Monitoraggio dei nodi Cloud TPU
Questa guida spiega come utilizzare Google Cloud Monitoring per monitorare i tuoi nodi Cloud TPU. Google Cloud Monitoring raccoglie automaticamente le metriche e i log da Cloud TPU e dal suo host Compute Engine. Questi dati possono essere utilizzati per monitorare l'integrità di Cloud TPU e Compute Engine.
Le metriche ti consentono di monitorare una quantità numerica nel tempo, ad esempio l'utilizzo della CPU, della rete o dell'MXU. I log acquisiscono gli eventi in un determinato momento. Le voci di log vengono scritte dal tuo codice, dai tuoi Google Cloud servizi, dalle applicazioni di terne parti e dall' Google Cloud infrastruttura. Puoi anche generare metriche dai dati presenti in una voce di log creando una metrica basata su log. Puoi anche impostare criteri di avviso in base ai valori delle metriche o alle voci di log.
Questa guida illustra il monitoraggio Google Cloud e spiega come:
- Visualizzare le metriche di Cloud TPU
- Configurare i criteri di avviso delle metriche Cloud TPU
- Esegui query sui log di Cloud TPU
- Crea metriche basate su log per configurare avvisi e visualizzare dashboard.
Prerequisiti
Questo documento presuppone alcune conoscenze di base del Google Cloud monitoraggio. Devi aver creato una VM Compute Engine e le risorse Cloud TPU prima di poter iniziare a generare e utilizzare Google Cloud Monitoring. Per maggiori dettagli, consulta la guida rapida di Cloud TPU.
Metriche
Le metricheGoogle Cloud vengono generate automaticamente dalle VM Compute Engine e dal runtime Cloud TPU. Le seguenti metriche vengono generate dai nodi Cloud TPU:
cpu/utilizationmemory/usagenetwork/received_bytes_countnetwork/sent_bytes_counttpu/mxu/utilizationtpu/tensorcore/idle_duration
Utilizzo CPU
La metrica cpu/utilization monitora l'utilizzo attuale della CPU sul worker Cloud TPU, rappresentato in percentuale. I valori sono in genere compresi tra 0,0 e 100,0, ma
potrebbero superare 100,0. Campionamento eseguito ogni 60 secondi. Potrebbero essere necessari fino a 180 secondi tra il momento in cui viene generato un valore e quello in cui viene visualizzato.
Utilizzo memoria
La metrica memory/usage monitora la memoria attualmente utilizzata dalla VM Cloud TPU in
byte. Questa metrica viene campionata ogni 60 secondi. Potrebbero essere necessari fino a 180 secondi tra il momento in cui viene generato un valore e quello in cui viene visualizzato.
Conteggio byte di rete ricevuti
La metrica network/received_bytes_count monitora il numero di byte cumulativi di
dati ricevuti dalla VM Cloud TPU tramite la rete in un determinato momento. Potrebbero essere necessari fino a 180 secondi tra il momento in cui viene generato un valore e quello in cui viene visualizzato.
Conteggio byte di rete inviati
La metrica network/sent_bytes_count monitora il numero di byte cumulativi inviati dalla VM Cloud TPU tramite la rete in un determinato momento. Potrebbero essere necessari fino a 180 secondi tra il momento in cui viene generato un valore e quello in cui viene visualizzato.
Durata inattività di TensorCore
La metrica tpu/tensorcore/idle_duration monitora il numero di secondi in cui il TensorCore di ogni chip TPU è rimasto inattivo. Questa metrica è disponibile per ogni chip su tutte le TPU in uso. Se è in uso un TensorCore, il valore della durata inattiva viene reimpostato su zero. Quando il TensorCore non è più in uso, il valore della durata inattivo inizia ad aumentare.
Il seguente grafico mostra la metrica tpu/tensorcore/idle_duration per una VM Cloud TPU v2-8 con un worker. Ogni worker ha quattro chip. In questo esempio, tutti e quattro i chip hanno gli stessi valori per tpu/tensorcore/idle_duration, quindi i grafici sono sovrapposti.
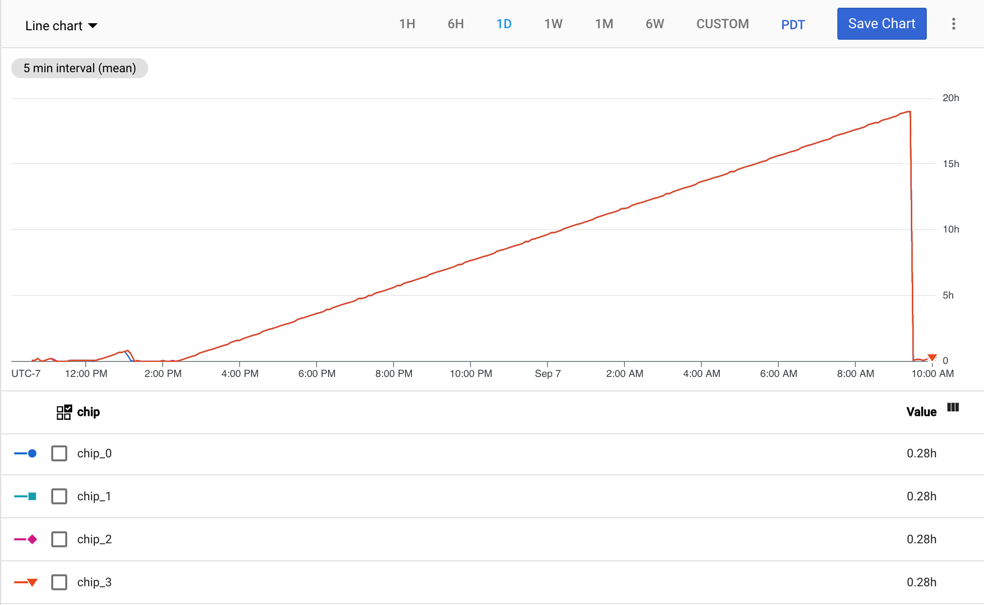
Utilizzo MXU
La metrica tpu/mxu/utilization monitora l'utilizzo corrente dell'unità MXU sul worker TPU, rappresentato in percentuale. I valori sono in genere numeri compresi tra 0,0
e 100,0. Campionamento eseguito ogni 60 secondi. Dopo il campionamento, i dati non sono visibili per un massimo di 180 secondi.
Per un elenco completo delle metriche generate da Cloud TPU, consulta Metriche Cloud TPU.
Visualizzazione delle metriche
Puoi visualizzare le metriche utilizzando Metrics Explorer nella Google Cloud console.
In Metrics Explorer, fai clic su SELEZIONA UNA METRICA
e cerca Cloud TPU Worker. Se l'opzione Mostra solo risorse e metriche attive è attiva, verranno visualizzate solo le metriche attualmente in fase di generazione. Fai clic su
Worker Cloud TPU per visualizzare le metriche disponibili.
Puoi anche accedere alle metriche utilizzando le chiamate HTTP di curl:
Utilizza il pulsante Prova nella documentazione di projects.timeSeries.query per recuperare il valore di una metrica nell'intervallo di tempo specificato.
- Inserisci il nome nel seguente formato: projects/{project-name}
- Aggiungi una query alla sezione Corpo della richiesta. Di seguito è riportata una query di esempio per recuperare la metrica della durata inattivo per la zona specificata negli ultimi 5 minuti.
fetch tpu_worker | filter zone = 'us-central2-b' | metric tpu.googleapis.com/tpu/tensorcore/idle_duration | within 5m" - Fai clic su Esegui per recuperare i risultati del messaggio POST HTTP.
Il documento Monitoring Query Language reference contiene ulteriori informazioni su come personalizzare questa query.
Puoi creare criteri di avviso che indicano a Google Cloud Monitoraggio di inviare un avviso quando viene soddisfatta una condizione.
Creazione di avvisi
I passaggi riportati in questa sezione mostrano un esempio di come aggiungere un criterio di avviso per la metrica Durata inattività TensorCore. Ogni volta che questa metrica supera le 24 ore, Cloud Monitoring invia un'email all'indirizzo email registrato.
- Vai alla console di monitoraggio
- Nel riquadro di navigazione, fai clic su Avvisi.
- Fai clic su MODIFICA CANALI DI NOTIFICA.
- In Email, fai clic su AGGIUNGI NUOVO.
- Digita un indirizzo email e un nome visualizzato, quindi fai clic su SALVA.
- Fai clic su CREA REGOLO.
- Fai clic su SELEZIONA UNA METRICA, seleziona Durata inattività tensor core e fai clic su APPLICA
- Fai clic su AVANTI e poi su Soglia.
- Per Attivatore di avvisi, seleziona Qualsiasi violazione della serie temporale.
- In Posizione soglia, seleziona Sopra la soglia.
- In Valore soglia, digita
86400000 - Fai clic su AVANTI
- In Canali di notifica, seleziona il canale di notifica via email e fai clic su Ok.
- Digita un nome per il criterio di avviso
- Fai clic su AVANTI e poi su CREA NORMA.
Quando la durata di inattività di TensorCore supera le 24 ore, viene inviata un'email all'indirizzo email specificato.
Logging
Le voci di log vengono scritte da Google Cloud servizi, servizi di terze parti, framework di ML o dal tuo codice. Puoi visualizzare i log utilizzando il visualizzatore log o l'API Logs. Per ulteriori informazioni sul Google Cloud logging, consulta Google Cloud Logging.
In Esplora log, puoi selezionare un tipo di risorsa:
- Worker Cloud TPU -> Zona -> ID nodo
- Risorsa sottoposta a controllo -> Cloud TPU -> API (
google.cloud.tpu.v1.Tpu.CreateNode,google.cloud.tpu.v1.Tpu.DeleteNode,google.cloud.tpu.v1.Tpu.UpdateNode)
I log del worker Cloud TPU contengono informazioni su un worker Cloud TPU specifico in una zona specifica, ad esempio la quantità di memoria disponibile sul worker Cloud TPU system_available_memory_GiB.
I log delle risorse sottoposte a controllo contengono informazioni su quando è stata chiamata una specifica API Cloud TPU e su chi ha effettuato la chiamata. Ad esempio CreateNode,
UpdateNode e DeleteNode.
I framework ML possono generare log in stdout e stderr. Questi log sono controllati dalle variabili di ambiente e vengono letti dallo script di addestramento.
Il codice può scrivere log in Google Cloud Logging. Per ulteriori informazioni, consulta Scrivere log standard e Scrivere log strutturati.
Visualizzazione dei log di Cloud TPU
- Vai al Google Cloud visualizzatore log
- Fai clic sul menu a discesa Risorsa.
- Fai clic su Nodo di lavoro Cloud TPU.
- Seleziona una zona
- Seleziona la Cloud TPU che ti interessa
- Fai clic su Applica. I log vengono visualizzati nei risultati della query
Per visualizzare i log delle risorse controllate:
- Vai al Google Cloud visualizzatore log
- Fai clic sul menu a discesa Risorsa.
- Fai clic su Risorsa sottoposta ad audit e poi su Cloud TPU.
- Scegli l'API Cloud TPU che ti interessa
- Fai clic su Applica. I log vengono visualizzati nei risultati della query
- Scegli le API che iniziano con
google.cloud.tpu.v1.Tpu
Query Google Cloud Log
Quando visualizzi i log nella Google Cloud console, la pagina esegue una query predefinita.
Puoi visualizzare la query selezionando l'opzione di attivazione/disattivazione Show query. Puoi
modificare la query predefinita o crearne una nuova. Per ulteriori informazioni, consulta
Creare query in Esplora log.
Informazioni sull'output del log per i log delle risorse sottoposte a controllo
Fai clic su una qualsiasi voce di log per espanderla e troverai un campo denominato protoPayload.
Espandi protoPayload per visualizzare una serie di campi secondari:
- logName: il nome del log
- protoPayload -> @type: il tipo di log
- resourceName: il nome della Cloud TPU
- methodName: il nome del metodo chiamato (solo log di controllo)
- request -> @type: il tipo di richiesta
- request -> node: dettagli sul nodo Cloud TPU
- request -> node_id: il nome della TPU
- severity: la gravità del log
Informazioni sull'output dei log per i log del worker Cloud TPU
Fai clic su una qualsiasi voce di log per espanderla e troverai un campo denominato jsonPayload.
Espandi jsonPayload per visualizzare una serie di campi secondari:
- accelerator_type: il tipo di acceleratore
- consumer_project: il progetto in cui si trova la Cloud TPU
- evententry_timestamp: l'ora in cui è stato generato il log
- system_available_memory_GiB: la memoria disponibile sul worker Cloud TPU (da 0 a 350 GB)
Creazione di metriche basate su log
Questa sezione descrive come creare metriche basate su log utilizzate per configurare dashboard e avvisi di monitoraggio. Per informazioni sulla creazione programmatica delle metriche basate su log, consulta Creare metriche basate su log in modo programmatico utilizzando l'API REST Cloud Logging.
L'esempio seguente utilizza il sottocampo system_available_memory_GiB per dimostrare come creare una metrica basata su log per il monitoraggio della memoria disponibile del worker Cloud TPU.
- Vai a Esplora log
Nella casella di query, inserisci la seguente query per estrarre tutte le voci di log con system_available_memory_GiB definito per il worker Cloud TPU principale:
resource.type=tpu_worker resource.labels.project_id=your-project resource.labels.zone=your-tpu-zone resource.labels.node_id=your-tpu-name resource.labels.worker_id=0 logName=projects/your-project/logs/tpu.googleapis.com%2Fruntime_monitor jsonPayload.system_available_memory_GiB:*
Fai clic su Crea metrica per visualizzare l'editor delle metriche.
In Tipo di metrica, scegli Distribuzione.
Digita un nome, una descrizione facoltativa e l'unità di misura per la metrica. inserisci "matrix_unit_utilization_percent" e "Utilizzazione MXU" rispettivamente nei campi Nome e Descrizione
Il filtro viene precompilato con lo script inserito in Esplora log
Fai clic su CREA METRICA.
Fai clic su Esplora metriche per visualizzare la nuova metrica. Potrebbero essere necessari alcuni minuti prima che le metriche vengano visualizzate
Creazione di metriche basate su log in modo programmatico utilizzando l'API REST Cloud Logging
Puoi anche creare metriche basate su log tramite l'API Cloud Logging. Per saperne di più, consulta la sezione Creare una metrica di distribuzione.
Creazione di dashboard e avvisi utilizzando metriche basate su log
Le dashboard sono utili per visualizzare le metriche (prevedi un ritardo di circa 2 minuti); gli avvisi sono utili per inviare notifiche in caso di errori. Per saperne di più, consulta Gestire le dashboard personalizzate e Creare criteri di avviso basati su metriche.
Creazione di dashboard
Per creare una dashboard in Cloud Monitoring per la metrica Durata inattività Tensorcore:
- Vai alla console di monitoraggio
- Nel riquadro di navigazione, fai clic su Dashboard.
- Fai clic su CREA DASHBOARD e poi su Aggiungi grafico.
- Scegli il tipo di grafico che vuoi aggiungere. Per questo esempio, scegli Linea
- Digita un titolo per la dashboard
- Fai clic sul pulsante sotto Risorsa e metrica.
- Scorri verso il basso nell'elenco delle risorse/metriche e seleziona Cloud TPU Worker -> Tpu -> Tensorcore idle duration
- Fai clic su Applica.
- Per filtrare i contenuti della dashboard, fai clic su CREA FILTRI DELLA DASHBOARD.
- Nel campo Etichetta, imposta project_id sul tuo progetto
- Fai clic su AGGIUNGI e imposta zone sulla zona in cui hai creato la TPU.
- Aggiungi un altro filtro per node_id e specifica il nome della tua Cloud TPU