Autocheckpoint を使用してトレーニングの進行状況を保持する
これまでのように、TPU VM でメンテナンスが必要な場合、ユーザーがチェックポイントの保存などの進行状況維持アクションを実行するための時間を確保することなく、処理がすぐに開始されます。これを図 1(a)に示します。
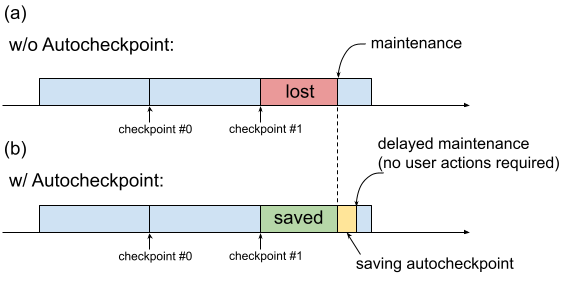
図 1. Autocheckpoint 機能の図:(a)Autocheckpoint がない場合、今後のメンテナンス イベントが発生すると、最後のチェックポイントからのトレーニングの進行状況が失われます。(b)Autocheckpoint を使用すると、今後のメンテナンス イベントの際に、最後のチェックポイント以降のトレーニングの進行状況を保持できます。
Autocheckpoint(図 1(b))を使用すると、メンテナンス イベントが発生したときにスケジュールが設定されていないチェックポイントを保存するようにコードを構成することで、トレーニングの進行状況を保持できます。メンテナンス イベントが発生すると、最後のチェックポイント以降の進行状況が自動的に保存されます。この機能は、単一スライスとマルチスライスの両方で機能します。
Autocheckpoint 機能は、SIGTERM シグナルをキャプチャしてチェックポイントを保存できるフレームワークで動作します。サポートされているフレームワークは次のとおりです。
Autocheckpoint の使用
Autocheckpoint 機能はデフォルトで無効になっています。TPU を作成するか、キューに格納されたリソースをリクエストする場合は、TPU のプロビジョニング時に --autocheckpoint-enabled フラグを追加して Autocheckpoint を有効にできます。この機能を有効にすると、Cloud TPU はメンテナンス イベントの通知を受信したら、次の操作を行います。
- TPU デバイスを使用してプロセスに送信された SIGTERM シグナルをキャプチャする
- プロセスが終了するか、5 分が経過するまで待ちます。
- 影響を受けるスライスのメンテナンスを行う
Autocheckpoint で使用されるインフラストラクチャは ML フレームワークに依存しません。任意の ML フレームワークは、SIGTERM シグナルをキャプチャしてチェックポイント プロセスを開始できる場合、Autocheckpoint をサポートできます。
アプリケーション コードで、ML フレームワークが提供する Autocheckpoint 機能を有効にする必要があります。たとえば、Pax の場合、トレーニングの起動時にコマンドライン フラグを有効にします。詳細については、Pax を使用した Autocheckpoint のクイックスタートをご覧ください。フレームワークは、SIGTERM シグナルを受信すると、スケジュール外のチェックポイントを保存します。TPU が使用されなくなったら、影響を受ける TPU VM はメンテナンスに入ります。
クイックスタート: MaxText での Autocheckpoint
MaxText は、Cloud TPU をターゲットとする純粋な Python/JAX で記述された、高性能で任意に拡張可能なオープンソース LLM です。MaxText には、Autocheckpoint 機能を使用するのに必要な設定がすべて含まれています。
MaxText README ファイルでは、MaxText を大規模に実行する 2 つの方法について説明しています。
multihost_runner.pyの使用(テストに推奨)multihost_job.pyの使用(本番環境に推奨)
multihost_runner.py を使用する場合は、キューに格納されたリソースをプロビジョニングするときに autocheckpoint-enabled フラグを設定して Autocheckpoint を有効にします。
multihost_job.py を使用する場合は、ジョブの起動時に ENABLE_AUTOCHECKPOINT=true コマンドライン フラグを指定して Autocheckpoint を有効にします。
クイックスタート: 単一スライス上の Pax での Autocheckpoint
このセクションでは、単一スライス上で Pax を使用して Autocheckpoint を設定して使用する方法の例を示します。適切な設定を行うと、次のようになります。
- メンテナンス イベントが発生すると、チェックポイントが保存されます。
- チェックポイントが保存されると、Cloud TPU は影響を受ける TPU VM のメンテナンスを行います。
- Cloud TPU のメンテナンスが完了すると、TPU VM を通常どおり使用できます。
TPU VM の作成時やキュー内のリソースのリクエスト時に
autocheckpoint-enabledフラグを使用します。例:
環境変数を設定します。
export PROJECT_ID=your-project-id export TPU_NAME=your-tpu-name export ZONE=zone-you-want-to-use export ACCELERATOR_TYPE=your-accelerator-type export RUNTIME_VERSION=tpu-ubuntu2204-base
環境変数の説明
変数 説明 PROJECT_ID実際の Google Cloud のプロジェクト ID。既存のプロジェクトを使用するか、新しいプロジェクトを作成します。 TPU_NAMETPU の名前。 ZONETPU VM を作成するゾーン。サポートされているゾーンの詳細については、TPU のリージョンとゾーンをご覧ください。 ACCELERATOR_TYPEアクセラレータ タイプでは、作成する Cloud TPU のバージョンとサイズを指定します。TPU の各バージョンでサポートされているアクセラレータ タイプの詳細については、TPU のバージョンをご覧ください。 RUNTIME_VERSIONCloud TPU ソフトウェアのバージョン。 アクティブな構成でプロジェクト ID とゾーンを設定します。
gcloud config set project $PROJECT_ID gcloud config set compute/zone $ZONE
TPU を作成します。
gcloud alpha compute tpus tpu-vm create $TPU_NAME \ --accelerator-type $ACCELERATOR_TYPE \ --version $RUNTIME_VERSION \ --autocheckpoint-enabled
SSH を使用して TPU に接続します。
gcloud compute tpus tpu-vm ssh $TPU_NAME単一スライスに Pax をインストールする
Autocheckpoint 機能は、Pax バージョン 1.1.0 以降で動作します。TPU VM に
jax[tpu]と最新のpaxmlをインストールします。pip install paxml && pip install jax[tpu] -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
LmCloudSpmd2Bモデルを構成するトレーニング スクリプトを実行する前に、ICI_MESH_SHAPEを[1, 8, 1]に変更します。@experiment_registry.register class LmCloudSpmd2B(LmCloudSpmd): """SPMD model with 2B params. Global batch size = 2 * 2 * 1 * 32 = 128 """ PERCORE_BATCH_SIZE = 8 NUM_LAYERS = 18 MODEL_DIMS = 3072 HIDDEN_DIMS = MODEL_DIMS * 4 CHECKPOINT_POLICY = layers.AutodiffCheckpointType.SAVE_NOTHING ICI_MESH_SHAPE = [1, 8, 1]
適切な構成でトレーニングを開始します。
次の例は、Autocheckpoint によってトリガーされたチェックポイントを Cloud Storage バケットに保存するように
LmCloudSpmd2Bモデルを構成する方法を示しています。your-storage-bucket は、既存のバケットの名前に置き換えます。または、新しいバケットを作成します。export JOB_LOG_DIR=gs://your-storage-bucket { python3 .local/lib/python3.10/site-packages/paxml/main.py \ --jax_fully_async_checkpoint=1 \ --exit_after_ondemand_checkpoint=1 \ --exp=tasks.lm.params.lm_cloud.LmCloudSpmd2B \ --job_log_dir=$JOB_LOG_DIR; } 2>&1 | tee pax_logs.txt
コマンドに渡される 2 つのフラグに注意してください。
jax_fully_async_checkpoint: このフラグをオンにすると、orbax.checkpoint.AsyncCheckpointerが使用されます。AsyncCheckpointerクラスは、トレーニング スクリプトが SIGTERM シグナルを受信すると、チェックポイントを自動的に保存します。exit_after_ondemand_checkpoint: このフラグをオンにすると、Autocheckpoint が正常に保存された後に TPU プロセスが終了し、メンテナンスがすぐに実行されます。このフラグを使用しない場合、チェックポイントの保存後にトレーニングが続行され、Cloud TPU はタイムアウト(5 分)が発生するまで待機してから、必要なメンテナンスを行います。
Orbax での Autocheckpoint
Autocheckpoint 機能は、MaxText または Pax に限定されません。SIGTERM シグナルをキャプチャしてチェックポイント プロセスを開始できるフレームワークは、Autocheckpoint によって提供されるインフラストラクチャで動作します。JAX ユーザーに共通のユーティリティ ライブラリを提供する名前空間である Orbax が、これらの機能を提供します。
Orbax のドキュメントで説明されているように、これらの機能は orbax.checkpoint.CheckpointManager のユーザーに対してデフォルトで有効になっています。各ステップの後に呼び出される save メソッドは、メンテナンス イベントが差し迫っているかどうかを自動的に確認します。その場合は、ステップ番号が save_interval_steps の倍数でない場合でも、チェックポイントを保存します。また、GitHub のドキュメントには、ユーザーコードを変更して、Autocheckpoint を保存した後にトレーニングを終了する方法も記載されています。