Monitorizar máquinas virtuales de TPUs de Cloud
En esta guía se explica cómo usar Google Cloud Monitoring para monitorizar tus VMs de TPU de Cloud. Google Cloud Monitoring recoge automáticamente métricas y registros de tu TPU de Cloud y de su host de Compute Engine. Estos datos se pueden usar para monitorizar el estado de tu Cloud TPU y Compute Engine.
Las métricas te permiten monitorizar una cantidad numérica a lo largo del tiempo. Por ejemplo, el uso de la CPU, el uso de la red o la duración de inactividad de Tensor Core. Registra eventos de captura en un momento específico. Las entradas de registro las escribe tu propio código, Google Cloud los servicios, las aplicaciones de terceros y la Google Cloud infraestructura. También puede generar métricas a partir de los datos presentes en una entrada de registro creando una métrica basada en registros. También puedes definir políticas de alertas basadas en valores de métricas o entradas de registro.
En esta guía se habla de la Google Cloud monitorización y se explica cómo hacer lo siguiente:
- Ver métricas de TPU de Cloud
- Configurar políticas de alertas de métricas de TPU de Cloud
- Consultar registros de TPU de Cloud
- Crea métricas basadas en registros para configurar alertas y visualizar paneles de control
También puedes usar el Planificador de capacidad (vista previa) para monitorizar las TPUs. Con Planificador de capacidad, puedes ver el uso de las TPU y los datos de previsión de tu proyecto, carpeta u organización. Estos datos se actualizan cada 24 horas y puedes usarlos para analizar las tendencias de uso y planificar las necesidades de capacidad futuras. Para obtener más información, consulta la descripción general de Planificador de capacidad.
En este documento se presupone que tienes conocimientos básicos sobre Google Cloud Monitorización. Debes haber creado una máquina virtual de Compute Engine y recursos de Cloud TPU para poder empezar a generar y trabajar con Google Cloud Monitoring. Consulta la guía de inicio rápido de Cloud TPU para obtener más información.
Métricas
Compute Engine genera automáticamente las métricas deGoogle Cloud máquinas virtuales y el tiempo de ejecución de TPU de Cloud. Las siguientes métricas se generan en las VMs de TPU de Cloud:
memory/usagenetwork/received_bytes_countnetwork/sent_bytes_countcpu/utilizationtpu/tensorcore/idle_durationaccelerator/tensorcore_utilizationaccelerator/memory_bandwidth_utilizationaccelerator/duty_cycleaccelerator/memory_totalaccelerator/memory_used
Puede tardar hasta 180 segundos en aparecer en el Explorador de métricas un valor de métrica desde que se genera.
Para ver una lista completa de las métricas generadas por TPU de Cloud, consulta Google Cloud Métricas de TPU de Cloud.
Uso de memoria
La métrica memory/usage se genera para el recurso TPU Worker y monitoriza la memoria que usa la VM de TPU en bytes. Esta métrica se muestrea cada 60 segundos.
Número de bytes recibidos por la red
La métrica network/received_bytes_count se genera para el recurso TPU Worker
y registra el número de bytes acumulados de datos que la VM de TPU ha recibido
en la red en un momento dado.
Número de bytes enviados por la red
La métrica network/sent_bytes_count se genera para el recurso TPU Worker y registra el número de bytes acumulados que la VM de TPU ha enviado a través de la red en un momento dado.
Uso de CPU
La métrica cpu/utilization se genera para el recurso TPU Worker y registra el uso actual de CPU del trabajador de TPU, representado como un porcentaje, con una muestra por minuto. Los valores suelen estar comprendidos entre 0,0 y 100,0, pero pueden superar el 100,0.
Duración de inactividad de Tensor Core
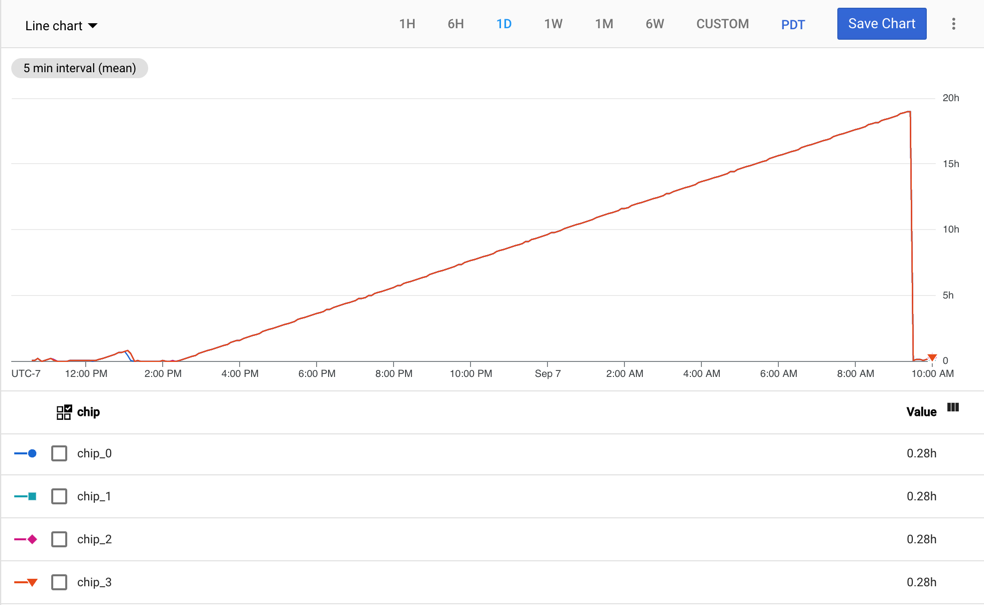
La métrica tpu/tensorcore/idle_duration se genera para el recurso TPU Worker y registra el número de segundos que el Tensor Core de cada chip de TPU ha estado inactivo. Esta métrica está disponible para cada chip de todas las TPUs en uso. Si se está usando un Tensor Core, el valor de la duración de inactividad se restablece a cero. Cuando Tensor Core deja de usarse, el valor de la duración de inactividad empieza a aumentar.
En el siguiente gráfico se muestra la métrica tpu/tensorcore/idle_duration de una máquina virtual de TPU v2-8, que tiene un trabajador. Cada trabajador tiene cuatro fichas. En este ejemplo, los cuatro chips tienen los mismos valores de tpu/tensorcore/idle_duration, por lo que los gráficos se superponen.
Uso de Tensor Core
La métrica accelerator/tensorcore_utilization se genera para el recurso GCE TPU
Worker y registra el porcentaje actual de Tensor Core que se utiliza. Esta métrica se calcula dividiendo el número de operaciones de Tensor Core
realizadas durante un periodo de muestra entre el número máximo de operaciones
que se pueden realizar durante el mismo periodo de muestra. Cuanto mayor sea el valor, mejor será la utilización. La métrica de uso de Tensor Core es compatible con las generaciones de TPU v4 y posteriores.
Uso del ancho de banda de la memoria
La métrica accelerator/memory_bandwidth_utilization se genera para el recurso GCE TPU Worker y registra el porcentaje actual del ancho de banda de la memoria del acelerador que se está usando. Esta métrica se calcula dividiendo el ancho de banda de memoria utilizado durante un periodo de muestreo entre el ancho de banda máximo admitido durante el mismo periodo. Cuanto mayor sea el valor, mejor será la utilización. La métrica Uso del ancho de banda de la memoria es compatible con la versión 4 y las generaciones más recientes de TPU.
Ciclo de actividad del acelerador
La métrica accelerator/duty_cycle se genera para el recurso GCE TPU Worker
y registra el porcentaje de tiempo del periodo de muestra durante el cual
el Tensor Core del acelerador ha estado procesando activamente. Los valores están comprendidos entre 0 y 100. Cuanto mayor sea el valor, mejor será la utilización de Tensor Core. Esta métrica se registra cuando se ejecuta una carga de trabajo de aprendizaje automático en la VM de TPU. La métrica Ciclo de trabajo del acelerador es compatible con JAX
0.4.14 y versiones posteriores, PyTorch
2.1 y versiones posteriores, y
TensorFlow
2.14.0 y versiones posteriores.
Memoria total del acelerador
La métrica accelerator/memory_total se genera para el recurso GCE TPU Worker
y registra la memoria total del acelerador asignada en bytes.
Esta métrica se registra cuando se ejecuta una carga de trabajo de aprendizaje automático en la VM de TPU. La métrica Total de memoria del acelerador se admite en JAX
0.4.14 y versiones posteriores, PyTorch
2.1 y versiones posteriores, y
TensorFlow
2.14.0 y versiones posteriores.
Memoria del acelerador utilizada
La métrica accelerator/memory_used se genera para el recurso GCE TPU Worker
y registra la memoria total del acelerador utilizada en bytes. Esta métrica se registra cuando se ejecuta una carga de trabajo de aprendizaje automático en la VM de TPU. La métrica Memoria usada del acelerador es compatible con JAX 0.4.14 y versiones posteriores, PyTorch 2.1 y versiones posteriores, y
TensorFlow 2.14.0 y versiones posteriores.
Ver métricas
Puedes ver las métricas con el explorador de métricas en la consola de Google Cloud .
En el Explorador de métricas, haga clic en Seleccionar una métrica y busque TPU Worker
o GCE TPU Worker en función de la métrica que le interese.
Seleccione un recurso para ver todas las métricas disponibles de ese recurso.
Si la opción Activo está habilitada, solo se mostrarán las métricas con datos de series temporales de las últimas 25 horas. Inhabilita Activo para ver todas las métricas.
Crear alertas
Puedes crear políticas de alertas que indiquen a Cloud Monitoring que envíe una alerta cuando se cumpla una condición.
En los pasos de esta sección se muestra un ejemplo de cómo añadir una política de alertas para la métrica Duración de inactividad de Tensor Core. Cuando esta métrica supera las 24 horas, Cloud Monitoring envía un correo a la dirección de correo registrada.
- Ve a la consola Monitoring.
- En el panel de navegación, haga clic en Alertas.
- Haz clic en Editar canales de notificaciones.
- En Correo electrónico, haz clic en Añadir nuevo. Escribe una dirección de correo y un nombre visible, y haz clic en Guardar.
- En la página Alerting (Alertas), haz clic en Create policy (Crear política).
- Haz clic en Seleccionar una métrica y, a continuación, en Duración de inactividad de Tensor Core y en Aplicar.
- Haz clic en Siguiente y, a continuación, en Umbral.
- En Activador de alerta, selecciona Cualquier serie temporal infringe.
- En Posición del umbral, selecciona Por encima del umbral.
- En Valor de umbral, escribe
86400000. - Haz clic en Siguiente.
- En Canales de notificación, selecciona el canal de notificación por correo y haz clic en Aceptar.
- Escribe un nombre para la política de alertas.
- Haz clic en Siguiente y, a continuación, en Crear política.
Cuando la duración de inactividad de TensorCore supera las 24 horas, se envía un correo a la dirección que hayas especificado.
Almacenamiento de registros
Los servicios, los servicios de terceros, los frameworks de aprendizaje automático o tu código escriben las entradas de registro. Google Cloud Puedes ver los registros con el Explorador de registros o la API Logs. Para obtener más información sobre el Google Cloud registro, consulta Google Cloud Registros.
Los registros de trabajadores de TPU contienen información sobre un trabajador de TPU de Cloud específico en una zona concreta, como la cantidad de memoria disponible en el trabajador de TPU de Cloud (system_available_memory_GiB).
Los registros de recursos auditados contienen información sobre cuándo se llamó a una API de TPU de Cloud específica y quién hizo la llamada. Por ejemplo, puedes encontrar información sobre las llamadas a las APIs CreateNode, UpdateNode y DeleteNode.
Los frameworks de aprendizaje automático pueden generar registros en la salida estándar y en el error estándar. Estas registros se controlan mediante variables de entorno y los lee tu script de entrenamiento.
Tu código puede escribir registros en Google Cloud Logging. Para obtener más información, consulta los artículos sobre cómo escribir registros estándar y escribir registros estructurados.
Registro de puerto serie
Cloud TPU usa el registro del puerto serie para solucionar problemas, monitorizar y depurar. El valor predeterminado es habilitar el registro de puertos serie. Si el registro del puerto serie no está habilitado, el proceso de creación de la VM de TPU falla y genera el siguiente mensaje de error.
"Cloud TPU received a bad request. Constraint
`constraints/compute.disableSerialPortLogging` violated. Create TPUs with
serial port logging enabled or remove the Organization Policy Constraint."
Este mensaje indica que se ha infringido la restricción constraints/compute.disableSerialPortLogging.
Para evitar este error, debe asegurarse de que se permite el registro del puerto serie en sus proyectos de TPU. Lo más recomendable es anular la política de la organización a nivel de proyecto.
Para obtener más información sobre cómo habilitar el registro de salida del puerto serie, consulta Habilitar e inhabilitar el registro de salida del puerto serie.
Consultar registros de Google Cloud
Cuando ves los registros en la Google Cloud consola, la página realiza una consulta predeterminada.
Para ver la consulta, selecciona el interruptor Show query. Puedes modificar la consulta predeterminada o crear una nueva. Para obtener más información, consulta el artículo Crear consultas en el Explorador de registros.
Registros de recursos auditados
Para ver los registros de recursos auditados, sigue estos pasos:
- Ve al Google Cloud Explorador de registros.
- Haga clic en el desplegable Todos los recursos.
- Haga clic en Recurso auditado y, a continuación, en TPU de Cloud.
- Elige la API de Cloud TPU que te interese.
- Haz clic en Aplicar. Los registros se muestran en los resultados de la consulta.
Haz clic en cualquier entrada de registro para ampliarla. Cada entrada de registro tiene varios campos, entre los que se incluyen los siguientes:
- logName: el nombre del registro.
- protoPayload -> @type: el tipo de registro.
- protoPayload -> resourceName: el nombre de tu TPU de Cloud
- protoPayload -> methodName: el nombre del método llamado (solo en los registros de auditoría)
- protoPayload -> request -> @type: el tipo de solicitud
- protoPayload -> request -> node: detalles sobre el nodo de TPU de Cloud
- protoPayload -> request -> node_id: el nombre de la TPU
- severity: la gravedad del registro.
Registros de trabajador de TPU
Para ver los registros de los trabajadores de TPU, siga estos pasos:
- Ve al Google Cloud Explorador de registros.
- Haga clic en el desplegable Todos los recursos.
- Haz clic en Trabajador de TPU.
- Selecciona una zona.
- Selecciona la TPU de Cloud que te interese.
- Haz clic en Aplicar. Los registros se muestran en los resultados de la consulta.
Haz clic en cualquier entrada de registro para ampliarla. Cada entrada de registro tiene un campo llamado jsonPayload. Amplía jsonPayload para ver varios campos, entre los que se incluyen los siguientes:
- accelerator_type el tipo de acelerador
- consumer_project: el proyecto en el que reside la TPU de Cloud
- evententry_timestamp la hora en la que se generó el registro.
- system_available_memory_GiB la memoria disponible en el trabajador de TPU de Cloud (de 0 a 350 GiB)
Crear métricas basadas en registros
En esta sección se describe cómo crear métricas basadas en registros que se usan para configurar paneles de control y alertas. Para obtener información sobre cómo crear métricas basadas en registros mediante programación, consulta el artículo Crear métricas basadas en registros mediante programación con la API REST de Cloud Logging.
En el siguiente ejemplo se usa el subcampo system_available_memory_GiB para mostrar cómo crear una métrica basada en registros que monitorice la memoria disponible de los trabajadores de Cloud TPU.
- Ve al Google Cloud Explorador de registros.
En el cuadro de consulta, introduce la siguiente consulta para extraer todas las entradas de registro que tengan definido el campo system_available_memory_GiB para el trabajador principal de la TPU de Cloud:
resource.type=tpu_worker resource.labels.project_id=your-project resource.labels.zone=your-tpu-zone resource.labels.node_id=your-tpu-name resource.labels.worker_id=0 logName=projects/your-project/logs/tpu.googleapis.com%2Fruntime_monitor jsonPayload.system_available_memory_GiB:*
Haz clic en Crear métrica para que se muestre el editor de métricas.
En Tipo de métrica, elige Distribución.
Escriba un nombre, una descripción opcional y una unidad de medida para la métrica. En este ejemplo, escriba "matrix_unit_utilization_percent" y "MXU utilization" en los campos Nombre y Descripción, respectivamente. El filtro se rellena automáticamente con la secuencia de comandos que has introducido en el Explorador de registros.
Haz clic en Crear métrica.
Haga clic en Ver en Explorador de métricas para ver la métrica nueva. Las métricas pueden tardar unos minutos en mostrarse.
Crear métricas basadas en registros con la API REST de Cloud Logging
También puedes crear métricas basadas en registros a través de la API de Cloud Logging. Para obtener más información, consulta Crear una métrica de distribución.
Crear paneles de control y alertas con métricas basadas en registros
Los paneles de control son útiles para visualizar métricas (con un retraso de unos 2 minutos), mientras que las alertas sirven para enviar notificaciones cuando se producen errores. Para obtener más información, consulta:
- Paneles de control de monitorización y registro
- Gestionar paneles de control personalizados
- Crear políticas de alertas basadas en métricas
Crear paneles de control
Para crear un panel de control en Cloud Monitoring para la métrica Tiempo de inactividad de Tensor Core, sigue estos pasos:
- Ve a la consola Monitoring.
- En el panel de navegación, haga clic en Paneles de control.
- Haz clic en Crear panel de control y, a continuación, en Añadir widget.
- Elige el tipo de gráfico que quieras añadir. En este ejemplo, elige Línea.
- Escribe un título para el widget.
- Haga clic en el menú desplegable Seleccionar una métrica y escriba "Tiempo de inactividad de Tensor Core" en el campo de filtro.
- En la lista de métricas, selecciona TPU Worker -> Tpu -> Tensorcore idle duration.
- Para filtrar el contenido del panel de control, haz clic en el menú desplegable Filtrar.
- En Etiquetas de recursos, seleccione project_id.
- Elige un comparador y escribe un valor en el campo Valor.
- Haz clic en Aplicar.