロジには次のような多くの利点があります。
- ロード バランシングの改善
- 二分帯域幅の向上
- パケットルートの短縮
これらのメリットは、最終的に多くのグローバル通信パターンのパフォーマンス向上につながります。
TPU ソフトウェアは、各ディメンションのサイズが最小のディメンションのサイズ(例: 4x4x8、4×8×8、12x12x24)に等しいか、2 倍であるスライスのツイストトリをサポートします。
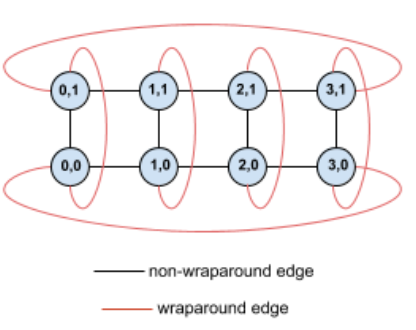
たとえば、スライス内に(X、Y)座標でラベル付けされた TPU がある次の 4×2 トーラス トポロジについて考えてみます。
このトポロジグラフのエッジは、わかりやすくするために無向エッジとして示されています。実際には、各エッジは TPU 間の双方向接続です。図に示すように、このグリッドの一方の側と反対側の間にあるエッジをラップアラウンド エッジと呼びます。
このトポロジをツイストすると、完全に対称な 4×2 ツイスト トーラス トポロジになります。
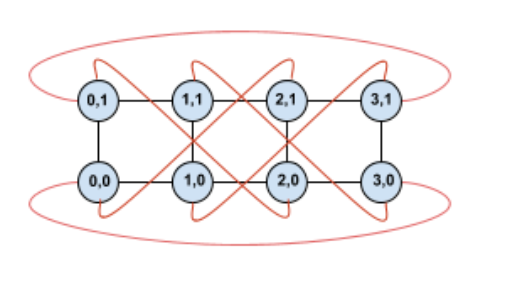
この図と前の図の違いは、Y の折り返しエッジのみです。同じ X 座標の別の TPU に接続するのではなく、座標 X+2 mod 4 の TPU に接続するようシフトされています。
同じ考え方を、さまざまなディメンション サイズと数のディメンションに一般化できます。結果として得られるネットワークは、各ディメンションが最小ディメンションのサイズと等しいか、2 倍である限り、対称になります。
Cloud TPU の作成時にツイストトリ構成を指定する方法の詳細については、AcceleratorConfig の使用をご覧ください。
次の表は、サポートされているツイスト トポロジと、ツイストされていないトポロジを使用した場合の二分帯域幅の理論的な増加を示しています。
| チップトポロジ | 二分帯域幅の理論上の増加 とツイストされていないトポロジ |
|---|---|
| 4×4×8_twisted | ~70% |
| 8x8x16_twisted | |
| 12×12×24_twisted | |
| 4×8×8_twisted | ~40% |
| 8×16×16_twisted |
TPU v4 トポロジ バリアント
同じ数のチップを含む一部のトポロジは、さまざまな方法で配置できます。たとえば、512 チップ(1,024 Tensor コア)の TPU スライスは、4x4x32、4x8x16、8x8x8 のトポロジを使用して構成できます。2,048 チップ(4,096 TensorCores)の TPU スライスは、さらに多くの 4x4x128、4x8x64、4x16x32、8x16x16 のトポロジ オプションを提供します。
特定のチップ数に関連付けられるデフォルトのトポロジは、キューブに最も近いものです。この形状は、データの並列 ML トレーニングに最適です。他のトポロジ(モデルとデータの並列処理、シミュレーションの空間パーティショニングなど)は、複数の種類の並列処理のワークロードで役立ちます。これらのワークロードは、トポロジが使用された並列処理に一致する場合に最も効果的です。たとえば、X 次元に 4 方向モデル並列処理、Y ディメンションと Z ディメンションに 256 方向データ並列処理を配置すると、4x16x16 トポロジと一致します。
並列処理のディメンションが複数あるモデルは、並列処理ディメンションが TPU トポロジ ディメンションにマッピングされていると、最も効果的です。これらは通常、データとモデル並列大規模言語モデル(LLM)です。たとえば、トポロジ 8x16x16 の TPU v4 スライスで、TPU トポロジ ディメンションは 8、16、16 です。8 方向または 16 方向のモデル並列処理(物理 TPU トポロジ ディメンションの 1 つにマッピング)を使用したほうがパフォーマンスが向上します。4 方向モデル並列処理は、TPU トポロジのディメンションと整合していないため、このトポロジには最適ではありませんが、同じ数のチップで 4x16x32 のトポロジを使用すると最適です。
TPU v4 構成は、64 チップより小さいトポロジ(小規模トポロジ)と 64 チップを超えるトポロジ(大規模トポロジ)の 2 つのグループで構成されています。
小規模な v4 トポロジ
Cloud TPU は、次の 64 チップよりも小さい TPU v4 スライス(4x4x4 キューブ)をサポートしています。これらの小規模な v4 トポロジは、TensorCore ベースの名前(v4-32 など)またはトポロジ(2x2x4 など)を使用して作成できます。
| 名前(TensorCore のカウントに基づく) | チップ数 | トポロジ |
| v4-8 | 4 | 2x2x1 |
| v4-16 | 8 | 2x2x2 |
| v4-32 | 16 | 2x2x4 |
| v4-64 | 32 | 2x4x4 |
大規模な v4 トポロジ
TPU v4 スライスは 64 チップ単位で利用でき、3 つのディメンションすべてで 4 の倍数の形状になっています。ディメンションは昇順にする必要があります。次の表に、いくつかの例を示します。これらのトポロジの一部は、--type フラグと --topology フラグを使用してのみ作成できるカスタム トポロジです。これは、チップを配置する方法は複数あるためです。
| 名前(TensorCore のカウントに基づく) | チップ数 | トポロジ |
| v4-128 | 64 | 4x4x4 |
| v4-256 | 128 | 4x4x8 |
| v4-512 | 256 | 4x8x8 |
カスタム トポロジ: --type フラグと --topology フラグを使用する必要があります。 |
256 | 4x4x16 |
| v4-1024 | 512 | 8x8x8 |
| v4-1536 | 768 | 8x8x12 |
| v4-2048 | 1024 | 8x8x16 |
カスタム トポロジ: --type フラグと --topology フラグを使用する必要があります。 |
1024 | 4x16x16 |
| v4-4096 | 2048 | 8x16x16 |
| … | … | … |