TPU のアーキテクチャ
Tensor Processing Unit(TPU)は、ML ワークロードを高速化するために Google が設計したアプリケーション固有の集積回路(ASIC)です。Cloud TPU は、TPU をスケーラブルなリソースとして利用できるようにする Google Cloud サービスです。
TPU は、行列演算をすばやく実行するように設計されているため、ML ワークロードに最適です。Pytorch、JAX などのフレームワークを使用して、TPU で ML ワークロードを実行できます。
TPU の仕組み
TPU の仕組みを理解するには、ML モデルのトレーニングにおける計算上の課題に、他のアクセラレータがどのように対処しているかを理解することが役立ちます。
CPU の仕組み
CPU は、フォンノイマン アーキテクチャに基づく汎用プロセッサです。つまり、CPU は以下に示すようにソフトウェアとメモリと連動して機能します。
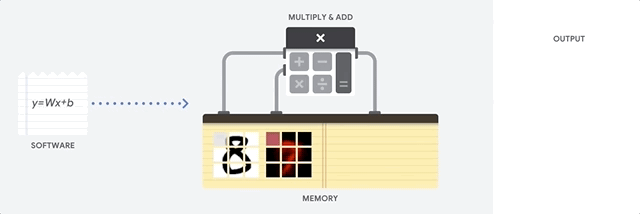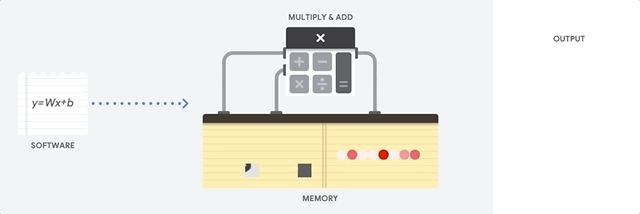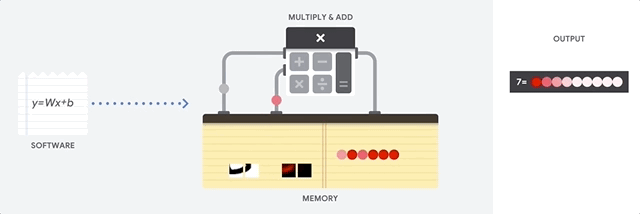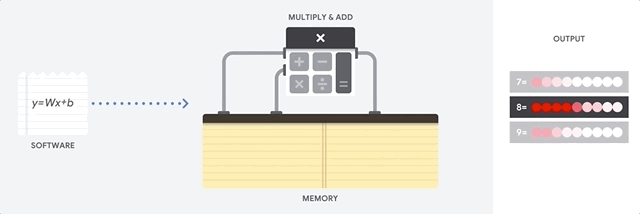
CPU の最大のメリットは、その柔軟性です。さまざまな種類のアプリケーションに対して、任意の種類のソフトウェアを CPU に読み込むことができます。たとえば、PC での文書処理、ロケット エンジンの制御、銀行取引、さらにはニューラル ネットワークを使用した画像分類にも CPU を使用できます。
CPU はメモリから値を読み込み、計算を行い、すべての計算結果をメモリに保存します。メモリアクセスは、計算速度に比べて遅く、CPU の総スループットを制限することがあります。これはフォンノイマン ボトルネックとも呼ばれます。
GPU の仕組み
スループットを向上させるため、GPU には単一のプロセッサ内に数千の算術論理演算ユニット(ALU)が組み込まれています。最新の GPU には、通常 2,500~5,000 個の ALU が含まれています。大量のプロセッサが存在するということは、数千の乗算と加算を同時に実行できるということになります。

ニューラル ネットワークでの行列乗算のように大量の並列処理を行うアプリケーションでは、この GPU アーキテクチャが効果を発揮します。実際、ディープ ラーニングの一般的なトレーニング ワークロードでは、GPU によって CPU とは桁違いのスループットを達成できます。
しかし、GPU が汎用プロセッサであることに変わりはなく、数多くのアプリケーションやソフトウェアをサポートしなければなりません。したがって、GPU にも CPU と同じ問題があります。何千もの ALU で行われるすべての計算で、GPU はレジスタや共有メモリにアクセスして、オペランドを読み取り、計算の中間結果を保存しなければなりません。
TPU の仕組み
Cloud TPU は、Google がニューラル ネットワークのワークロードに特化して設計した行列プロセッサです。TPU は文書処理、ロケット エンジンの制御、銀行取引といった操作に対応できませんが、ニューラル ネットワークで使用される大規模な行列演算は極めて高速に処理できます。
TPU の主なタスクは、乗算演算と累積演算の組み合わせである行列処理です。TPU には数千の乗算アキュムレータが含まれています。これらは、直接接続して大規模な物理マトリックスを形成しています。この構造は、シストリック アレイ アーキテクチャと呼ばれています。Cloud TPU v3 では、単一プロセッサ上に 128 x 128 ALU のシストリック アレイが 2 つあります。
TPU ホストは、インフィード キューにデータをストリーミングします。TPU は、インフィード キューからデータを読み込んで HBM メモリに保存します。計算が完了すると、TPU は結果をアウトフィード キューに読み込みます。TPU ホストは次に、アウトフィード キューから結果を読み取り、ホストのメモリに保存します。
行列演算を実行するために、TPU は HBM メモリからパラメータを Matrix Multiplication Unit(MXU)に読み込みます。

続いて、TPU は HBM メモリからデータを読み込みます。乗算が行われるたびに、その結果が次の乗算アキュムレータに渡されます。データとパラメータの乗算結果をすべて合計したものが出力となります。行列乗算処理中にメモリアクセスは必要ありません。
その結果、TPU はニューラル ネットワークにおいて、高い演算スループットを達成できます。
TPU システム アーキテクチャ
以降のセクションでは、TPU システムの主なコンセプトについて説明します。ML の一般的な用語の詳細については、ML の用語集をご覧ください。
Cloud TPU を初めて使用する場合は、TPU ドキュメントのホームページをご覧ください。
TPU チップ
TPU チップには、1 つ以上の TensorCore が含まれています。TensorCore の数は、TPU チップのバージョンによって異なります。各 TensorCore は、1 つ以上のマトリックス乗算ユニット(MXU)、ベクトル ユニット、スカラー ユニットから構成されます。TensorCore の詳細については、ディープ ニューラル ネットワークをトレーニングするための一領域に特化したスーパーコンピュータをご覧ください。
MXU は、シストリック アレイ内の 256 x 256(TPU v6e)または 128 x 128(v6e より前の TPU バージョン)の乗算アキュムレータで構成されています。MXU は、TensorCore の大部分の計算能力を提供します。各 MXU により、サイクルごとに 16,000 の乗累算演算を処理できます。すべての乗算は bfloat16 の入力を取りますが、すべての累積は FP32 数値形式で実行されます。
ベクトル ユニットは、活性化やソフトマックスなどの一般的な計算に使用されます。スカラー ユニットは、制御フロー、メモリアドレスの計算、その他のメンテナンス オペレーションに使用されます。
TPU Pod
TPU Pod は、専用のネットワークでグループ化された一連の連続した TPU です。TPU Pod 内の TPU チップの数は、TPU のバージョンによって異なります。
スライス
スライスは、高速チップ間相互接続(ICI)で接続された同じ TPU Pod 内にあるチップの集合体です。スライスは、TPU のバージョンに応じて、チップまたは TensorCore の観点で説明されます。
チップ形状とチップトポロジもスライス形状を指します。
マルチスライスとシングル スライス
マルチスライスはスライスのグループであり、チップ間相互接続(ICI)接続を超えて TPU 接続を拡張し、スライスを超えてデータを送信するためにデータセンター ネットワーク(DCN)を利用します。各スライス内のデータは、ICI で引き続き送信されます。このハイブリッド接続を使用すると、マルチスライスでスライス間の並列処理が可能になり、単一のスライスで処理できるよりも多くの TPU コアを 1 つのジョブで使用できます。
TPU は、単一のスライスや複数のスライスでジョブを実行するために使用できます。続きの内容は、マルチスライスの概要をご覧ください。
TPU タイプ
相互接続された TPU チップの 4x4x4 トポロジ。これは 3D トポロジ(TPU v4 以降)にのみ適用されます。
SparseCore
SparseCore は、スパース オペレーションを使用するモデルを高速化するデータフロー プロセッサです。主なユースケースは、エンベディングに大きく依存するレコメンデーション モデルの高速化です。v5p にはチップあたり 4 つの SparseCore が搭載されています。v6e にはチップあたり 2 つの SparseCore が搭載されています。SparseCore の使用方法の詳細については、大規模エンベディング モデル(LEM)用の SparseCore の詳細をご覧ください。XLA コンパイラで SparseCore を使用する方法は、XLA フラグを使用して制御します。詳細については、TPU XLA フラグをご覧ください。
Cloud TPU ICI の復元力
ICI の復元力により、キューブ間で TPU を接続する光リンクと光回路スイッチ(OCS)のフォールト トレランスが向上します(キューブ内の ICI 接続は影響を受けない銅リンクを使用しています)。ICI 復元力により、ICI 接続は OCS 障害と光 ICI 障害を回避して経路設定されます。その結果、TPU スライスのスケジューリング可用性が改善されますが、ICI のパフォーマンスが一時的に低下するというトレードオフがあります。
Cloud TPU v4 と v5p では、1 キューブ以上のスライスに対して ICI 復元力がデフォルトで有効になっています。次に例を示します。
- v5p-128(アクセラレータ タイプを指定する場合)
- 4x4x4(アクセラレータ構成を指定する場合)
TPU のバージョン
TPU チップのアーキテクチャは、厳密にいえば使用する TPU のバージョンによって異なります。また、TPU バージョンはそれぞれさまざまなスライスサイズと構成をサポートしています。システム アーキテクチャとサポートされている構成の詳細については、次のページをご覧ください。
TPU クラウド アーキテクチャ
Google Cloud を使用すると、TPU VM を介して TPU をコンピューティング リソースとして使用できます。ワークロードに TPU VM を直接使用することも、Google Kubernetes Engine または Vertex AI を介して使用することもできます。以降のセクションでは、TPU クラウド アーキテクチャの主なコンポーネントについて説明します。
TPU VM アーキテクチャ
TPU VM アーキテクチャを使用すると、SSH で TPU デバイスに物理的に接続されている VM に直接接続できます。TPU VM(ワーカー)は、基盤となる TPU にアクセスできる Linux を実行している仮想マシンです。VM への root アクセス権があるため、任意のコードを実行できます。コンパイラとランタイム デバッグログ、エラー メッセージにアクセスできます。

シングルホスト、マルチホスト、サブホスト
TPU ホストは、TPU ハードウェアに接続された物理コンピュータで実行される VM です。TPU ワークロードは 1 つ以上のホストを使用できます。
シングルホスト ワークロードは 1 つの TPU VM に制限されます。マルチホスト ワークロードは、トレーニングを複数の TPU VM に分散します。サブホスト ワークロードは、TPU VM 上の一部のチップを使用しません。
TPU ノード アーキテクチャ(非推奨)
TPU ノード アーキテクチャは、gRPC を介して TPU ホストと通信するユーザー VM で構成されています。このアーキテクチャを使用している場合、TPU ホストに直接アクセスできないため、トレーニング エラーや TPU エラーのデバッグが難しくなります。
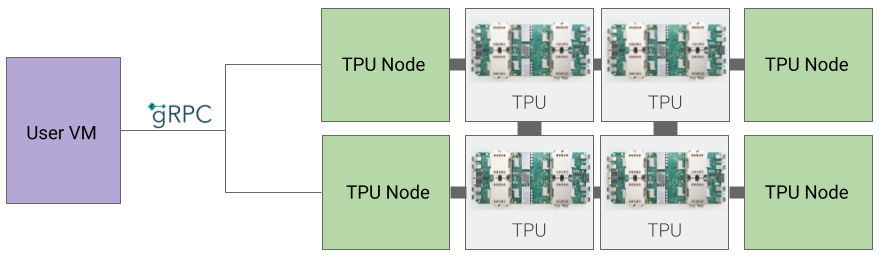
TPU ノードから TPU VM アーキテクチャへの移行
TPU ノード アーキテクチャを使用している TPU がある場合は、次の手順で TPU VM として識別、削除、再プロビジョニングを行います。
[TPU] ページに移動します。
[アーキテクチャ] の見出しで、TPU とそのアーキテクチャを見つけます。アーキテクチャが「TPU VM」の場合は、対応の必要はありません。アーキテクチャが「TPU ノード」の場合は、TPU を削除して再プロビジョニングする必要があります。
TPU を削除して再プロビジョニングします。